[논문 리뷰] Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Multi-modal
고려대 컴퓨터학과 소속 김현우교수님 랩실에서 나온 논문이다.
학부생 수준으로 공부하고 이해한 뒤 작성한 것이라 틀린게 있을 수 있음.
Abstract
Video-text 간 representation을 supervised 방식으로 학습하기 위해선 굉장히 많은 ("prohibitively") 양의 manually annotated 데이터셋이 필요하다.
representation learning:
예를 들면 unsupervised learning의 종류 중 contrastive learning에 해당하는데, 데이터를 표현하는 방식을 학습하는 걸 말한다.
uncurated but narrated(엄선되진 않았지만 나레이션이 있는?) 데이터셋인 HowTo100M이 존재한다.
그치만 text가 모호하다는 점과, 순서가 맞지 않은 것도 있어서 self-supervised 방식으로 학습시키기에는 무리가 있다.
그래서 고안한 Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS 억지)를 논문에서 제시한다. 정제되지 않은 데이터에서 정보를 잘 뽑아내도록 Dynamic Time Warping(DTW)(추후 설명)의 variant를 활용한 방식이다.
이 DTW가 잘 매칭되지 않은 데이터(weakly correlated data)를 잘 못다루고, globally 가장좋은 path만 생각하는 경향이 있어서 differentiable DTW를 개발했다. 얘는 이런 데이터 속에서도 local information를 반영한다.
추가적으로 contrastive learning scheme도 적용했다.
1. Introduction
기존 video-text 모델들은 많은 manual annotation들이 필요했다. 하지만 큰 scale의 데이터셋을 만드는게 어렵다.
최근 fully supervised methods 말고 multi-modal을 많은 양의 데이터로 self-supervised learning을 하는 연구들이 있었다. 여기서 HowTo100M 데이터셋이 등장한다.
 HowTo100M 데이터셋은 weakly correlated; 위 그림처럼 한 video clip에 해당하는 caption이 일찍/늦게 등장하거나, 아에 없을 수도 있다는 뜻이다. a가 이상적인 형태이고, bcd는 나쁜예 유형이다.
HowTo100M 데이터셋은 weakly correlated; 위 그림처럼 한 video clip에 해당하는 caption이 일찍/늦게 등장하거나, 아에 없을 수도 있다는 뜻이다. a가 이상적인 형태이고, bcd는 나쁜예 유형이다.
이를 해결하기 위해, multiple instance learning(MIL)-based contrastive learning adopting Noise Contrastive Learning(NCE) loss 연구가 있었다. 이 연구는 한 clip에 대해 많은 caption들 중 어떤게 제일 가까운지; 즉, one-to-many correspondence를 봤다.
여기서는 문제해결을 위해 Dynamic Time Warping(DTW)를 제안한다. standard DTW는 순서상의 배열만 보는데, 안맞는 쌍을 넘기고, 랜덤한 시간대에 시작/마침으로써 유연성을 추가했다.
또, local neighborhood smoothing으로 locally optimal path 뿐만아니라 globally optimal path를 고려하도록 했다.
게다가 미분가능하게 알고리즘을 짜서 이거를 representation learning 상 거리계산으로 활용했다.
다 합쳐서 자동으로 weakly correlated 쌍을 활용하는 위에서 말한 VT-TWINS을 만들었다.
downstream task들에 적용해 generalized well한지 보일 것이다.
2. Related Work
Self-Supervised Learning for Videos
2가지 연구동향이 있다.
-
Design video-specific pretext tasks(시간순서 맞추기, video rotation 예측 등).
-
Contrastive learning 활용.
같은 영상의 clip이면 가까이, 다른 영상이면 멀리 떨어지게끔 학습하는 방식.
많은 연구에서 여러 modalities의 mutual supervision 으로부터 각각 modality의 representation을 얻으려고 한다. 예를들어, video, audio, narrations들을 같이 고려한다.
MIL-NCE는 contrastive learning으로 clip과 caption들간 joint embedding을 학습하는 연구이다.
번외로 additional crossmodal encoder를 활용하는 연구도 있다.
이 논문에서는 contrastive learning을 확장해서 additinal crossmodal encoder없이 두가지 시간축의 modality를 시간적으로 정렬할 것이다.
