
위 주제는 밑바닥부터 시작하는 딥러닝2 2강, CS224d를 바탕으로 작성한 글 입니다.
도입
NLP (Natural Language Processing, 자연어처리)는 텍스트에서 의미있는 정보를 분석, 추출하고 이해하는 일련의 기술이다.
이러한 NLP를 활용하기 위하여 컴퓨터에게 단어의 의미를 이해시키는 것이 중요하다. 이러한 컴퓨터에게 자연어를 이해시키는 방법은 크게 3가지가 존재한다.
- 시소러스를 활용한 기법
- 통계 기반 기법
- 추론 기반 기법(word2vec)
시소러스
시소러스란 기본적으로 유의어 사전으로, '동의어'나 '유의어'가 한 그룹으로 분류되어 있다. 또한 자연어 처리에 이용되는 시소러스에서는 단어 사이의 '상위와 하위' 혹은 '전체와 부분'등, 더 세세한 관계까지 정의해둔 경우가 있다. 이를 활용한 모델은 WordNet이 있다.
'단어 네트워크'를 이용하여 컴퓨터에게 단어 사이의 관계를 가르칠 수 있다. 'automobile'과 'car'가 유의어임을 알고 있으면 'car'의 검색 결과에 'automobile'의 검색 결과도 포함시켜주면 된다. ( 'car' == 'automobile')
시소러스의 문제점
1. 시대 변화에 대응하기 어렵다. '크라우드 펀딩'과 같은 신조어나 단어의 의미가 변하는 경우가 있다.
2. 수동적으로 하여 사람의 노동력이 많이 필요하다. (WordNet에 등록된 단어는 20만개 이상 현존하는 영어 단어의 수는 1000만개 이상)
이미지, 자연어 처리 모두 처음에는 수동으로 feature을 뽑아내곤 했는데 이제는 딥러닝 기술을 활용하여 컴퓨터가 스스로 학습한다.
3. 단어의 미묘한 차이를 알기 어렵다.
이 문제를 피하기 위해 대량의 텍스트 데이터에서 단어의 의미를 자동으로 추출하는 '통계 기반 기법'과 신경망을 사용한 '추론 기반 기법'이 있다.
통계 기반 기법
말뭉치는 자연어 처리 연구나 애플리케이션을 염두해두고 수집된 대량의 텍스트 데이터를 말한다(ex. Wikipedia, Google News). 통계 기반 기법의 목표는 말뭉치에서 자동으로, 효율적으로 핵심을 추출하는 것을 말한다.
파이썬으로 말뭉치 전처리하기
텍스트 데이터를 단어로 분할하고 그 분할된 단어들을 ID목록으로 변환
Preprocess() 만들기
text = 'You say goodbye and I say hello.'text = text.lower() # 모든 문자를 소문자로 변환
text = text.replace('.',' .') # '.'를 ' .'로 변환
text # 'you say goodbye and i say hello .'
words = text.split(' ')
words # ['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']단어에 ID 부여하고, ID의 리스트로 이용할 수 있도록 하기
word_to_id ={}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
id_to_word # {0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'}
word_to_id # {'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}corpus = [word_to_id[w] for w in words]
corpus = np.array(corpus)
corpus # array([0, 1, 2, 3, 4, 1, 5, 6])
#['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']단어의 벡터 표현
전처리된 말뭉치를 사용해 '단어의 의미'를 추출해보자. 이에는 벡터 표현이 들어간다. 단어를 벡터로 표현하는 것을 분산 표현이라 한다.
분포 가설은 '단어의 의미는 주변 단어에 의해 형성된다'는 것을 의미하며 이는 단어가 사용된 '맥락'이 의미를 형성한다는 것이다.

윈도우 크기를 맥락의 크기라하는데 1이면 좌우 한 단어씩, 2이면 좌우 두 단어씩을 포함한다.
