
9장 컴퓨터 비전을 위한 고급 딥러닝
8장까지는 이미지 분류 모델을 주로 다루었다.
일반적으로 3개의 주요 컴퓨터 비전 작업을 알아 둘 필요가 있다.
- 이미지 분류(image classification): 이미지에 하나 이상의 레이블을 할당하는 것이 목표이며, 단일 레이블 분류이거나 다중 레이블 분류일 수 있다.
- 이미지 분할(image segmentation): 이미지를 다른 영역으로 나누거나 분할하는 것이 목표이며, 사진에 만약 자전거를 탄 사람이 있다면 이미지 분할로 하여금 자전거와 사람을 분리하여 인식할 수 있다.
- 객체 탐지(object detection): 이미지에 있는 관심 객체 주변에 바운딩 박스 사각형을 그리는 것이 목표이며, 각 사각형은 하나의 클래스에 연관된다.
이미지 분할 예제
이미지 분하라에는 두 가지 종류가 있다.
시맨틱 분할(semantic segmentation: 각 픽셀이 독립적으로 'cat'과 같은 하나의 의미를 가진 범주로 분류된다.인스턴스 분할(instance segmentation: 이미지 픽셀을 범주로 분류하는 것뿐만 아니라 개별 객체 인스턴스를 구분, 이미지에 2마리의 고양이가 있다면 'cat1'과 'cat2'를 별개의 클래스로 다룬다.
사용 데이터셋 : Oxford-IIIT Pets Datasets(다양한 동물사진 + 7390개의 분할마스크)
분할마스크 : 이미지 분할에서 레이블에 해당한다.(입력 이미지와 동일한 크기의 이미지이고, 컬러 채널은 하나이다. 각 정수 값은 입력 이미지에서 해당 픽셀의 클래스를 나타낸다. 이 데이터셋의 경우 분할 마스크의 픽셀은 3개의 정수값중 하나를 가진다. 1:전경, 2:배경, 3:윤곽
원래 레이블은 1, 2, 3이나 여기에 1을 빼고 127을 곱하여 레이블 값을 0, 127, 254로 검은색, 회색, 흰색으로 만든다. 그런 후에 color_mode를 grayscale로 설정하여 하나의 컬러 채널이 있는 것 처럼 다룬다.
def display_target(target_array):
# 타깃 마스크 그레이 스케일화
normalized_array = (target_array.astype("uint8") - 1) * 127
# 검, 회, 흰색으로 만들기.
plt.axis("off")
plt.imshow(normalized_array[:, :, 0])
img = img_to_array(load_img(target_paths[9], color_mode="grayscale"))
display_target(img)
입력과 타깃을 2개의 넘파이 배열로 로드하고 이 배열을 훈련과 검증 세트로 나눈다. 데이터셋이 매우 작기에 모두 메모리로 로드 가능하다.
import numpy as np
import random
img_size = (200, 200) #입력과 타깃 모두 200,200사이즈로
num_imgs = len(input_img_paths)
# 데이터에 있는 전체 샘플 개수
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_paths)
#같은 시드로 타겟과 input데이터 섞기
def path_to_input_image(path):
return img_to_array(load_img(path, target_size=img_size))
# 인풋 데이터배열 가져오기
def path_to_target(path):
img = img_to_array(
load_img(path, target_size=img_size, color_mode="grayscale"))
img = img.astype("uint8") - 1 #레이블 0,1,2로 만들기
return img
# 타겟 데이터배열 가져오기
input_imgs = np.zeros((num_imgs,) + img_size + (3,), dtype="float32")
targets = np.zeros((num_imgs,) + img_size + (1,), dtype="uint8")
# 인풋, 타겟 데이터 정의
for i in range(num_imgs):
input_imgs[i] = path_to_input_image(input_img_paths[i])
