
8장 컴퓨터 비전을 위한 딥러닝
이 장에서 소개할 합성곱 신경망은 컨브넷(convnet)이라고 불리운다. 이 딥러닝 모델은 이제 거의 대부분의 컴퓨터 비전 애플리케이션에 사용된다.
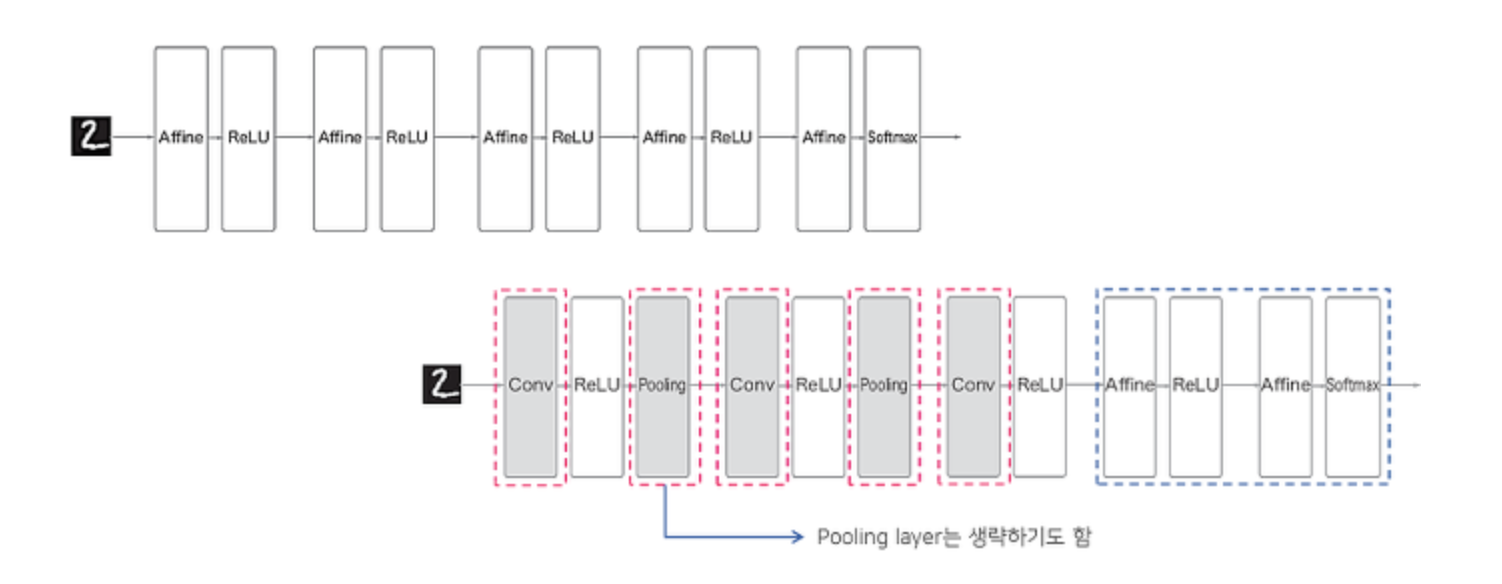
간단한 컨브넷 만들기
# 간단한 컨브넷 만들기
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(28, 28, 1)) #shape 설정
x = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(inputs) #첫번째 컨브넷 레이어와 인풋 연결
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = layers.Flatten()(x) # 3d -> 1d 펼치기
outputs = layers.Dense(10, activation='softmax')(x) # 다중분류이므로 softmax적용, 분류수 : 10
model = keras.Model(inputs=inputs, outputs=outputs) # 모델껍데기 만들기
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)) # input shape에 맞게 수정
train_images = train_images.astype('float32') / 255 # 정규화
test_images = test_images.reshape((10000, 28, 28, 1)) # input shape에 맞게 수정
test_images = test_images.astype('float32') / 255 # 정규화
model.compile(optimizer='rmsprop',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64) #훈련
# 컨브넷 평가
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('테스트 정확도: {:.3f}'.format(test_acc))다른 것은 모두 이전장에서 보았던 코드들이지만, Conv2D레이어와MaxPooling레이어의 역할을 이 코드 뒤에서 설명한다.
합성곱 연산이란
완전 연결 층과 합성곱 층 사이의 근본적인 차이는 Dense 층은 입력 특성 공간에 있는 전역 패턴을 학습하지만, 합성곱 층은 지역 패턴을 학습한다. 이미지일 경우 작은 2D윈도우로 입력해서 패턴을 찾는다. 즉 2D이미지의 경우 한 이미지를 여러 공간으로 나누어 해당 공간들을 학습하는 것이고, Dense층의 경우 모두 학습한다.
