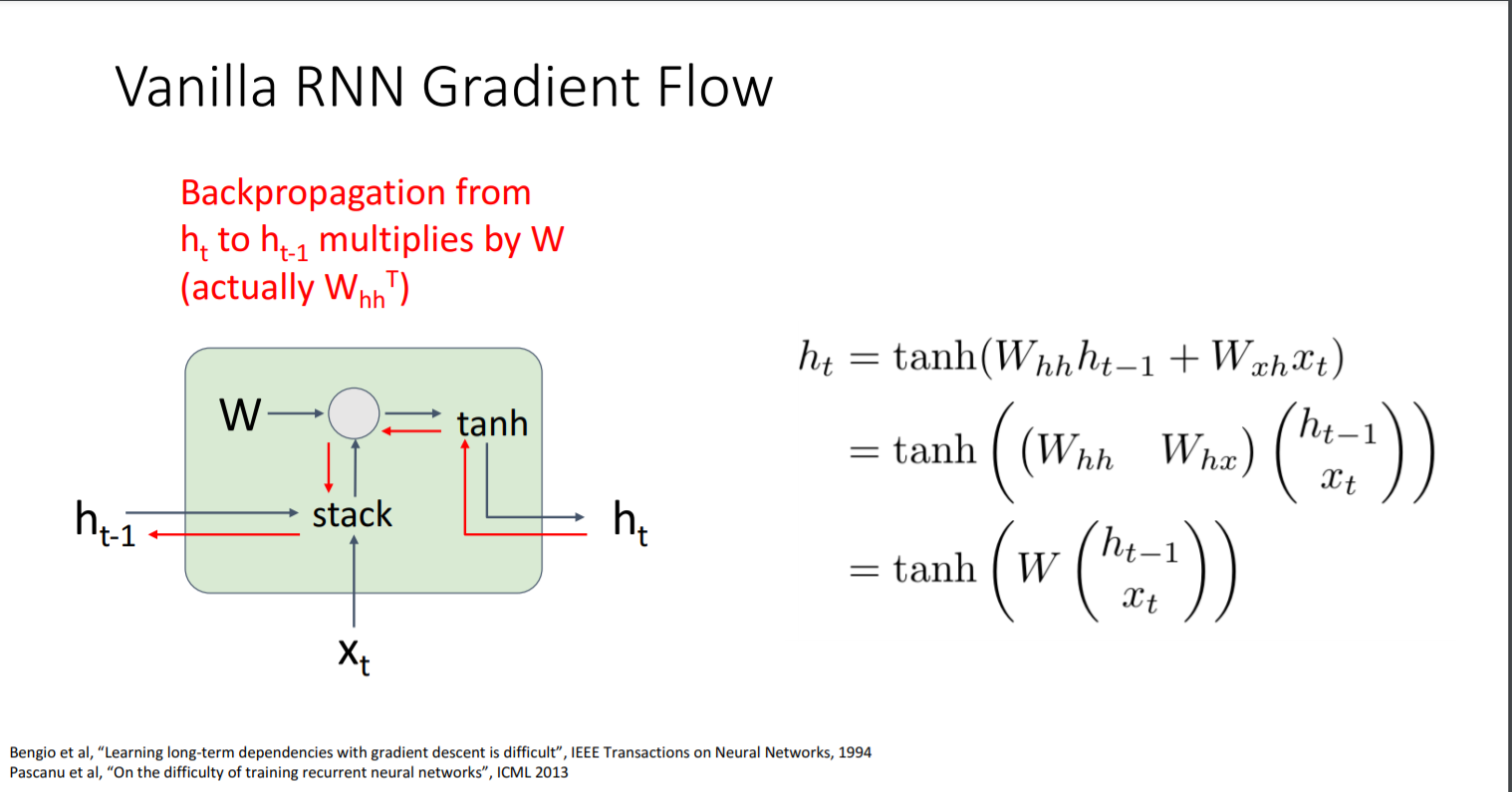
RNN은 같은 weight matrix를 사용하기 때문에 입력 sequence의 길이가 어떻든 간에 사용할 수 있다는 이점이 있다.
