[논문 리뷰] e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce
Multi-modal
네이버에서 22년에 출간한 vision-llm multi-modal 관련 논문이다.
네이버 스마트스토어를 통해 얻은 데이터셋을 잘 활용할 수 있는 방법을 담은 논문이다.
논문 전체를 하나하나 뜯어보진 않은 상태이다.
0. Abstract
E-commerce에 활용하기 위한 vision-language multi-modal논문이다.
unlabeled text, image로 contrastive learning framework에 적용ㅎ여 language, vision model을 학습할 것이다.
이때 e-commerce라는 domain 특화된 문제들이 있고, 해결한 방법을 공유한다.
이후 5가지 downstream task에 활용하여 성능을 본다: category classification, attribute extraction, product matching, product clustering, adult product recognition.
1. Introduction
e-commerce domain 특성상 데이터셋에 나타나는 5가지 문제점을 제시한다.
- Noisy Data: 너무 많은 사람들이 상품을 등록하고 하다보니, image-text pair가 안맞는경우가 많다. 이런 데이터가 들어가면 model generalization에 방해된다.
- Duplicate and Similar Products: 같은 상품이 다른 판매자로부터 여러번 등록된다. 그러다보니 약간씩 다른 사이즈, 부피 같은 상품 특징을 가진 데이터가 매우 많다.
이런 같은 데이터가 등장하는 경우는 한 쌍 제외 모두 negative pair로 두고 밀어내도록 contrastive learning에 있어 매우 취약하다. 실제로 같은데 다르다고 해버릴 것이기 때문이다. - Irregularity and Sparsity: 문법적 오류도 있고, title 길이도 매우 짧다. (<11단어) 때문에, 제목으로부터 올바른 의미 정보를 얻기 어렵다.
- Limited Memory: GPU, TPU 한계 때문에 큰 batch size를 이용하기 어렵다.
- Model Convergence: 큰 batch를 이용해 학습하면 epoch수를 늘려도 모델 정확도가 떨어지고, converge 하는데에도 오래걸린다.
2. Related Works
생략
3. System Architecture
3.1 Overview
총 3개의 subsystems로 구성되어 있다: data preparation, modeling, applications
대략적인 설명:
판매자들로부터 상품 정보들, 제목, 이미지를 받아 적당한 처리를 하고 데이터베이스에 저장한다.
이후 여기서 전처리 과정을 거쳐 multimodal을 학습하는데 사용한다. 적절한 성능이 나오는 source model을 가지고 약간의 fine-tuning으로 여러 downstream applications에 활용한다.
이제 이 downstream applications를 가지고 상품설명 내용을 늘려서 검색 시스템이나 검색 순위에 영향을 준다.
3.2 Data Preparation
3.2.1 Data Collection
네이버 쇼핑에 가입한 판매자들은,
product content, descriptions- title, price, brand name, images를 등록한다. 등록이 허가되면 이미지는 썸네일 기준에 맞게 전처리와 resizing을 거쳐 저장된다.
이후, 이 상품이 판매중인지, 품절인지 확인하고, 판매중이라면,
classification을 거쳐 예측된 카테고리에 등록되고, 데이터베이스에 비슷한 상품이 있는지 product comparison으로 확인한다. - 이때 text, image base의 만든 multimodal을 활용한다.
여기까지 합격하면 serviceable하다고 판단한다.
네이버 쇼핑의 데이터베이스는 주로 Hadoop(빅데이터 처리 플랫폼), Spark(Apache)를 통해 관리한다.
3.2.2 Data Preprocessing

e-commerce 데이터셋의 3가지 문제를 해결해 보자
- Invalid Product:
1) 이미지가 없거나, 너무 작거나, 잘린 이미지가 있는 pair 제거.
2) rule-based system으로 상품 제목의 token set과 비교해 안맞는 text가 있으면 제거.
3) 특수문자를 공백으로 바꾸고, 제목이 2 token이내라면 제거. - Duplicate Products:
1) 제목이 같으면 제거.
