
위 주제는 밑바닥부터 시작하는 딥러닝2 7강, CS224d를 바탕으로 작성한 글 입니다.
이전 글에서 LSTM을 사용하여 언어 모델을 구현하고, 드랍아웃, 가중치 공유를 사용하여 개선해보았다. 그리고 PTB 데이터를 학습해보았다.
오늘은 언어 모델을 사용해 '문장 생성'을 수행해보자. '문장 생성'을 위해 seq2seq라는 새로운 구조의 신경망도 다뤄볼 것 이다.
언어 모델을 사용한 문장 생성
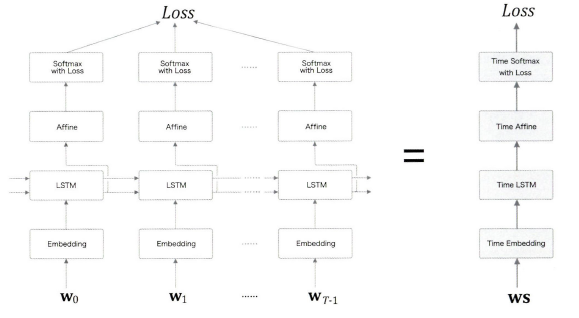
이전에 시계열 데이터를 한꺼번에 처리하는 Time 계층을 사용하였다.
이 언어 모델에서 문장을 생성시켜보자.
"you say goodbye and I say hello."라는 말뭉치에서 언어 모델에 "I"를 입력하여 주면 다음과 같이 확률분포를 출력한다.
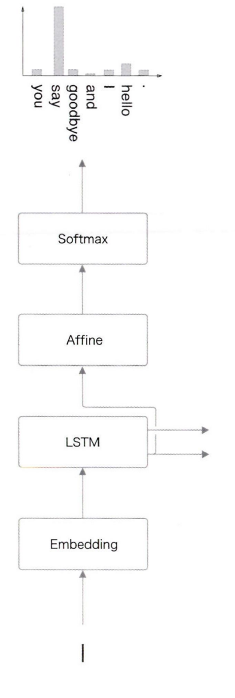
다음 단어를 생성하는 방법은 2가지가 있다.
- 첫번째로, '확률이 가장 높은 단어'를 선택하는 방법이 있다. 이는 확률이 가장 높은 단어를 선택하여 '결정적'인 방법이라 할 수 있다.
- 두번재로, '확률적'으로 단어를 선택하는 방법이 있다. 이는 확률이 높은 단어는 선택되기 쉽고(say), 낮은 단어는 선택되기 어려워진다.(and나 you)
두번째의 경우는 늘 같은 단어가 출력되는 것이 아니므로 샘플링이 매번 다를 수 있다.
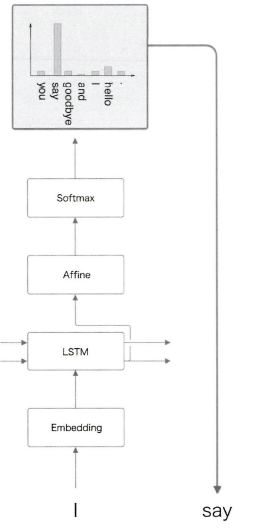
"I"다음으로 확률적으로 "say"가 나왔다. 중요한 것은 '필연적'인 것이 아니라 '확률적'인 것이다.
두번째 단어도 이런 방식으로 '확률적'으로 뽑아낸다.
이 작업을 원하는 만큼 반복하여 "<eos>" 같은 종결 기호가 나타날 때까지 반복한다.
문장을 생성할 수 있는 이유는 무엇일까? 언어 모델은 훈련 데이터를 암기한 것이 아니라, 훈련 데이터에서 사용된 단어의 정렬 패턴을 학습한 것이기 때문이다. 퍼플렉시티가 낮도록 잘 학습하면, 생성된 문장은 자연스럽고 의미가 통하는 문장일 수 있다.
문장 생성 구현
이전에서 구현한 Rnnlm 클래스를 사용하여 RnnlmGen 클래스를 만들어본다.