targets[i] = path_to_target(target_paths[i])
# 데이터 주입
num_val_samples = 1000
train_input_imgs = input_imgs[:-num_val_samples]
train_targets = targets[:-num_val_samples]
val_input_imgs = input_imgs[-num_val_samples:]
val_targets = targets[-num_val_samples:]
# train, validation으로 나누기모델 만들기
from tensorflow import keras
from tensorflow.keras import layers
def get_model(img_size, num_classes):
inputs = keras.Input(shape=img_size + (3,))
x = layers.Rescaling(1./255)(inputs)
# input shape설정후 Rescaling하여 정규화
x = layers.Conv2D(64, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(256, 3, strides=2, padding="same", activation="relu")(x)
x = layers.Conv2D(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same", strides=2)(x)
outputs = layers.Conv2D(num_classes, 3, activation="softmax", padding="same")(x)
model = keras.Model(inputs, outputs)
return model
model = get_model(img_size=img_size, num_classes=3)
model.summary()이 모델의 처음 절반은 컨브넷과 닮았다. 이 모델의 처음 절반의 목적은 이미지를 작은 특성 맵으로 인코딩하는 것이다. 공간상의 각 위치는 원본 이미지에 있는 더 큰 영역에 대한 정보를 담고 있다.(일종의 압축), 하지만 이전 장의 예시와 다른 점은 다운샘플링 방식에 있다. 이전 장에서는 MaxPooling을 통해, 현재는 스트라이드(stride)로 다운샘플링하였다. 이미지 분할의 경우 모델의 출력으로 픽셀별 타깃 마스크를 생성해야하므로 정보의 공간상 위치에 많은 관심을 두기 때문이다. 최대풀링을 사용할 경우 풀링 윈도우 안의 위치정보가 완전히 삭제된다. 왜냐면 2x2윈도우에 속한 값중 최댓값을 가져오게 되는데, 이때 최댓값은 어디서 온 것인지 알 수 없기 때문이다.
- 분류작업 : 위치고려필요x 2x2최대풀링 사용가능
- 분할작업 : 특성 위치 고려 필요하므로 최대풀링 대신에 스트라이드 사용
Conv2DTranspose를 사용하는 이유
모델의 처음 절반, 즉 Conv2D층들을 통과하고 특성맵은 (25, 25, 256)크기를 가진다. 우리는 최종 출력으로 타깃 마스크의 크기인 (200, 200, 3)의 출력을 받아야한다. 즉 업샘플링이 필요하여 이 층을 두는 것이다.
모델 컴파일, 훈련 및 검증손실 그래프
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
batch_size=64,
validation_data=(val_input_imgs, val_targets))epochs = range(1, len(history.history["loss"]) + 1)
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()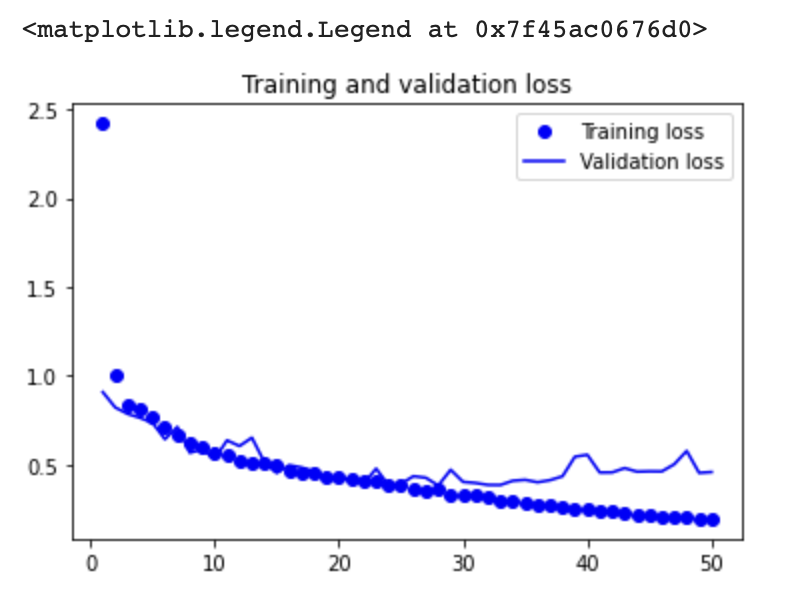
최신 컨브넷 아키텍처 패턴
모델의
아키텍처(architecture)는 모델을 만드는 데 사용된 일련의 선택이다. 사용할 층, 층의 설정, 층을 연결하는 방법등이다. 이런 선택이 모델의 가설공간을 정의한다. 좋은 가설 공간은 현재 문제와 솔루션에 대한 사전지식을 인코딩한다. 예로 합성곱 층을 사용한다는 것은 입력 이미지에 있는 패턴이 이동 불변성이 있음을 미리 알고 있다는 뜻이다. 모델 아키텍처는 경사 하강법이 해결할 문제를 간단하게 만드는 것이다.
