Object Detection
이미지나 동영상에서 사람, 동물, 차량 등 의미 있는 객체(object)의 종류와 그 위치(bounding box)를 정확하게 찾기 위한 컴퓨터 비전(computer vision) 기술.
일반적으로 검출 대상에 대한 후보 영역을 찾고 그 후보 영역에 대한 객체의 종류와 위치를 학습된 모델을 통해 예측한다. 이 과정을 위해서 영상 및 영상 내의 객체 종류(class)와 객체 위치(bounding box) 정보가 필요하다. 얼굴, 도로상의 보행자 및 차량 등의 인식에 딥 러닝(deep learning) 기반의 객체 탐지 기술이 많이 이용된다.
YOLOv8
-
YOLO 개요
-
You Only Look Once의 약어로, 2015년 Joseph Redmon이 아키텍처를 논문과 함께 발표함
-
YOLO가 등장하기 전까지는 Faster R-CNN 계열의 아키텍처(최대 7 FPS 성능)가 많이 사용되었지만, 2015년 평균 45 FPS 성능을 가진 YOLO의 등장으로 Object Detection 분야에 획기적인 발전이 이루어짐
-
~ YOLOv4 : C언어 기반 Darknet 아키텍처 사용
-
YOLOv5 ~ : PyTorch로 개발이 이루어짐
-
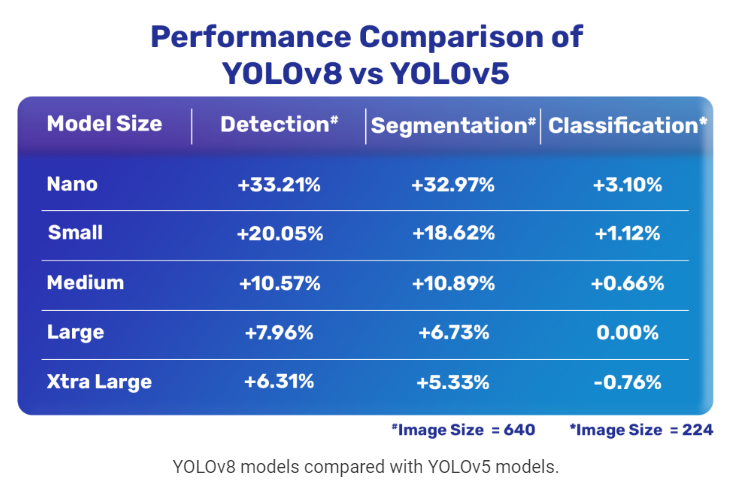
2023년 현재, 학습해야 하는 parameter의 수는 상대적으로 감소하고 속도(성능)은 증가한 YOLOv8까지 진화하였다.
YOLOv8은 ① 빠른 속도와 ② 사용자 친화적인 파이썬 인터페이스를 제공하는 것이 특징이다.
-
-
YOLOv8
- YOLOv8은 동일한 API를 이용하여 object detection 뿐만 아니라 이미지나 동영상에서의 image segmentation 또한 구할 수 있는 장점이 있다.
- 사전 학습된 YOLO 모델 loading → train → predict
(사전학습 모델 종류와 데이터 위치를 나타내는 yaml 파일만 바꾸어 동일한 API에서 object detection과 image segmentation 구현이 가능하다.)
Load data
import os
import zipfile
with zipfile.ZipFile('/content/test_image_dir.zip') as target_fle:
target_fle.extractall('/content/test_image_dir')
print('test images = ', os.listdir('/content/test_image_dir'))예측에 사용될 4장의 test 이미지를 colab에 업로드

(이미지 출처 : MS COCO Dataset)
Install YOLOv8
!pip install ultralyticspip install을 이용하여 yolov8과 실행에 필요한 라이브러리를 설치한다.
import ultralytics
ultralytics.checks()
Load pre-trained model
from ultralytics import YOLO
model = YOLO('yolov8n.pt')사전학습된 yolov8n 모델을 로드한다.
제공되는 사전학습된 모델로는 yolov8n, yolov8s, yolov8m, yolov8l, yolov8x이 있으며 n은 Nano를 의미한다.
모델의 크기가 증가할수록 정확도가 증가하지만 메모리를 차지하는 용량이 증가하는 trade-off가 존재한다.
print(type(model.names), len(model.names))
print(model.names)
model.names를 통해 현재 가지고 있는 모델이 어떤 class를 예측할 수 있는지 확인할 수 있다.
실행 결과 80개의 class를 예측할 수 있으며, 각각의 class는 0 : person, 1 : bicycle, 2 : car 등 특정 숫자와 그에 해당하는 class name이 매칭되어 있는 것을 알 수 있다.
Prediction
results= model.predict(source='/content/test_image_dir/*.jpg', save=True)predict 함수를 이용하여 source에 주어진 파일에 대해 예측을 수행한다.



