
위 주제는 밑바닥부터 시작하는 딥러닝2 6강, CS224d를 바탕으로 작성한 글 입니다.
이전 글에서 RNN의 문제와, 게이트가 추가된 RNN인 LSTM에 대해서 알아보는 시간을 가졌다.
이전글 보러가기 >> 게이트가 추가된 RNN(1)
오늘은 LSTM을 사용한 언어 모델을 구현해보고 간단하게 PTB 데이터를 학습한 다음 개선까지 해볼 것이다.
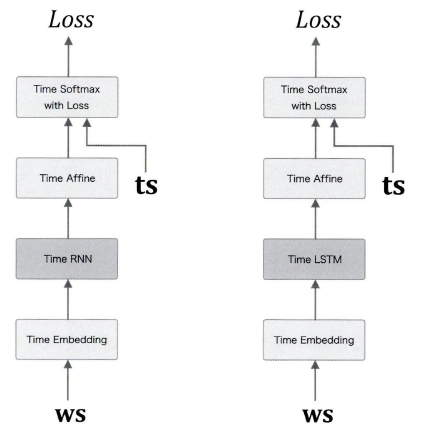
LSTM을 사용한 언어 모델
LSTM을 사용한 언어 모델은 이전글인 RNN을 사용한 언어 모델과 굉장히 흡사하다.
class Rnnlm:
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()__init__
- V는 Vocab_size 단어의 개수(중복 제거), 행렬의 사이즈
- D는 wordvec_size 단어의 벡터화된 사이즈
- H는 hidden_size 이다
가중치 초기화를 위해 embed, lstm, affine의 가중치를 초기화 해준다.
계층을 생성하고 모든 가중치와 기울기를 리스트에 모은다.
predict
- forward함수가 불리면 Softmax 계층 직전까지 forward해준다.
forward
- predict를 하고, TimeSoftmaxWithLoss로 loss값을 구하여 준다.
backward
- layers를 reversed시키고 역전파를 구하여 갱신해준다.
# 하이퍼파라미터 설정
batch_size = 20
wordvec_size = 100
hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수
time_size = 35 # RNN을 펼치는 크기
lr = 20.0
max_epoch = 4
max_grad = 0.25
# 학습 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_test, _, _ = ptb.load_data('test')
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
# 모델 생성
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
# 기울기 클리핑을 적용하여 학습
# xs = 20 * 35
trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad, eval_interval=20)
trainer.plot(ylim=(0, 500))
# 테스트 데이터로 평가
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('테스트 퍼블렉서티: ', ppl_test)
# 매개변수 저장
model.save_params()그리고 앞의 RNN과 비슷하게 PTB 데이터를 학습한다.
차이는 기울기 클리핑인데,
max_grad라는 변수를 지정해주어 클리핑을 적용한다.
# 기울기 구하기
model.forward(...)
model.backward(...)
params, grads = model.params, model.grads
#기울기 클리핑
if max_grad is not None:
clip_grads(grads, max_grad)
# 매개변수 갱신
optimizer.update(params, grads)
매 20번째 반복 퍼플렉서티 값이 출력된다.
처음에는 9999.69인 퍼플렉서티 값인데, 이는 학습을 하지 않은 상태를 말한다. 하지만 학습을 계속할수록 퍼플렉시티가 점점 좋아지고 있다.
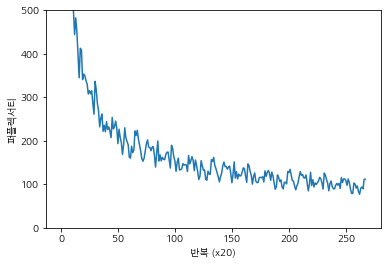
4에폭정도 학습을 수행하였는데 100에 가까운 퍼플렉서티값을 갖는다.
테스트 퍼블렉서티: 136.39106711546 라는 값이 나왔는데 이는 그다지 좋은 결과는 아니다. 그래서 현재 RNNLM을 한층 더 개선해보자
2020년 기준 PTB 데이터셋의 퍼플렉서디는 30~40을 돌고있다.
RNNLM 추가 개선
- LSTM 계층 다층화
- 드롭아웃에 의한 과적합 억제
- 가중치 공유
이 3가지가 RNNLM을 개선할 수 있는 포인트이다.