- 학습된 패턴은 평행 이동 불변성을 가진다. 컨브넷이 이미지의 특정, 예로 오른쪽 아래 모서리에서 어떤 패턴을 학습했다면, 다른 곳에서도 이 패턴을 인식할 수 있다. 즉 적은 수의 훈련 샘플을 사용해서 일반화 능력을 가진 표현을 학습할 수 있다.
- 컨브넷은 패턴의 공간적 계층구조를 학습할 수 있다. 처음 컨브넷층이 작은 지역 패턴을 학습하고, 두번째 컨브넷 층은 처음 층의 특성으로 더 큰 패턴을 학습한다. 이러한 방식으로 컨브넷은 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있다.
완전 연결 계층의 문제점
완전연결 계층(fully connected layer)을 이용해 MNIST 데이터셋을 분류하는 모델을 만들 때, 3차원(세로, 가로, 채널)인 MNIST 데이터(28, 28, 1)를 입력층(input layer)에 넣어주기 위해서 아래의 그림(출처: cntk.ai)처럼, 3차원 → 1차원의 평평한(flat) 데이터로 펼쳐줘야 했다. 즉, (28, 28, 1)의 3차원 데이터를 784크기의 1차원 데이터로 바꾼다음 입력층에 넣어줬다.
이러한 완전연결 계층의 문제점은 바로 '데이터의 형상이 무시'된다는 것이다. 이미지 데이터의 경우 3차원(세로, 가로, 채널)의 형상을 가지며, 이 형상에는 공간적 구조(spatial structure)를 가진다. 예를 들어 공간적으로 가까운 픽셀은 값이 비슷하거나, RGB의 각 채널은 서로 밀접하게 관련되어 있거나, 거리가 먼 픽셀끼리는 관련이 없는 등, 이미지 데이터는 3차원 공간에서 이러한 정보들이 내포 되어있다. 하지만, 완전연결 계층에서 1차원의 데이터로 펼치게 되면 이러한 정보들이 사라지게 된다.
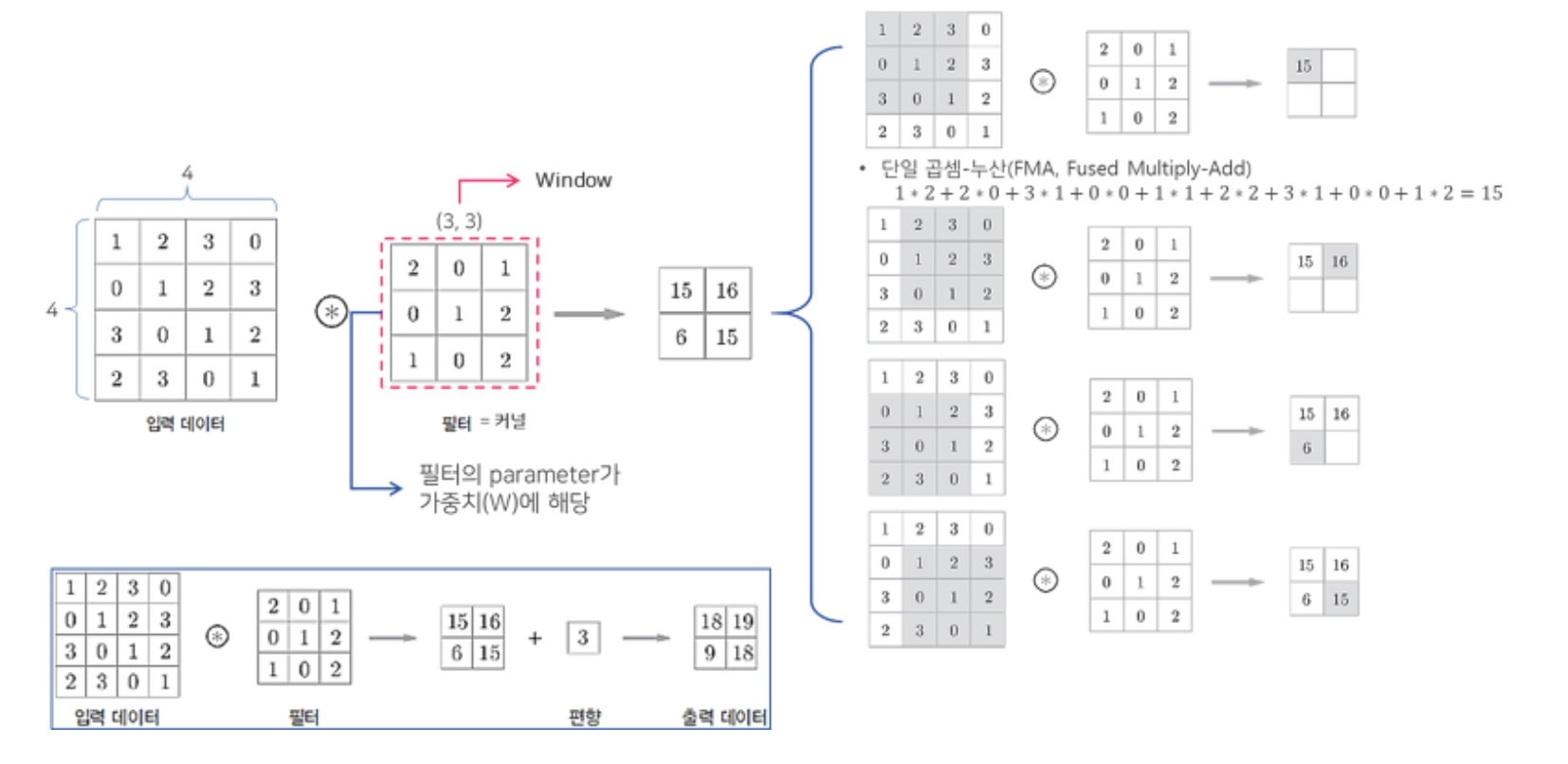