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
'''
start_id 최초로 주는 단어의 ID
skip_ids 단어 ID의 리스트(ex. [12, 20]) 리스트에 속하는 ID는 샘플링X
sample_size = 샘플링 단어 수
'''
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
# predict()는 미니배치 처리를 하므로 입력 x는 2차원 배열이여야 한다.
x = np.array(x).reshape(1, 1)
score = self.predict(x)
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids-
generatestart_id최초로 주는 단어의 IDskip_ids단어 ID의 리스트(ex. [12, 20]) 리스트에 속하는 ID는 샘플링X. 이유는<unk>나N등, 전처리된 단어를 샘플링 하지 않게 하는 용도로 사용한다.sample_size샘플링 단어 수
우선 generate에서 model.predict(x)로 score를 구한다.
그리고 softmax로 점수를 정규화한다.
얻은 p의 값으로 다음 단어를 샘플링한다. 참고로 p의 확률분포로부터 샘플링 할 때 np.random.choice(len(p), size=1, p=p)를 사용한다.
문장 생성
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
# model.load_params('../Rnnlm.pkl')
# 시작(start) 문자와 건너뜀(skip) 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
# txt가 ID배열을 문장으로 변환해준다.
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)# ID배열을 문장으로 변환해준다. ' '.join(['you', 'say', 'goodbye']) >>> 'you say goodbye'
샘플링 하지 않는 단어는 ['N', '<unk>', '$']로 선택한다.
txt 결과
you numerous mystery diluted incorrectly plummeted manitoba fully painted usx fend korea powerful realist competition invests breed wellington holidays creativity jail impetus rothschilds aware hitachi suggested real powerhouse wage solicitation climbing collateralized laband begin sequester shape del. ...
코드에 보면 이전에 학습해둔 model.load_params('../Rnnlm.pkl') 가중치 파일을 사용하지 않고 무작위의 가중치 초깃값을 사용했기 때문에, 엉터리 문장이 나왔다.
그러면 주석을 풀고 다시 모델을 돌려보면
txt 결과 (Rnnlm.pkl 사용)
you talks on the institutions ' parent of taxes increases and played buying differ management and ca n't gauge death.
mr. jones said remains throughout contrast with arby 's state created for navigation mixte 's west stock to make close on confidential medical....
문법적으로 이상하거나 의미가 통하지 않는 문장이 조금 있지만. 그럴듯한 문장도 있다. ("당신은 기관의 세금 인상의 부모에 대해 이야기하고 다른 관리를 구매하고 죽음을 측정할 수 없습니다."??????🤔 퍼플렉서티가 200언저리였으니.... )
주어와 동사는 올바른 순서로 배치한 것 같다.
더 좋은 문장으로
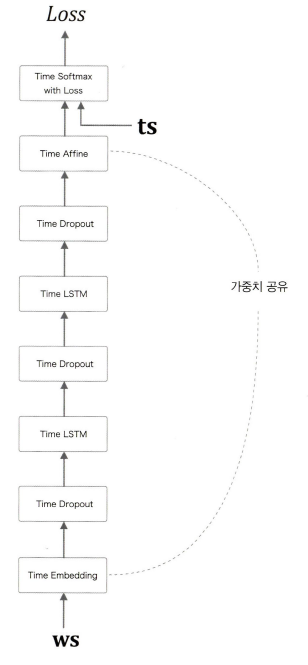
Dropout과 가중치 공유를 사용한 BetterRnnlm모델을 학습시켜 퍼플렉서티가 40대로 나온 가중치 파일을 이용해서 문장을 생성해보자.
class BetterRnnlmGen(BetterRnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
'''
이와 동일
'''txt 결과 (BetterRnnlm.pkl 사용)
you would pitch attracting die mr. warren says.
the most part the firm is willing to take he one.
the jittery difference between china and england of the u.k. finally proved more success in the ec in making the of all free barriers in putting the goods together.
it would guide the problems where they break a package with greater quality to the west....