각각의 이미지에 포함되어 있는 객체가 무엇이고 해당 객체가 몇 개인지 나타내주며, 이미지에서 객체의 위치(bounding box)와 객체가 어떤 class에 속하는지 확률값을 나타낸다.
import numpy as np
for result in results:
uniq, cnt = np.unique(result.boxes.cls.cpu().numpy(), return_counts=True)
uniq_cnt_dict = dict(zip(uniq, cnt))
print('\n{class num:counts} = ', uniq_cnt_dict, '\n')
for c in result.boxes.cls:
print('class num =', int(c), ', class_name =', model.names[int(c)])
predict 함수의 return 값 중 boxes.cls라는 attribute를 이용하면 각 객체를 나타내는 class의 고유한 값과, 그러한 class가 몇 개 있는지, 해당 class의 구체적인 이름 등을 알 수 있다. → 디버깅하거나 사용자 UI를 만들 때 유용하게 사용할 수 있다.
for i in results:
print(i.boxes)
print(i.boxes.xyxy) # x, y, x, y
print(i.boxes.xywh) # x, y, width, height
print(i.boxes.conf) # 확률
print(i.boxes.cls) # 클래스
print(i.names)위와 같은 방법으로도 탐지된 객체의 bounding box 좌표값을 얻을 수 있다.
boxes.xyxy로 설정하면 bounding box 네 꼭짓점의 좌표를 알 수 있다.
boxes.xywh는 x좌표, y좌표, 너비, 높이를 알 수 있다.
boxes.conf는 탐지된 객체의 정확도를 볼 수 있다.
boxes.cls는 탐지된 객체의 클래스를 확인할 수 있다.
SSD
Single Shot MultiBox Detector
SSD 모델은 Bounding Box에 대한 offset을 조절할 때, pixel과 feature들을 재추출하지 않음으로써 기존의 속도와 정확성의 trade-off 문제를 극복하고자 고안된 classification과 localization을 동시에 실행하는 단일 신경망 모델이다.
Single Shot은 한 번 forward 한다는 뜻이고 (1-stage detector), MultiBox는 detector에서 사용하는 anchor들이 많다는 것을 의미한다.
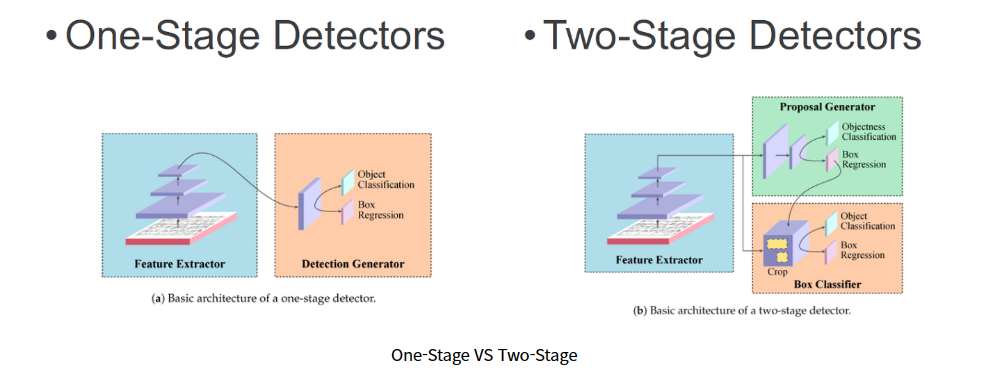
two-stage 모델은 Region Proposal과 Object Detection 단계를 분리해 전개되는 모델로 RCNN, SPP, Fast RCNN 등이 해당된다. (탐지 성능↑, 탐지 속도↓)
반면 one-stage 종류의 모델은 Region Proposal과 Object Detection을 분리하지 않고 동시에 수행하는 모델이다.
two-stage 모델의 탐지 속도 문제를 해결하기 위해 one-stage 모델이 개발되었다.
SSD 모델의 구조
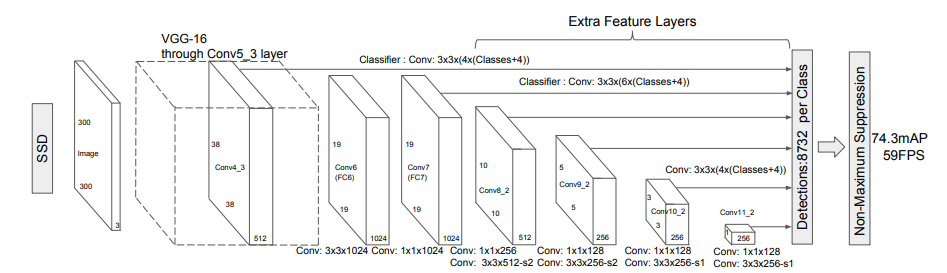
Base network로 VGG16을 사용, 이후 Extra Feature Layers를 추가한 구조
여러 사이즈의 Feature map 정보를 받아와 세부적인 정보를 함께 고려하며 default box를 활용해 다양한 형태의 object들을 detect
Example
미리 학습된 SSD 모델을 사용하여 샘플 이미지에서 객체를 감지하고 결과를 시각화한다.
