
위 주제는 밑바닥부터 시작하는 딥러닝2 3강, CS224d를 바탕으로 작성한 글 입니다.
추론 기법
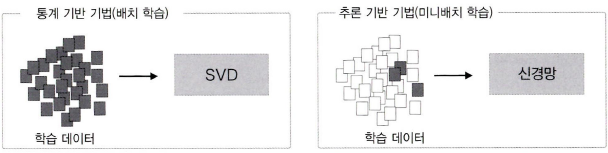
이전에 '통계 기반 기법'에 대해서 다루어 보았는데 이번에는 통계 기반 기법의 문제를 지적하고, 그 대안인 추론 기반 기법의 이점을 설명한다.
통계 기반 기법의 문제점
통계 기반 기법의 문제는 어마어마한 말뭉치의 어휘수의 처리에서 발생한다. 어휘가 100만 개라면, '100만*100만'이라는 거대한 행렬을 만든다.
SVD를 n*n행렬에 적용하는 비용은 O(n^3)이다. 상당한 컴퓨팅 자원을 들여 장시간 계산해야 하는 단점이 있다.
추론 기반 기법은 학습 데이터의 일부를 사용하여 순차적으로 학습한다.
추론 기반 기법 개요
말 그대로 Window_size의 정보를 입력받아 각 단어의 출현 확률을 출력해준다. 그 학습의 결과로 단어의 분산 표현을 얻는 것이 추론 기반 기법의 전체 그림이다.
신경망에서의 단어 처리
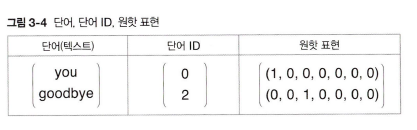
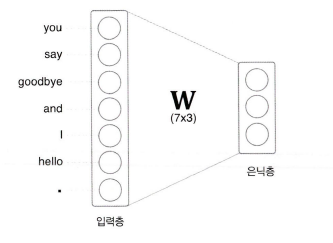
신경망을 이용해 '단어'를 처리한다. 단어를 '고정 길이의 벡터'로 변환하기 위해, 원핫 벡터를 사용하여 변환한다.
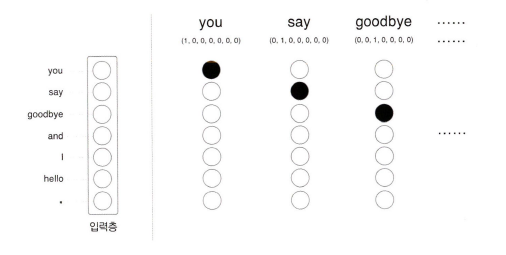
입력층의 뉴런은 총 7개이다. 이 7개의 뉴런은 차례로 7개의 단어들에 대응한다.
import numpy as np
c = np.array([[1, 0, 0, 0, 0, 0, 0]]) # 입력
W = np.random.randn(7, 3) # 가중치
h = np.matmul(c, W) # 중간 노드
print(h) # [[-1.8292028 -1.21867646 0.05741966]]c는 원핫 표현이므로 단어 ID에 대응하는 원소만 1이고 그 외에는 0인 벡터이다. 따라서 h는 가중치의 행벡터 하나를 '뽑아낸' 것과 같다.
가중치로부터 행벡터를 뽑아낼 뿐인데 행렬 곱을 계산하는건 비효율적이다.
c = np.array([[1, 0, 0, 0, 0, 0, 0]]) # 입력
W = np.random.randn(7, 3) # 가중치
layer = MatMul(W)
h = layer.forward(c)
print(h)단순한 word2vec
'모델'을 신경망으로 구축하는 방법에는 2가지가 있다.
- CBOW
- skip-gram
이번에 사용할 모델은 CBOW모델이다.
CBOW와 skip-gram의 차이는 후에 설명한다.