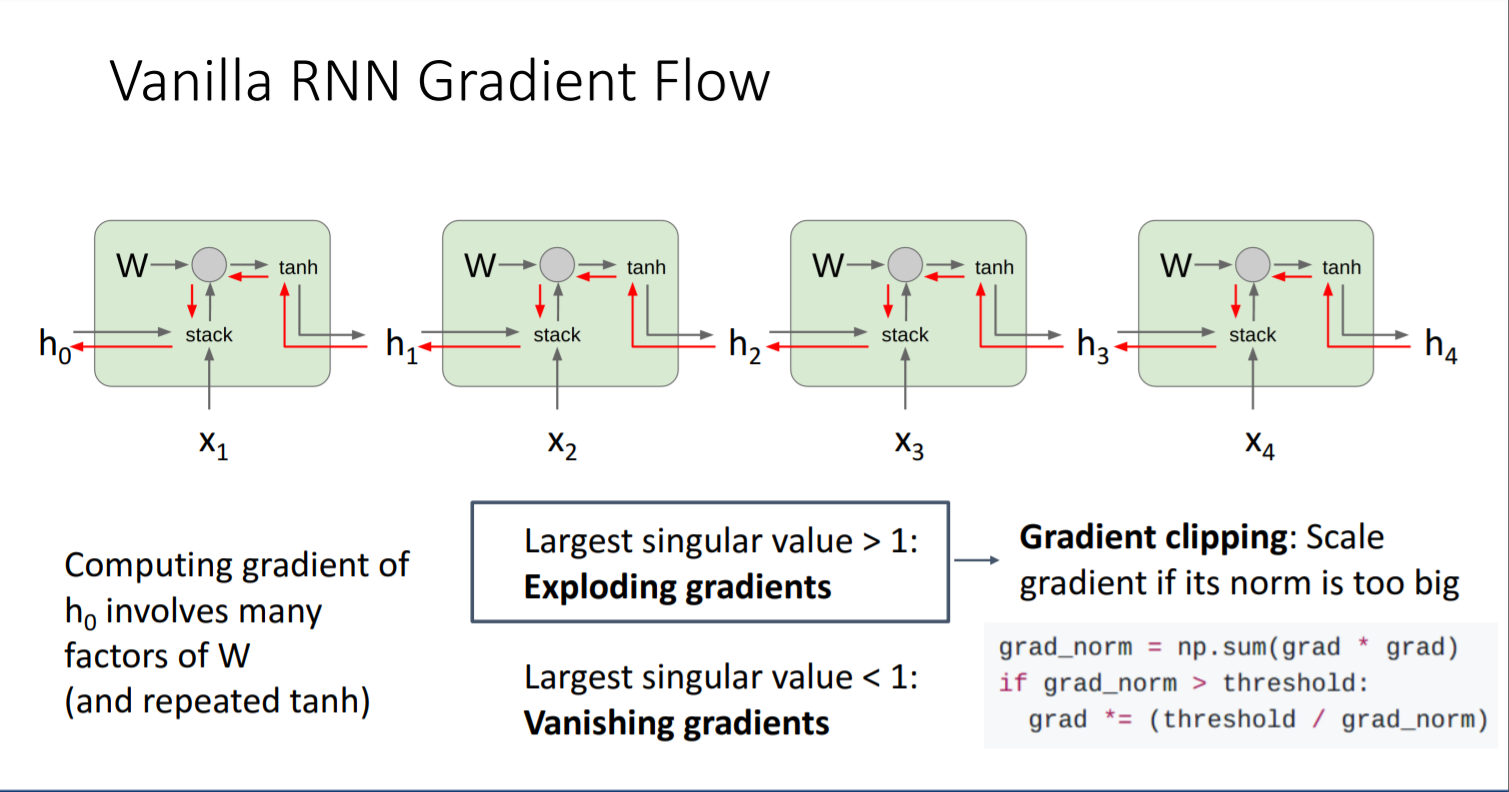
하지만 단점 역시 존재한다. 가장 기본적인 형태의 RNN형태를 통해 그 단점이 무엇인지 살펴보자. Backpropogation을 할 때 gradient flow 상 두 가지 문제가 발생한다.
