
-
CV분야에는 Classification, Detection, Segmentation, Pose estimation, Image Generation등 여러 요소가 있다
-
Detection은 카테고리가 어떤 Boundary내에서 이루어 진다면 Segmentation은 모든 픽셀에 카테고리를 정해준다.
→ 그래서 더 어려운 Task이다.
Semantic vs Instance

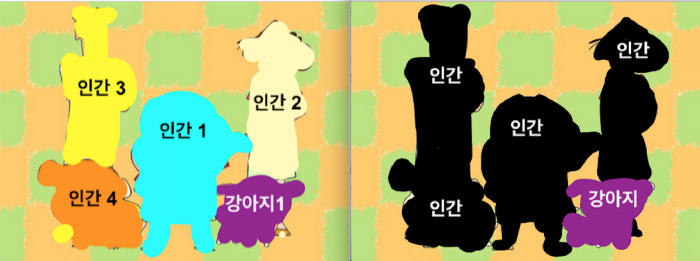
- semantic segmentation은 같은 class의 instance 를 구별하지 않는다는 것
- instance segmentation는 class뿐 아니라 instance 를 구별
Segmenataion Map
- Segmentation Inference를 하면 나오는 값의 형식은 보통 다음과 같다
.png)
- One-Hot encoding 으로 각 class 에 대해 출력채널을 만들어서 segmentation map생성
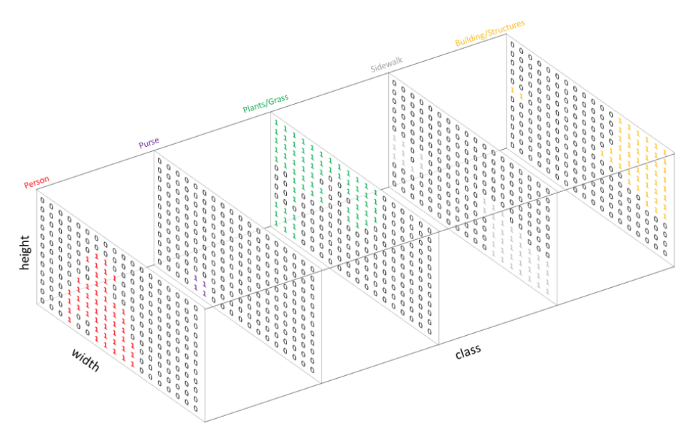
- 512 * 512 이미지의 클래스가 30개인경우 [1, 512, 512, 30] shape의 output 형성
Segmentation의 방법(1) - FCN
-
저해상도에서의 학습의 대표적인 방법
-
Segmentation은 기본적으로 Encoder(Downsampling) ↔ Decoder(Upsampling) 구조를 가짐
-
간단하게 말하면 Segmentation task를 수행하기 위해 기존의 Classification의 basic인 CNN + FC Layer의 구조에서 FC Layer를 제거하고 1 x 1 Conv Layer로 구성하여 위치/공간 정보를 학습해 Upsampling하여 Segmentation mask 생성
Segmentation에 적합한 신경망?
자세한 위치정보를 잡는 것이 우선적이며 중요하다.
그래서 위치/공간 정보를 잃어버리는 FC Layer는 적합하지 않고
AlexNet, VGG같이 Parameter의 개수 및 차원을 줄이기 때문에 정보를 자세하게 담을 수 없다.
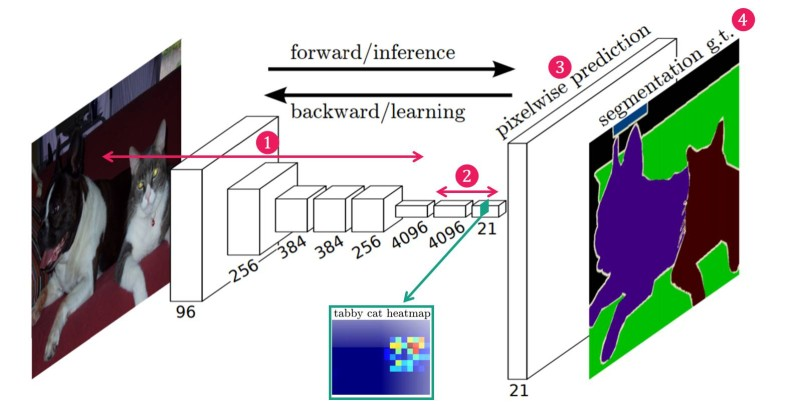
- CNN + FC Layer 구조가 Segmentation에 적합하지 않은 이유?