합성곱 연산은 특성 맵(feature map이라고 부르는 랭크-3 텐서에 적용된다. 이 텐서는 2개의 공간 축과 깊이 축을 가지며, RGB 이미지의 경우 깊이 축이 3개의 컬러로 인해 차원이 3이 된다. (MNIST의 경우 흑백이므로 1)
- 합성곱 연산은 입력 특성 맵에서 작은 패치들을 추출하고, 이런 모든 패치에 같은 변환을 적용하여 출력 특성맵을 만들고, 출력 특성 맵또한 높이와 너비를 가진 랭크-3텐서이다. 출력 텐서의 깊이는 층의 매개변수로 결정되어 상황에 따라 다르다.
필터(filter)
깊이 축의 채널은 더 이상 RGB 입력처럼 특정 컬러를 의미하지 않게 되고 그 대신 일종의 필터를 의미한다고 책에 서술되어 있다. 필터는 입력 데이터의 특성을 인코딩하는데, 예로 하나의 필터가 입력에 얼굴이 있는지를 인코딩할 수 있다는 것이다. 필터는 즉 층의 가중치라고 보면 될 것이다. 필터
위 예제에서 처음 층의 (28, 28, 1)크기는 특성 맵을 입력으로 받아 (26, 26, 32)크기의 특성 맵을 출력하게 된다. 이러한 특성 맵은 층을 거치면서 (3, 3, 128)로 변화한다. 다음의 시각자료 과정처럼 이미지를 처음부터 flatten하게 펼치지 않고 소규모로 점점 줄어들어 마지막에 특성이 응집된 작은 분류용 이미지데이터가 펼쳐져 dense층에 입력되어진다.
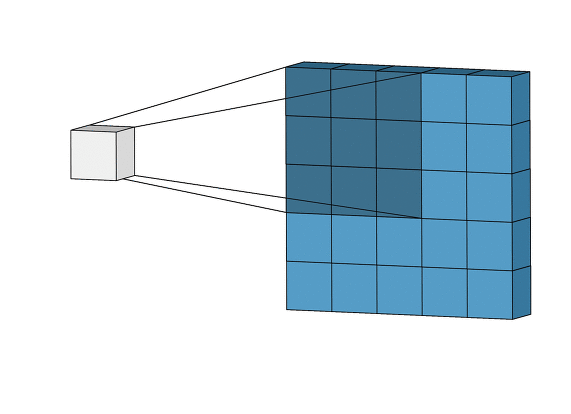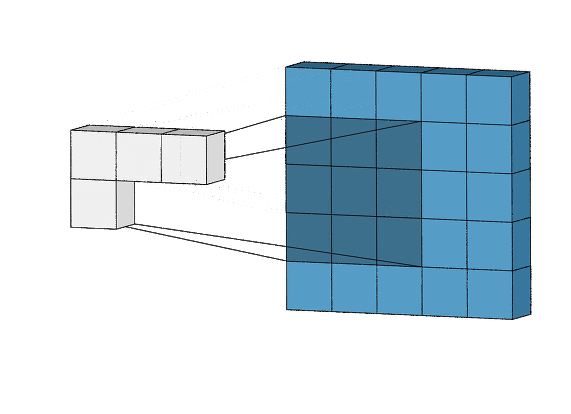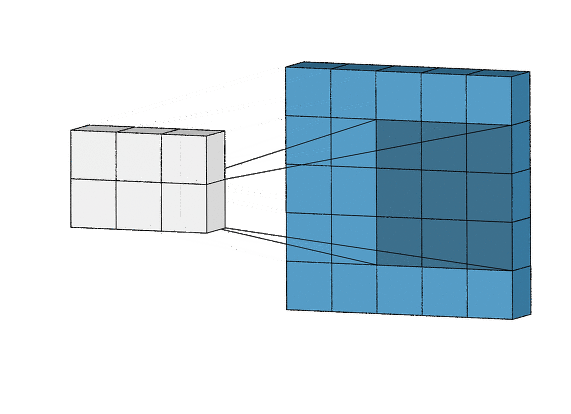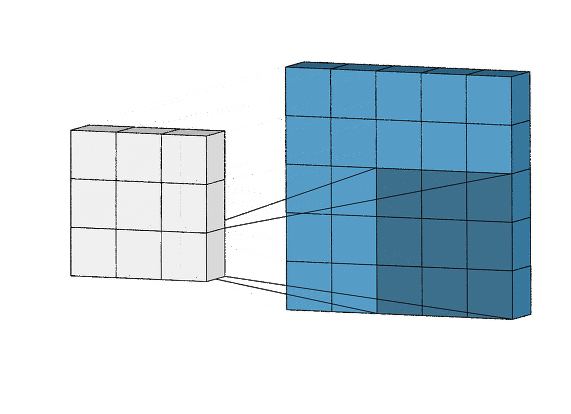
합성곱 층의 핵심 파라미터 2개
- 입력으로부터 뽑아낼 패치의 크기: 전형적으로 3x3 또는 5x5 크기를 사용한다. 패치는 즉 필터라고 보면 된다. 즉 위의 gif파일에서 5x5의 구조를 3x3카메라로 계속 관찰하고 있다. 3x3카메라 자체가 커널이며, 이 크기를 패치의 크기라고 일컫는다.