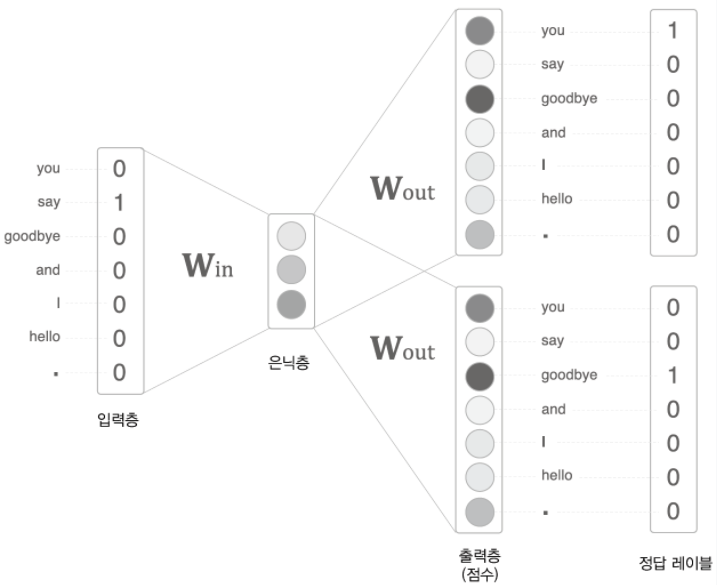
CBOW 모델의 추론 처리
CBOW 모델은 맥락으로부터 타깃을 추측하는 용도의 신경망이다('타깃'은 중앙 단어이고 그 주변 단어들이 '맥락'이다).
-
맥락을 원핫 표현(one-hot)으로 변환하여 CBOW 모델이 처리할 수 있도록 준비한다.
-
가중치 W는 7*3 행렬이며, 단어의 분산 표현이 담겨 있다고 볼 수 있다.
-
학습을 진행할수록 맥락에서 출현하는 단어를 잘 추측하는 방향으로 분산 표현들이 갱신될 것이다.
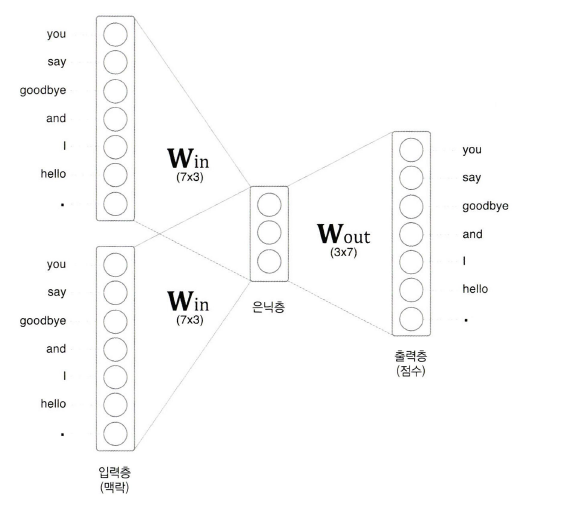
이 그림에서 입력층이 2개인 이유는 맥락으로 고려할 단어를 2개로 정했기 때문이다. 즉, 맥락에 포함시킬 단어가 N개라면 입력층도 N개가 되어야한다.
-
은닉층의 뉴런은 입력층의 완전연결계층에 의해 변환된 값이 되는데, 입력층이 여러 개이면 전체를 '평균'하면 된다.
계층 관점에서 본 CBOW 모델의 신경망 구성 입력층이 2개이기 때문에 (h1+h2)/2로 평균값을 구한다.
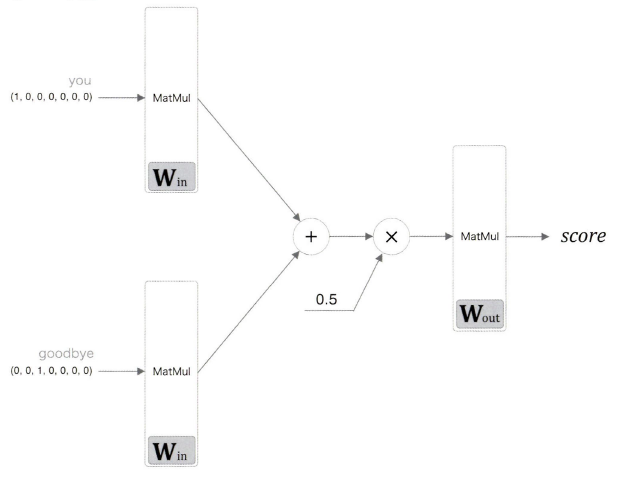
보앗듯이 CBOW 모델은 활성화 함수를 사용하지 않는 간단한 구성의 신경망이다.
은닉층의 뉴런 수를 입력층의 뉴런 수보다 적게 하는 것이 중요한 핵심! 은닉층에 단어 예측에 필요한 정보를 '간결하게' 담게 되며, 결과적으로 밀집벡터 표현을 얻을 수 있다. 이는 '인코딩'에 해당한다.