- CNN에서 FC Layer로 값을 전달 할 때 3차원 이미지에서 1차원 벡터로 변형 되면서 공간/위치 정보를 잃게 된다.
기존 Classification에서는 공간/위치 정보는 필요 없이 레이블의 정보만을 필요로 하다. - FC Layer의 weight 개수가 고정되어 feature map 크기가 고정되어 Input의 이미지의 해상도가 고정되어 있다.
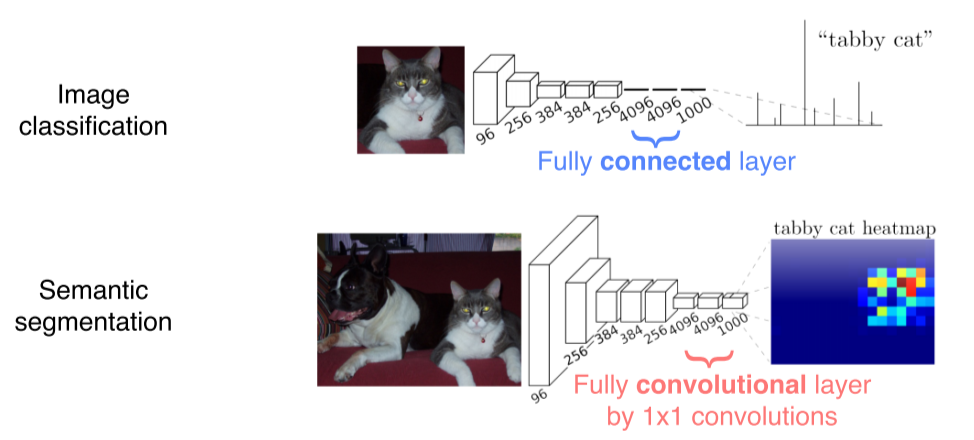
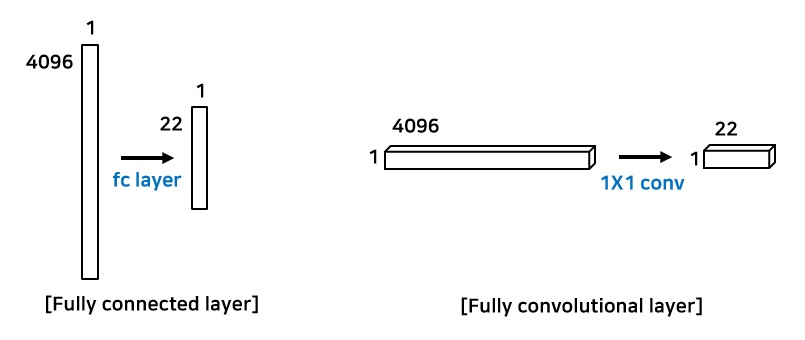
1 x 1 Conv Layer가 공간/위치 정보와 Input 이미지의 크기 제한을 해결.
- CNN에서 FC Layer로 값을 전달 할 때 3차원 이미지에서 1차원 벡터로 변형 되면서 공간/위치 정보를 잃게 된다.