Sequence Alignment
순서를 정렬하는게 매우 중요하다. 그래서 DTW를 활용하여 strong temporal constraints로 두 sequences 사이의 거리를 잴 것이다.
선행 연구로
- DTW로 global sequence alignment를 대체 task로 활용한 연구,
- discrete operations(min함수 같은)의 미분가능한 approximations를 활용해 end-to-end learning 연구,
- DTW로 frame-wise alignment loss 계산하는 연구,
- Drop-DTW로 pairwise distance 기반해서 outlier를 자동으로 날리는 연구,
- DTW만 쓰면 한 점으로 feature embedding이 모이는 feature collapsing이 발생한다. 따라서 subsidiary regularization loss term을 DTW에 추가한 연구도 있다.
3. Preliminaries
3.1 Dynamic Time Warping(DTW)
DTW는 두 시계열 데이터의 optimal한 정렬을 찾아내는 것이다.
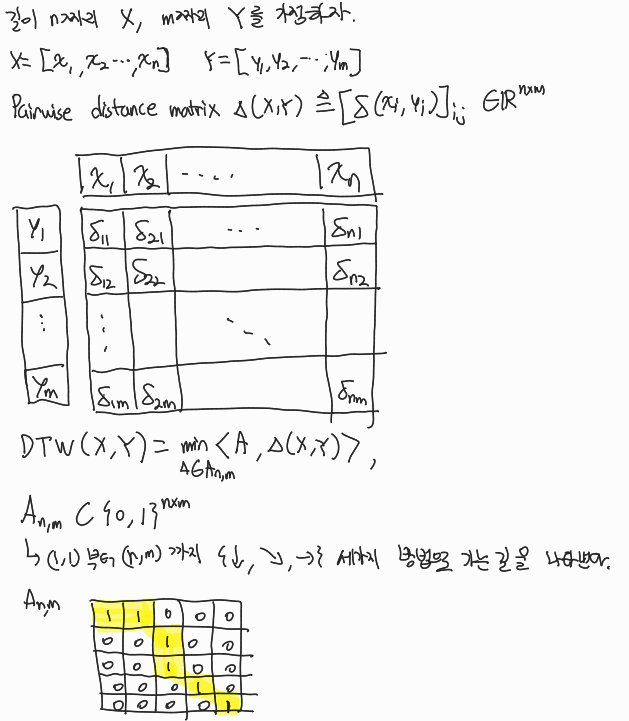 도달하는 길을 잘 찾기위해 코테에 나오는 dynamic programming을 활용한다.
도달하는 길을 잘 찾기위해 코테에 나오는 dynamic programming을 활용한다.
A로 표시한 길과 cost간 내적을 통해 DTW(X,Y)값이 결정되는 것이다. 계산 결과를 보고 최적의 A를 찾아내려한다.
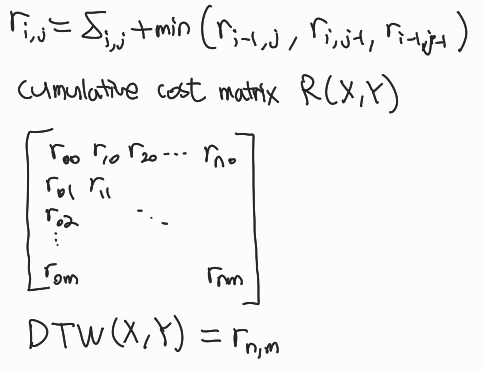
거리 cost를 누적해서 담아두는 에 부터 update하기 시작한다. 왼쪽 대각선 위, 왼쪽, 위쪽 cost중 낮은걸 계속 더해 저장하면 결국 에는 부터 도달하는데까지 필요한 cost가 나와서 결국 DTW값이 값과 같아진다.
Soft-DTW
이건 DTW에 min함수가 미분이 안되기때문에 조금 고쳐서 아래 써놓은것 처럼 로그함수의 합으로 미분가능하게 바꾼 식이다.
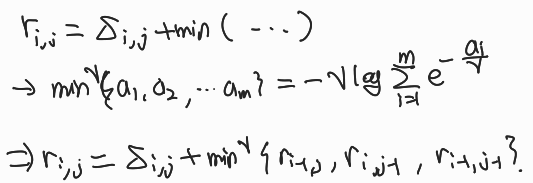 감마값이 0이면 min함수와 같아지고 커질수록 suboptimal path들의 cost도 더한다고 생각하면 된다.