아까보다 조금 더 자연스러운 문장이 만들어졌다. 주관적일 수 있지만...ㅎㅎ
지금까지는 'you'라는 단어를 주어 순전파를 진행했지만 한번 'the meaning of life is'라는 글을 주고 순전파를 수행하여 출력해보자.
LSTM 계층에 단어열 정보를 유지한다음, "is"를 첫 단어로 입력해 문장을 생성한다는 의미이다.
start_words = 'the meaning of life is'
start_ids = [word_to_id[w] for w in start_words.split(' ')]
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x)
word_ids = model.generate(start_ids[-1], skip_ids)
word_ids = start_ids[:-1] + word_ids
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print('-' * 50)
print(txt)txt 결과 (the meaning of life is...)
the meaning of life is n't enough to use for this week. ...
"이번 주에는 삶의 의미가 충분하지 않다." 라는 글이 나왔다.
오! 이번에는 의미가 있는 문장이 생성 된 것을 알 수 있다.
seq2seq
시계열 데이터를 다른 시계열 데이터로 변환하는 어플리케이션은 많다.
음성을 텍스트로 바꾸거나, 동영상을 텍스트로 바꾸는 등 수 많은 변환 방법이 있다.
이를 위한 기법으로 여기에서는 2개의 RNN을 이용하는 seq2seq 라는 방법을 살펴보겠다.
원리
seq2seq를 Encoder-Decoder 모델이라고 한다.
2개의 모듈, Encoder 와 Decoder 가 등장한다.
문자 그대로 Encoder 는 입력 데이터를 인코딩(부호화)하고 Decoder 는 인코딩된 데이터를 디코딩(복호화)한다.
인코딩(부호화)은 'A'라는 문자를 '10000001'이라는 이진수로 변환하고, 디코딩(복호화)는 '1000001'을 다시 'A'로 되돌리는 것을 말한다.
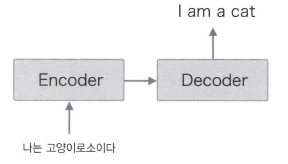
Encoder 가 "나는 고양이로소이다"라는 출발어 문장을 인코딩한다.
어어서 그 인코딩한 정보를 Decoder 에 전달하고, Decoder 가 도착어 문장을 생성한다.
이때 Encoder 가 인코딩한 정보에는 번역에 필요한 정보가 조밀하게 응축되어 있다.
Docder 는 조밀하게 응축된 정보를 바탕으로 도착어 문장을 생성하는 것이다.
Encoder
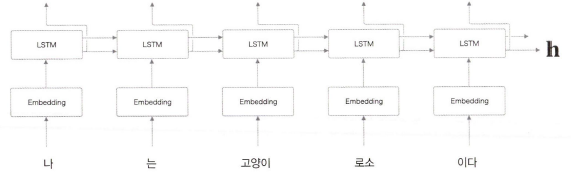
Encoder 는 RNN을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환한다.
지금 예에서는 RNN으로써 LSTM 을 이용했지만, '단순한 RNN'이나 GRU 등도 이용할 수 있다.
그리고 여기에서는 우리말 문장을 단어 단위로 쪼개 입력한다고 가정한다.
h는 LSTM의 마지막 은닉 상태이다.
마지막 은닉 상태 h에 입력 문장(출발어)를 번역하는 데 필요한 정보가 인코딩된다.
여기서 중요한 점은 LSTM의 은닉 상태 h는 고정 길이 벡터라는 사실이다.
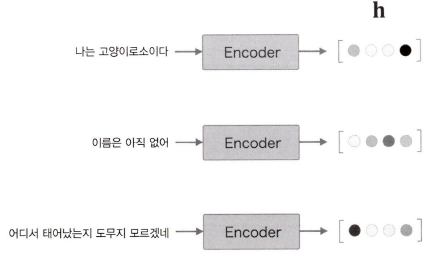
즉, Encoding이라는 것은 임의 길이의 문장을 고정 길이 벨터로 변환하는 작업을 말한다.