- 특성 맵의 출력 깊이: 합성곱으로 계산할 필터의 개수이다. 즉 위의 과정을 몇 얼마나 더해서 깊게 쌓을지 이다.
출력과 입력의 높이, 너비 shape가 다를 수 있는 이유
- 경계 문제. 입력 특성 맵에 패딩을 추가하여 대응가능
- 스트라이드(stride) 사용 여부에 따라 다르다.
윈도우의 크기 때문에 짤림현상이 발생하여 경계문제가 발생한다. 즉 28 x28 이었던 앞 선 예제에서 26x26이 되는 상황도 이러한 문제이다. 만약 동일한 높이,너비를 가진 출력 특성맵을 얻고 싶다면 패딩을 사용할 수 있다. 위의 gif 파일또한 5x5가 3x3으로 변하는 모습을 보여준다.
패딩(padding): 입력 특성 맵의 가장자리에 적절한 개수의 행과 열을 추가한다. (어떻게 무슨 논리로 추가하는거지?) 파이썬에서는 padding매개 변수를 통해 조절가능하다. same은 입력과 동일한 출력을, valid는 패딩을 사용하지 않으며, 디폴트는 valid이다.
스트라이드는 움직임의 정도이다. 위의 gif를 보면 3x3필터는 한칸씩 움직이고 있다. 스트라이드의 기본값은 1이며 1보다 큰 스트라이드 합성곱도 가능하다. 이렇게 될 경우 건너뜀 현상때문에 특성맵의 크기가 바뀔 수 있으며 경계문제또한 동시에 발생가능하다. 스트라이드 합성곱은 분류 모델에서 드물게 사용되지만, 일부 문제에서 유용할 수 있다.
MAX POOLING(최대 풀링 연산)
간단한 컨브넷 만들기 예제에서 MaxPooling2D 층마다 특성 맵의 크기가 절반으로 줄어드는 것을 볼 수 있었다. 강제적으로 특성 맵을 다운샘플링하는 것이 최대풀링의 역할이다.
최대 풀링은 최댓값 추출 연산을 사용하며, 2x2 윈도우와 스트라이드2를 사용하여 특성 맵을 절반 크기로 다운샘플링한다. 최대 풀링 연산이 없다면 공간적 계층 구조학습에 도움이 되지 않으며, 최종 특성 맵이 너무 큰 가중치가 유지된다는 것을 방지하기 위함이다.