Upsampling
- Trainable한 End-to-end의 형태를 위해 파라미터가 없는 Interpolation이 아닌 학습 가능한 Transposed Convolution 사용 t보다 작아지는 특성
- 딥러닝에서 convolution layer를 깊게 쌓을 수록 feature map의 크기가 계속 작아지게 되는데 이 압축된 정보를 다시 Upsampling하여 mask를 만들어야함
- Dilated Conv를 사용하여 해상도의 크기를 medium-resolution로 유지
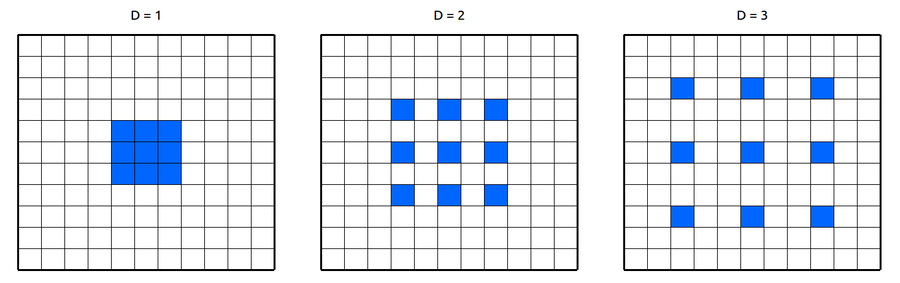
→ Receptive Field는 filter가 한번에 보는 영역
→ Receptive가 크면 output을 계산할 때 사용하는 정보의 양이 많다는 것
→ 하지만 연산량이 많아지는 단점이 존재
→ 이를 극복하기 위해 픽셀 주변에 padding을 주는 Dilated Conv 사용
→ 연산량은 그대로임
Skip Architecture
- 단순 Upsampling으로는 성능을 기대하기 어려움
- 압축된 정보를 통해 원본을 복귀하는 것은 쉽지가 않음
- 직관적으로 feature-map크기가 점점 작아지므로 Conv의 과정을 거치면서 Detail을 저장하여 Upsampling시 활용할 수 있도록 함
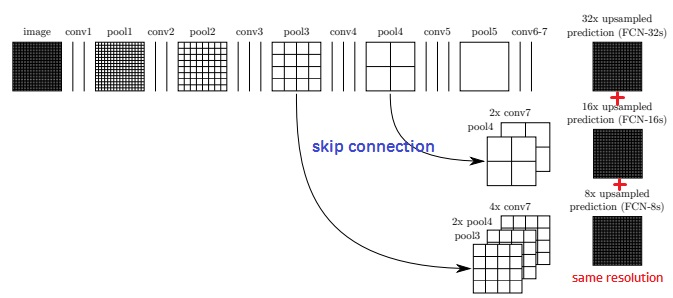
-
FCN-32s : 32 * 32의 output을 위해 pool5 (1x1) 을 32stride Upsample
-
FCN-32s : 32 * 32의 output을 위해 pool5 (2x2) 을 16stride Upsample
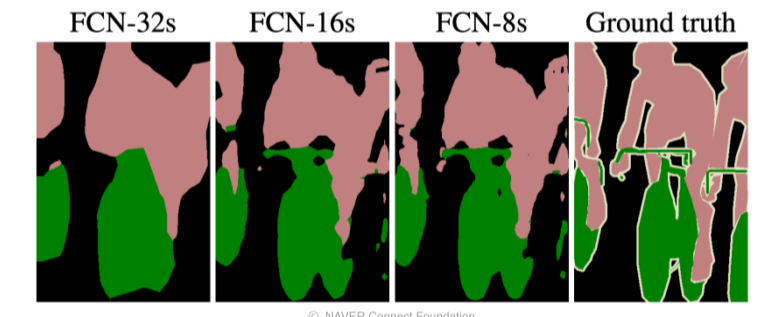
FCN-8s까지만 있는 이유는 더 낮은 layer(pool2)를 사용하면서부터는 오히려 성능이 나빠졌기 때문
