Convolutional Networks
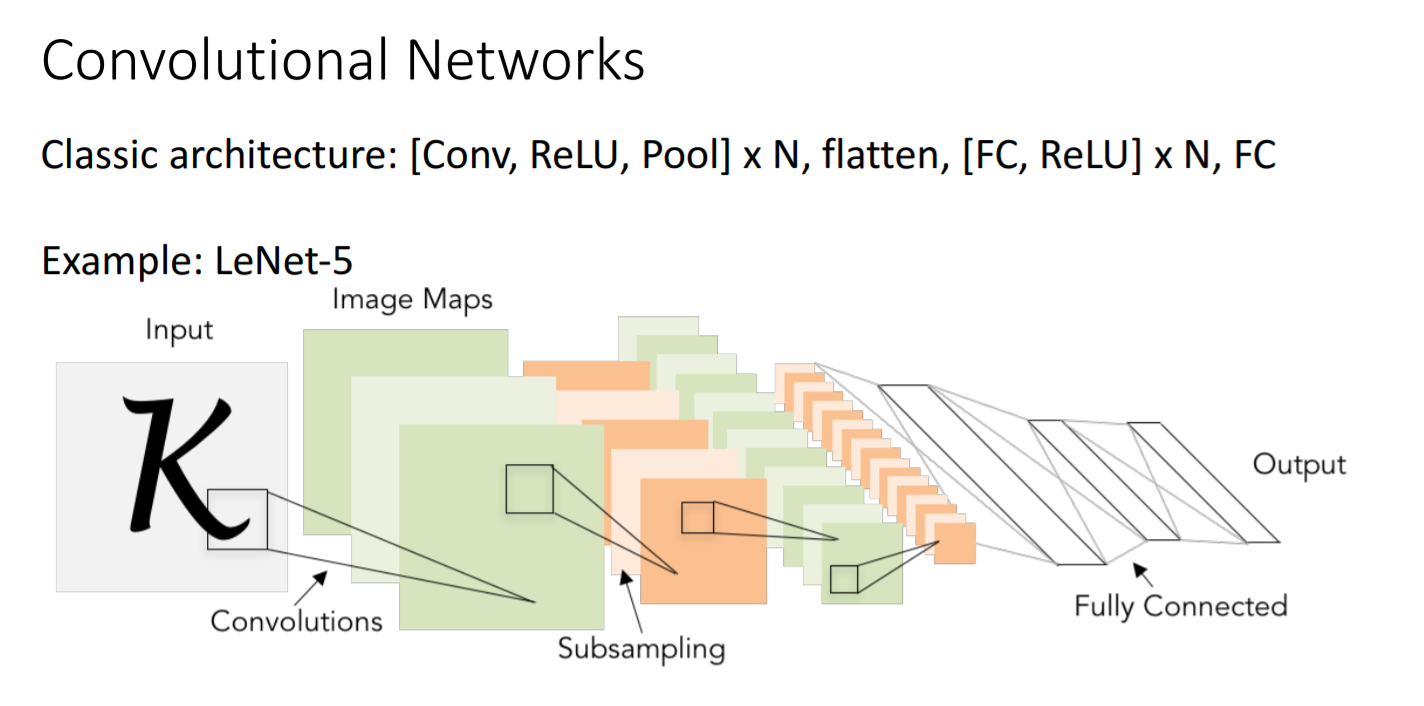
Convolutional Network는 convolutional layer과 max pooling layer으로 크게 두 부분으로 나눌 수 있다.
