
위 주제는 밑바닥부터 시작하는 딥러닝2 8강, CS224d를 바탕으로 작성한 글 입니다.
이전글에서 Attention의 구현과 "날짜"데이터를 사용해서 학습시켜보고 기존의 seq2seq모델과 비교를 해보았다.
오늘은 "어텐션(Attention)"에서 심층적으로 몇가지의 기법을 이야기를 해보려고 한다. 이전글 보기 어텐션-Attention(1)
양방향 RNN
이전 글에서 설명한 Encoder는 LSTM의 각 시각의 은닉은 hs로 모아진다.
그리고 Encoder가 출력하는 각 행에는 그 행에 대응하는 단어의 성분이 많이 포함되어 있다.
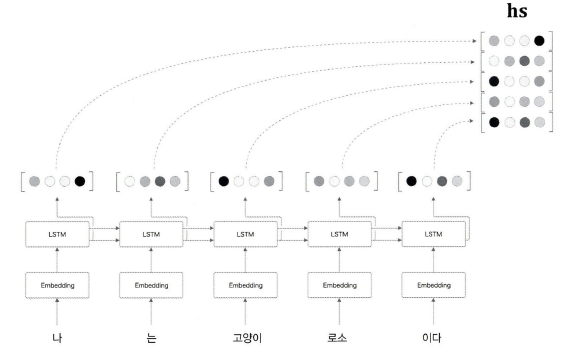
주목할 것은 우리는 글을 왼쪽에서 오른쪽으로읽는다는 것이다. 따라서 "고양이"에 대응하는 벡터에 "나", "는", "고양이"까지 총 세단어의 정보가 인코딩 되어 있다.
전체적인 균형을 위해 "고양이" 단어의 왼쪽 단어만이 아니라, '주변'정보를 균형있게 담아야 한다.
반대로 LSTM을 오른쪽으로도 처리하여 이 두가지를 같이 적용한 양방향 LSTM기술을 떠올릴 수 있다.
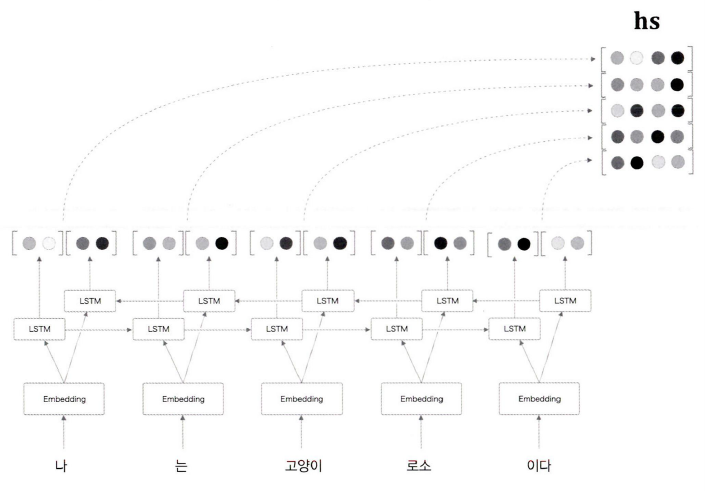
간단하게 이야기하면
- 기존 LSTM의 계층에 더해서 역방향으로 처리하는 LSTM 계층도 추가한다.
- 이 두 LSTM 계층의 은닉 상태를 연결 시킨 벡터를 최종 은닉 상태로 처리한다.('연결'외에도, '합', '평균'의 방법도 존재한다.)
이렇게 양방향으로 처리함으로써, 좌, 우 방향으로부터의 정보를 집약해 균형있게 인코딩을 할 수있다.
구현도 쉽다. 2개의 LSTM을 사용해서 각각 계층에 주는 단어를 '왼쪽부터 오른쪽'으로 처리하고, '오른쪽부터 왼쪽'으로 처리하도록 나누어 주면 된다.