LSTM 계층 다층화
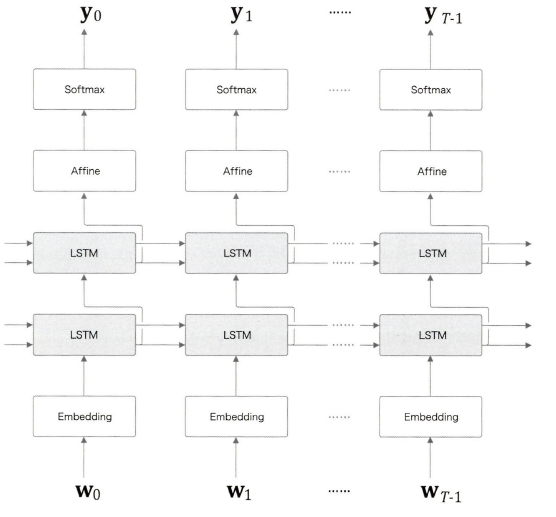
LSTM 계층을 깊게 쌓아 효과를 볼 수 있다.
위 그림은 LSTM 계층을 두 개 쌓은 모습이다.
첫 번째 LSTM 계층의 은닉 상태가 LSTM 계층에 입력된다. 이와 같은 요령으로 LSTM 계층을 몇 층이라도 쌓을 수 있으며, 그 결과 더 복잡한 패턴을 학습할 수 있다.
다층화를 할 때 주의할 점은 하이퍼파라미터에 관한 문제이다. 복잡도나, 준비된 학습 데이터의 양에 따라 하이퍼파라미터를 적절하게 결정해야 한다.
PTB 데이터셋의 언어 모델에서는 LSTM의 층 수는 2~4에서 좋은 성능을 보인다.
구글 번역에 사용되는 GNMT 모델은 LSTM을 8층이나 쌓은 신경망이다.
처리할 문제가 복잡하고 학습 데이터를 대량으로 준비한다면, LSTM 계층을 '깊게' 쌓는 것이 정확도 향상을 이끌 수 있다.
드롭아웃에 의한 과적합 억제
LSTM을 다층화하면 표현력이 풍부한 모델을 만들 수 있다. 하지만 이런 모델은 종종 과적합(overfitting)이 일어난다.
특히 RNN은 일반적인 피드포워드 신경망보다 쉽게 과적합을 일으킨다.
우리는 과적합을 줄이는 여러가지 방법을 알고 있다. '훈련 데이터의 양 늘리기'와 '모델의 복잡도 줄이기'가 있다. 그 외에 복잡도에 페널티를 주는 정규화(normalization)도 효과적이다.
드롭아웃(dropout)처럼 활성화 함수 뒤에 삽입하여 훈련 시 계층 내 뉴런 몇개를 무작위로 비활성하는 방법도 있다.
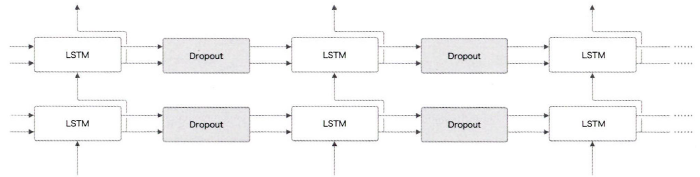
RNN을 사용한 모델에는 드롭아웃을 어디에 넣어야 할까?
첫 번째로, LSTM의 시계열 방향으로 삽입하는 것이다. 하지만 이것은 좋은 방법이 아니다.
시계열 방향으로 드롭아웃을 넣으면 (학습 시) 시간이 흐름에 따라 정보가 사라질 수 있다. 즉, 흐르는 시간에 비례해 드롭아웃에 의한 노이즈가 축적된다.