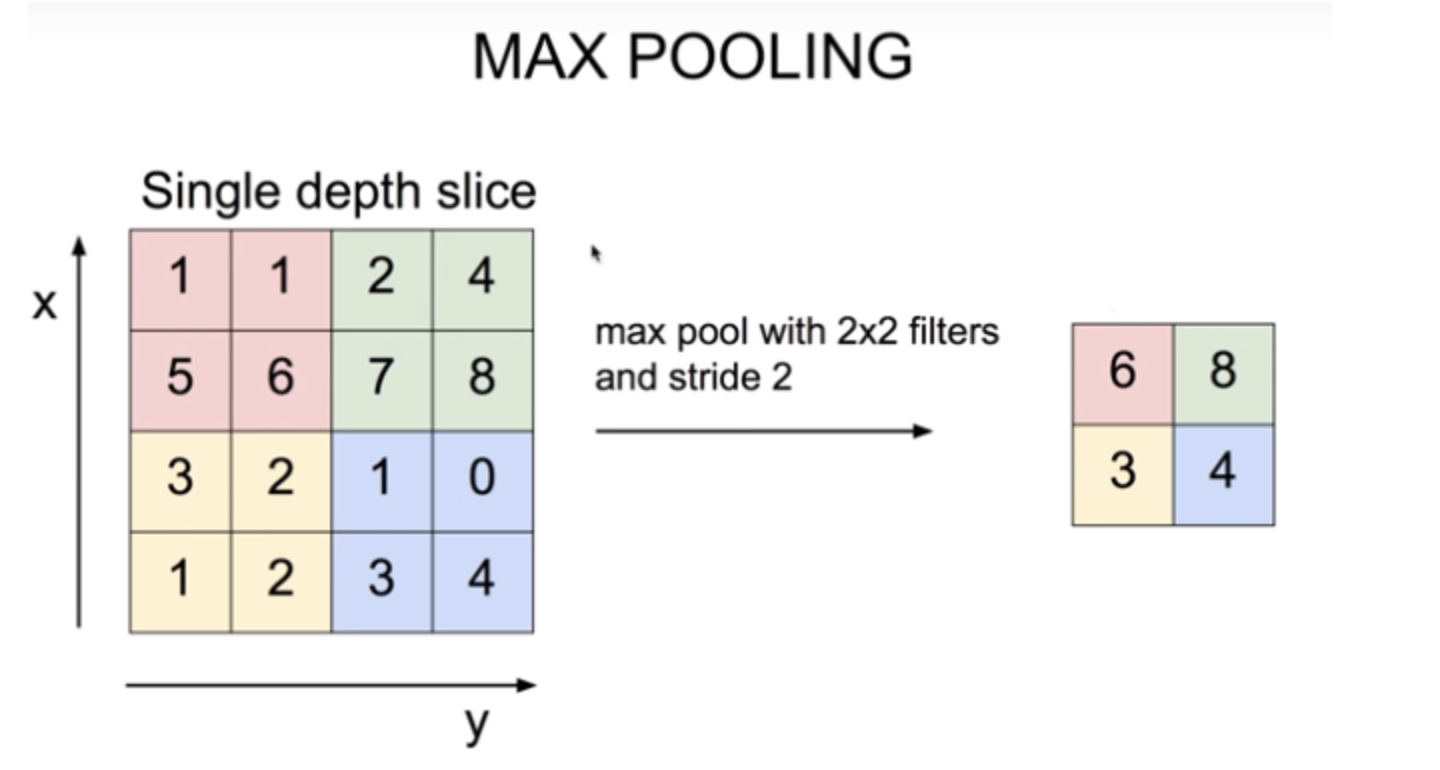
- 간단히, 처리할 특성 맵의 가중치 개수를 줄이기 위함이다. 그러므로 가장 중요한 최댓값만 가져와 중요 가중치만 보고 판단하겠다는 뜻이다.
- 스트라이드나 평균 풀링(채널별 평균 값 계산)을 사용할 수도 있으나 최대풀링이 보통 더 잘 작동하는 편이다. 특성공학의 개념과 유사하게, 불 필요한 특성들이 모델에서 활약하는 것보다는 중요한 특성을 중요하게 보는 것이 더 성능적으로 우위를 점할 수 있다는 개념으로 인식하면 편하다.
밑바닥부터 컨브넷 훈련
사용할 데이터는 캐글의 강아지 vs 고양이 데이터셋을 이용하였다. 케라스에 따로 존재하지 않아, 캐글에서 다운받아 사용하여야하며, 2013년 당시 컨브넷 사용팀이 95%의 정확도로 우승하였었다.