class TimeBiLSTM:
def __init__(self, Wx1, Wh1, b1,
Wx2, Wh2, b2, stateful=False):
self.forward_lstm = TimeLSTM(Wx1, Wh1, b1, stateful)
self.backward_lstm = TimeLSTM(Wx2, Wh2, b2, stateful)
self.params = self.forward_lstm.params + self.backward_lstm.params
self.grads = self.forward_lstm.grads + self.backward_lstm.grads
def forward(self, xs):
o1 = self.forward_lstm.forward(xs)
o2 = self.backward_lstm.forward(xs[:, ::-1])
o2 = o2[:, ::-1]
out = np.concatenate((o1, o2), axis=2)
return out
def backward(self, dhs):
H = dhs.shape[2] // 2
do1 = dhs[:, :, :H]
do2 = dhs[:, :, H:]
dxs1 = self.forward_lstm.backward(do1)
do2 = do2[:, ::-1]
dxs2 = self.backward_lstm.backward(do2)
dxs2 = dxs2[:, ::-1]
dxs = dxs1 + dxs2
return dxs__init__
self.forward_lstm은 우리가 흔히 알고 있는 정방향 LSTM이다.self.backward_lstm은 역방향 LSTM으로 LSTM계층을 총 2개 준비한다.
forward
- 기존의 forward와 같다. 하지만
self.backward_lstm의 순전파에는 xs를 반전시켜서 넣어준다. - 그리고
out변수에 두가지의 o값을 합쳐서 return 해주면 된다.
backward
- 순전파시 concatenate한것을 2개로 나누어서
do1,do2로 나누어서 역전파를 진행해주면 된다.
Attention 계층 사용 방법
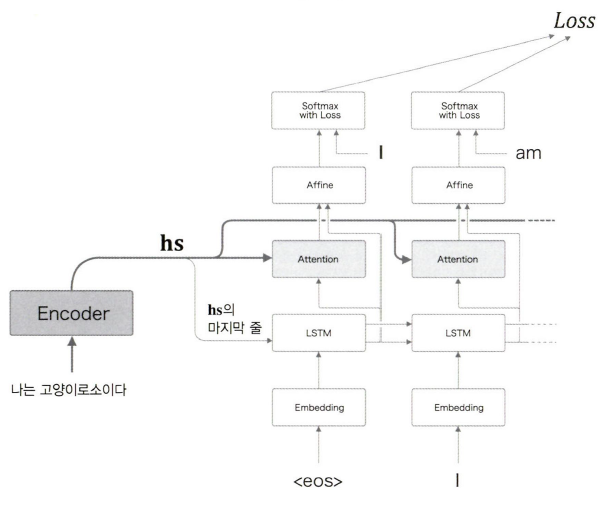
우리는 Attention 계층을 LSTM 계층과 Affine 계층 사이에 삽입했다.
Attention 계층은 사실 다른 위치에 들어가도 된다.
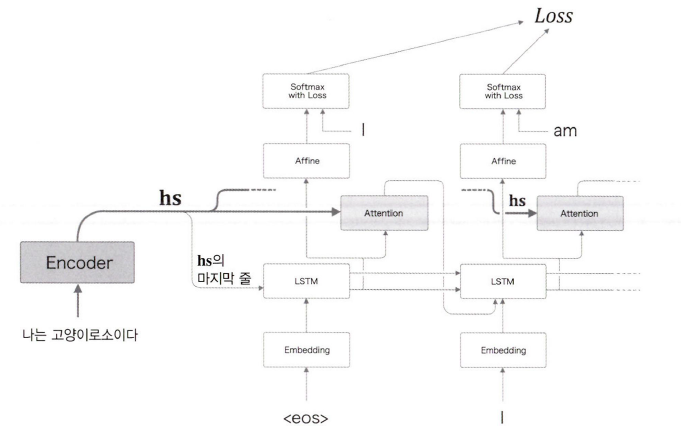
위 그림처럼 Attention 계층의 출력을 Affine에 입력되는게 아니라 LSTM 계층에 입력이 되도록 연결 해도 된다.
이렇게 구성하면 LSTM 계층이 맥락 벡터의 정보를 이용할 수 있게 된다.
이를 최종 정확도에 영향을 어떻게 줄지는 직접 해봐야 아는 것이다. 다만, 둘다 모두 맥락 벡터를 잘 활용하는 구성이라서 큰 차이가 없을지도 모른다.
구현 관점에서 보면 LSTM 계층과 Affine 계층 사이에 Attention 계층을 삽입하는 쪽이 구현하기 쉽다.
seq2seq 심층화와 skip 연결
현실에서의 시계열 데이터는 앞 장에서 사용했던 예제들보다 더욱 복잡하다.
즉, 어텐션을 갖춘 seq2seq에 더 높은 표현력을 요구하는데, 우선적으로 층을 깊게 쌓는 방법이 있다.