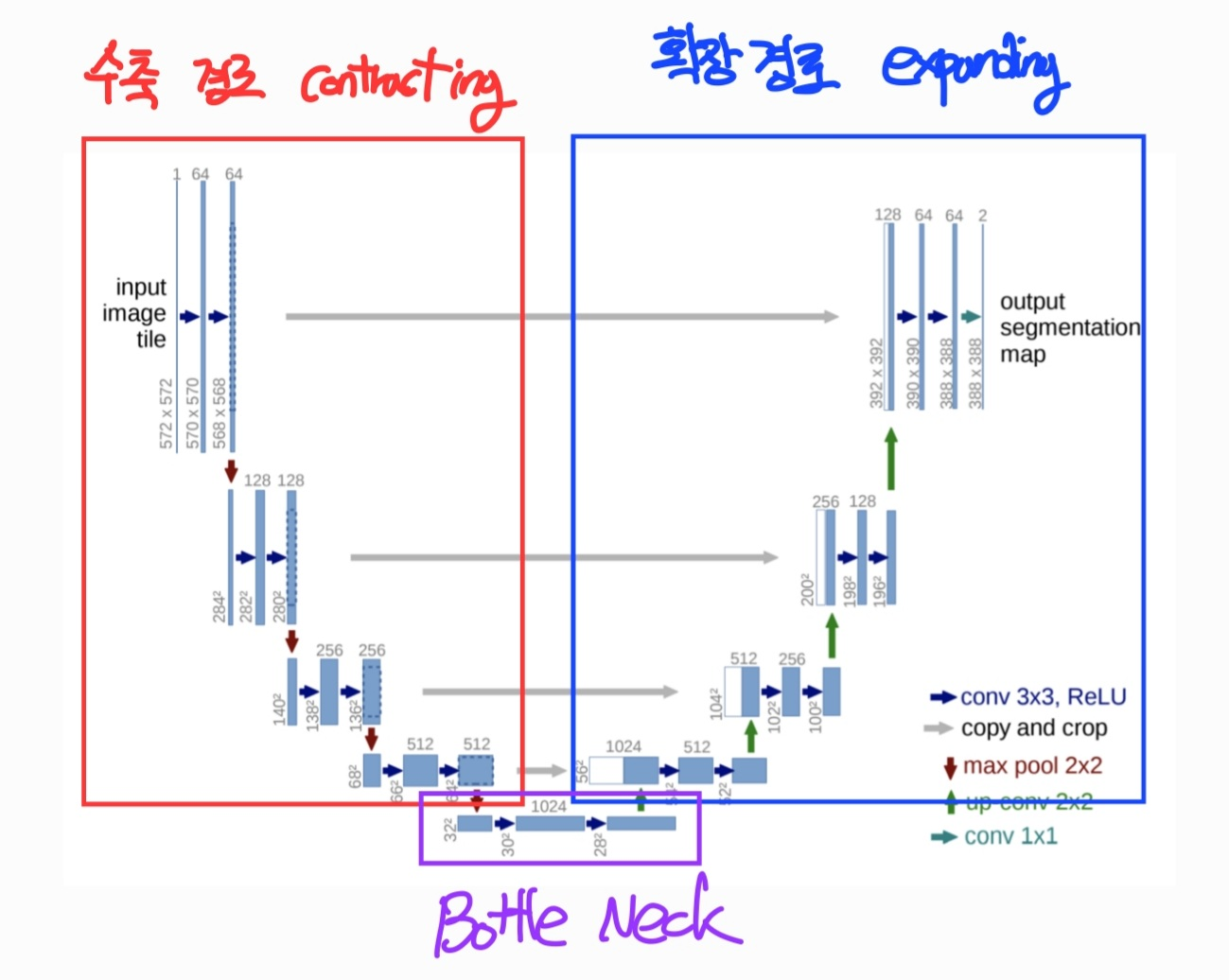
Segmentation의 방법(2) - UNet
- Conv Layer를 Base로 만들어짐
- 고해상도 회복의 Segmentation
-
Contracting Path: 넓은 범위의 이미지 픽셀을 보며 정보를 추출하는 수축 경로
-
Expanding Path: 정보를 픽셀 위치 정보와 결합(Localization)해 각 픽셀마다 어느 객체에 속하는지 구분 (회색 화살표) + 작아진 Feature map Upsampling
-
Bottle Neck: Contracting → Expanding으로 넘어가는 구간
Contracting Path
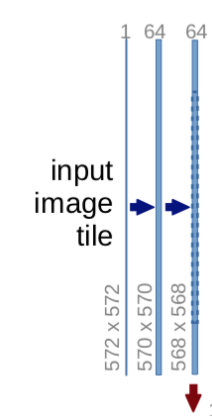
Input image
→ 3×3 Convolution Layer (No Padding, Stride 1)
→ 3×3 Convolution Layer (No Padding, Stride 1)
→ 2×2 Max-polling Layer (Stride 2)
를 통해 Feature Map 형성
- 패딩을 하지 않으므로 특징맵(Feature Map)의 크기가 감소
- 채널 수는 1 → 64 → 128 → 256 → 512 → 1024로 Downsampling
3번 반복
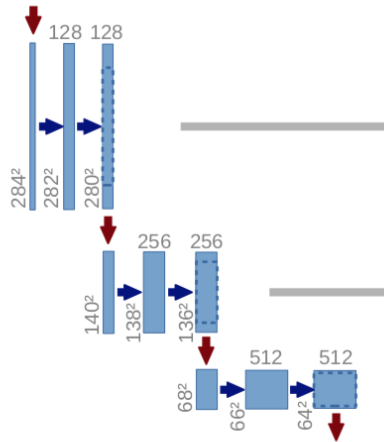
Bottle Neck

→ 3×3 Convolution Layer (No Padding, Stride 1)
→ 3×3 Convolution Layer (No Padding, Stride 1)
→ Dropout
- 마지막에 Dropout을 사용하여 Regularization
- 28x28x1024 크기로 조정
Expanding Path
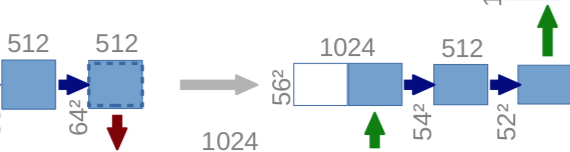
