딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드M
https://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM
3회차는 지금까지 배웠던 전처리 실습입니다.
목차
- 토큰화
- 어간 추출, 표제어 추출
- 불용어 처리
- 정수 인코딩
- 유사도 분석
- CBOW/Skip gram 학습
- SGNS 학습시키기
1. 토큰화
다양한 토큰화 함수들 중 TreebankWordTokenizer를 사용해 보았다.
뒤에서 또 다른 토큰화 함수 등장 예정
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "T1 won world championship by 3:1 score"
print(tokenizer.tokenize(text))2. 어간 추출, 표제어 추출
어간추출 Stemmer
from nltk.stem import PorterStemmer, LancasterStemmer
stem1 = PorterStemmer()
stem2 = LancasterStemmer()
words = ['eat','ate','eaten','eating']
print('Porter',[stem1.stem(w) for w in words])
print('Lancaster',[stem2.stem(w) for w in words])Porter ['eat', 'ate', 'eaten', 'eat']
Lancaster ['eat', 'at', 'eat', 'eat']
표제어 추출 Lemmatizer
import nltk
from nltk import WordNetLemmatizer
nltk.download('wordnet')
lemm = WordNetLemmatizer()
words = ['eat','ate','eaten','eating']
print('wordNet Lemm',[lemm.lemmatize(w,pos='v') for w in words])wordNet Lemm ['eat', 'eat', 'eat', 'eat']
lemmatize 입력 변수로 pos에 v를 넣으면 동사, n을 넣으면 명사를 쪼개준다.
3. 불용어 처리
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
print(stopwords.words('english')[:5])
text = "hi how are you?"
word_tokens = tokenizer.tokenize(text)
stop_words = stopwords.words('english')
result = []
for w in word_tokens:
if w not in stop_words:
result.append(w)
print(word_tokens)
print(result)['hi', 'how', 'are', 'you', '?']
['hi', '?']
4. 정수 인코딩
vocab = {'apple':2,'July':6,'piano':4,'cup':8,'orange':1}
vocab_sort = sorted(vocab.items(),key=lambda x:x[1],reverse=True)
print(vocab_sort)
word2idx = {word[0]:index+1 for index,word in enumerate(vocab_sort)}
print(word2idx)[('cup', 8), ('July', 6), ('piano', 4), ('apple', 2), ('orange', 1)]
{'cup': 1, 'July': 2, 'piano': 3, 'apple': 4, 'orange': 5}
빈도가 주어졌다고 치고, 가장 많이 나온게 1, 2, 3 순서대로 인코딩 된다.
5. 유사도
코사인 유사도
import numpy as np
def cos_sim(A,B):
return np.dot(A,B)/(np.linalg.norm(A)*np.linalg.norm(B))
a = [1,0,0,1]
b=[0,1,1,0]
c=[1,1,1,1]
print(cos_sim(a,b),cos_sim(b,c),cos_sim(c,a))0.0 0.7071067811865475 0.7071067811865475
레반슈타인 거리
def leven(text1,text2):
len1 = len(text1)+1
len2 = len(text2)+1
sim_array = np.zeros((len1,len2))
sim_array[:,0] = np.linspace(0,len1-1,len1)
sim_array[0,:] = np.linspace(0,len2-1,len2)
for i in range(1,len1):
for j in range(1,len2):
add_char = sim_array[i-1,j]+1
sub_char = sim_array[i,j-1]+1
if text1[i-1] == text2[j-1]:
mod_char = sim_array[i-1,j-1]
else:
mod_char = sim_array[i-1,j-1]+1
sim_array[i,j] = min([add_char,sub_char,mod_char])
return sim_array[-1,-1]
print(leven('데이터마이닝','데이타마닝'))2.0
6. CBOW/Skip gram 학습
https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews?resource=download
IMDB 영화 리뷰 데이터셋을 활용하였다.