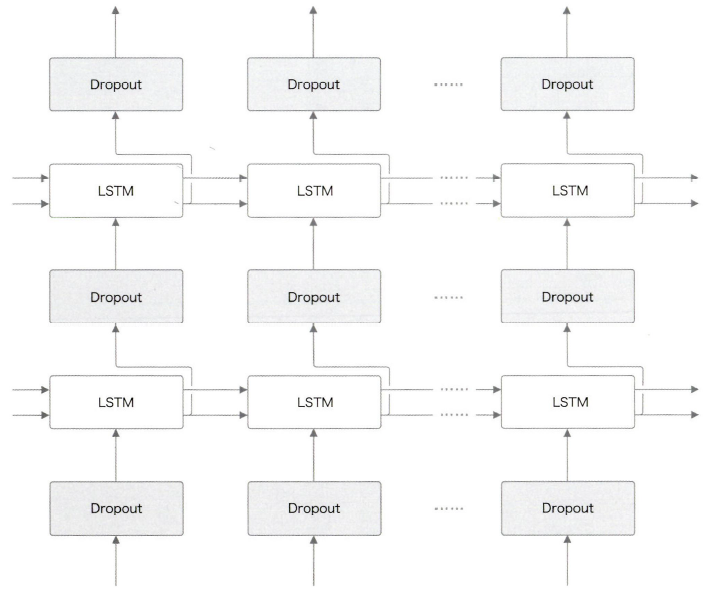
이렇게 구성하면, 시간 방향(좌우 방향)으로 진행해도 정보를 잃지 않는다.
하지만 최근 연구에서 RNN의 시간 방향 정규화 즉 변형 드롭아웃을 제안하고, 시간 방향으로 적용하는데 성공했다.
같은 계층에 속한 드롭아웃들은 같은 마스크를 공유한다.
마스크란 데이터의 '통과/차단'을 결정하는 이진 형태의 무작위 패턴이다.
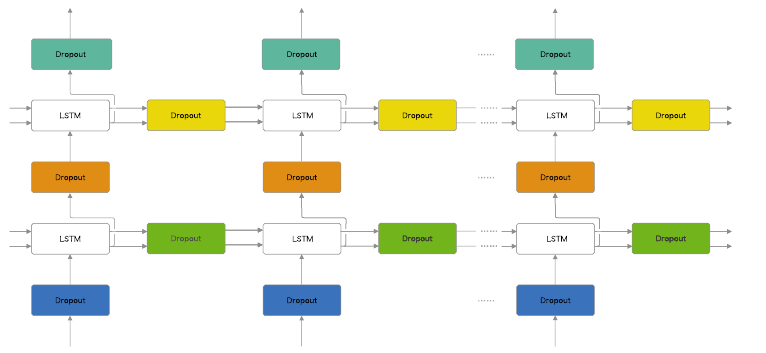
가중치 공유
언어 모델을 개선하는 아주 간단한 트릭 중 가중치 공유가 있다.
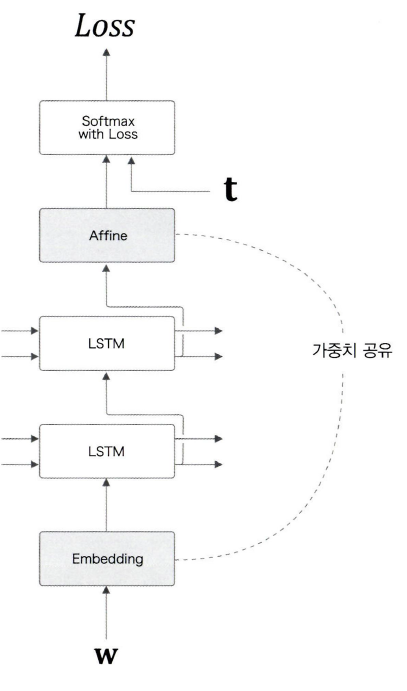
두 계층의 가중치를 연결하여, 공유함으로써 학습하는 매개변수의 수가 크게 줄어드는 동시에 정확도도 향상되는 일석이조의 기술이다.
어휘 수를 V, LSTM의 은닉 상태의 차원수를 H라 할 때, Embedding 계층의 가중치는 형상이 V X H이며, Affine 계층의 가중치 형상은 H X V가 된다. 이때 가중치 공유를 적용하려면 가중치 전치를 사용해 설정하면 된다.
가중치 공유가 효과가 있는 이유는 직관적으로는 가중치를 공유함으로써 학습해야할 매개변수 수를 줄일 수 있고, 그 결과 학습하기가 더 쉬워지기 때문이다. 게다가 매개변수 수가 줄어든다 함은 과적합이 억제되는 혜택으로 이어질 수 있다.