2×2 Deconvolution layer (Stride 2) 채널 수 1/2
→ Concatenation
→ 3×3 Convolution Layer (No Padding, Stride 1)
→ 3×3 Convolution Layer (No Padding, Stride 1)
- Concatenate로 동일 Level의 Feature map을 합침
uconv3 = concatenate([deconv3, conv3])
- deconv: upsampling하고 나온 output
- conv3: Contracting Path에서 나온 output
-
동일 Level의 수축경로와 확장경로의 Feature map의 크기가 다른 이유는 패딩없는 3x3 Conv를 지나면서 줄어들기 때문, 크기를 맞추기 위해 Crop사용
-
마지막에 1x1 Conv를 통해 64개의 component feature vector를 Class에 대한 정보로 매핑 (Width x Height x Class) 벡터가 형성
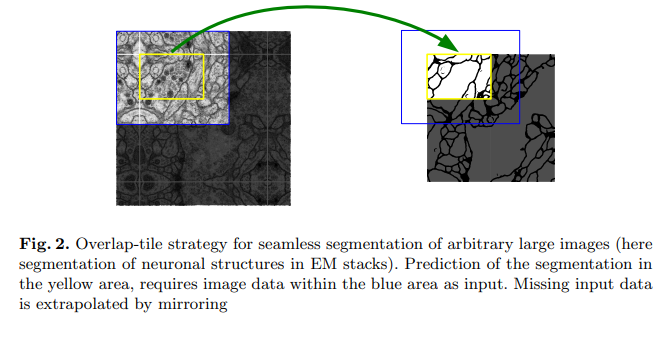
Overlap-tile
-
이미지를 겹치는 부분이 있도록 일정크기로 나누고 모델의 Input으로 활용
-
GPU memory자원에 영향을 받지 않고 높은 Image Resoultion 데이터를 사용할 수 있음
-
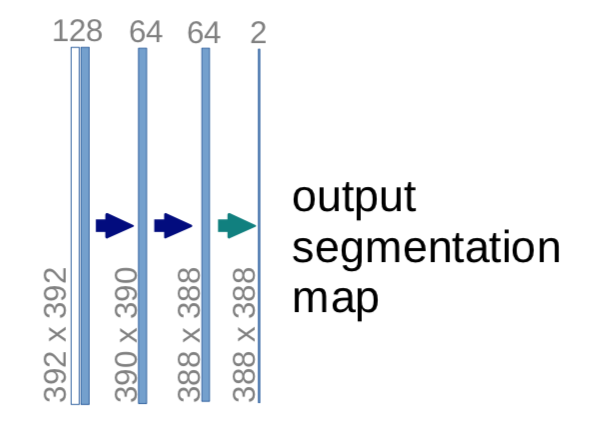
Unet은 이미지 크기가 줄어들어 출력되기 때문에 파란색을 Input으로 주면 노란색이 Output으로 나옴
-
그래서 겹치는 부분이 존재하도록 이미지를 자르고 Segmentation을 진행
Weight Loss
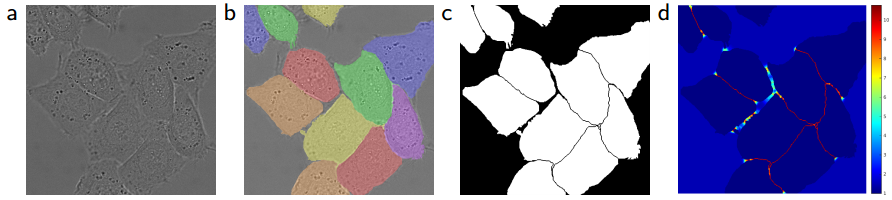
(a) 세포 현미경 raw image
(b) ground truth