모듈화, 계층화, 재사용
복잡한 시스템을 단순하게 만들고 싶다면, 복잡한 구조를 모듈화
하고 모듈을 계층화하고 같은 모듈을 적절하게 여러 곳에서 재사용하는 것이다. 이것을 MHR(Modularity-Hierarchy-Reuse)공식이다.
- 효율적인 코드는 모듈화되고 계층적이며 동일한 것을 두 번 구현하지 않는다.
- 그 대신 재사용 가능한 클래스와 함수를 사용한다.
잔차연결
계층 구조가 깊으면 즉, 작은 층을 깊게 쌓은 모델이 큰 층을 얇게 쌓은 것보다 성능이 좋다. 하지만 그레이디언트 소실(vanishing gradient)문제 때문에 층을 쌓을 수 있는 정도의 한계가 있고, 이러한 문제가
잔차연결을 탄생시켰다.
y = f4(f3(f2(f1(x)))) 이 게임은 f4의 출력에 기록된 오차를 기반으로 연결된 각 함수의 파라미터를 조정하는 것이다. f1을 조정하려면 f2,f3,f4에 오차정보를 통과시켜야 한다. 하지만 연속적으로 놓인 각 함수에는 일정량의 잡음이 있다. 함수연결이 너무 깊다면 이 잡음이 그레이디언트 정보를 압도하게 되고 역전파가 동작하지 않게 된다. 이것을 그레이디언트 소실(vanishing gradient)문제라고 한다.
해결을 위해 연결된 각 함수를 비파괴적으로 만들면 된다. 즉 이전 입력에 담긴 잡음 없는 정보를 유지시키는 것이며 이를 위해 가장 쉬운 방법이 잔차연결인 것이다.
- 잔차연결 : 층이나 블록의 입력을 출력에 더하기만 하면 된다.
(입력을 블록의 출력에 다시 더하는 것은 출력 크기가 입력과 같아야 한다는 것을 의미한다.)
# 필터 개수가 변경되는 잔차 블록
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(32, 32, 3))
# input이 처음 컨브넷 층으로 들어감. 깊이32, 필터3x3
x = layers.Conv2D(32, 3, activation="relu")(inputs)
# 해당 층을 residual변수에 저장.
residual = x
# 필터수가 64개로 증가한 층에 다시 연결(same padding : 다운샘플링 되지 않도록)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
# 잔차변수의 필터수와 블록의 필터수를 같게 만들기
residual = layers.Conv2D(64, 1)(residual)
# 블록의 출력과 잔차를 더하기.
x = layers.add([x, residual])
# 최대 풀링 층을 가진 잔차 블록
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs)
residual = x
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
# 맥스 풀링으로 인해 다운샘플링 된 것, 스트라이드로 잔차층도 동일하게 만들어주기.
x = layers.MaxPooling2D(2, padding="same")(x)
residual = layers.Conv2D(64, 1, strides=2)(residual)
x = layers.add([x, residual])- 잔차연결을 사용하면 그레이디언트 소실에 대해 걱정하지 않고 원하는 깊이의 네트워크를 만들 수 있다.
배치 정규화
정규화란 머신러닝 모델에 주입되는 샘플들을 균일하게 만드는 광범위한 방법이다. 모델이 학습하고 새로운 데이터에 잘 일반화되도록 돕는다. 이전 예제들에서는 모델에 데이터를 주입하기 전 정규화를 진행하였지만, 정규화는 네트워크에서 일어나는 모든 변환 후에도 필요할 수 있다. 즉 정규화된 입력 데이터에 대해 출력데이터또한 동일한 분포를 가질 것이라고 기대하기 어렵다는 것이다.