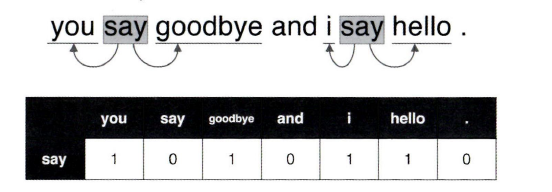
단어 "say"의 맥락에 포함되는 단어의 빈도를 표로 정리
def create_co_matrix(corpus, vocab_size, window_size=1):
#corpus array([0, 1, 2, 3, 4, 1, 5, 6])
#vocab_size는 행렬의 사이즈
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i #window사이즈 지정
right_idx =idx + i
if left_idx >=0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix
# [[0 1 0 0 0 0 0]
# [1 0 1 0 1 1 0]
# [0 1 0 1 0 0 0]
# [0 0 1 0 1 0 0]
# [0 1 0 1 0 0 0]
# [0 1 0 0 0 0 1]
# [0 0 0 0 0 1 0]]벡터 간 유사도
벡터 사이의 유사도 측정에는 내적, 유클리드 거리를 생각할 수 있지만 대표적으로 단어의 벡터에는 코사인 유사도를 자주 이용한다. (두 벡터가 가리키는 방향이 얼마나 비슷한가)
x = (x1, x2, x3, ...)
y = (y1, y2, y3, ...)
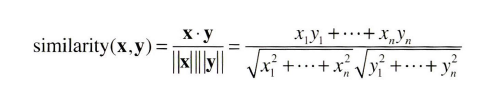
def cos_similarity(x, y, eps=1e-8):
nx = x / np.sqrt(np.sum(x**2) + eps ) #x의 정규화
ny = y / np.sqrt(np.sum(y**2) + eps) #y의 정규화
return np.dot(nx, ny)text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
c0 = C[word_to_id['you']] # array([0, 1, 0, 0, 0, 0, 0])
c1 = C[word_to_id['i']] # array([0, 1, 0, 1, 0, 0, 0])
print(cos_similarity(c0, c1)) # 0.7071067691154799 "you"와 "i"의 유사도 1과 가까울수로 유사성 크다.랭킹 표시
- 검색어의 단어 벡터를 꺼낸다.
- 검색어의 단어 벡터와 다른 모든 단어 벡터와의 코사인 유사도를 계산한다.
- 계산한 코사인 유사도 결과를 기준으로 값이 높은 순서대로 출력
def most_similar(query, word_to_id, id_to_word, word_matrix, top=5):
# query 검색어를 꺼낸다
if query not in word_to_id:
print('%s(을)를 찾을 수 없습니다.' %query)
return
print('\n[query]' + query)
query_id = word_to_id[query] # you니까 "1"
query_vec = word_matrix[query_id] # 1행 [0 1 0 0 0 0 0]
# 코사인 유사도 계산
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size) # [0, 0, 0, 0, 0, 0, 0]
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
# 코사인 유사도를 기준으로 내림차순으로 출력
count = 0
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s: %s' %(id_to_word[i], similarity[i]))
count += 1
if count >= top:
return 결과 'you'에 가장 가까운 단어는 3개, 'i'와 비슷한 것은 납득이 가지만
'goodbye'와 'hello'의 코사인 유사도가 높다는 것은 직관과는 거리가 멀다. 원인은 말뭉치의 크기가 너무 작기 때문이다.
result
[query] you
goodbye: 0.7071067691154799
i: 0.7071067691154799
hello: 0.7071067691154799
say: 0.0
and: 0.0
통계 기반 기법 개선
the, a 같은 경우에는 형식적으로 많이 쓰여서 실제로 관련성이 떨어져도 동시 발생 값이 높아져서 관련성이 높게 나올 수 있다. 예를 들어서 car, drive의 관계보다 car, the의 관계가 더 높게 나타날 수 있는데 이를 방지하는 방법이 점별 상호정보량, PMI(pointwise mutual information)다.
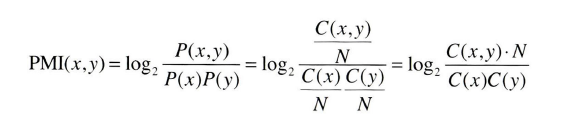
p(x)는 corpus에서 단어 x가 등장할 확률을 의미한다. the처럼 전체적인 곳에서 많이 발생한다면 분모가 너무 커져 PMI값이 매우 낮아질 것이고, 동시 발생 확률 p(x,y)가 커지면 log값이 커져서 PMI가 높아질 것이다. 즉, 더욱 더 문맥에 맞는 단어 벡터를 얻을 수 있다.