# 샘플 맥락 데이터
c0 = np.array([[1, 0, 0, 0, 0, 0, 0]])
c1 = np.array([[0, 0, 1, 0, 0, 0, 0]])
# 가중치 초기화
W_in = np.random.randn(7, 3)
W_out = np.random.randn(3, 7)
# 계층 생성
in_layer0 = MatMul(W_in)
in_layer1 = MatMul(W_in)
out_layer = MatMul(W_out)
# 순전파
h0 = in_layer0.forward(c0)
h1 = in_layer1.forward(c1)
h = 0.5 * (h0 + h1)
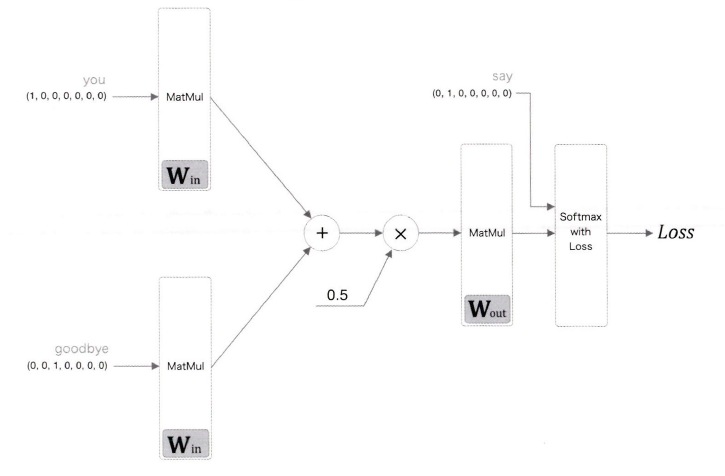
s = out_layer.forward(h)
print(s) # [[-1.59756613 1.91167236 1.19265239 0.47494206 1.32799998 -0.99693663, 2.16783]]CBOW 모델의 학습
전에 각 단어의 점수를 출력하였는데, 이 점수에 소프트 맥스 함수를 적용하면 '확률'을 얻을 수 있다. 이 확률은 맥락(전후 단어)가 주어졌었을 때 그 중앙에 어떤 단어가 출현하는지를 나타낸다. 'you'와 'goodbye' 사이에는 'say'가 나와야한다.
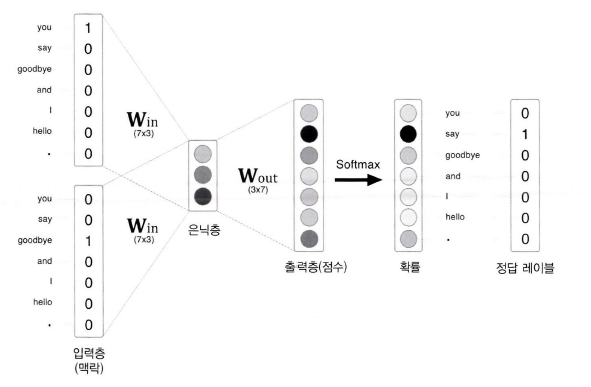
이 신경망을 학습하려면 소프트맥스와 교차 엔트로피 오차만 이용하면 된다. 소프트맥스 함수를 이용해 점수를 확률로 바꾸고, 그 확률과 점수 레이블로부터 교차 엔트로피 오차를 구한 후, 그 값을 손실로 사용해 학습을 진행한다.
word2vec의 가중치와 분산 표현
입력 측 가중치의 각 행이 각 단어의 분산 표현에 해당한다. 출력 측 가중치에도 단어의 의미가 인코딩된 벡터가 저장되고 있다고 생각할 수 있다. 다만, 출력 측 가중치는 단어의 분산 표현이 열방향으로 저장된다.
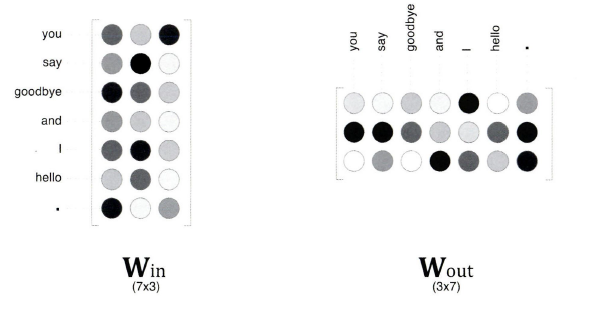
그렇다면 최종적으로 이용하는 단어의 분산 표현으로는 어느 쪽 가중치를 선택하는 것이 좋을까?