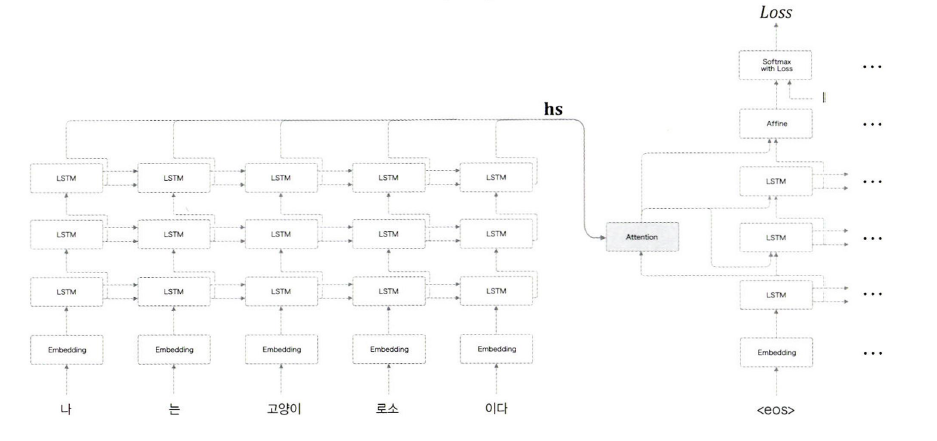
위 그림은 Encoder와 Decoder로 3층 LSTM 계층을 사용하고 있다.
이 예처럼 Encoder와 Decoder에서는 같은 층수의 LSTM 계층을 사용하는 것이 일반적이다.
위의 그림은 하나의 예일 뿐, 여러가지 Attention 계층이 존재한다.
계층을 깊게 쌓을 수록 일반화 성능을 떨어뜨리지 않는 것이 중요하다. 이에는 드롭아웃, 가중치 공유 등의 기술이 효과적이다.
다음으로 skip 연결이 있다. 'skip 연결'은 층을 깊에 할때 사용하는 중요한 기법이다. 계층을 넘어(=계층을 건너 뛰어) '선을 연결'하는 단순한 기법이다.
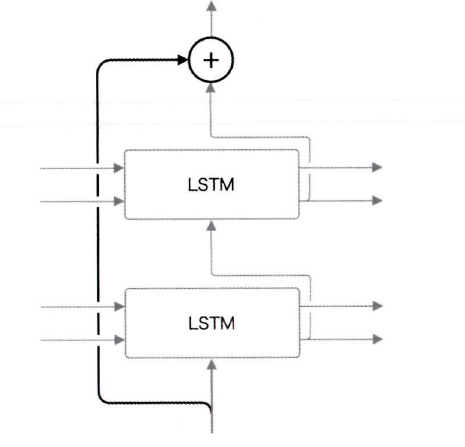
- skip 연결의 접속부에서는 2개의 출력이 '더해'진다.
- 이는 덧셈이기 때문에 역전파시 '흘려'보내서, skip 연결의 기울기가 아무런 영향을 받지 않아 Gradient vanishing, Gradient exploding을 걱정할 필요가 없다.
시간 방향의 Gradient vanishing에는 LSTM이나 GRU로 해결할 수 있고, 시간 방향의 Gradient exploding에는 '기울기 클리핑'으로 대응할 수 있다.
한편, 깊이 방향 Gradient vanishing에서는 skip 연결이 효과적이다.
어텐션 응용
어텐션은 중요한 기술로 다양한 방면에서 등장하는데, 몇가지 연구를 소개한다.
구글 신경망 기계 번역(GNMT)
기계번역의 역사를 보면 다음과 같이 변화해왔다.
- 규칙 기반 번역 -> 용례 기반 번역 -> 통계 기반 번역
현재는 신경망 기계 번역(NMT) 이 주목받고 있다.
계층 구성은 다음과 같다.
GNMT는 2016년 부터 신경망 번역을 사용하였으며, 아키텍쳐의 구성은 다음과 같다.