- 문제 1: tanh nonlinearity 문제
tanh는 nonlinearity를 완화시키는 역할을 수행한다. 하지만 nonlinearity가 완전히 해소되는 것이 아니기 때문에 문제가 발생하는 것이다. - 문제 2: 가중치 행렬의 transpose로 곱하는 문제
하나의 RNN 블록을 통과할 때 가중치 행렬의 transpose로 곱하는 것이 문제가 되지 않지만, 위 그림에서 보다시피 여러 블록을 통과하게 되면 gradient 상 문제가 발생한다.- 문제 2-1: 가장 큰 singular value > 1일 때,
exploding gradient가 발생
해결방법: gradient clipping - 문제 2-2: 가장 작은 singular value < 1일 때,
vanishing gradient가 발생
해결방법: RNN 구조 자체를 바꾼다.
- 문제 2-1: 가장 큰 singular value > 1일 때,
그래서 문제 2-2를 해결하기 위해 LSTM 구조를 만든 것이다.
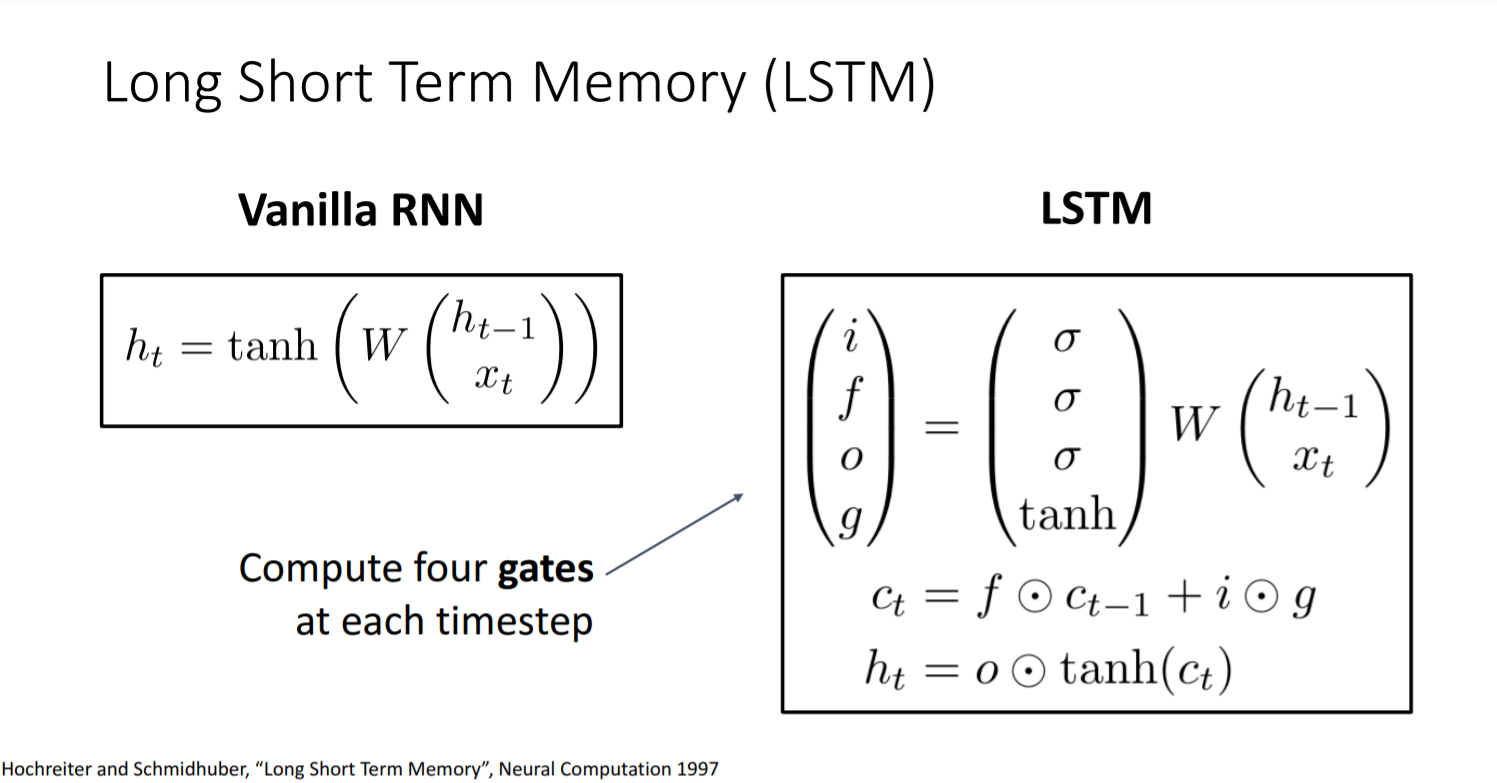
- 기존 RNN 구조와의 차이점?