다운받은 캐글의 데이터셋을 3개의 서브셋으로 나누어 강아지와 고양이를 따로 디렉터리에 저장하는 코드를 구현하였다.(책에 존재하는 코드는 에러가 떠 직접 제작)
import os, shutil
# 원본 데이터셋을 압축 해제한 디렉터리 경로
original_dataset_dir = '/Users/jkky/Documents/git/study/keras/dogs-vs-cats/train'
# 소규모 데이터셋을 저장할 디렉터리
base_dir = '/Users/jkky/Documents/git/study/keras/dogs-vs-cats/add'
# 훈련, 검증, 테스트 분할을 위한 디렉터리
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 훈련용 고양이 사진 디렉터리
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 훈련용 강아지 사진 디렉터리
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 검증용 고양이 사진 디렉터리
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 검증용 강아지 사진 디렉터리
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 테스트용 고양이 사진 디렉터리
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# 테스트용 강아지 사진 디렉터리
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 처음 1,000개의 고양이 이미지를 train_cats_dir에 복사합니다
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 고양이 이미지를 validation_cats_dir에 복사합니다
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 고양이 이미지를 test_cats_dir에 복사합니다
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 처음 1,000개의 강아지 이미지를 train_dogs_dir에 복사합니다
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 강아지 이미지를 validation_dogs_dir에 복사합니다
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 강아지 이미지를 test_dogs_dir에 복사합니다
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
모델의 경우 이전 예제보다 이미지가 커지고 복잡한 문제이기에 모델을 더 크게 만들기 위해 Conv2D와 MaxPooling2D 단계를 더 추가하여 층을 늘려 최종적으로 7x7 특성맵으로 Flatten층 이전까지 구현한다.
inputs = keras.Input(shape=(180, 180, 3))
x = layers.Rescaling(1./255)(inputs)
#이미지가 이전보다 크기가 커짐. 모델을 좀 더 크게 만들 것.
x = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.Flatten()(x) # 3d -> 1d 펼치기
outputs = layers.Dense(1, activation='sigmoid')(x) # 이진분류이므로 sigmoid적용
model = keras.Model(inputs=inputs, outputs=outputs) # 모델껍데기 만들기이렇게 모델을 만들고 원래처럼, 모델 컴파일 후 데이터를 주입하고 결과를 관찰하면 검증 정확도가 약 75%정도까지 도달하게 된다.
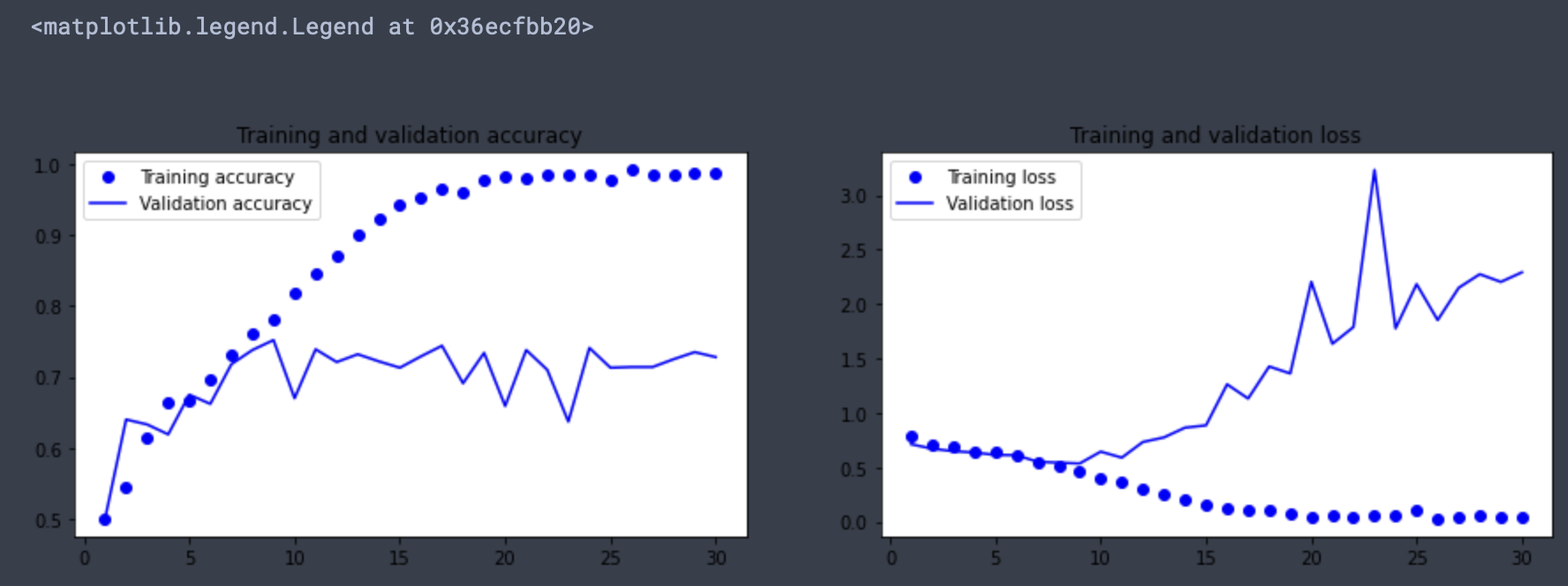
데이터 증식
데이터 증식은 기존 훈련 샘플로부터 더 많은 훈련 데이터를 생성하는 방법이다. 이미지를 랜덤한 변환을 적용하여 샘플을 늘린다. 케라스에서는 모델 시작 부분에 여러개의 데이터 증식 층을 추가할 수 있다.