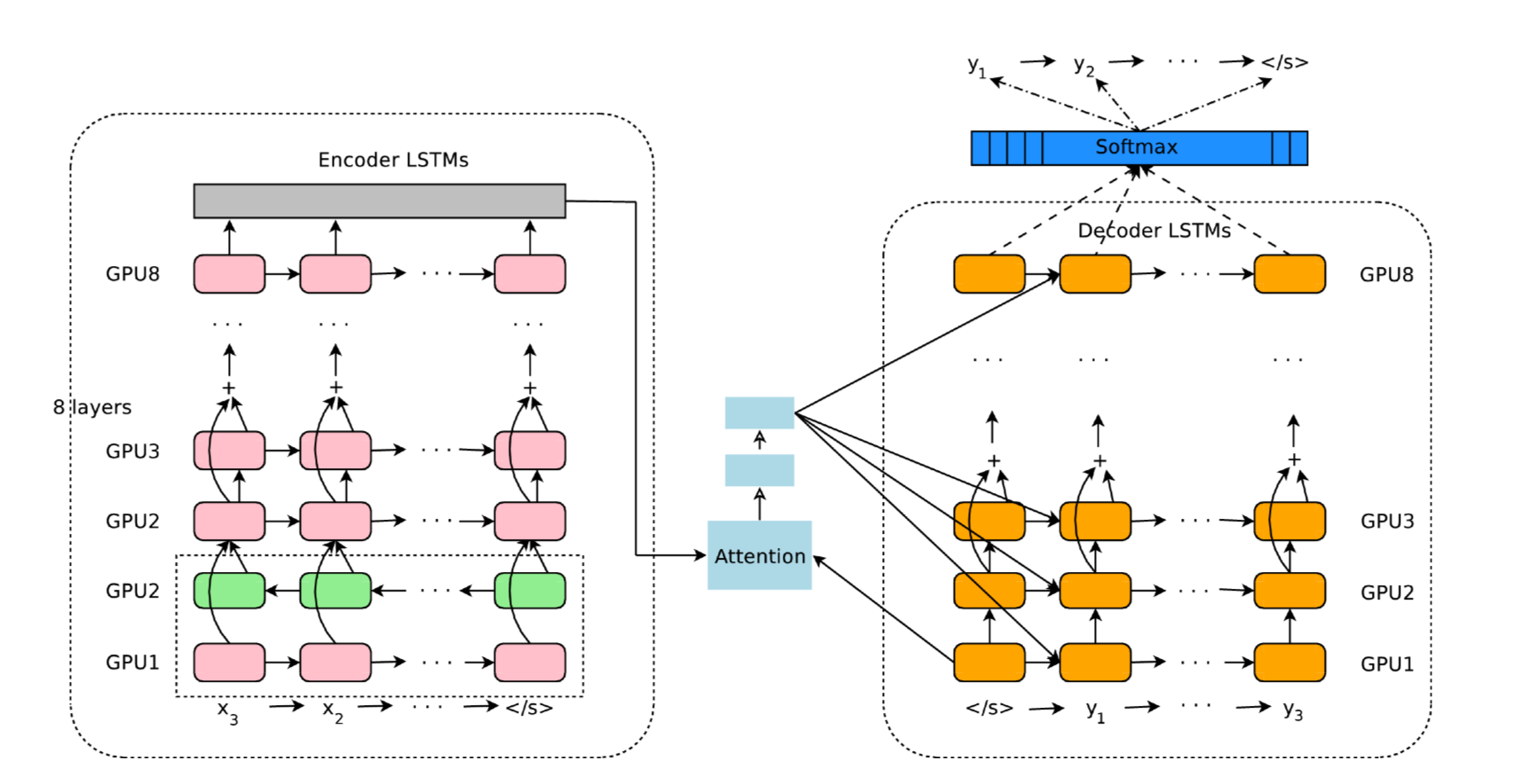
우리가 앞서 배웠던 어탠션을 갖춘 seq2seq와 마찬가지로 Encoder, Decoder, Attention으로 구성되어있다. 다만, 여기에 번역 정확도를 높이기 위해 몇가지 기술이 들어갔다.
- LSTM의 계층의 다층화
- 양방향 LSTM
- Skip 연결
- 학습 시간을 단축하기 위해 GPU로 분산학습
이외에도 낮은 빈도의 단어처리나 추론 고속화를 위한 양자화 등의 연구도 이루어지고 있다.

결과는 GNMT가 기존 기법('구문 기반 기계번역')과 비교해 번역 품질을 크게 끌어올리는 것을 알 수 있는데, 정확도가 거의 사람과 비슷하다.
구글 연구원에 따르면 GNMT는 문장 전체를 하나의 번역 단위로 파악하기 때문에 번역 오류를 55% ~ 85%나 줄일 수 있다고 밝히고 있다.