감마값이 0이면 min함수와 같아지고 커질수록 suboptimal path들의 cost도 더한다고 생각하면 된다.
3.2 The HowTo100M Dataset
데이터셋 크기와 특징을 소개했다.
단점을 Ambiguity, Irrelevant pairs, Non-Sequential alignment로 구분했다.
4. Method
VT-TWINS 구성을 드디어 소개한다.
DTW를 변형한 Locally Smoothed Soft-DTW with Weak Alignment(S2DTW):
1. local neighborhood smoothing과 weak alignment를 적용한다.
2. temporal data augmentation를 non-sequentail alignments에 적용한다.
3. contrasitve learning scheme을 적용한다.
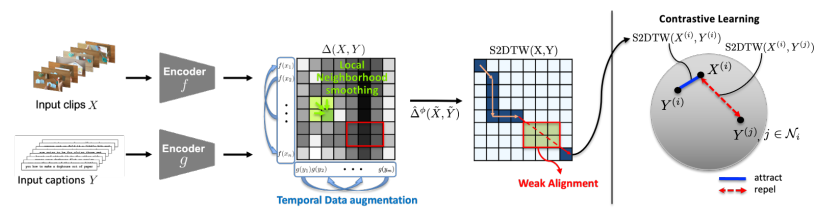
4.1 Local Neighborhood Smoothing
DTW를 계산할 때
- 여러개를 같이 고려할 수 있다는 점,
- 그 와중에도 local optimal, 즉, 근처에 것에 좀 더 집중한다는 점
을 챙기는 방법이다.

기존에 있던 distance matrix 에 dp를 한번더 해서 smooth한 distance matrix 를 생성한다. 이후 이걸로 cost계산하는 dp를 돌려서 DTW값을 계산해 낸다.
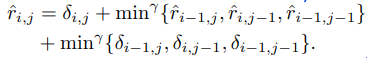
이렇게 하면 global optimality만큼 local optimality도 같이 보게된다.
Differentiation
미분으로 증명. 자세한 계산은 (어려워서)생략한다.
Soft-DTW와 다르게 S2DTW는 이 껴 있어서 간단하게 안된다 (). 오히려 좋은게,
Soft DTW는 local optimal path를 못보는데,
S2DTW는 두 개를 다르게 해석할 수 있어서, 과의 관계로 global optimal path, 와의 관계로 local optimal path를 둘 다 볼 수 있다는 점을 챙겼다.
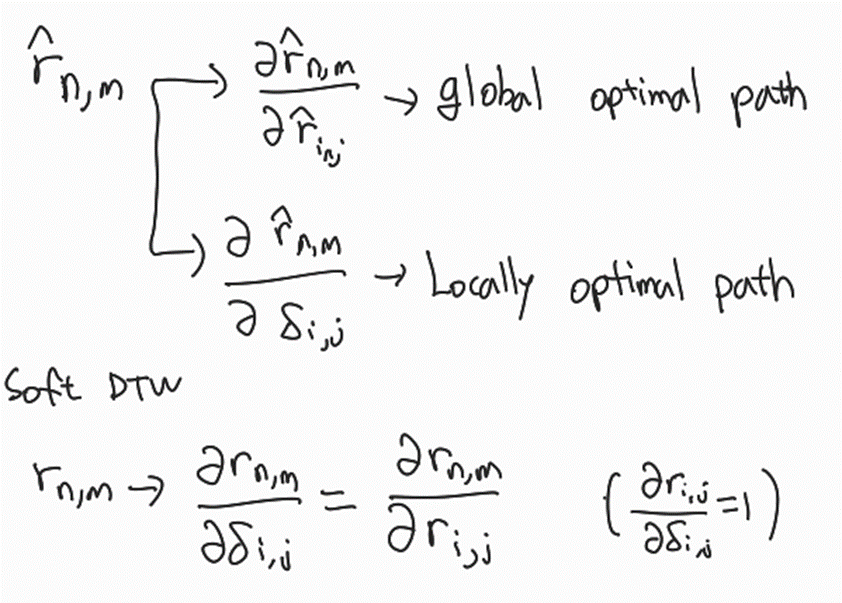
4.2 Weak Alignment
Soft-DTW에서 변형시켜서 irrelevant pair쪽으론 정렬 안되게 강제로 막는 방법이다.