# 패키지 설치
pip install numpy scipy scikit-image matplotlibimport torch
ssd_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd')
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')COCO 데이터 세트에서 사전 훈련된 SSD 모델과 모델 입력 및 출력의 형식 지정을 위한 유틸리티 메서드를 로드한다.
ssd_model.to('cuda')
ssd_model.eval()uris = [
'http://images.cocodataset.org/val2017/000000397133.jpg',
'http://images.cocodataset.org/val2017/000000037777.jpg',
'http://images.cocodataset.org/val2017/000000252219.jpg'
]객체 감지를 위한 입력 이미지를 준비
inputs = [utils.prepare_input(uri) for uri in uris]
tensor = utils.prepare_tensor(inputs)네트워크 입력을 준수하도록 이미지를 포맷하고 텐서로 변환한다.
with torch.no_grad():
detections_batch = ssd_model(tensor)object detection을 수행하기 위해 SSD 네트워크를 실행한다.
results_per_input = utils.decode_results(detections_batch)
best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]confidence가 40% 이상인 것만 가져오도록 출력을 필터링한다.
classes_to_labels = utils.get_coco_object_dictionary()COCO annotation을 다운로드한다.
# 시각화
from matplotlib import pyplot as plt
import matplotlib.patches as patches
for image_idx in range(len(best_results_per_input)):
fig, ax = plt.subplots(1)
# Show original, denormalized image...
image = inputs[image_idx] / 2 + 0.5
ax.imshow(image)
# ...with detections
bboxes, classes, confidences = best_results_per_input[image_idx]
for idx in range(len(bboxes)):
left, bot, right, top = bboxes[idx]
x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
ax.add_patch(rect)
ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
plt.show()
YOLOv8, SSD 결과 비교

MRCNN
(Mask R-CNN)
R-CNN 계열 모델은 4가지 종류(R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN)가 있다.
RCNN → Fast RCNN → Faster RCNN 으로 발전하면서 예측력은 비슷하게 유지하면서 train과 test 모두에서 속도가 상당히 빨라졌다.
위 3개 모델은 모두 객체 검출만을 위한 모델이었으나, Mask R-CNN은 Faster R-CNN을 확장하여 Object Detection + Instance Segmentation을 적용할 수 있는 모델이다.
(Object Detection과 Semantic Segmentation을 동시에 수행)
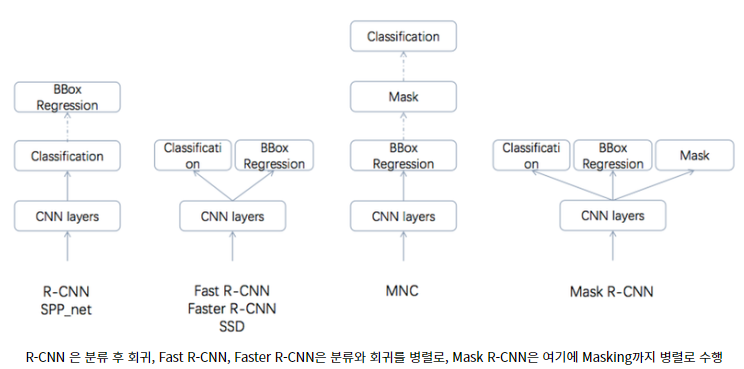
즉, Mask R-CNN은 Faster F-CNN이 검출한 객체 각각의 박스에 Mask를 씌우는 모델이다. 이를 위해서 기존의 Faster R-CNN은 객체 검출의 역할을 하고, 여기에 RoI(Region of Interest)에 segmentation을 해주는 작은 FCN(Fully Convolutional Network)를 추가한 구조를 갖는다.
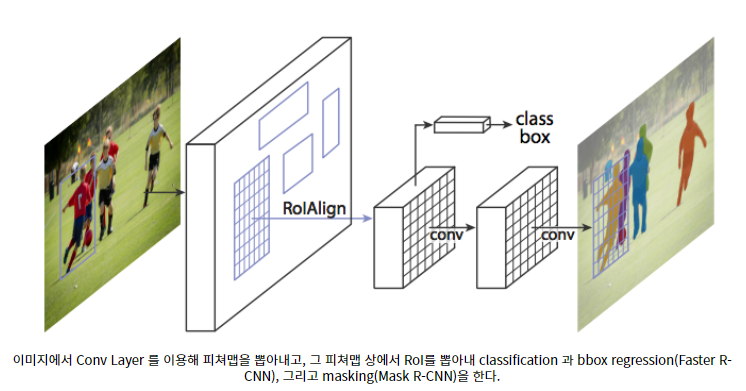
텐서플로우 v2.0 에서 layers 모듈 지원 X