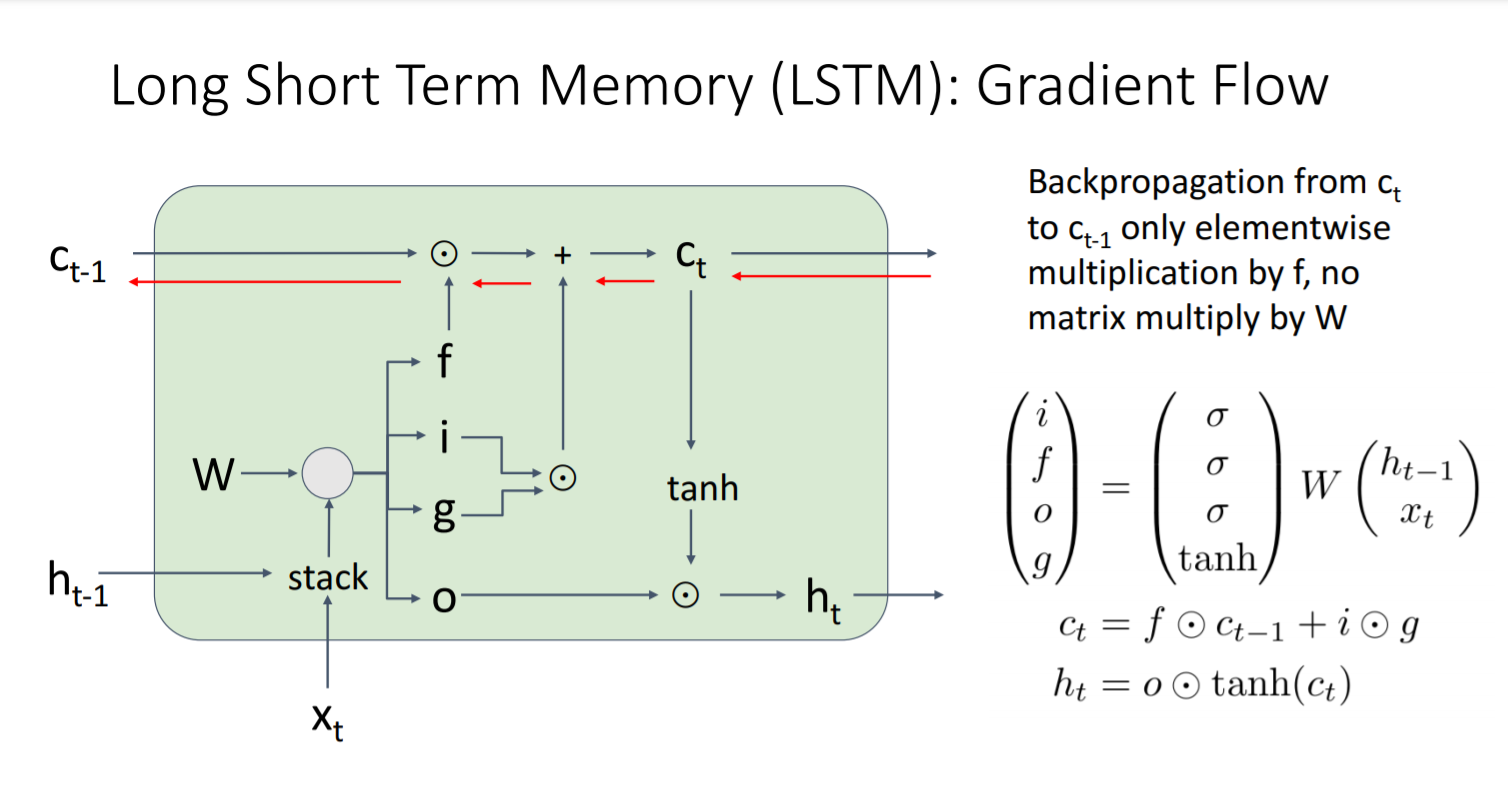
: hidden vector의 수 - 기존 RNN: 하나의 step 당 하나의 hidden vector(h(t))를 생성
- LSTM: 하나의 step 당 두 개의 hidden vector(h(t), c(t))를 생성
- Output을 hidden vector가 아닌 4개의 게이트로 설정한다