GNMT를 실제로 학습하는데 있어서 대량의 데이터를 사용하고, 모델 하나를 학습시키는 데 100개의 가까운 GPU로 6일이나 걸렸다고 한다. 8개의 모델을 병행 학습하는 앙살블 학습이나 강화 학습을 이용해 품질을 더욱 개선하려는 연구도 진행되고있다. 근데 우리는 위의 기술들을 알고 있으니 GNMT에 사용되는 기술의 핵심 지식은 이미 습득한 셈이다.
Transformer
GPU의 장점이 딥러닝의 기본적인 행렬 곱하기 연산을 병렬 처리하여 병렬 연산을 통해 빠르게 학습할 수 있다는 점이다.
근데 RNN은 이전 시각에 계산한 결과를 이용해서 순서대로 계산을 하기 때문에, 시간 방향으로 병렬 계산하기란 불가능하다.
즉, GPU의 이점을 얻기 힘들다는 단점이 있다.
그래서 Attention is all you need라는 논문에서 제안한 기법인 트랜스포머(transformer)모델이 있다.
이는 기본적으로 어텐션을 사용해 처리를하며 RNN을 제거했다는 성과를 가지고 있다.
Recurrence를 제거하고 Attention에 전적으로 의지해서 입력과 출력간 관계 인식
Attention-> 한 번의 행렬 곱으로 위치 정보가 포함된 시퀀스 한 번에 계산 ⇒ 병렬 처리 가능
셀프 어텐션이라는 기술을 사용하는게 핵심이다.
Self-Attention이란 것은 '자인에 대한 주목', 즉, 하나의 시계열 데이터를 대상으로 한 어텐션으로, '하나의 시계열 데이터 내에서' 각 원소가 다른 원소들과 어떻게 관련되는지를 살펴본다는 것이다.
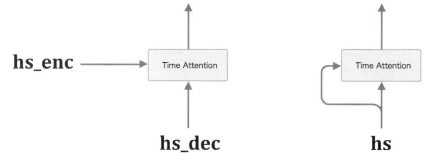
Time Attention 계층에서는 서로 다른 두 시계열 데이터가 입력된다.
반면, Self-Attention은 그림처럼 두 입력선이 모두 하나의 시계열 데이터로부터 나온다. 이렇게 하면 하나의 시계열 데이터 내에서 원소 간 대응 관계가 구해진다.
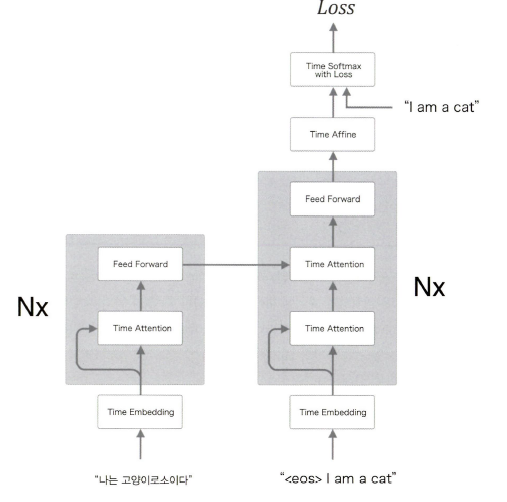
트랜스포머의 계층 구성을 보면 Encoder와 Decoder 모두에서 셀프 어텐션을 사용함을 알 수 있다. 또한 Feed Forward 계층은 피도포워드 신경망(시간 방향으로 독립적으로 처리하는 신경망)을 나타낸다.
정확히는 은닉층이 1개이고 활성화 함수로 'ReLU'를 사용하는 완전연결계층 신경망을 이용한다.
Nx는 계층을 N겹 쌓았다는 뜻이다.
이렇게하면 계산량도 줄고 GPU를 이용한 병렬 계산의 이익도 누릴 수 있다.
결과 트랜스포머는 GNMT보다 학습 시간을 큰 폭으로 줄이는 데 성공했다.
뉴럴 튜링 머신
복잡한 문제를 풀 때 '종이와 펜'을 사용하는 일이 많다.
'종이와 펜'은 외부의 '저장 장치'덕분에 우리의 능력이 확장되었다고 해석할 수 있다.
신경망에도 이와 같은 '외부 메모리'를 이용해서 새로운 힘을 부여할 수 있다.