BetterRnnlm 구현
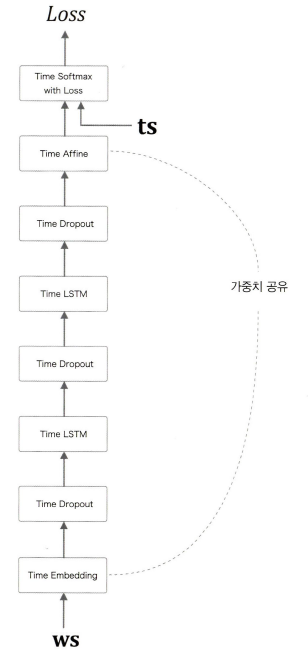
class TimeDropout:
def __init__(self, dropout_ratio=0.5):
self.params, self.grads = [], []
self.dropout_ratio = dropout_ratio
self.mask = None
self.train_flg = True
def forward(self, xs):
if self.train_flg:
flg = np.random.rand(*xs.shape) > self.dropout_ratio
scale = 1 / (1.0 - self.dropout_ratio)
self.mask = flg.astype(np.float32) * scale
return xs * self.mask
else:
return xs
def backward(self, dout):
return dout * self.mask- TimeDropout도 기존 Dropout과 같다.
- 몇개를 비활성(0값)으로 만드는 대신 남아 있는 값은 scale 만큼 곱해주어 값을 유지하도록 한다.
class BetterRnnlm(BaseModel):
def __init__(self, vocab_size=10000, wordvec_size=650, hidden_size=650, dropout_ratio=0.5):
V, D, H =vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b) # weight tying!!
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state() __init__
- TimeLSTM 계층을 2개 겹치고, 사이사이 TimeDropout 계층을 사용한다. 그리고 TimeEmbedding 계층과 TimeAffine 계층에서 가중치를 공유한다.
predict
- forward함수가 불리면 Softmax 계층 직전까지 forward해준다.
train_flg가True이면 dropout을 사용하겠다는 의미이다. 아닌 경우는 통과
forward
- predict를 하고, TimeSoftmaxWithLoss로 loss값을 구하여 준다.
backward
- layers를 reversed시키고 역전파를 구하여 갱신해준다.