먼저 전처리 과정을 거쳐 준다
1) 토큰화를 해 주고
import pandas as pd
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
data=pd.read_csv('C:/nlp_datas/IMDB Dataset.csv')
print('missing Values: ',data.isnull().sum())
merge_data = ''.join(str(data.iloc[i,0]) for i in range(500))
print('Total word count:', len(merge_data))missing Values: review 0 sentiment 0
dtype: int64
Total word count: 681583
Review에 실제 평가 문장, sentiment에 긍정/부정 인지 적혀있기에 Review 열만 사용할 예정이다.
2) 불용어를 없애주고
tokenizer = RegexpTokenizer('[\w]+')
token_text = tokenizer.tokenize(merge_data)
stop_words = set(stopwords.words('english'))
token_stop_text = []
for w in token_text:
if w not in stop_words:
token_stop_text.append(w)
print('After cleaning:', len(token_stop_text))After cleaning: 70257
3) 빈도수 셀 겸 중복인 단어를 없애주고
word2idx={}
Bow=[]
for word in token_stop_text:
if word not in word2idx.keys():
word2idx[word] = len(word2idx)
Bow.insert(len(word2idx)-1,1)
else:
idx = word2idx.get(word)
Bow[idx] +=1
print('Unique Words Count: ',len(Bow))Unique Words Count: 14216
4) 실제 학습
리스트 형태였던 토큰들을 np array로 바꿔주고,
gensim 라이브러리에서 제공하는 Word2Vec 모델에
- 각 단어당 임베딩 벡터 길이(
vector_size): 100, - Skip gram의 hyperparameter인 어느 범위까지 참조할 건지(
window): 5, - 양 끝쪽에 참조할게 적어져 생략할 범위를 정하는(
min_count): 2, - skipgram을 쓸건지, cbow를 쓸건지(
sg): 0 -> CBOW/ 1-> Skipgram
import numpy as np
token_stop_text = np.reshape(np.array(token_stop_text),[-1,1])
from gensim.models import Word2Vec
model = Word2Vec(vector_size = 100, window = 5, min_count=2, sg=0)
model.build_vocab(token_stop_text)
model.train(token_stop_text,total_examples=model.corpus_count,epochs= 30)
vocabs = model.wv.key_to_index.keys()
word_vec_list = [model.wv[i] for i in vocabs]5) PCA로 시각화
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pcafit = pca.fit_transform(word_vec_list)
x = pcafit[:50,0]
y = pcafit[:50,1]
import matplotlib.pyplot as plt
plt.scatter(x,y,marker='o')
for i,v in enumerate(vocabs):
if i<=49:
plt.annotate(v,xy=(x[i],y[i]))
plt.show()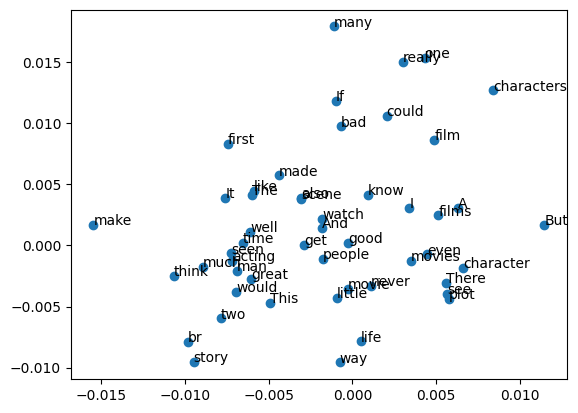 좋은거만 좀 봐보면 life, way 비슷한 느낌이니 같이 있고, One many 가 비슷하게 위쪽에 위치했다.
좋은거만 좀 봐보면 life, way 비슷한 느낌이니 같이 있고, One many 가 비슷하게 위쪽에 위치했다.
7. SGNS 학습시키기
똑같이 전처리를 해준다.
import pandas as pd
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
data=pd.read_csv('C:/nlp_datas/IMDB Dataset.csv')
print('missing Values: ',data.isnull().sum())
merge_data = ''.join(str(data.iloc[i,0]) for i in range(200))
print('Total word count:', len(merge_data))
tokenizer = RegexpTokenizer('[\w]+')
token_text = tokenizer.tokenize(merge_data)
stop_words = set(stopwords.words('english'))
token_stop_text = []
for w in token_text:
if w not in stop_words:
token_stop_text.append(w)
print('After cleaning:', len(token_stop_text))SGNS는 단어 두개가 이웃한지 여부를 이용하는 알고리즘이니,
이 형태의 데이터 셋을 만들기 위해 Tensorflow에서 제공하는 Tokenizer과 skipgrams를 사용한다.