1. 입력 측의 가중치
2. 출력 측의 가중치
3. 양쪽 가중치 모두 이용
word2vec(특히 skip-gram 모델)에서는 '입력 측의 가중치만 이용한다'가 가장 대중적인 선택이다.
맥락과 타깃

맥락과 타깃을 작성하는 함수
def create_contexts_target(corpus, window_size=1):
target = corpus[window_size:-window_size]
contexts = []
for idx in range(window_size, len(corpus)-window_size):
cs = []
for t in range(-window_size, window_size + 1):
if t == 0:
continue
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)contexts[0]에는 0번째 맥락이 저장되고, contexts[1]에는 1번째 맥락이 저장된다. target도 같은 방식.
원핫 표현으로 변환
말뭉치로부터 맥락과 타깃을 만들어냈는데, 이 맥락과 타깃의 각 원소를 원 핫 표현으로 변환해야 한다.

def convert_one_hot(corpus, vocab_size):
'''
:param corpus: 단어 ID 목록(1차원 또는 2차원 넘파이 배열)
:param vocab_size: 어휘 수
:return: 원핫 표현(2차원 또는 3차원 넘파이 배열)
'''
N = corpus.shape[0]
if corpus.ndim == 1:
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
elif corpus.ndim == 2:
C = corpus.shape[1]
one_hot = np.zeros((N, C, vocab_size), dtype=np.int32)
for idx_0, word_ids in enumerate(corpus):
for idx_1, word_id in enumerate(word_ids):
one_hot[idx_0, idx_1, word_id] = 1
return one_hotCBOW 구현
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# 계층 생성
self.in_layer_0 = MatMul(W_in)
self.in_layer_1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
# 모든 가중치와 기울기를 리스트에 모은다.
layers = [self.in_layer_0, self.in_layer_1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
def forward(self, contexts, target):
h0 = self.in_layer_0.forward(contexts[:, 0])
h1 = self.in_layer_1.forward(contexts[:, 1])
h = (h0 + h1) * 0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer_1.backward(da)
self.in_layer_0.backward(da)
return None입력 측의 MatMul 계층을 2개(윈도우 크기 만큼 생성), 출력 측의 MatMul 계층을 하나, 그리고 Softmax with Loss 계층을 하나 생성한다.
위의 예에서는 context 배열의 형상은 (6, 2, 7)이 된다. 0번째 차원의 원소 수는 미니배치의 수만큼이고, 1번째 차원의 원소 수는 맥락의 윈도우 크기, 2번째 차원은 원핫 벡터를 의미한다.
target의 형상은 (6, 7)과 같은 형상이 된다.
후에 역전파를 통해서 grads의 기울기를 갱신하면 된다.
학습
CBOW 모델의 학습은 일반적인 신경망의 학습과 완전히 같다.
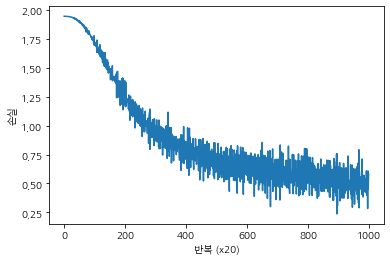
학습 경과를 그래프로 표시한 것인데, 보다시피 학습을 거듭할수록 손실이 줄어드는 것을 알 수 있다. 학습이 끝난 후 가중치의 매개변수는
you - [ 0.93948716 1.1471828 0.9876904 -1.5107943 -0.9072483 ]
say - [-1.2550594 -0.33916035 -1.2577727 -0.15432052 1.2682257 ]
goodbye - [ 1.0768011 0.69896984 1.0905025 -0.17019284 -1.0796039 ]
and - [-1.0884993 -1.5440016 -1.1070035 1.603704 1.11817 ]
i - [ 1.0628144 0.6580432 1.08559 -0.1830638 -1.0735143]
hello - [ 0.9399647 1.1701053 0.9819399 -1.5028169 -0.9213758]
. - [-1.0079472 1.4644911 -0.9318077 -1.3403562 1.0558087]
말뭉치가 적기 때문에 좋은 결과를 얻지 못했다.
CBOW 모델과 확률
확률 표기법
동시 확률 : P(A , B) - A와 B가 동시에 일어날 확률
사후 확률 : P(A | B) - B(라는 정보)가 주어졌을 때 A가 일어날 확률
말뭉치를 w1,w2, ... ,wr 처럼 단어로 표기한다면 특정 단어와 그 단어에 대한 윈도우 크기가 1인 맥락을 다음과 같이 표현할 수 있다.