동시발생 횟수가 0인경우에는 log값이 음의 극한으로 가기 때문에, 이를 피하기 위해 PMI가 음수일 때는 0으로 취급하는 양의 상호정보량(PPMI)를 사용한다.
def ppmi(C, verbose=False, eps=1e-8):
#verbose = True 중간 진행상황 출력
M = np.zeros_like(C, dtype=np.float32)
N = np.sum(C) 14
S = np.sum(C, axis=0) # 각열의 빈도 수 [1 4 2 2 2 2 1]
print(N)
print(S)
total = C.shape[0] * C.shape[1]
cnt = 0
for i in range(C.shape[0]):
for j in range(C.shape[1]):
pmi = np.log2(C[i, j] * N / (S[j]*S[i]) + eps)
M[i, j] = max(0, pmi)
if verbose:
cnt += 1
if cnt % (total//100) == 0:
print('%.1f%% 완료' % (100*cnt/total))
return Mtext = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
W = ppmi(C)
np.set_printoptions(precision=3) # 유효 자릿수를 세 자리로 표시
print('동시발생 행렬')
print(C)
print('-'*50)
print('PPMI')
print(W)
result
goodbye: 0.40786147117614746
i: 0.40786147117614746
hello: 0.2763834297657013
say: 0.0
and: 0.0
차원 감소
PPMI 행렬도 문제가 있는데, 쓸모없는 메모리가 낭비된다는 단점이 있다. 이를 개선하기 위해서 차원을 축소하는 방법을 사용한다.
데이터의 분포를 고려하여 중요한 축을 찾고 그 축으로 사영된 값으로 바꾼다.
희소벡터Sparse vector에서 중요한 축을 찾아내어 더 적은 차원으로 다시 표현하다보면 희소벡터는 원소 대부분이 0이 아닌 '밀집벡터Dense vector'으로 변환된다.
차원을 감소하는 방법에는 singular vector decomposition SVD를 사용한다. 행렬을 세 행렬의 곱으로 분해한다.(X=USV^t)

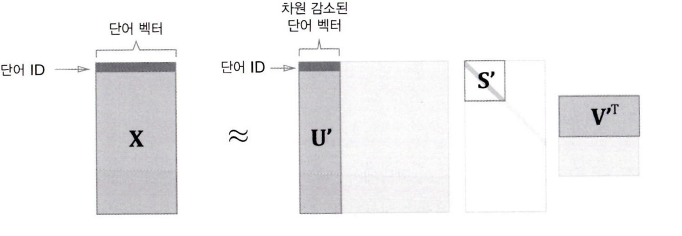
차원 감소에 대한 자세한 내용은 다음 글에서 자세하게 설명한다. ( 이해하기 힘든건 안비밀 )
import matplotlib.pyplot as plt
from common.util import preprocess, create_co_matrix, ppmi
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(id_to_word)
C = create_co_matrix(corpus, vocab_size, window_size=1)
W = ppmi(C)
# SVD
U, S, V = np.linalg.svd(W)
print(C[0]) # 동시발생 행렬 [0 1 0 0 0 0 0]
print(W[0]) # PPMI 행렬 [0. 1.807 0. 0. 0. 0. 0. ]
print(U[0]) # SVD [-3.409e-01 -1.110e-16 -3.886e-16 -1.205e-01 0.000e+00 9.323e-01 2.226e-16]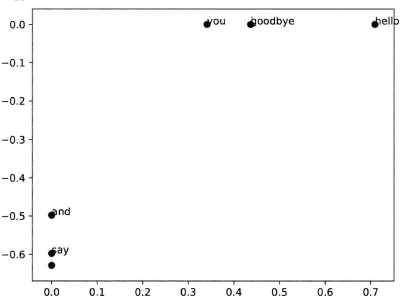
적용 (PTB dataset)
PTB 말뭉치는 word2vec의 발명자인 Tomas Mikolov의 웹페이지에서 받을 수 있다. 텍스트 파일로 제공된다.

각 문장을 '하나의 큰 시계열 데이터'로 취급한다.

큰 행렬에 SVD를 적용해야 하므로 고속 SVD를 이용해보자, Sklearn 모듈을 설치해 사용한다.
try:
# truncated SVD (빠르다!)
from sklearn.utils.extmath import randomized_svd
U, S, V = randomized_svd(W, n_components=wordvec_size, n_iter=5,
random_state=None)
except ImportError:
# SVD (느리다)
U, S, V = np.linalg.svd(W)결과를 출력해서 보면 우선 "you"라는 검색어에서는 인칭대명사인 "i"와 "we"가 상위를 차지했다. "year"의 연관어는 "month" "quarter", "car"의 연관어로는 "auto"와 "vehicle"등이 뽑혔다. 이렇듯 우리의 직관과 비슷한 결과라고 할 수 있다.