(근데 tensorflow 설치가 안돼서 일단 급하게 소스코드를 복사하여 사용했다)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(token_stop_text)
word2idx = tokenizer.word_index
encoded = tokenizer.texts_to_sequences(token_stop_text)
encoded = np.array(encoded).T
skip_gram = [skipgrams(sample,vocabulary_size = len(word2idx)+1,window_size = 10)for sample in encoded]skip_gram안에는 단어 인덱스가 두개씩 묶인 쌍들이 저장된다. 그리고 두 숫자가 이웃해 있는지 여부가 뒤쪽에 저장된다.
[[[[1,2],[2,3]...],[1,1,0,0,...]]]import torch
import torch.nn as nn
from torch import LongTensor as LT
from torch import FloatTensor as FT
class Word2Vec(nn.Module):
def __init__(self,vocab_size,embed_size):
super(Word2Vec,self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
self.word1_vector = nn.Embedding(self.vocab_size,self.embed_size)
self.word2_vector = nn.Embedding(self.vocab_size,self.embed_size)
self.word1_vector_weight = nn.Parameter(torch.cat([torch.zeros(1,self.embed_size),FT(self.vocab_size-1,self.embed_size).uniform_(-0.1,0.1)]))
self.word2_vector_weight = nn.Parameter(torch.cat([torch.zeros(1,self.embed_size),FT(self.vocab_size-1,self.embed_size).uniform_(-0.1,0.1)]))
self.word1_vector.weight.requires_grad = True
self.word2_vector.weight.requires_grad = True
def forward_word1(self,data):
vec = LT(data)
vec = vec.cuda() if self.word1_vector.weight.is_cuda else vec
return self.word1_vector(vec)
def forward_word2(self,data):
vec = LT(data)
vec = vec.cuda() if self.word2_vector.weight.is_cuda else vec
return self.word2_vector(vec)단어 두개의 임베딩을 뽑아주는 Word2Vec class를 정의한다.
class SGNS(nn.Module):
def __init__(self,embed,vocab_size):
super(SGNS,self).__init__()
self.embed = embed
self.vocab_size = vocab_size
self.weights = None
def forward(self,word1, word2, label):
soft = 1e-9
word1 = self.embed.forward_word1(word1).unsqueeze(1)
word2 = self.embed.forward_word2(word2).unsqueeze(2)
label = LT(label).unsqueeze(1)
prediction = torch.bmm(word1, word2).squeeze(2).sigmoid()
pr1 = prediction.log()
pr0 = (1-prediction+soft).log()
loss = -label*pr1-(1-label)*pr0
return loss.mean()SGNS 모델 class를 정의한다.
각 단어 임베딩은 (Batch,100) 형태를 가질 텐데 여기서 해야하는 연산은
이므로 unsqueeze 함수를 이용해
word1의 shape은 (Batch,1,100)
word2의 shape은 (Batch,100,1)로 만들어
(1,100) x (100,1) 연산결과로 (1x1)을 얻어낸다.
; torch.bmm을 결과로 (Batch,1,1)의 결과가 나오는데, 1하나를 squeeze해준다.
이후 시그모이드에 로그확률 형태로 만들어
loss function은 binary cross entropy 모양을 그대로 가져왔다.