# 데이터 증식 예시
data_augmentation = keras.Sequential([
layers.RandomFlip('horizontal'), # 랜덤하게 50% 이미지를 수평으로 뒤집기
layers.RandomRotation(0.1), # -10%~10% 범위에서 회전
layers.RandomZoom(0.2) # -20%~20% 범위에서 확대혹은 축소
])하지만 적은 수의 원본 이미지에서 만들어졌기 때문에 여전히 입력 데이터들 사이에 상호 연관성이 크기 때문에 과대적합을 더 억제하기 위해 밀집 연결 분류기 이전에 Dropout층을 추가하도록 한다.
- Dropout
dropout은 결과적으로 과대적합을 방지하기 위해 사용된다. 각 뉴런 연결층이 일부 뉴런만으로도 좋은 출력 값을 제공할 수 있도록 최적화 되었다고 가정할 때 모든 반복되는 뉴런연결의 경우에 대해 dropout을 진행하면, 진행하기 전과 비교할 때, 더욱 편향되지 않은 출력값을 얻을 수 있다.
편향되지 않은 출력값, 직관적으로 이해가 되지 않는다면, 예시를 통해 자세히 설명해보자면, 어느 특정 Feature가 어떤 출력값에 가장 큰 상관관계가 있다고 가정할 때, Drop-out을 적용하지 않고 모델을 학습하면 해당 Feature에 가중치가 가장 크게 설정되어 나머지 Feature에 대해서는 제대로 학습되지 않을 것이다. 즉 나머지 Feature가 과도하게 무시받는 것을 예방할 수 있다.
# 드롭아웃 + 이미지 증식
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(inputs)
#이미지가 이전보다 크기가 커짐. 모델을 좀 더 크게 만들 것.
x = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation='relu')(x)
x = layers.Flatten()(x) # 3d -> 1d 펼치기
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation='sigmoid')(x) # 이진분류이므로 sigmoid적용
model = keras.Model(inputs=inputs, outputs=outputs) # 모델껍데기 만들기
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
callbacks = [
keras.callbacks.ModelCheckpoint(filepath='convnet_from_scratch_augmentation.keras',
save_best_only=True,
monitor='val_loss')
]
history = model.fit(train_dataset,
epochs=100,
validation_data=validation_dataset,
callbacks=callbacks)
#결과 : 약 정확도 10% 상승사전훈련 모델 사용하기(전이학습)
사전 훈련된 모델은 일반적으로 대규모 이미지 분류 문제를 위해 대량의 데이터셋에서 미리 훈련된 모델이다. 주입될 이미지 데이터가 다르다고 하여도, 학습된 특성의 계층 구조는 실제 세상에 대한 일반적인 모델로 효율적인 역할이 가능하다.
VGG16을 사용하여 모델 만들기
사전 훈련된 모델을 사용하는 두 가지 방법
- 특성추출(feature extraction)
- 미세조정(fine tuning)
특성추출의 경우 훈련된 모델의 합성곱 기반 층을 선택하여 새로운 데이터를 통과시키고 그 분류기를 훈련한다. 일반적으로 밀집 연결 분류기 재사용은 권장되지 않는다. 합성곱 층에 의해 학습된 표현이 더 일반적이기 때문이다.