RNN 계층은 내부 상태를 활용해서 시계열 데이터를 기억할 수 있었다. 그러나 내부 상태는 길이가 고정이라서 채워 넣을 수 있는 정보량이 제한적이다. 그래서 RNN 외부에 기억 장치(메모리)를 두고 필요한 정보를 거기에 적절하게 기록하는 방안을 착안했다.
어텐션을 갖춘 Seq2seq에서는 Encoder가 입력 문장을 인코딩한다. 그리고 인코딩된 정보를 어텐션을 통해 Decoder가 이욯나다.
여기서 주목할 것은 "어텐션"인데, Encoder가 필요한 정보를 메모리에 쓰고, Decoder는 그 메모리로부터 필요한 정보를 읽어 들인다고 해석할 수 있다.
이에 대한 기술의 연구가 정말 활발한데, 그 중 유명한 뉴럴 튜닝 머신(NTM)에 대해서 이야기 해본다.
큰 흐름에서 중요한것이 '컨트롤러' 모듈인데, 이는 정보를 처리하는 모듈로 신경망을 이용한다.
이 컨트롤러에서 바깥에 있는 메모리에서 정보를 읽고, 신경망에서 계산하고, 출력하는 것이다.
다시 NMT로 생각해보면, NMT 는 외부 메모리를 읽고 쓰면서 시계열 데이터를 처리한다. 그리고 이러한 메모리 조작을 '미분 가능한' 계산으로 구축했다. 따라서 메모리 조작 순서도 데이터로부터 학습이 가능하다.
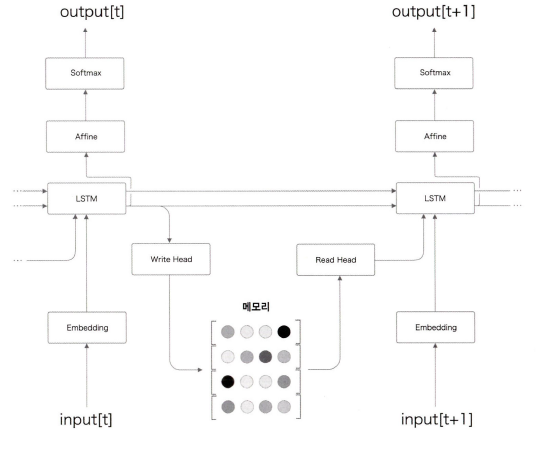
메로리 쓰기를 수행하는 Write Head 계층과 Read Head 계층이 새로 등장 했다.
각 시각에서 LSTM 계층의 은닉 상태를 Write Head 계층이 받아서 필요한 정보를 메모리에 쓴다.
그런다음 Read Head 계층이 메모리로부터 중요한 정보를 읽어 들여 다음 시각의 LSTM 계층으로 전달한다.
Write Head 와 Read Head 계층이 어떻게 메모리를 조작하는 것은, 2개의 어텐션, '콘텐츠 기반 어텐션'과 '위치 기반 어텐션'을 사용하여 메모리를 조작한다.
콘텐츠 기반 어텐션은 지금까지 본 어텐션과 같고, 입력으로 주어진 어느 벡터(Query 벡터)와 비슷한 벡터를 메모리로부터 찾아내는 용도로 이용된다.
한편 위치 기반 어텐션은 '이전 시각에서 주목한 메모리의 위치(=메모리의 각 위치에 대한 가중치)'를 기준으로 그 전후로 이동(시프트)하는 용도로 사용된다.
이 기술은 1차원의 합성곱 연산으로 구현된다.
메모리 위치를 하나씩 옮겨가며 읽어나가는 컴퓨터 특유의 움직임을 쉽게 재현할 수 있다.
(전공 과목인 '컴퓨터 구조'가 떠오른다....)
NTM을 통해 긴 시계열을 기억하는 문제와 정렬(=수들을 크기 순으로 나열) 등의 문제를 해결하였다.
정리
이번 8장에서는 Attention에 대한 전반적인 내용을 다루고 계층을 구현해 보았다.
어텐션이 정말 뛰어난 효과를 가진다는 것은 말그대로 어디에 '집중'하는지에 대한 기능으로 설명할 수 있다.
어텐션을 통하여 구현한 "Transformer"에 대해 간단히 말했는데, "Attention all you need"라는 논문을 읽고 리뷰를하고 코드 실습까지 해볼 생각이다.
이렇게 책한권이 끝났다. 책거리 하자 유후!!