S2DTW는 시작과 끝을 랜덤한 곳으로 설정한다.
DWSA의 방식을 가져와서 one-to-one matching with skipping을 적용할건데, 각 X 원소들 사이에 dummy element를 추가한다. 그러면 계산하던 distance matrix 크기가 (2n+1)x(2m+1)로 커진다.
는 하이퍼파라미터로 정해서, DTW path를 계산할때 이 값보다 작은쪽으로 안가게끔 하는 역할을 했다.
아래 그림을 보면, 연관없는 y3을 기존 방식대로라면 억지로 지나가야 했지만, dummy element를 넣음으로써 y3말고 dummy element를 통해 지나가는 길을 만들었다.
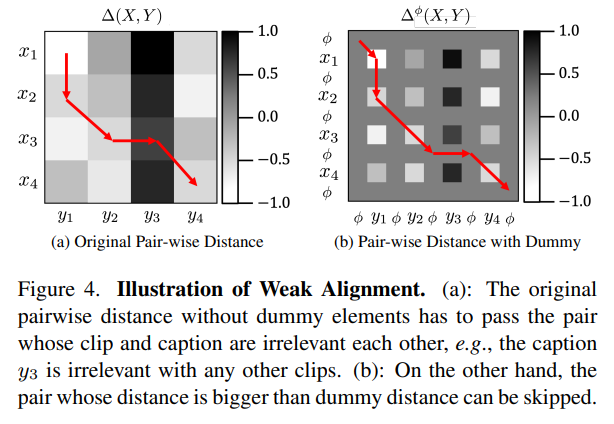
DTW, soft-DTW는 각 시간대 하나당 clip-text 한 쌍을 붙여줬다. S2DTW에서는 irrelevent pairs에 대해선 weakly align정도만 하고, many-to-many matching을 구현했다.
4.3 Temporal Data Augmentation
clip-caption이 제 순서대로 안맞는 경우를 위해 준비했다.
기존 DTW는 아래, 오른쪽 대각선 아래, 오른쪽으로 가는 선택지만 있어서 해결할 수 없었다.
이를 극복하기 위해 clip과 caption의 시간순서를 섞는 augmentation을 적용한다.
π를 순열이라 하면, clip에 해당하는 이 되는데 여러가지 순열에 대해 연산을 할건데, 모든 순열을 다해보면 너무 많고 않좋으니까 가능한 몇개의 subset을 뒀다.
먼저 time window개념으로 j번째 clip은 j+w, j-w 안쪽에 있도록 했다.
즉, 범위를 로 한정한다.
이 조건을 만족하는 순열들을 라 하면, target distribution은 다음과 같다
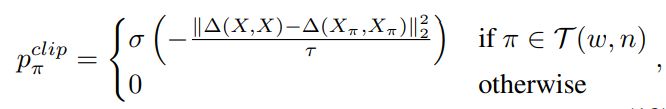
일단 는 모든 에 대해 계산하는 확률 계산용 softmax 함수, 는 temperature parameter(온도아님-분포를 조절하는 변수). 는 순열 적용 전후에 해당하는 자기 자신에 대한 유사도 matrix이다.
원본 거리 matrix와 augmentation이후 거리 matrix의 차이가 작은 것에 높은 을 주기 때문에, 자기자신에 대한 유사도를 최대한 덜 바꾸는 순열을 주로 내 놓을 것이다;
사용한 augmentation이 representation learning을 방해할 정도로 강한 aug가 아니다.
~ 는 분포에서 샘플링한 순서가 섞인 sequence이다. 도 같은 방법으로 계산해서
DTW를 계산할 때 쓸 distance matrix는 가 된다
이렇게 하면 순서상 옆에 없던 clip, caption들간의 feature도 계산해 볼 수 있다.
4.4 Contrastive Learning with S2DTW
DTW를 사용하면 조심해야하는 문제가 negative pair 없이 distance를 최소화하려 하다보면 feature collapsing이 발생할 수 있다.
하여 contrastive loss중 하나인 InfoNCE loss를 적용한다.