2) 같은 이미지를 찾기위해,
이미지를 5x5 패치로 만들고, mean color value로 1자리 hash key 생성. 이미지 사이즈도 고려해서 총 29자리 hashed value를 만들어 같은 hash value라면 제거.
3) Compressed Embedding(Resnet-34의 마지막 레이어에서)을 뽑아내 embedding이 같으면 제거. - Inappropriate Products:
얘네들의 분포는 보통 상품과 차이가 나긴 하지만, 걸러지지 않기 위한 변형(중요한 부분에 blur나 mask)이 들어가있다.
->관리 시스템상 flagged된적 있다면 데이터셋에서 제외.
그 결과 총 1B dataset으로부터 330M pair(=NAVER Shopping data)로 걸러졌다. 학습시간 단축과 실험을 위해 product matching system으로 한번 더 걸러서 270M사이즈 데이터셋도 있다.
3.3 Pre-training Method: e-CLIP
CLIP이나 LiT에서 제시한 contrastive loss를 사용하면 위에서 언급한 데이터셋의 문제 때문에 안좋다. 아래 그림이 제시한 e-CLIP의 전체 구조이다.
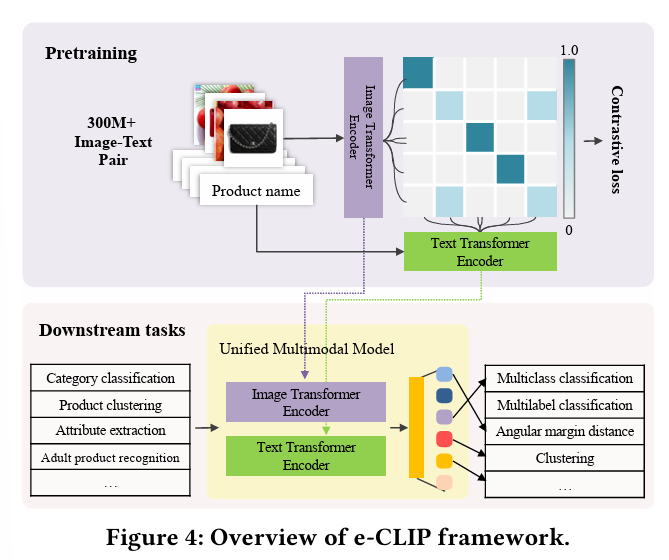
3.3.1 Model architecture:
Image encoder: ViT-B/32 - Multimodal에서 CNN을 사용하는 것 보다 학습시간이 짧고 GPU사용이 적다.
Text encoder: fine-tune a pre-trained multilingual BERT-base model.
- ALIGN, CLIP처럼 [CLS] token의 representation을 활용하거나 BASIC처럼 전 step의 averaging representation을 활용하기보다
모델의 가장 위 레이어에서 steps of token length에서 average representation를 계산했다. - ??
3.3.2 Training objective
InfoNCE loss를 사용하기 위해 몇가지 수정사항을 적용한다.
- Catalog-based soft labeling:
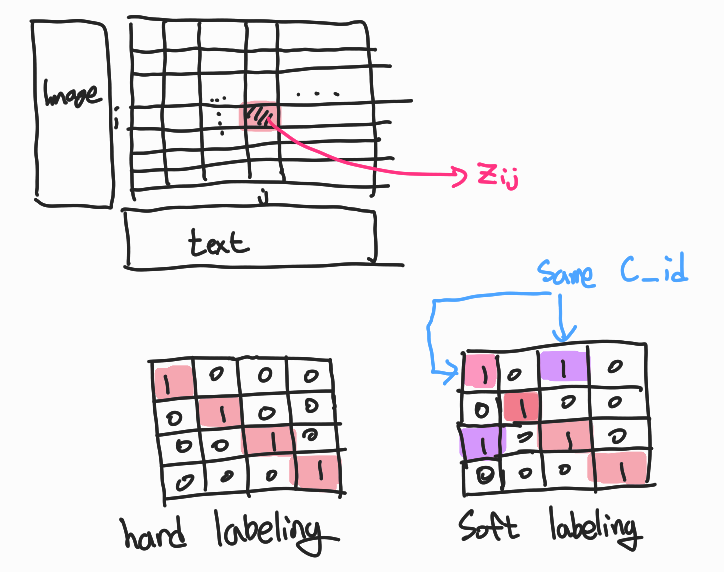
기존 방식인 hard labeling에서는 대각방향만 같다는 뜻으로 1, 나머지는 0이 들어갔다. soft labeling 방식은 batch내의 같은 상품을 찾기 위해 Input들의 catalog id를 확인해 같으면 1을 넣었다.
