머신러닝 → 명시적인 규칙을 코딩하지 않고 기계가 데이터로부터 학습하여 어떤 작업을 더 잘하도록 만드는 것
머신러닝 시스템의 종류
지도 학습과 비지도 학습
머신러닝 시스템을 '학습하는 동안의 감독 형태나 정보량'에 따라 분류할 수 있다.
지도 학습, 비지도 학습, 준지도 학습, 강화 학습 등 네 가지 주요 범주로 나눈다.
① 지도 학습
supervised learning → 알고리즘에 주입하는 훈련 데이터에 레이블(답)이 포함된다.
-
전형적인 지도 학습 작업
-
분류 classification
(예: 스팸 메일 분류) -
회귀 regression : 주어진 입력 특성으로 값을 예측
(예: 중고차 가격 예측)
-
-
지도 학습 알고리즘
- k-최근접 이웃 k-nearest neighbors
- 선형 회귀 linear regression
- 로지스택 회귀 logistic regression
→ 클래스(레이블의 범주)에 속할 확률을 출력 - 서포트 벡터 머신 support vector machine(SVM)
- decision tree와 random forest
- 신경망 neural networks
② 비지도 학습
unsupervised learning → 훈련 데이터에 레이블 X
-
비지도 학습 알고리즘
-
군집 clustering
- k-means
- DBSCAN
- 계층 군집 분석 hierarchical cluster analysis (HCA)
-
이상치 탐지 outlier detection와 특이치 탐지 novelty detection
- one-class SVM
- isolation forest

-
차원 축소 dimensionality reduction
: 상관관계가 있는 여러 feature를 하나로 합쳐 (feature extraction) 너무 많은 정보를 잃지 않으면서 데이터를 간소화한다. → 머신러닝 알고리즘에 데이터를 주입하기 전 차원 축소 알고리즘을 사용하여 훈련 데이터의 차원을 줄이면 실행 속도가 빨라지고 디스크와 메모리를 차지하는 공간이 줄어들며, 경우아 따라 성능이 좋아지기도 한다.- 주성분 분석 principal component analysis (PCA)
- kernel PCA
- 지역적 선형 임베딩 locally-linear embedding (LLE)
- t-SNE (t-distributed stochastic neighbor embedding)
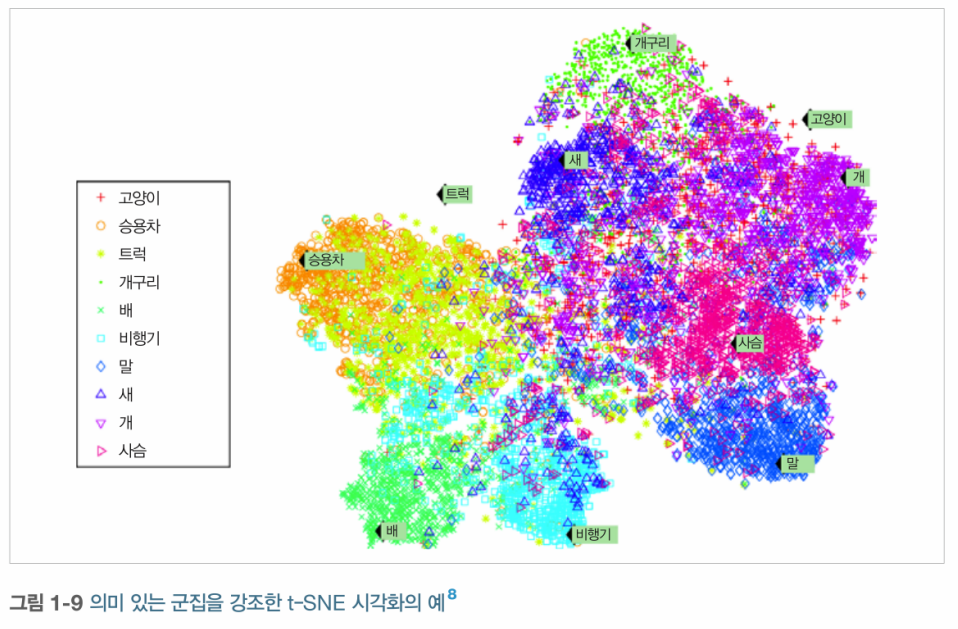
-
연관 규칙 학습 association rule learning
- Apriori
- Eclat
-
③ 준지도 학습
semisupervised learning
데이터에 레이블을 다는 것은 일반적으로 시간과 비용이 많이 들기 때문에 레이블이 없는 샘플이 많고 레이블된 샘플은 적은 경우가 많다.
어떤 알고리즘은 일부만 레이블이 있는 데이터를 다루는데, 이를 준지도 학습이라고 한다.
대부분의 준지도 학습 알고리즘은 지도학습과 비지도 하급의 조합으로 이루어져 있다.
(예: 심층 신뢰 신경망 deep belief network(DBN)은 여러 겹으로 쌓은 제한된 볼츠만 머신 restricted Boltzmann machine(RBM)이라 불리는 비지도 학습에 기초한다. RBM이 비지도 학습 방식으로 순차적으로 훈련된 다음 전체 시스템이 지도 학습 방식으로 세밀하게 조정된다.)