: 주의할 점: 비선형성을 다르게 설정한다- sigmoid[0,1]: input, forget, output gate
- tanh[-1,1]: gate gate
- 여기서 4개의 게이트 벡터의 크기는 h
- 직전의 hidden vector와 현재의 input과 결합
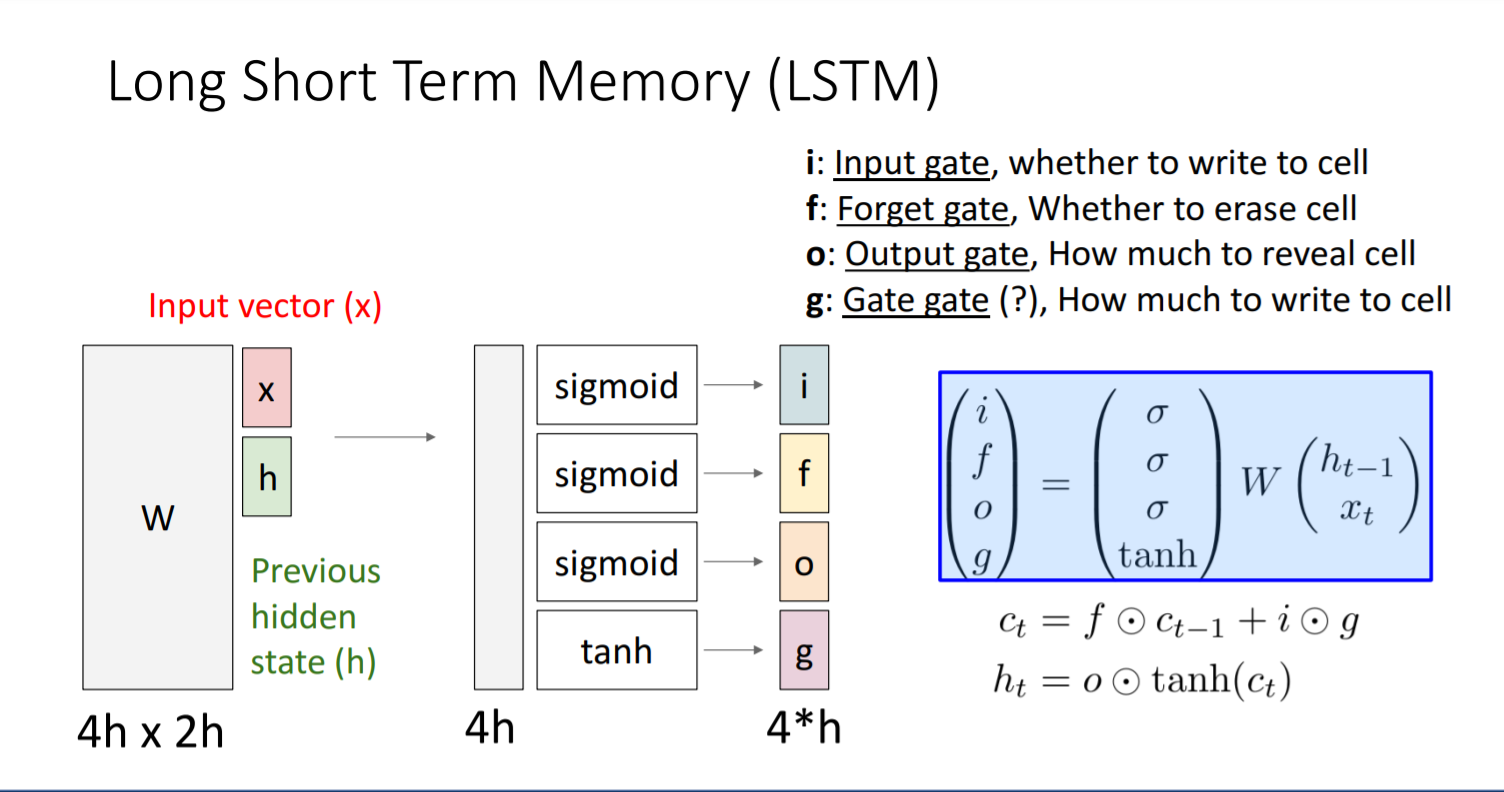
- Output을 hidden vector가 아닌 4개의 게이트로 설정한다