Adam쓸 예정이고, 필요한 word2vec 리스트, 모델을 정의해 준다.
from torch.optim import Adam
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdm
vocab_size = len(word2idx)+1
word2vec = Word2Vec(vocab_size=vocab_size,embed_size=100)
sgns = SGNS(embed = word2vec, vocab_size = vocab_size)
optim = Adam(sgns.parameters())데이터 로더를 정의할 건데,
skip_gram 변수엔 [[[idx1, idx2],... , [1,0,...]]] 구조로 되어있다.
element[0]에 해당하는게 숫자 인덱스 쌍들 [[idx1,idx2],[1,2]...]
element[1]에 해당하는게 라벨값 [1,0,...]
word1에 기준 인덱스, word2에 근처인지 비교할 인덱스, label에 이웃한지 를 저장한다.
for _,element in enumerate(skip_gram):
word1 = LT(np.array(list(zip(*element[0]))[0],dtype='int32'))
word2 = LT(np.array(list(zip(*element[0]))[1],dtype='int32'))
label = LT(np.array(element[1],dtype='int32'))
dataset = TensorDataset(word1,word2,label)
train_loader = DataLoader(dataset, batch_size=256, shuffle=True) 학습
for epoch in range(5):
with tqdm(train_loader) as tepoch:
for word1, word2, label in tepoch:
loss = sgns(word1, word2,label)
optim.zero_grad()
loss.backward()
optim.step()
tepoch.set_description(f"Epoch {epoch}")
tepoch.set_postfix(loss = loss.item())Epoch 0: 100%|██████████| 4346/4346 [01:15<00:00, 57.89it/s, loss=3.33]
Epoch 1: 100%|██████████| 4346/4346 [01:14<00:00, 58.42it/s, loss=2.64]
Epoch 2: 100%|██████████| 4346/4346 [01:17<00:00, 56.14it/s, loss=1.71]
Epoch 3: 100%|██████████| 4346/4346 [01:31<00:00, 47.28it/s, loss=1.4]
Epoch 4: 100%|██████████| 4346/4346 [01:45<00:00, 41.14it/s, loss=0.806](5 에폭에 데이터도 많이 안써서 loss값이 형편없다.)
각 단어 인덱스를 받으면 sgns내에서 그 단어에 해당하는 임베딩들을 만들기 시작할 것이고, loss function 왔다갔다 하면서 업데이트 할 것이다.
결과 확인을 위해 임베딩값들을 저장해 준다.
import gensim
with open("C:/nlp_datas/vectors.txt",'w') as f:
ww=0
f.write('{} {}\n'.format(7500,100))
vectors = word2vec.word1_vector.weight.detach().numpy()
for i , v in enumerate(word2idx.keys()):
try:
f.write('{} {}\n'.format(v, ' '.join(map(str,list(vectors[i+1,:])))))
ww+=1
except:
continue
embed_word2vec = gensim.models.KeyedVectors.load_word2vec_format("C:/nlp_datas/vectors.txt",)마지막 줄에 이제 gensim 라이브러리를 활용해 비슷한 단어가 뭐가 있는지 보기위해 로드해 준다.
embed_word2vec.most_similar(positive = ['enjoy']) ('nights', 0.3993881344795227),
('great', 0.36998695135116577),
('fight', 0.35548287630081177),
('follow', 0.3486346900463104),
('i', 0.3483388423919678),
('the', 0.34802910685539246),
('parts', 0.3476596772670746),
('promise', 0.347569078207016),
('correct', 0.3447914719581604)]예시로 enjoy와 비슷한 단어를 찍어보니 이렇게 나온다.
아무래도 영화리뷰이다 보니 movie라는 단어가 워낙 많이 있을 거라 movie와의 유사도가 높은것 같고, great, fight는 나름 연관성이 있어보이긴 한다.
학습을 더 시켜보면 좋은 결과가 나올 것 같긴 하다.
총정리
실제로 전처리부터 간단한 인코딩 알고리즘들을 돌려보니 NLP에 대해 감이 잡히는듯 안잡히는듯 아직 그렇다.
그래도 NLP를 몰랐을 때 보단 실제 코드로 실습도 하고 하니 뭔가 해볼 순 있겠다는 자신감은 생긴다.
지금까지 본건 사실상 현재 NLP에서 안쓰이는 기법들일 거고,
앞으로 RNN Attention Transformer를 볼 텐데 얼마나 성능향상이 있을지 기대된다.