이때 catalog자체와 id는 downstream task중 하나인 clustering 과 matching을 활용해 만든거라 weakly supervised manner로 생성되었다.
1) 먼저 image feature , text feature 로 cosine similarity를 계산하여 를 생성한다.
2) 이후 learnable temperature 를 추가한 softmax 계산한다.
3) soft-labeling으로 생성한 를 곱해 cross-entropy loss를 계산한다.
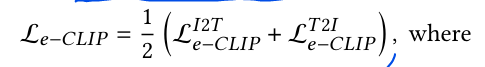
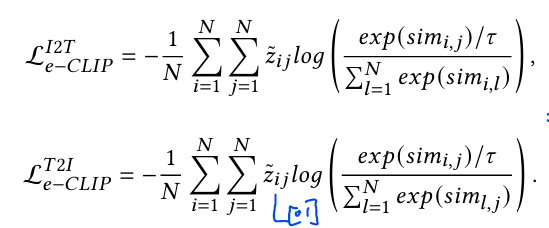
- Category-based negative sampling:
가지고있는 category 정보들로, 비슷한 카테고리로 구성된 batch를 만들 수 있다. 여기서 볼 수 있는 category-based hard negative들로부터 같은 category면 어떤 특징을 가지는지 비교할 수 있다.
이렇게 만든 모델을 transfer-learning에 활용할 수 있다.
근데 zero-shot transfer과정엔 fine-tuning 같은 과정이 안들어 가다보니 일부 zero-shot transfer에서 안좋은 결과가 나오기도 한다. 이는 충분히 data cleaning을 했지만 여전히 남아있는 noise 때문일 것이다.
3.3.3 Implementation Design
메모리 문제는 주로 contrastive loss의 NxN similarity matrix에 대한 gradient계산에서 나타나는데,
한정된 GPU에서 batch를 늘리기 위해 multiple forward passes를 이용한다.
- multi-stream accumulation:
gradient 계산시, 전체 similarity matrix에 대한 gradient 계산과 embedding에 대한 gradient 계산을 분리한다.
1) embeddings from each forward pass are concatenated, activation value들을 저장하지 않고 similarity matrix를 계산하는데 사용한다.
2) 각 local batch의 gradients를 계산할 때 앞에서 계산해 둔 similarity matrix와 model parameter를 활용한다.
이렇게 해서 학습 시간은 좀 느리지만 batch size를 30배 늘릴 수 있었다. - batch size scheduler:
모델이 빨리 converge하도록 적용한 convergence algorithm
Reducing gradient synchronization frequencies가 주로 학습을 가속하는데 활용돼서 learning rate scheduler 대신, batch size scheduler를 활용한다:
batch size를 늘리는게 learning rate를 줄이는 것과 같은 효과를 낸다는 연구결과가 있다.
Cosine annealing scheduler without restart와 같은 방식으로 batch scheduling이 들어갔다. 는 처음 batch size, 는 epoch수를 의미한다.
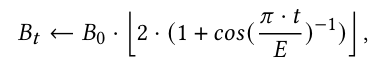
- mixed-precision:
GPU의 embedding들의 local batch에 필요한 pairwise similarity들의 subset만 계산함으로써 embedding similarity 계산 결과를 공유했다.
3.4 Downstream Tasks
pre-trained source model을 만들었으니 활용한다.
1. Product Clustering
2. Product Matching
3. Attribute Extraction
4. Category Classification
5. Adult Product Recognition