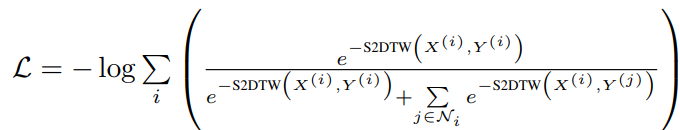
가 i번째 video(batch)의 negative samples에 해당한다. 가까이에 있는 negative sample은 다른 negative sample들에 비해 더 강하게 밀려난다. - S2DTW로 거리를 계산해서 비교적 가까우면 점수를 잘 받기 때문이다.
5. Experiments
5.1 Downstream tasks
Action Recognition, Video Text Retreival, Action step localization. 이 세가지 Task에 대해 5가지 dataset으로 실험한 결과 다른 self-supervise model들보다 좋은 결과를 보였다.
5.2 Ablation studies
-
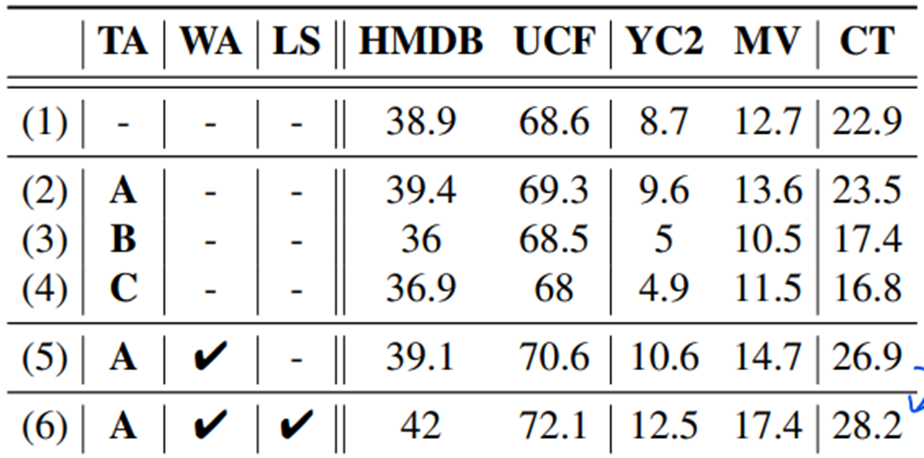
Temporal Data Augmentation (표 2,3,4)
A. 논문에서 제시한대로 self-similarity 점수가 높은 순열이 잘나오게끔
B. 완전 랜덤
C. A와 반대로 self-similarity가 낮으면 잘나오게끔
해서 봤더니 A가 좋았다. -
Weak Alignment. (표 2,5)
실제 그림으로 봤을때에도 관계없는 caption을 무시하는 결과를 볼 수 있다.
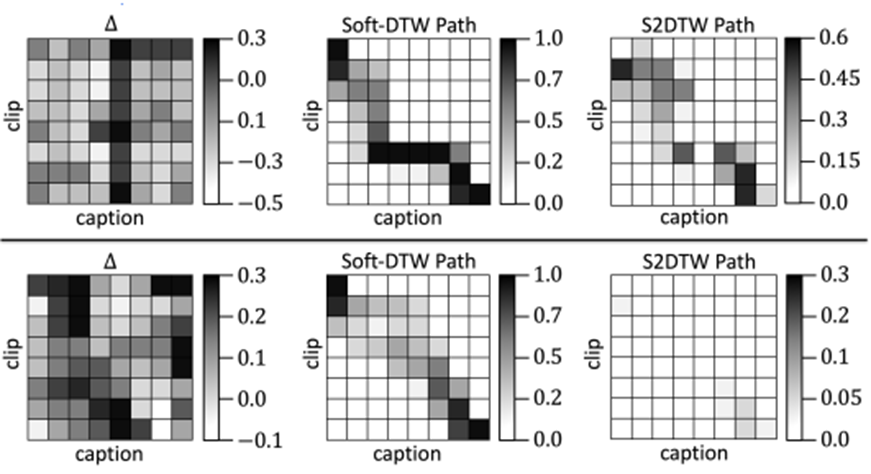
- Local Neighborhood Smoothing (표 5,6)
확실히 global optimal path만 보던 Soft-DTW에 비해 local optimal path도 고려하는 S2DTW가 효과적이다.