결정 트리
트리 모델의 기본이 되는 모델이다. 단순히 생각하면 어떠한 특성을 기준으로 기준을 만들어서 해당하면 왼쪽, 해당이 안되면 오른쪽에 놓는 것을 반복해서 수행하는 것이라 보면 된다. 기준을 만드는 곳을 노드라고 한다. 이 모델을 만드는 기준은 불순도가 기준이다. 여기서는 지니 불순도를 이용하였다. 부모 노드와 자식 노드의 불순도가 가장 크게 되는 값을 정보 이득이라고 하는데, 이 값이 가장 크게 모델이 만들어진다. 마지막으로 결정트리는 정규화가 필요 없다.
지니 불순도 = 1 - (음성 클래스 비율의 제곱 + 양성 클래스 비율의 제곱)
정보 이득 = 부모 불순도 - {(왼쪽 노드의 샘플 수 / 부모 노드의 샘플 수 ) X 왼쪽 노드의 불순도 + (오른쪽 노드의 샘플 수 / 부모 노드의 샘플 수 ) X 오른쪽 노드의 불순도}
# 결정트리 모델을 통한 분류
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state = 42)
dt.fit(train_scaled, train_target)# 트리 모델 모형 만들기
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize = (10, 7))
plot_tree(dt)
plt.show()
# 가지치기
dt = DecisionTreeClassifier(max_depth = 3, random_state = 42)
dt.fit(train_scaled, train_target)
plt.figure(figsize = (15, 10))
plot_tree(dt, filled = True, feature_names = ['alcohol', 'sugar', 'pH'])
plt.show()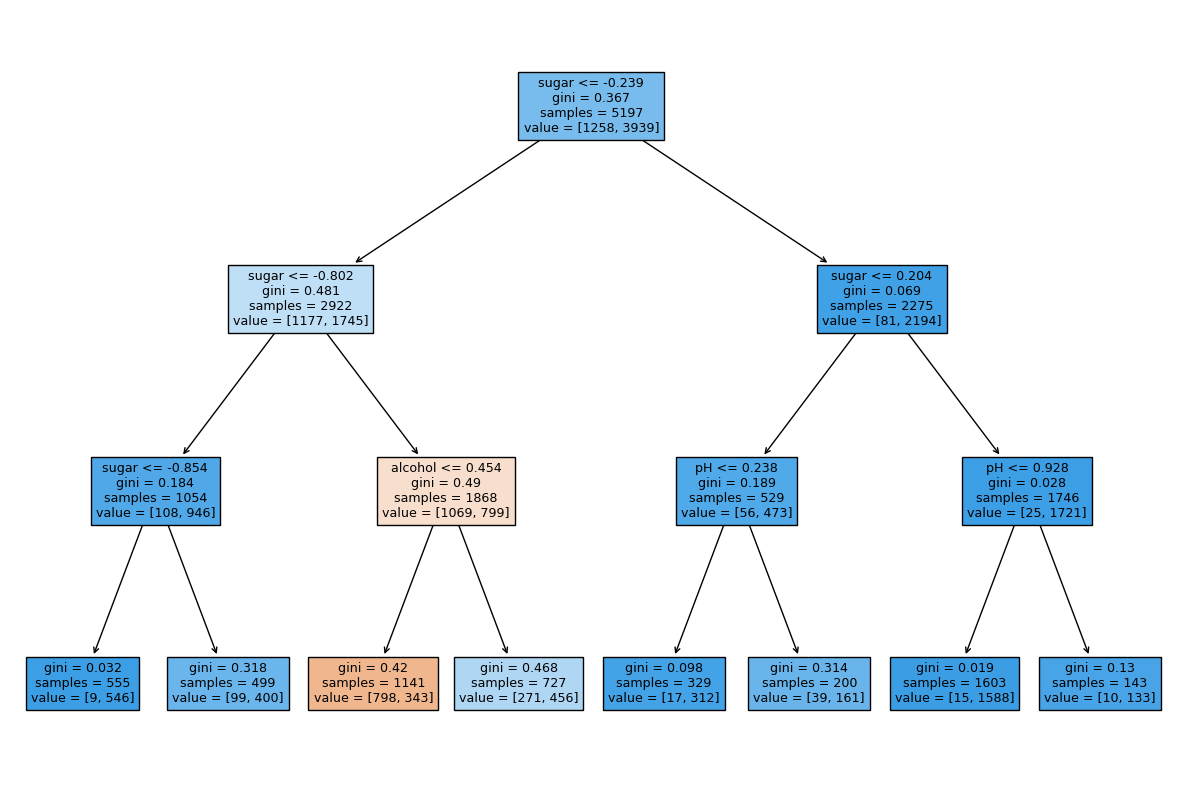
교차 검증
우선 이전에는 훈련 세트와 테스트 세트로만 데이터를 분할해서 사용했는데, 이제는 훈련 세트와 테스트 세트로 나눈뒤 다시 훈련 세트를 훈련 세트와 검증 세트로 나누어서 사용한다. 테스트 세트는 모델을 다 만들고 평가에만 사용하고, 모델의 적합도를 평가해 모델을 수정하는데는 검증 세트만을 이용한다.