④ 강화 학습
reinforcement learning
학습하는 시스템을 에이전트라고 부르며, 환경 environment을 관찰해서 행동 action을 실행하고 그 결과로 보상 reward을 받는다.
가장 큰 보상을 얻기 위해 정책 policy이라고 부르는 최상의 전략을 스스로 학습한다.
(예: 알파고)
배치 학습과 온라인 학습
머신러닝 시스템을 분류하는 데 사용하는 다른 기준은 '입력 데이터의 스트림 stream으로부터 점진적으로 학습할 수 있는지 여부'이다.
① 배치 학습
batch learning
시스템이 점진적으로 학습할 수 없으며, 가용한 데이터를 모두 사용해 훈련시켜야 한다. 일반적으로 이 방식은 시간과 자원을 많이 소모하므로 보통 오프라인에서 수행된다. 먼저 시스템을 훈련시키고 그런 다음 제품 시스템에 적용하면 더 이상의 학습 없이 실행된다. (학습한 것을 단지 적용함)
⇒ 이를 오프라인 학습 offline learning 이라고 한다.
-
배치 학습 시스템이 새로운 데이터에 대해 학습하려면, 이전 데이터를 포함한 전체 데이터를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야 한다. 그런 다음 이전 시스템을 중지시키고 새 시스템으로 교체한다. → 전체 데이터셋을 사용해 훈련하는 데 많은 시간이 소요될 수 있다.
-
전체 데이터셋을 사용해 훈련하는 경우 많은 컴퓨팅 자원이 필요하다.
-
스마트폰 등 자원이 제한된 시스템이 스스로 학습을 위해 많은 자원을 사용하면 문제가 발생할 수 있다.
→ 이러한 경우 점진적으로 학습할 수 있는 알고리즘을 사용하는 것이 낫다.
② 온라인 학습
online learning
데이터를 순차적으로 한 개씩 또는 미니배치 mini-batch 라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킨다. 매 학습 단계가 빠르고 배용이 적게 들어, 시스템은 실시간 데이터를 즉시 학습할 수 있다.
온라인 학습을 사용하면 캄퓨터 한 대의 메인 메모리에 들어갈 수 없는 대량의 데이터를 학습할 수 있다.
온라인 학습 시스템에서의 중요한 파라미터 ⇒ 학습률 learning rate
- 학습률을 높게 하면 시스템이 데이터에 빠르게 적용하지만 예전 데이터를 금방 잊어버린다.
- 반대로 학습률이 낮으면 시스템의 관성이 더 커져 느리게 학습된다.
(하지만 새로운 데이터에 있는 잡음이나 대표성 없는 데이터 포인트에 덜 민감해짐)
사례 기반 학습과 모델 기반 학습
머신러닝 시스템은 '어떻게 일반화 generalize 되는가'에 따라 분류할 수 있다.
머신러닝은 주어진 train 데이터로 학습하고 새로운 데이터에서 좋은 예측을 만들어야 (일반화되어야) 한다. train 데이터에서 높은 성능을 내는 것이 좋지만, 진짜 목표는 새로운 샘플에 대해 잘 작동하는 모델을 만드는 것이다.
① 사례 기반 학습
instance-based learning
시스템이 train 샘플을 기억함으로써 학습하고, 유사도 측정을 사용해 새로운 데이터와 학습한 샘플을 비교하는 식으로 일반화한다.
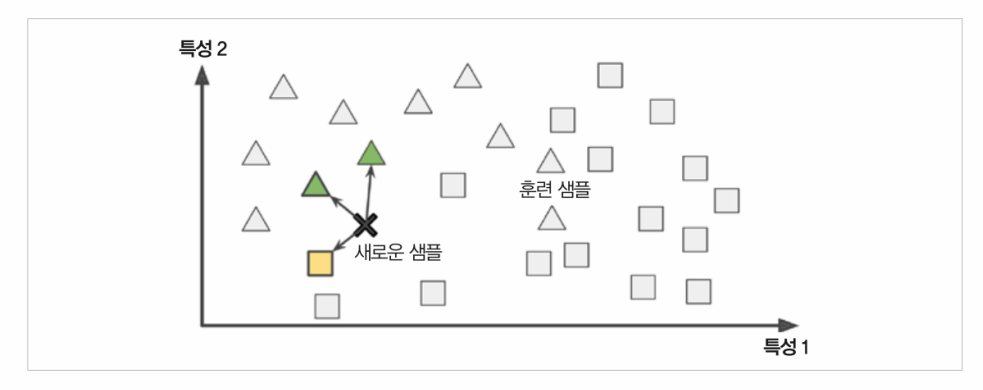
예) 그림에서 새로운 샘플은 가장 비슷한 샘플 중 다수가 삼각형이므로 삼각형 클래스로 분류된다.
② 모델 기반 학습
model-based learning
샘플들의 모델을 만들어 예측에 사용하는 것을 모델 기반 학습이라고 한다.