Decoder
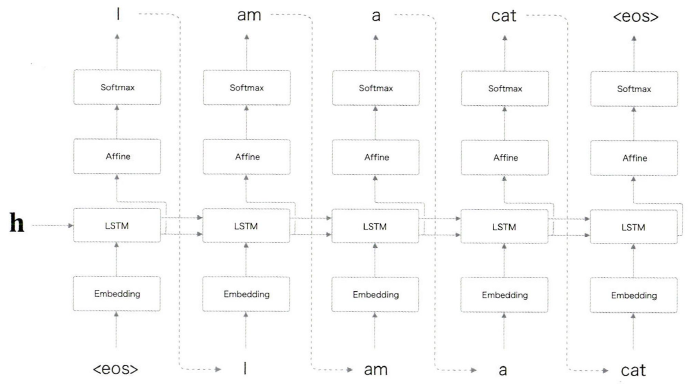
그림과 같이 Decoder 는 여태 배운 신경망과 완전히 같은 구성이다.
단 한가지, LSTM 계층이 벡터 h를 입력받는다는 점이 다르다.
참고로, 앞 절의 언어 모델에서는 LSTM 계층이 아무것도 받지 않는다.
(굳이 따지자면, 은닉 상태로 영벡터를 받았다고 할 수 있다)
참고로 이전 글에서 한번 언급을 한 적이 있다.
이처럼 단 하나의 사소한 차이가 평범한 '언어 모델'을 '번역도 해낼 수 있는 Decoder'로 탈바꿈시킨다.
<eos>라는 것은 '구분자'로, Decoder에 문장 생성의 시작을 알리는 신호로 사용된다. 또한 Decoder가 <eos>를 출력할 때까지 단어를 샘플링하도록 하기 위한 종료 신호이기도 하다. 즉 '시작/종료'를 알리는 구분자로 이용한다. <eos> 이외에도 <go>, <start>, 밑줄(_)을 이용하기도 한다.
연결
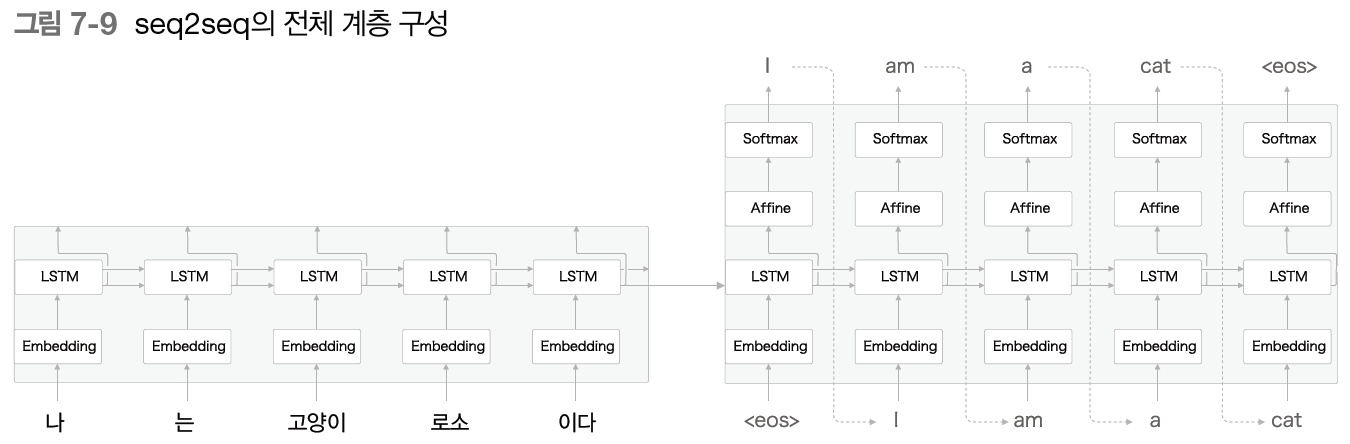
seq2seq는 LSTM 2개로 이어진다. LSTM 계층의 은닉 상태가 Encoder와 Decoder를 이어주는 '가교'가 된다.
Forward시에는 Encoder의 인코딩 정보가 은닉 상태를 통해 Decoder로 전해진다.
Backward시에는 '가교'를 통해 기울기가 Decoder에서 Encoder로 전해진다.