(c) segmentation mask
(d) pixel wise loss
- 각 픽셀이 경계와 얼마나 가까운지 Weight-Map을 만듬
- 경계에 가까운 픽셀의 Loss를 Weight-Map에 비례하게 증가 시킴으로 경계를 학습 하도록 함
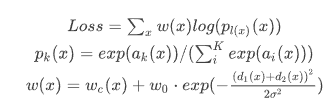
: 픽셀 의 output
: 픽셀 가 일 확률
: 픽셀 의
: 논문의 Weight Hyper-parameter, 10으로 설정
: 논문의 Weight Hyper-parameter, 5로 설정
: 픽셀 의 위치로부터 가장 가까운 경계와의 거리
: 픽셀 의 위치로부터 두 번째로 가까운 경계와의 거리
- 픽셀 X가 경계와의 거리가 가까우면 w(x)는 큰 값을 가지게 됨
- 해당 픽셀의 Loss 비중이 커짐
- 경계학습에 뛰어남
정리
FCN은 저해상도에서의 학습의 대표적인 예시이며 feature map의 크기가 줄어든 상황에서 Upsampling을 진행하기 때문에 성능이 뛰어나지는 않음
UNet
Skip Architecture를 통해 Layer를 깊게 쌓아도 정보의 손실을 줄임
Decoder처럼 Upsampling네트워크의 중요성 및 고도화
Weighted Loss를 통해 경계값에 대한 Loss를 크게 두어 경계를 잘 분리하도록함
biomedical segmentation application 분야에서 뛰어난 성능을 가짐
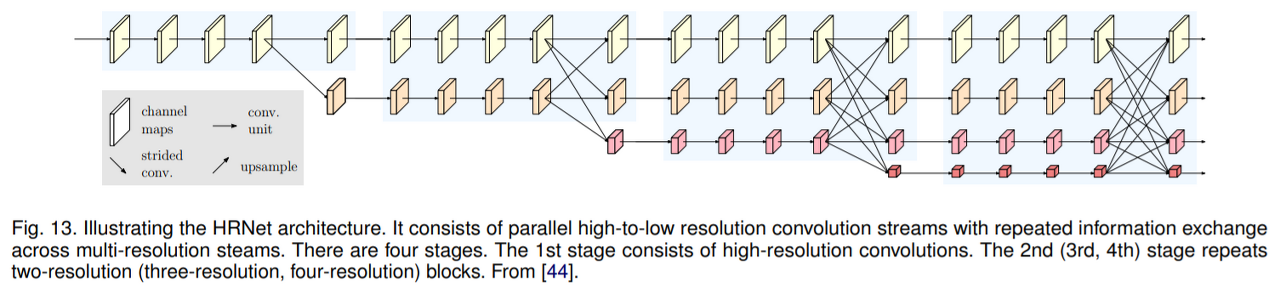
다음 예고
기본적인 Segmentation의 대표적인 방법인 저해상도에서의 학습(FCN), 고해상도 회복(UNet)을 간단하게 살펴봤다.
다음은 Stage가 지속되어도 High-Resolution을 지속하는 고해상도 유지의 방법 중 SOTA를 차지하고있는 HRnet에 대해서 논문 리뷰 및 코드 작성을 해본다.

너무 잘 읽었습니당