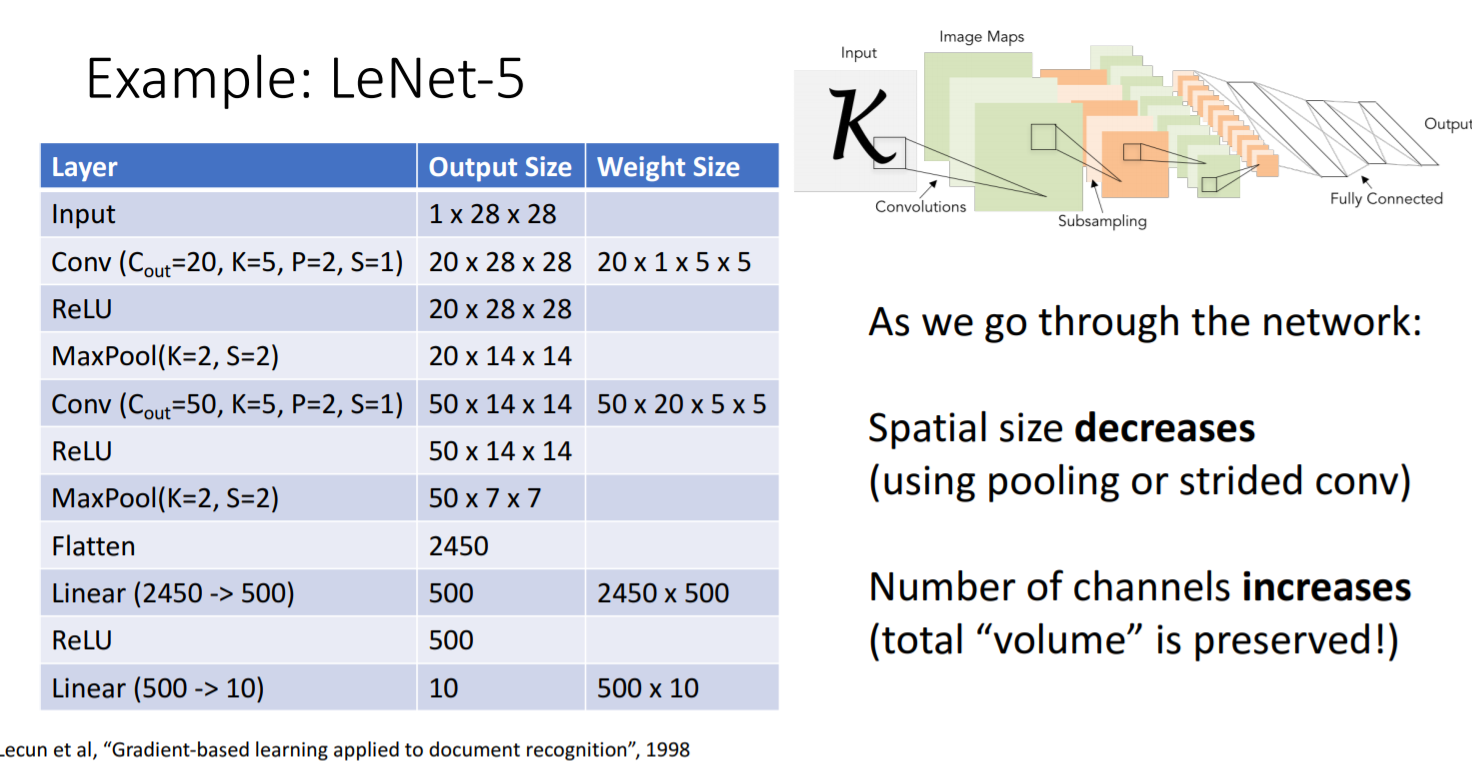
Input layer는 색깔이 없는 1, 28 28크기의 이미지가 입력된다. Convolutional layer 뒤에는 relu activation function을 통과시킨다. Maxpool에서 kernal size를 2 2, stride = 2로 설정해주면 이미지의 크기가 절반으로 줄어든다. 그 후 2차원 array를 1차원으로 flatten해주고 마지막에는 분류되는 개수로 크기를 최종적으로 줄인다.
- Q1) Maxpooling에서 Max is not unique?
- A) 전영역이 0이 되는 경우 잘 발생하지 않으니 걱정하지 않아도된다.
- Q2) Maxpooling에서 이미 비선형성이 구현되는데 굳이 relu activation function쓰는 이유?
- A) 물론 relu를 통해 비선형성을 구현할 필요성이 maxpooling에 의해 사라졌지만, 최근 모델들에서는 그럼에도 불구하고 regularity를 위해 relu를 거의 사용한다.
- layer를 더할 때 pooling layer과 strided convolutional layer를 통과하면서 spatial size는 줄어드나, 필터의 개수가 늘어나면서 total values는 보존된다. train해야 할 값이 너무 많으므로 이 과정에서 문제가 발생한다. 이러한 구조를 training시키기 어렵다. 이 경우 training시키기 어렵다는 뜻은 deep한 neural network에서 convergence issue가 발생한다는 것이다.
- 해결방안?
Batch Normalization
- Normalization이란?
- 평균이 0, 분산이 1인 정규분포로 나타내는 것
- 방법은?
- 평균을 빼주고 표준편차로 나눠주면 된다
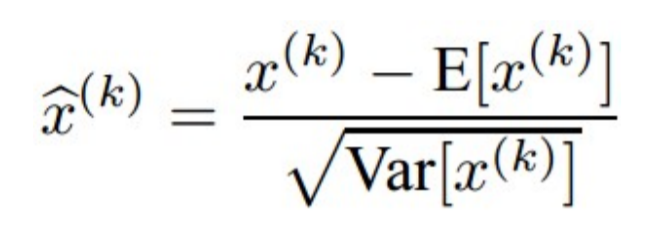
- 사용 이유?
- internal covariant shift를 조정시켜줘서 optimization 성능을 높인다.
- 구체적으로 구현하는 방법은?