GPU를 사용하여 40 에포크를 돌렸다.
한 에포크당 7분정도 소모 되었으니, 280분.... 대략 4시간 40분 ~ 5시간정도 학습을 하였다.
CPU를 사용하면 2일 정도가 걸린다고 한다.
그리고 마지막 테스트 퍼플렉서티가 76이 나왔다. 이전 136 퍼플렉서티보다 훨씬 개선된 것을 알 수 있다.
1. LSTM의 다층화로 표현력을 높인다.
2. 드롭아웃으로 범용성을 향상시켰다.
3. 가중치 공유로 가중치를 효율적으로 이용하였다.
이 세가지로 정확도 향상을 달성할 수 있다.
연구
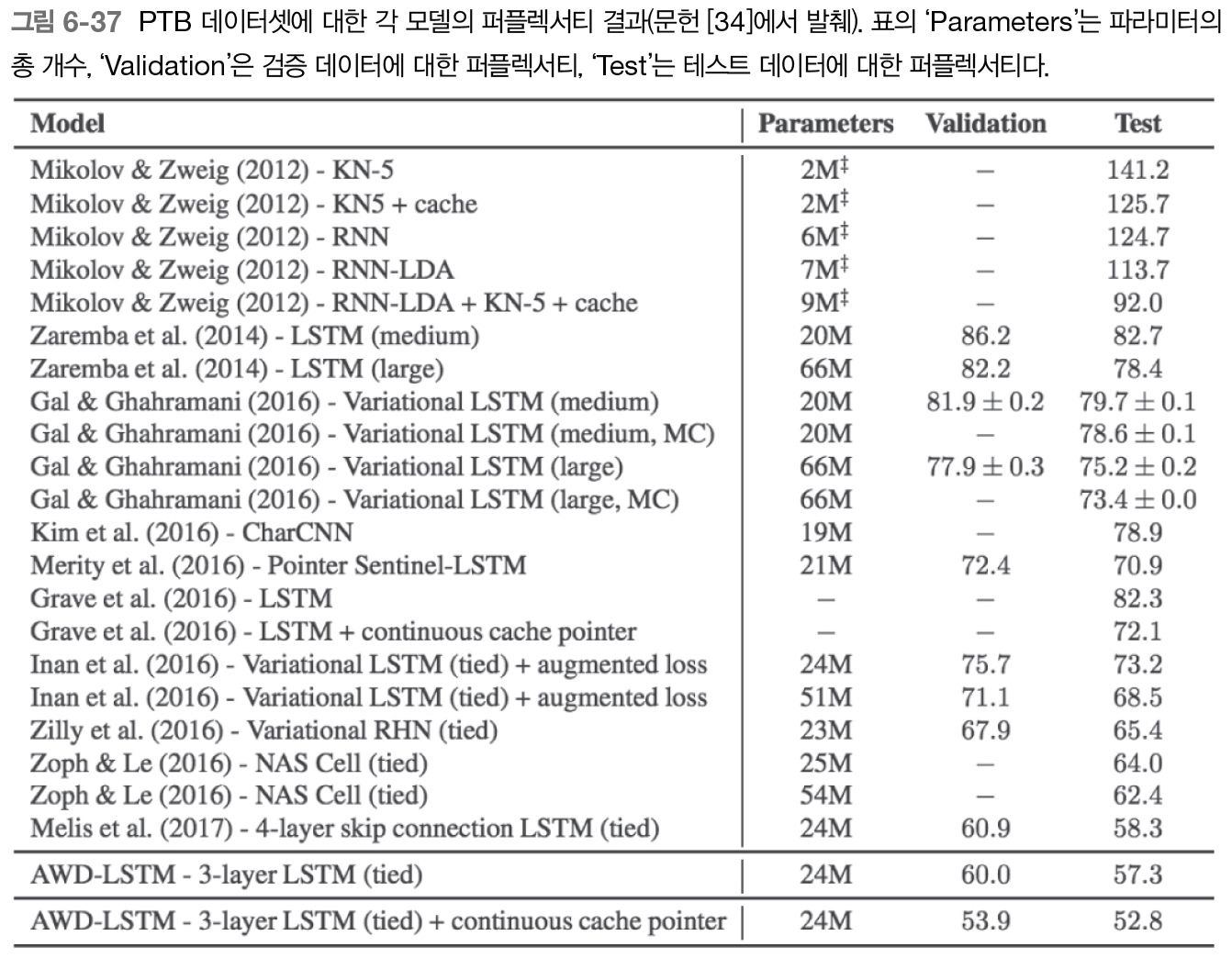
마지막 모델의 이름은 AWD-LSTM 3-layer LSTM(tied) + continuous cache pointer"이다. continuous cache pointer는 후에 어텐션을 기반으로 한 기술인데, 어텐션에 대해서도 글을 올릴 예정이다. 어텐션은 매우 중요한 기술이며 다양한 용도로 쓰인다.
정리
이번에는 게이트가 추가된 RNN을 살펴보았다.
앞 장의 단순한 RNN에서는 기울기 소실(또는 기울기 폭발)이 문제가 되었는데, 그것을 대신하는 계층으로써 게이트가 추가된 RNN(구체적으로는 LSTM과 GRU 등)이 효과가 있음을 설명했다.
이 계층들에는 게이트라는 구조가 사용되며, 게이트는 데이터와 기울기 흐름을 적절히 제어하는 메커니즘이다.
또한 LSTM 계층을 사용한 언어 모델을 만들어봤다.
그리고 PTB 데이터셋을 학습하여 퍼플렉서티를 구했다.
나아가 LSTM 다층화, 드롭아웃, 가중치 공유 등의 기법을 적용해 정확도를 큰 폭으로 향상시켰다.
- 단순한 RNN의 학습에서는 기울기 소실과 기울기 폭발이 문제가 된다.
- 기울기 폭발에서는 기울기 클리핑, 기울기 소실에는 게이트가 추가된 RNN(LSTM과 GRU등)이 효과적이다.
- LSTM에는 input 게이트, forget 게이트, output 게이트 등 3개의 게이트가 있다.
- 게이트에는 전용 가중치가 있으며, 시그모이드 함수를 사용하여 0.0~1.0 사이의 실수를 출력한다.
- 언어 모델 개선에는 LSTM 계층 다층화, 드롭아웃, 가중치 공유 등의 기법이 효과적이다.
- RNN의 정규화는 중요한 주제이며, 드롭아웃 기반의 다양한 기법이 제안되고 있다.
다음은 seq2seq로 문장 생성을 공부해 보자!!