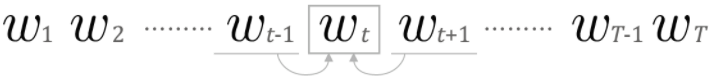
그렇다면 W(t-1) 과 W(t+1)이 주어졌을 때 Wt의 확률은 다음과 같이 표현할 수 있다.
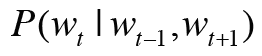
이 식을 이용하여 CBOW 모델의 손실함수를 나타낼 수 있다.
앞서 Cross-entropy를 사용했으므로 교차 엔트로피식으로 생각해보면,
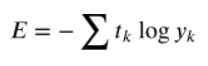
과 같다.
t와 y 모두 one-hot-encoding 형식이며 t는 정답을 나타내는 것이므로 정답 부분만 1이고 나머지는 모두 0이다. yk부분에서 1인 부분만 곱해져서 살아남을 것이므로 이 점을 고려하여 다음과 같이 식을 바꿀 수 있다.
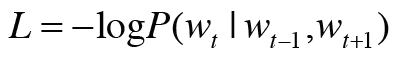
이를 음의 로그 가능도(negative log likelihood)라고 하며, 손실함수를 음의 로그 가능도로 나타낼 수 있다.
이를 말뭉치 전체로 확장하게 된다면 다음 식이 된다.
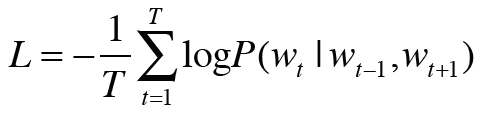
skip-gram 모델
word2vec의 나머지 모델이다. skip-gram모델은 CBOW에서 다루는 맥락과 타깃을 역전시킨 모델이다.
즉, Skip-gram 모델은 중앙의 단어(타깃)로 부터 주변의 여러 단어(맥락)를 추측한다.

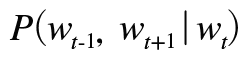
이는 CBOW와 마찬가지로 교차 엔트로피 오차에 적용하고 말뭉치 전체로 확장하여 다음과 같은 식을 도출한다.
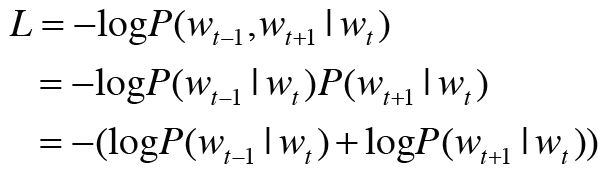
CBOW 모델은 타깃 하나의 손실을 구하지만, skip-gram 모델은 맥락의 수만큼 추측하기 때문에, 그 손실 함수는 각 맥락에서 구한 손실의 총합이다.
성능면에서는 skip-gram 모델이 더 뛰어나다. 학습 속도면에서는 CBOW가 빠르지만, 단어 분산 표현의 정밀도 면에서, skip-gram 모델이 뛰어나며, 말뭉치가 커질수록 저빈도 단어나 유추 문제의 성능 면에서도 더 뛰어나다.
직관적인 이유로 skip-gram 모델이 더 풀기 어려운 문제에 도전하기 때문이다. 우리가 두 모델의 문제를 각각 풀어본다 할때, 맥락을 통해 중앙 단어를 유추하는 것보다, 중앙 단어를 통해 주변 맥락을 파악하는 것이 더 어렵다.
class SimpleSkipGram:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# 계층 생성
self.in_layer = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer1 = SoftmaxWithLoss()
self.loss_layer2 = SoftmaxWithLoss()
# 모든 가중치와 기울기를 리스트에 모은다.
layers = [self.in_layer, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
def forward(self, contexts, target):
h = self.in_layer.forward(target)
s = self.out_layer.forward(h)
l1 = self.loss_layer1.forward(s, contexts[:, 0])
l2 = self.loss_layer2.forward(s, contexts[:, 1])
loss = l1 + l2
return loss
def backward(self, dout=1):
dl1 = self.loss_layer1.backward(dout)
dl2 = self.loss_layer2.backward(dout)
ds = dl1 + dl2
dh = self.out_layer.backward(ds)
self.in_layer.backward(dh)
return None 학습하는 부분은 CBOW와 다르게 구현해야 한다.
출력층 부분에서 손실함수들의 합을 최종 손실함수로 사용하여 최종 손실함수로 학습을 시켜야 하기 때문이다.