교차 검증은 데이터를 n개의 세트로 나누어 검증과 훈련의 역할을 번갈아 가며 수행하도록 하게 하는 것이다. 여기서 기본적으로 k-폴드 교차검증을 이용하는데, 데이터를 몇으로 분할 하느냐에 따라 이 k값이 결정된다.
# 교차검증(5-폴드 교차검증)
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)하이퍼파라미터 튜닝
머신러닝 모델을 구축할때에 사람이 지정해야 하는 값을 하이퍼파라미터라고 하는데, 이 값을 어떻게 설정해야 좋은 모델이 만들어지는지 모르기 때문에 검증값이 가장 높게 나오는 최적의 값을 찾으려면 그리드 서치 를 사용해야 합니다. 원하는 하이퍼파라미터에 넣을 값을 리스트로 정리해서 그리드 서치에 넘겨주면, 머신러닝 모델이 알아서 최적의 값을 찾아줍니다.
# 하이퍼파라미터 튜닝
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
gs = GridSearchCV(DecisionTreeClassifier(random_state = 42), params, n_jobs = -1)
gs.fit(train_input, train_target)검증값을 리스트로 넘겨줄 경우 그 값에서만 돌기 때문에 정확하지 않을 수도 있고, 정확한 값을 찾기위해 넘겨주는 리스트를 촘촘하게 할 경우 그리드 서치를 하는데 시간이 오래 걸릴 수도 있습니다. 이를 해결하기 위해 랜덤 서치 를 할 수도 있는데, 어떤 범위의 값을 랜덤하게 돌면서 그리드 서치와 같이 가장 좋은 하이퍼파라미터 값을 찾아주는 것입니다.
# 랜덤 서치
from scipy.stats import uniform, randint
from sklearn.model_selection import RandomizedSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25)
}
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state = 42), params, n_iter = 100, n_jobs = -1, random_state = 42)
gs.fit(train_input, train_target)앙상블 학습
앙상블 학습은 여러개의 모델을 합쳐서 한개의 모델을 만드는 것을 의미한다.
첫번째로 배운 앙상블 학습은 랜덤 포레스트이다. 이름에서 보시다시피 결정 트리들을 합쳐서 모델을 만드는 것이다. 전체 데이터에서 부트스트랩으로(중복 허용하여 뽑기) 전체 데이터의 수만큼 뽑은 후 결정 트리를 여러개 만들어(기본 100개) 클래스별 확률을 평균시켜 가장 높은 확률을 가진 클래스로 예측을 하는 것이다.
엑스트라 트리는 랜텀 포레스트와 매우 유사하지만 샘플을 부트스트랩이 아닌 전체 데이터를 이용하고, 대신 결정트리에서 노드를 분할 할때에 랜덤으로 분할 한다는 점이 다른 점이다.
그레이디언트 부스팅은 이름에서 그레이티언트(점진적) 에서 알 수 있듯이 경사 하강법을 이용해 트리를 앙상블에 하나씩 추가해가며 점진적으로 앙상블을 만드는 것이다.