- LSTM의 parameter 설명
- LSTM의 구조가 gradient flow 문제를 완벽하게는 아니지만 어느정도 어떻게 해결했는지 설명
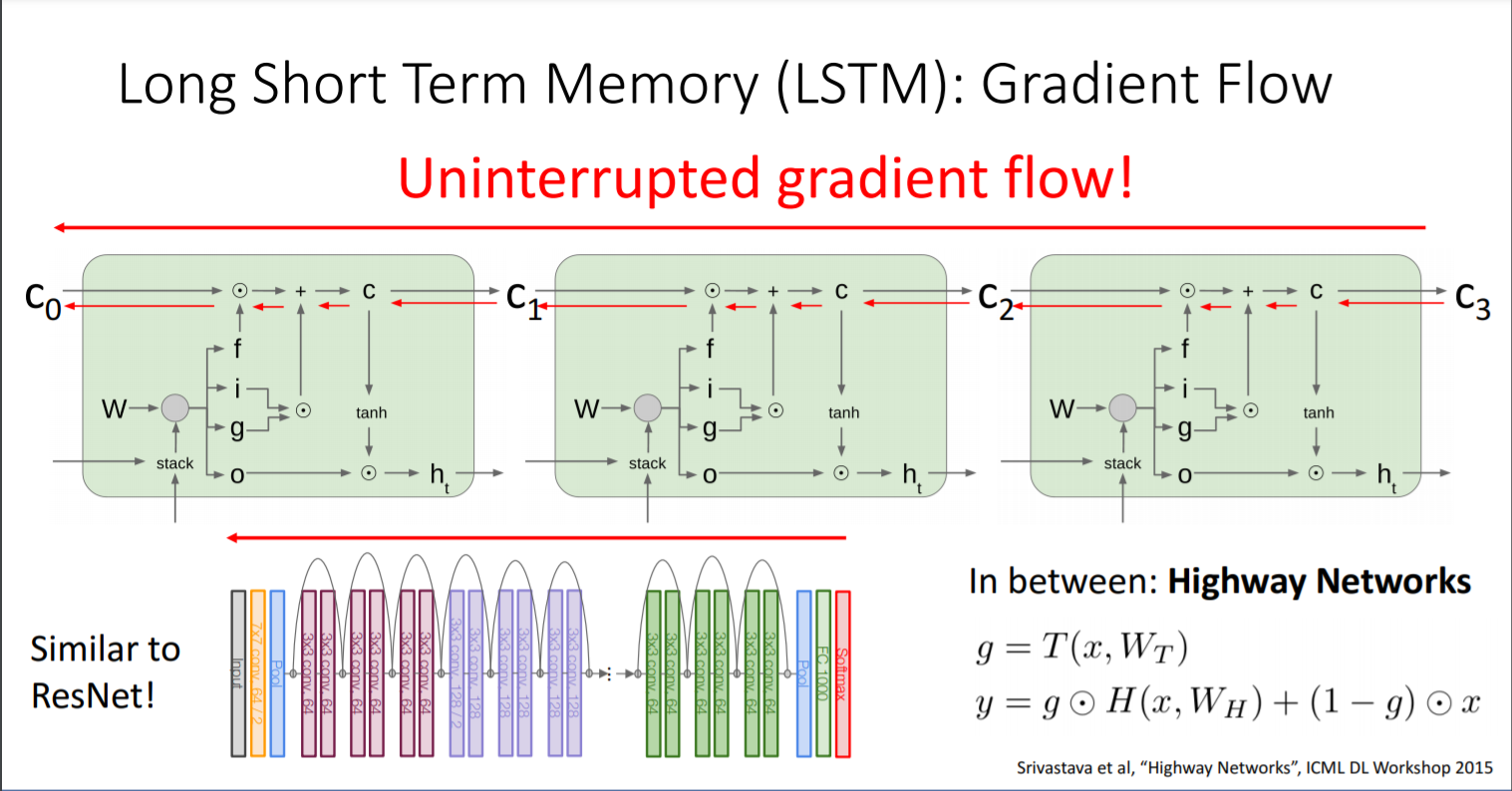
- LSTM의 구조가 RNN의 구조와 유사하다. 이처럼 유사한 다른 구조에서 아이디어를 얻는 경우가 많다.

https://github.com/aacara