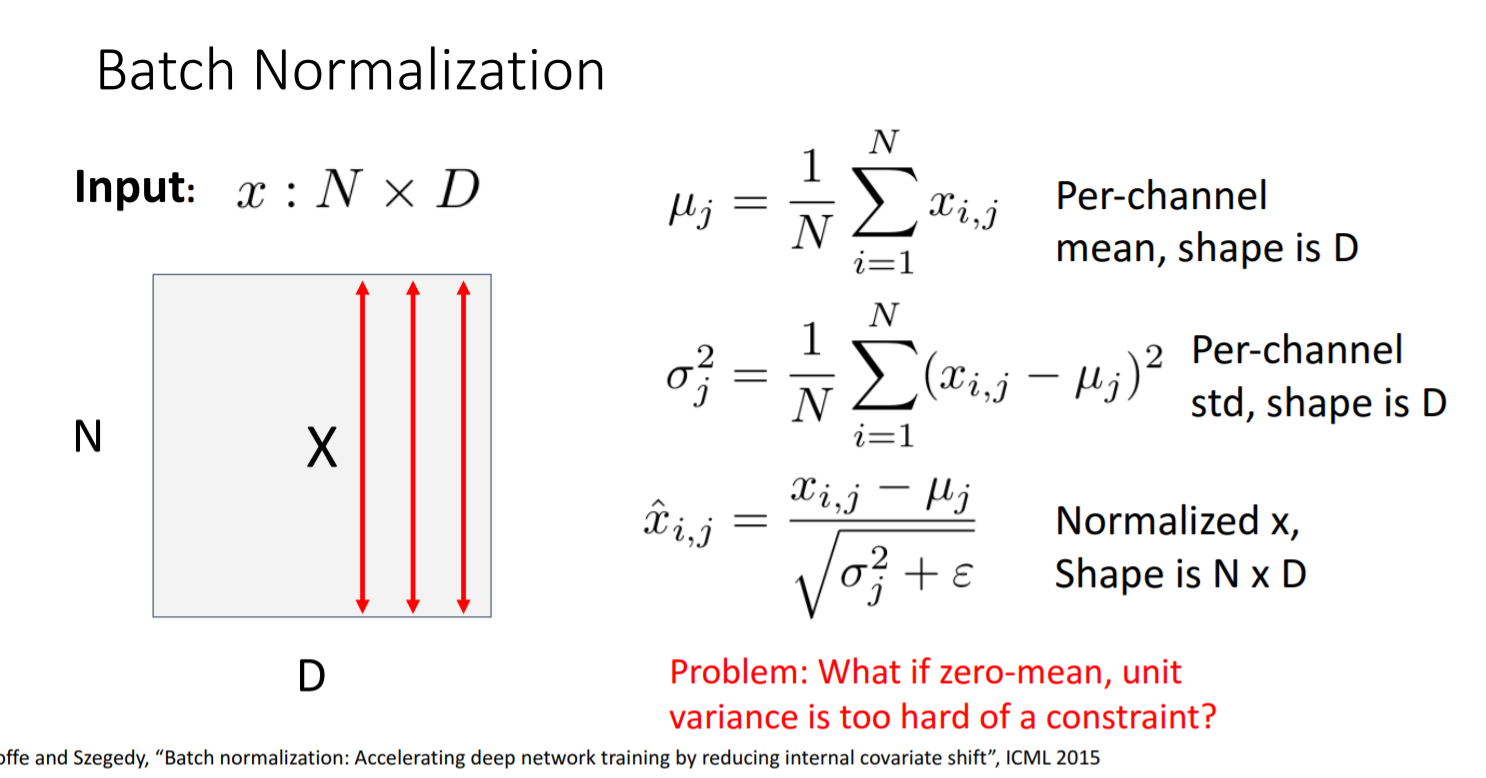
열을 기준으로 연산한다. - N: batch dimension
- D: number of dimensions in each vector
- 연산 과정: batch dimension의 평균과 분산을 구한다. (열의 평균, 분산) 그 후, batch dimension을 또 평균한다.
- epsilon의 의미: 분산이 0일 경우 분모가 0이 되지 않도록 작은 수를 지정해주는 것
- Batch normalization의 문제점?
- 원래 각 요소는 independence를 유지하는데, 평균화와 분산화 과정에서 dependency가 생긴다.
- 해결방안: training할 때와 testing할 때 구분한다.
Training할 때는 학습이 진행될 때의 평균값을 계속 추적해서 그 값을 사용한다. Testing할 때는 training 때 구한 최종적인 평균값과 분산값을 고정시켜서 사용한다. 이로써 testing할 때의 요소들 간의 independency를 보존시켰다.
Michigan University의 Justin Johnson의 Deep Learning for Computer Vision, 10강 내용입니다.

https://github.com/aacara