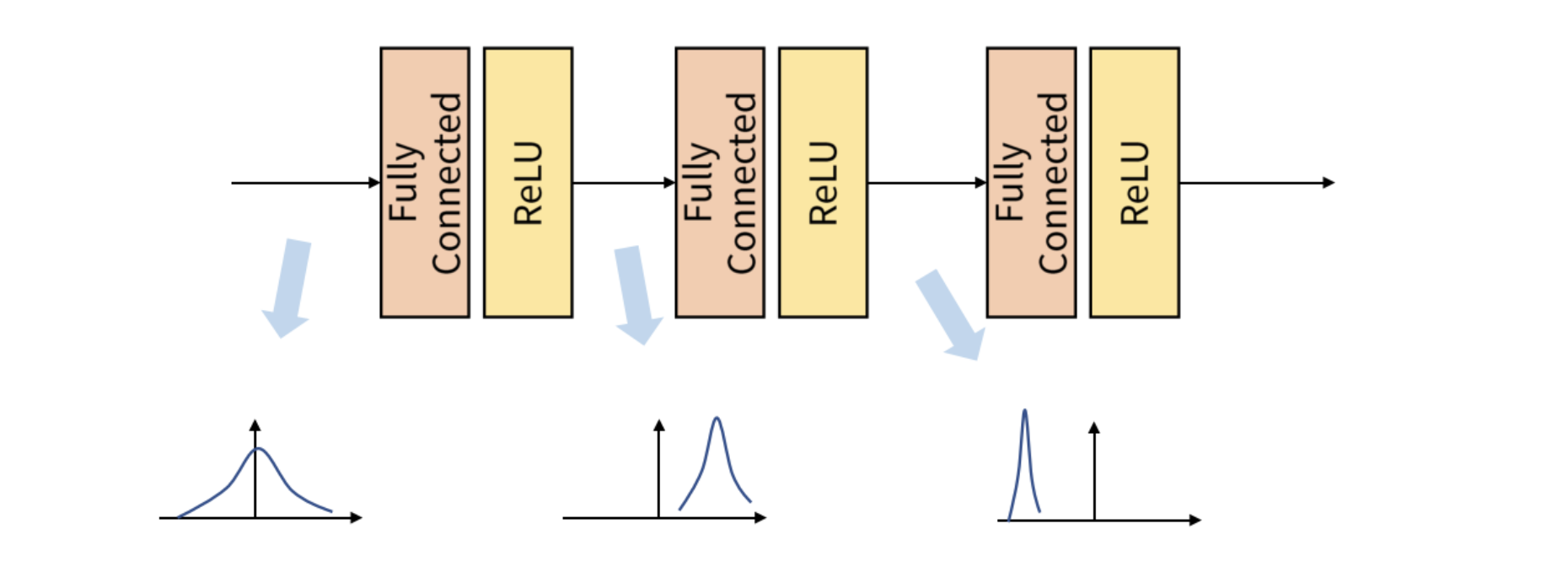
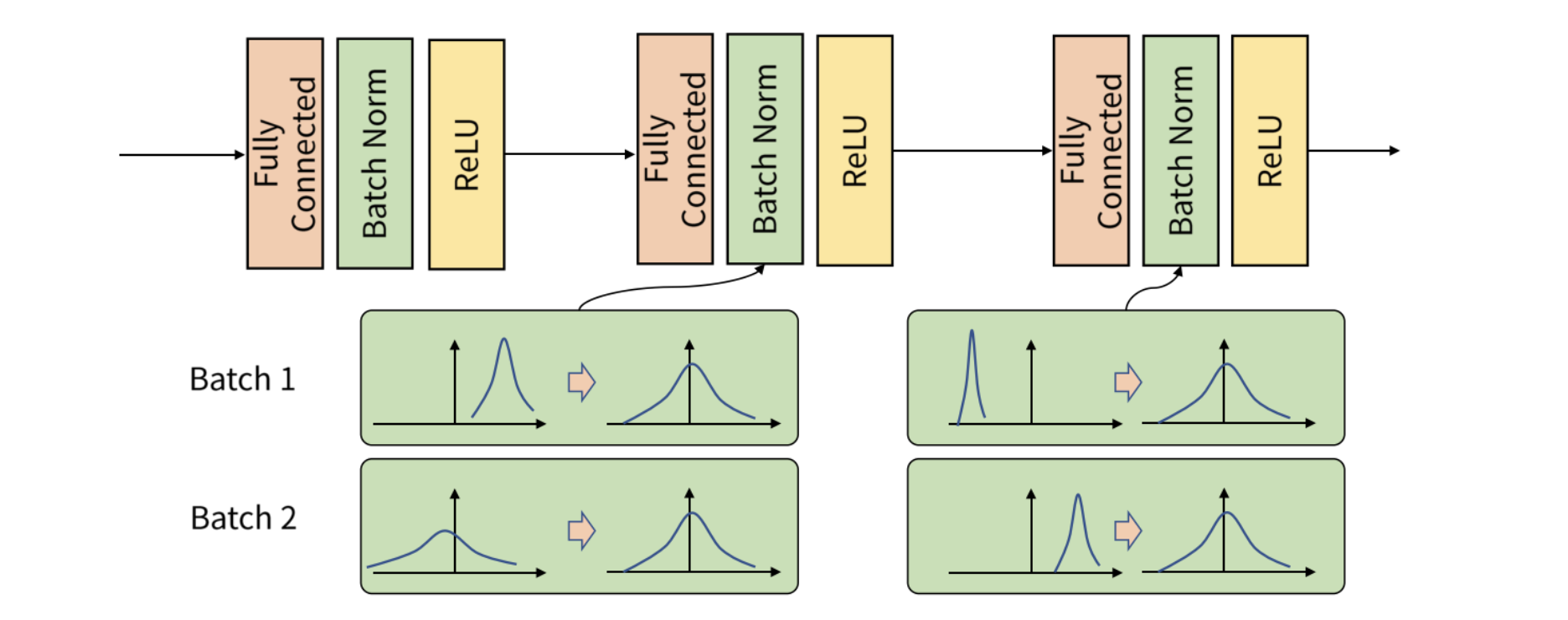
- 배치 정규화가 왜 도움이 되는지 확실히 아는 사람은 없다!
- 일반적으로 그레이디언트 전파를 도와준다.
- 활성화 층 이전에 배치 정규화 층을 놓는 것이 좋다.
- 미세조정시 배치정규화층들을 동결하는 것이 좋다.
깊이별 분리 합성곱
이 층은 입력 채널별로 따로따로 공간 방향의 합성곱을 수행한다. 그 다음 점별합성곱을 통해 출력 채널을 합친다. 이는 공간 특성의 학습과 채널 방향 특성의 학습을 분리하는 효과를 낸다.
- 공간상의 위치는 높은 상관관계를 가지나, 채널 간에는 매우 독립적이라는 가정에 의존
깊이별 분리 합성곱은 일반 합성곱보다 훨씬 적은 개수의 파라미터를 사용하고 더 적은 수의 연산을 수행하면서 유사한 표현 능력을 가지고 있다. 수렴이 더 빠르고 쉽게 과대적합되지 않음.
컨브넷 아키텍처 원칙 정리
- 모델은 반복되는 층 블록으로 조직되어야한다.(합성곱+최대풀링)
- 특성 맵의 공간방향 크기가 줄어듦에 따라 필터가 증가해야한다.
- 깊고 좁은 아키텍처가 얕고 넓은 것보다 낫다.
- 층 블록에 잔차 연결을 추가하면 깊은 네트워크 훈련에 도움이 된다.
- 합성곱 층 다음 배치정규화 층을 추가하면 도움이 된다.(relu이전)
- Conv2D보다 파라미터 효율성이 좋은 SeparableConv2D사용하면 도움이 될 수 있다.
Xception
위의 아이디어들을 하나의 모델에 적용할 경우 작은 버전의 Xception 모델과 비슷해진다!
# 강아지 vs 고양이 Xception Style로 모델만들기
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs) # 데이터 증식
# 정규화
x = layers.Rescaling(1./255)(x)
# 처음 컨브넷층 조성(첫번째 에서는 특성 채널인 RGB는 매우 높은 상관관계를 가지므로 처음 층은 일반 컨브넷 층으로!)
x = layers.Conv2D(filters=32, kernel_size=5, use_bias=False)(x)
# 필터수 점진적으로 증가를 위한 for문 작성
# 층이 많아지지만 우리는 배치정규화와 잔차연결 진행하기에 괜찮
for size in [32, 64, 128, 256, 512]:
# 잔차연결을 위한 x복사
residual = x
# relu이전에 배치정규화
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
residual = layers.Conv2D(
size, 1, strides=2, padding="same", use_bias=False)(residual)
x = layers.add([x, residual]) # 잔차연결
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)