import numpy as np
# 특성추출 코드
def get_features_and_labels(dataset):
all_features = []
all_labels = []
for images, labels in dataset:
preprocessed_images = keras.applications.vgg16.preprocess_input(images)
features = conv_base.predict(preprocessed_images)
all_features.append(features)
all_labels.append(labels)
return np.concatenate(all_features), np.concatenate(all_labels)
train_features, train_labels = get_features_and_labels(train_dataset)
val_features, val_labels = get_features_and_labels(validation_dataset)
test_features, test_labels = get_features_and_labels(test_dataset)
inputs = keras.Input(shape=(5,5,512))
x = layers.Flatten()(inputs)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation='sigmoid')(x)
model = keras.Model(inputs, outputs)
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
callbacks = [
keras.callbacks.ModelCheckpoint(filepath='feature_extraction.keras',
save_best_only=True,
monitor='val_loss')
]
history = model.fit(train_features, train_labels,
epochs=20,
validation_data=(val_features, val_labels),
callbacks=callbacks)- VGG16으로의 훈련결과
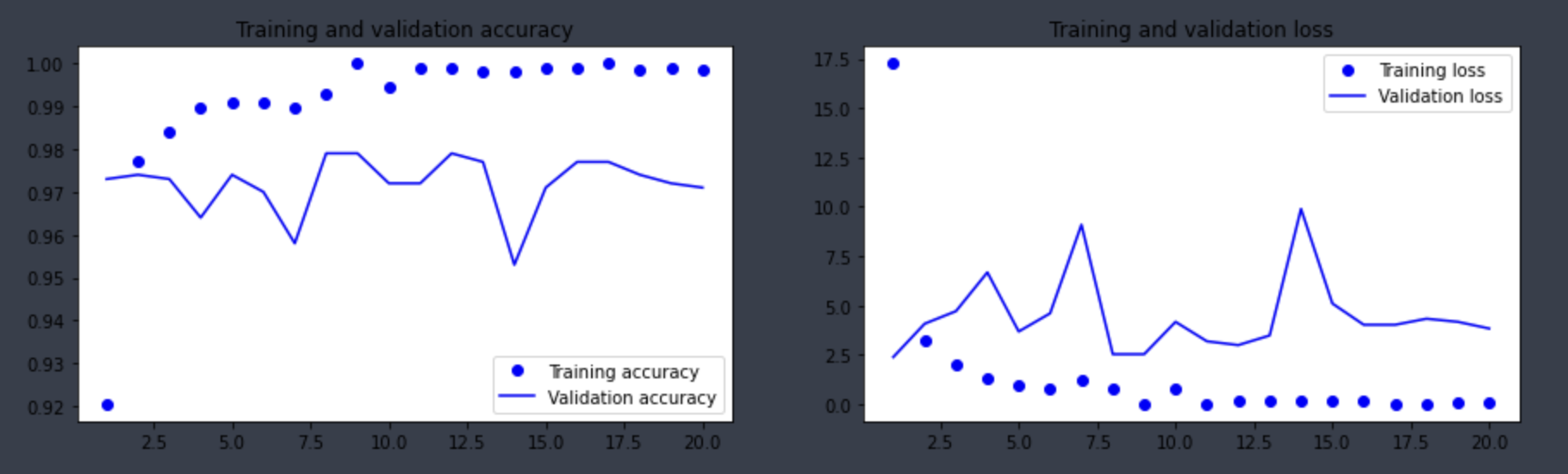
데이터 증식을 포함한다면?
데이터 증식을 포함하기 위해서는 VGG16의 층을 동결시켜야 한다.
- 데이터 증식 단계
- 동결된 합성곱 기반 층 단계
- 밀집 분류기
@코드는 포함하지 못하였는데, gpu성능때문에 불가능하였다.
책에서는 테스트 정확도가 약간 올라간 것으로 나타내었다.
사전 훈련된 모델 미세 조정하기
미세조정은 특성 추출에 사용했던 동결 모델의 상위 층 몇 개를 동결에서 해제하고 모델에 새로 추가한 층과 함께 훈련하는 것이다.
초기에 동결하는 이유: 중요한 정보가 손실될 가능성을 배제하기 위함이며, 기존의 VGG16은 랜덤하게 형성된 Dense층의 가중치에 의해 큰 오차가 전파되어 손상될 수 있음. 특성추출은 VGG16의 특성을 추출하여 모델의 학습에 도움이 되도록 주입하는 것이기 때문에, VGG16모델과 새로운 dense층과의 연결이 아님.
파인튜닝: 정교한 파라미터 튜닝
기존에 학습이 된 레이어에 내 데이터를 추가로 학습시켜 파라미터를 업데이트 해야 한다. 기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적(나의 이미지 데이터에 맞게)변형하고 이미 학습된 모델 Weights로 부터 학습을 업데이트하는 방법
❔ 그럼 위에 풀링 계층과 마지막 레이어를 추가한 건 파인 튜닝이 아닌가요?
아니다! 피쳐를 추출해내는 레이어의 파라미터를 업데이트 하지 않기 때문이다.
마지막 레이어를 업데이트 하지 않냐고 생각할 수 있지만 내가 새로 구성한 레이어이기 때문에 업데이트가 아니며 초기 가중치가 랜덤이기 때문에 정교하지도 않다.