시계열 데이터 변환용 장난감 문제
시계열 변환 문제로 '더하기'를 다루어본다. seq2seq가 "57+5"를 "62"라는 답으로 출력하도록 할 것이다.
이렇게 평가를 위해 간단히 만든 문제를 '장난감 문제'라고 한다.
우리는 당연히 덧셈을 알겠지만, seq2seq는 덧셈 논리에 대해 아무것도 모른다.
그래서 seq2seq 는 덧셈의 샘플로부터 거기서 사용되는 문자의 패턴을 학습한다.
과연 패턴을 학습하는게 덧셈 논리를 올바르게 학습할 수 있는가?
이번 문제에서는 단어가 아닌 문자 단위로 분할한다.
문자 단위 분할이란, 예컨대 '57+5' 가 입력되면, [5,7,+,5] 라는 리스트로 처리하는 걸 말한다.
가변 길이 시계열 데이터
'덧셈'을 문자의 리스트로 다루기로 했다. 문제는 문자 수가 문제마다 길이가 다르다는 것이다. 이를 '가변 길이 시계열 데이터'라 하며 '미니배치 처리'를 위해서는 길이를 일정하게 해야한다.
가별 길이 시계열 데이터를 미니배치로 학습하기 위한 가장 단순한 방법은 패딩을 사용하는 것이다.
-
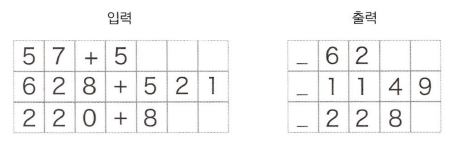
이번 문제에서는 0~999 사이의 숫자 2개만 더하기로 하겠다.
따라서 +까지 포함하면 입력의 최대 문자 수는 7,
자연스럽게 덧셈 결과는 최대 4문자이다. -
질문과 정답을 구분하기 위해 출력 앞에 구분자로 "_"를 붙이기로 한다. 구분자는 Decoder에 문자열을 생성하라 알리는 신호로 사용된다.
-
그 결과 출력 데이터는 총 5문자로 통일한다
-
Decoder 에 입력된 데이터가 패딩이라면 손실의 결과에 반영하지 않도록 해야 한다. (Softmax with Loss 계층에 '마스크'기능을 추가해 해결할 수 있다.)
-
한편 Encoder 에 입력된 데이터가 패딩이라면 LSTM 계층이 이전 시각의 입력을 그대로 출력하게 한다. (ex. 16+75..)
덧셈 데이터셋
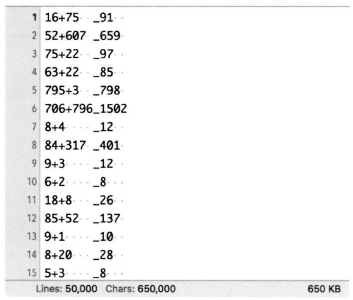
총 5000개가 들어있는 덧셈 데이터 셋이다.
from dataset import sequence
(x_train, t_train), (x_test, t_test) = \
sequence.load_data('addition.txt', seed=1984)
char_to_id, id_to_char = sequence.get_vocab()
# char_to_id : {'1': 0, '6': 1, '+': 2, '7': 3, '5': 4, ' ': 5, '_': 6, '9': 7, '2': 8, '0': 9, '3': 10, '8': 11, '4': 12}
print(x_train.shape, t_train.shape)
print(x_test.shape, t_test.shape)
# (45000, 7) (45000, 5)
# (5000, 7) (5000, 5)
print(x_train[0])
print(t_train[0])
# [ 3 0 2 0 0 11 5 ]
# [ 6 0 11 7 5 ]
print(''.join([id_to_char[c] for c in x_train[0]]))
print(''.join([id_to_char[c] for c in t_train[0]]))
# 71+118
# _189다음장에서 계속...
다음에는 Seq2seq를 구현해보고 덧셈 데이터셋을 활용하여 성능을 확인해 볼 것이다.
그리고 성능을 올려보는 2가지 방법을 구현해 보려한다.
