딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드M
https://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM
2회차는 텍스트 마이닝편입니다.
목차
- Word2Vec - CBOW, SkipGram
- NN lanuguage model (NNLM)
- Glove
- FastText
- 사전훈련 모델(Pre-trained)
1. Word2Vec
지난시간에 봤던 정수 인코딩과 One-hot Encoding의 단점에서 시작해보자
정수 인코딩의 단점:
-> 단어 순서나 의미에 관계없이 등장횟수에 따라 1, 2, 3으로 encode하기 때문에 단어 사이의 연관성이 반영되지 않는다.
One-hot Encoding 단점:
-> 메모리를 많이 잡아 먹는다.
-> 정수 인코딩처럼 당연히 연관성 반영 x
-> 벡터 내에 0이 매우 많고, 1이 적은 Sparse Representation(희소 표현) 문제가 발생한다.
Sparse Representation(희소 표현) v.s. Dense Representation(밀집 표현)
- 벡터의 차원을 원하는 대로 설정한다.
- NN 기반 학습으로 W를 학습해 Sparse Representation에 많던 0들 대신에 다른 값들을 채워 넣는다.
https://soki.tistory.com/63
1) Continuous Bag Of Words (CBOW)
주변 단어를 통해 중간 단어를 예측 라벨링한다.
예를 들어
I studied hard for the exam 라는 문장이 있다. (토큰화, 정제 추출 생략)
중간 단어를 for 로 설정하면
주변 단어는 studied, hard, the, exam 이 된다. (2개만 본다면)
이제 주변단어를 Input으로 쓰고, 중간 단어를 Output으로 쓰는 NN을 구성한다.
https://paperswithcode.com/method/cbow-word2vec
Input layer -> Projection layer
4개의 주변단어들 평균을 구한다.
여기서 만들어진 이 중심 단어의 Dense Representation이 된다.
Projection layer -> Output layer
weight matrix를 곱해 output벡터를 만든다.
Output layer
NN의 Output layer에서 주로 사용하는 Softmax 함수를 이용한다.
Loss Function(Cross Entropy)
CE Loss를 계산한다.
2) Skip-Gram
CBOW와 반대로 중간 단어를 통해 주변단어를 라벨링한다.
https://paperswithcode.com/method/skip-gram-word2vec
모델 구조도 반대로 생겼다.
2. NN Language Model(NNLM)
지난 시간에 봤던 N-gram 방식을 활용한 NN
예문 : "what will the fat cat sit on"
https://wikidocs.net/45609
한계점:
- 정해진 길이만 보기 때문에 함축된 정보나, long-term 정보를 파악하기 어렵다.
- 문장 길이에 따른 한계점이 있다.
NNLM vs Word2Vec
- NNLM 은 앞의 단어로 다음 단어를 예측한다
- W2V 는 주변/중심 단어로 중심/주변 단어를 예측한다.
Word2Vec (CBOW, SkipGram)의 한계
: 단어수가 많아지면 중심-주변은 잘 아는데 그 밖에는 잘 모른다.
-> SkipGram with Negative Sampling (SGNS)로 선택된 임의의 두 단어가 중심-주변단어인지 맞추는 OX퀴즈 문제로 변형시킨다.
일반 SkipGram은
'중심 단어'-> Skip Gram -> '주변 단어'
를 예측하는 one-hot classification task 였다면
SGNS는
'중심 단어', '주변 단어'-> SGNS -> 중심-주변 관계일 확률
(1: 중심-주변 관계이다. 0: 아니다)
가 되서 binary classification task로 문제가 간단해 진다.
3. Glove
앞에서 봤던 Word2Vec이나 SGNS와 마찬가지로 효율적으로 word embedding을 만드는 알고리즘 중 하나이다.
우선 Co-Occurence Matrix 개념을 알아보자
한 단어 주변에 어떤 단어가 나왔는지 저장해둔 Matrix이다.
예를 들어
I like studying math , I enjoy studying math 두 문장이 있다.
가로 세로줄에 나온 단어들의 종류를 쭉 적고, 같은 단어는 0으로, 다른 단어는 옆에 등장한 횟수를 채워준다.