히스토그램 기반 그레이디언트 부스팅은 입력되는 특성을 256개의 구간으로 나누어 그레이디언트 부스팅을 하는 것이란다. 사실 잘 모르겠다.
과제
-
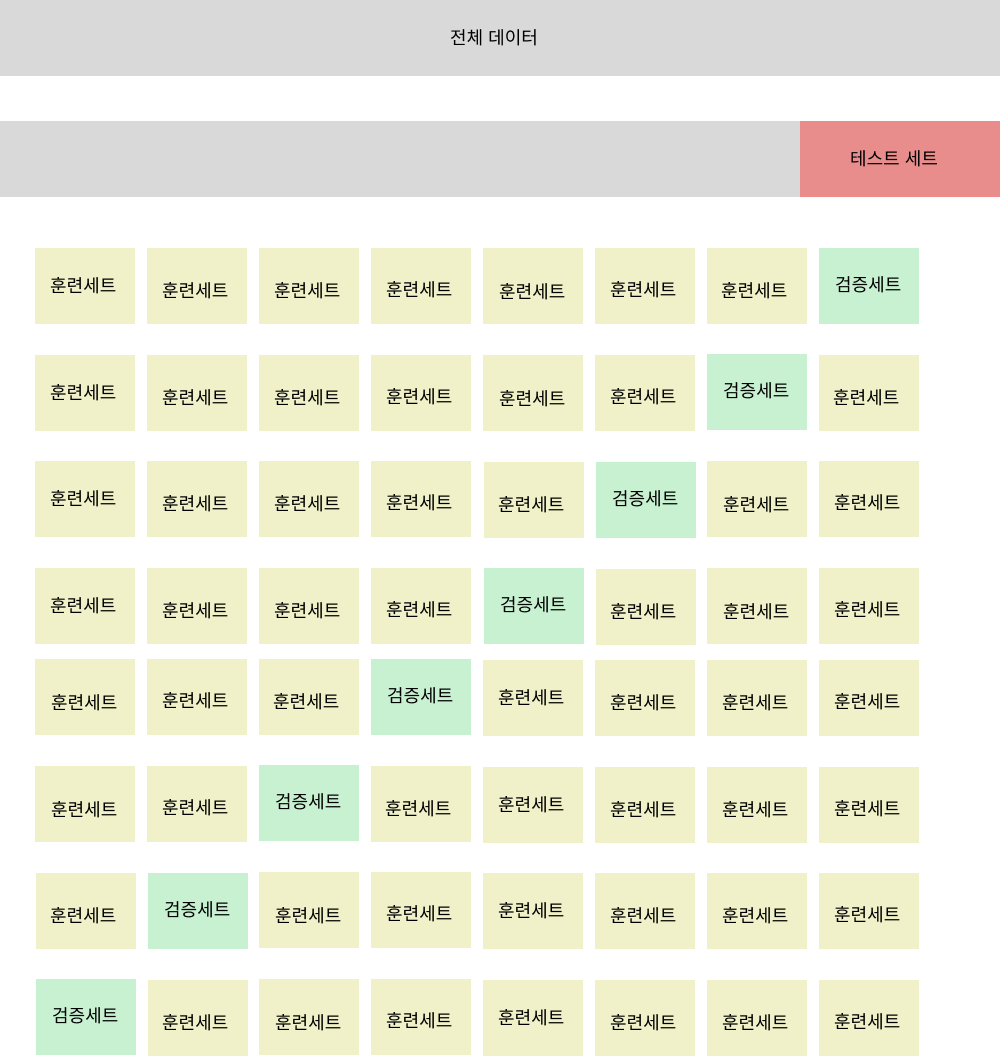
교차 검증 그림으로 설명하기
교차검증은 테스트 세트를 제외한 데이터들을 k개로 나누어 검증세트를 한번씩 수행하고 나머지 데이터들이 훈련세트를 수행하는 방식으로 작동한다.
-
앙상블 모델 손코딩 코랩화면 캡처하기