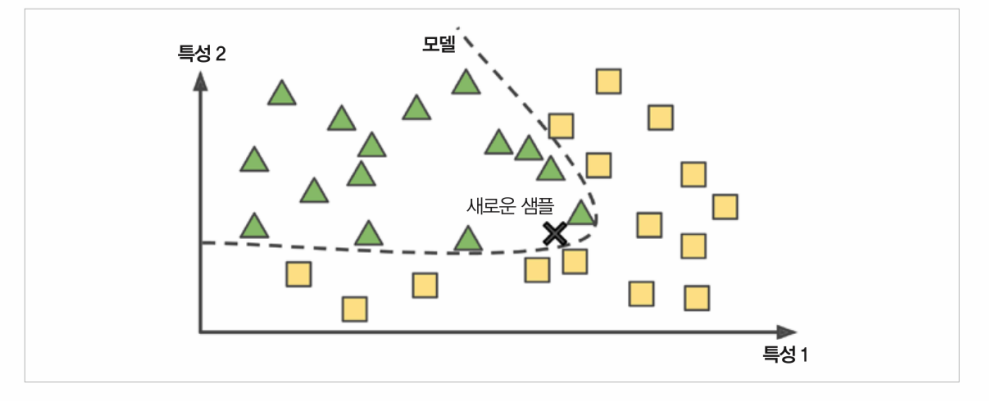
머신러닝 프로젝트 과정
- 데이터 분석
- 모델 선택
- 모델 training
(학습 알고리즘이 비용 함수를 최소화하는 모델 파라미터 찾기!)- 새로운 데이터에 모델 적용하여 예측
머신러닝의 주요 도전 과제
-
충분하지 않은 양의 train 데이터
→ 머신러닝 알고리즘이 잘 작동하려면 많은 양의 데이터가 필요하다. -
대표성 없는 훈련 데이터
→ 일반화하려는 사례들을 대표하는 훈련 세트를 사용하는 것이 중요하다.
(샘플이 작으면 샘플링 잡음 즉, 우연에 의한 대표성 없는 데이터가 생기고, 매우 큰 샘플이라도 표본 추출 방법이 잘못되면 대표성을 띠지 못할(샘플링 편향) 수 있다.) -
낮은 품질의 데이터
train 데이터가 에러, 이상치, 잡음으로 가득하다면 머신러닝 시스템이 내재된 패턴을 찾기 어려워 잘 작동하지 않을 것이다. → 데이터 정제 필요 -
관련 없는 특성
garbage in, garbage out
train 데이터에 관련 없는 특성이 적고 관련 있는 특성이 충분해야 한다. ⇒ 특성 공학 feature engineering- feature selection : 가지고 있는 feature 중 가장 유용한 것을 선택한다.
- feature extraction : feature를 결합하여 더 유용한 feature를 만든다. (차원 축소 알고리즘 등)
- 새로운 데이터를 수집해 새 feature를 만든다.
-
overfitting
모델이 훈련 데이터에는 너무 잘 맞지만 일반성이 떨어지는 경우를 의미한다.overfitting은 train 데이터에 있는 잡음에 비해 모델이 너무 복잡할 때 일어나고, 다음과 같은 방법으로 해결할 수 있다.
- 파라미터 수가 적은 모델을 선택하거나, 모델에 제약을 가하여 단순화시킨다.
- train 데이터를 더 많이 모은다.
- 오류 데이터 수정, 이상치 제거 등을 통해 train 데이터의 잡음을 줄인다.
-
underfitting
overfitting의 반대, 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 일어난다.
테스트와 검증
모델이 새로운 데이터에 얼마나 잘 일반화될지 알기 위해서는 새로운 데이터에 모델을 실제로 적용해 보아야 한다.
보통 데이터를 train dataset과 test dataset으로 나누어, train data를 사용해 모델을 훈련하고 test data를 사용해 모델을 테스트한다.
test dataset에서 모델을 평가함으로써 오차에 대한 추정값을 얻는다. → train data에서의 오차가 낮지만 일반화 오차가 높다면 이는 훈련 데이터에 overfitting 되었다는 뜻
하지만 일반화 오차를 test dataset에서 여러 번 측정했다면, 모델과 하이퍼파라미터가 test set에 최적화된 모델을 만들어 새로운 데이터에 잘 작동하지 않을 수 있다.
이러한 문제를 해결하기 위해 train data의 일부를 떼어내어 validation set를 만들어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택한다.
→ train set에서 다양한 하이퍼파리미터 값을 가진 여러 모델을 훈련하고, validation set에서 가장 높은 성능을 내는 모델 선택. 최종 모델을 test set에서 평가하여 일반화 오차를 추정한다.
이 방법은 일반적으로 잘 동작하지만 validation set가 너무 작거나 너무 크다면 문제가 될 수 있다. 이를 해결하기 위해 cross-validation을 수행한다.
(작은 validation set 여러개를 사용해 반복적인 교차 검증을 수행, validation set 마다 나머지 데이터에서 훈련한 모델을 해당 validation set에서 평가한다.)