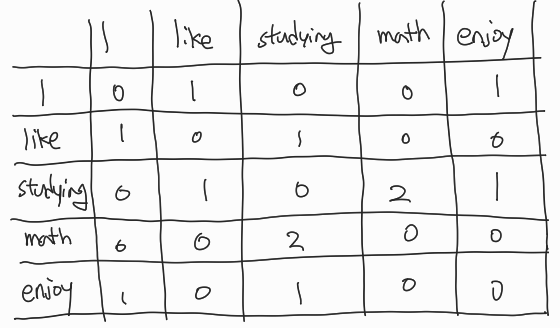
math 옆에 studying이 두 문장 모두 한번씩 등장하고 있기에 2를 넣어준다.
Glove는 이 표를 활용하여 (Co-Occurence Probability)확률과 해당 단어 벡터들의 내적을 연관지으려 하는 알고리즘이다.
: Co-occurence Matrix
: 중심 단어 embedding vector, : 주변단어 embedding vector
Loss function을 다음과 같이 정의한다.
여기서 와 는 중심 단어 후보이고, 가 주변 단어이므로 이 변수 3개가 주어졌을 때 함수 의 결과가 확률로 나온다고 가정하고
우변 확률항을 단어 k 가 주어졌을 때 i가 등장할, j가 등장할 조건부 확률로 썼다.
의 변수를 2개로 줄이기 위해 중심 단어 후보 2개의 차만 이용하자.
벡터 두개로 연산을 했는데 결과가 스칼라다? 이러면 내적이 떠오른다.
함수의 준동형성
를 함수의 준동형성을 이용해 찢어주면,
분자 분모가 같다고 하면,
를 로 둔다면,
i가 중심 단어, k가 주변 단어일 때, 이렇게 까지 정리 가능하다.
k가 중심 단어, i가 주변 단어일 때도 같은 결과가 나와야하니 교환법칙이 성립해야 한다.
라 문제 없지만 는 분명 다르다.-> bias를 더해주자.
항은 분모에 있던 에서 왔고, 항은 교환법칙을 고려해서 추가해준 항이다.
이제 사용하려는 Loss function을 넣어 backpropagation을 통해 NN을 학습시킬 수 있다.
문제점
1) 값이 발산하는 경우()
를 이용한다.
2) Co-occurence가 Sparse(0이 너무 많은) 경우:
-> Weighted Probability를 이용한다.
4. Fast Text
Facebook에서 개발한 W2V 알고리즘이다.
단어를 알파벳 단위까지 쪼갠 subword 개념을 도입한다; 글자 단위 N-gram
Ex) mouse -> 3-gram: <'mo', 'mou', 'ous', 'use', 'se'>
1 토큰이었던게 5개로 찢어졌다. 메모리 소모는 많아졌지만, 그만큼 장점이 존재한다.
1) Out Of Vocabulary (OOV)
하나의 데이터셋으로 세상에 존재하는 모든 단어를 학습할 순 없다.
-> 이 문제를 철자 단위로 학습시켜 모르는 단어도 얼추 찢어서 의미를 예측할 수 있다.
2) Rare Word
등장 빈도가 적은 단어들의 경우 전처리에서 제거되거나 학습하는 횟수가 적어 W2V에 안좋은 영향을 준다.
-> 마찬가지로 단어를 쪼개서 그 의미를 예상할 수 있다.
3) 오타
오타 때문에 세상에 존재하지 않는 단어를 보더라도 가장 비슷한 단어와 유사도가 가장 높을 것이기에 오타에도 강인하다.
5. 사전훈련 모델(Pre-trained)
지금까지 본 CBOW, Skip gram, Glove, Fast Text 등 다양한 모델들을 대규모 데이터로 미리 학습시킨 버전 뿐만 아니라 일부 도메인 특화 데이터셋으로 학습을 시킨 버전도 다운만 받아 쉽게 사용할 수 있는 사전 훈련 모델들이 존재한다.
우리는 다운받아 각 모델에 넣어줘야 하는 데이터 형식만 지켜서 아주 간단하게 해보고 싶은 Task에 적용시켜볼 수 있다.
총정리
NLP는 크게 보면,
토큰화 -> 정제 및 추출 -> 인코딩 -> 활용
단계로 진행되고 특히 이번에 인코딩을 어떻게 잘 하면 좋을지 제시한 다양한 알고리즘들도 알아보았고 여기까지 해서 NLP 기본 전처리 방법들을 알아보았다.
이 정도 수준으로 세상에 존재하는 수많은 단어들을 다 커버할 수 있을지 의문이 큰데, 요새 GPT나 각종 LLM들 실력을 보면 이후 강의에 등장할 Transformer가 도대체 어떤 마법을 부렸길래 NLP 수준을 그정도까지 끌어 올렸는지 새삼 문득 대단해진다..
