본 포스트는 오토인코더의 모든 것(슬라이드)과 오토인코더의 모든 것(영상)을 참고하여 작성되었습니다.
주변 지인(?)들에 의해서 굉장히 명강의라는 이야기를 많이 들었고 최근에 논문을 읽을 일이 많았는데 transformer, encoder, decoder... 등등 encoder 관련된 부분들이 너무 어렵게 다가왔기 때문에 기초를 다지는 겸 듣고 정리해보기로 했다. (사실 기초는 아니긴 하다)
먼저 1강 초반에는 잘 알려진 전통적인 머신러닝 & 딥러닝에 대해서 개괄적으로 요약한 느낌이다. 이미 알고 있다고 생각하는 것들도 잘 설명해주셔서 같이 정리해볼 예정이다.
Revisit Deep Neural Networks
Autoencoder에 대해 설명하기 전에 Deep learning이 무엇인지에 대해 짚고 넘어가는 부분이다. 이 포스트에서는 remind해야할 부분만 기록할 예정이다!
Loss Function

먼저 가장 이해하기 쉽게 "input이 1이면 어떻게 output 0을 만들 수 있을까?"라는 질문에서 부터 시작한다. 사실 loss는 수백, 수천개의 layer에서 복잡하게 역전파가 일어나더라도 본질은 변하지 않기 때문이다!
딥러닝을 처음 배울 때 복잡한 수식 구조로 흐름을 배우면 중요한 의미나 기능들을 놓칠 수가 있다. Loss에 대해서도 MSE의 식은 이렇다, CSE를 미분하면 이렇게 된다 등 이해없이 그냥 넘어가기 마련인데 예측한 데이터와 정답 데이터와의 차이를 두고 이를 minimize하기 위해서 training을 하는 것을 잊으면 안된다. 위 슬라이드에도 전개식이 복잡하게 나와있지만 핵심을 다시 한번 머리에 새길 수 있었다.
왜 다르게 수렴할까?
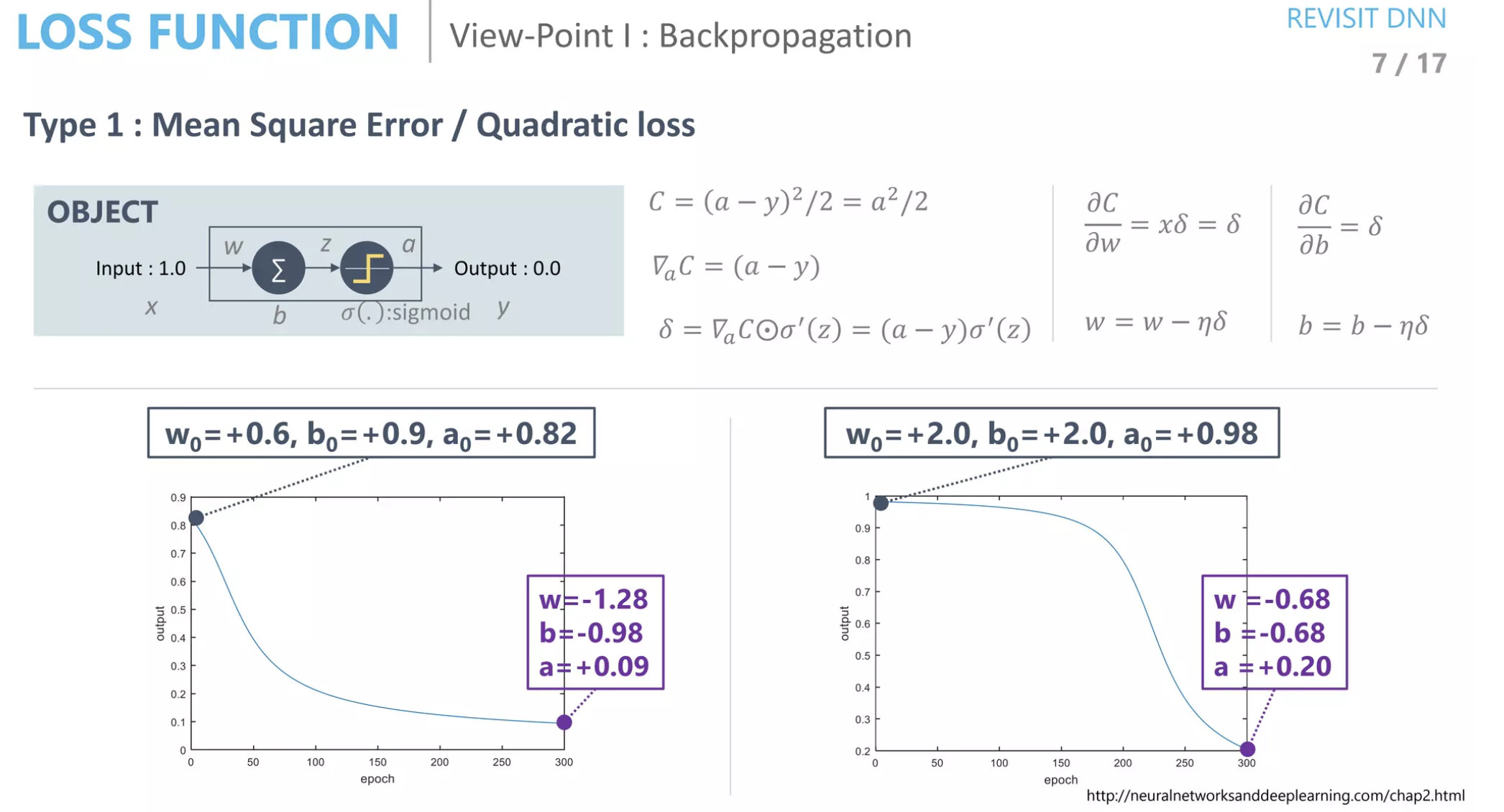
초기 파라미터 값들이 다르면 수렴하는 형태가 다름을 알 수 있다. Loss function이나 다른 부분이 다르더라도 초기값의 영향이 크다는 걸 알 수 있다. 왼쪽처럼 점진적으로 감소하는 그래프가 더 잘 학습되고 있다고 볼 수 있다.
Vanishing Gradient란?
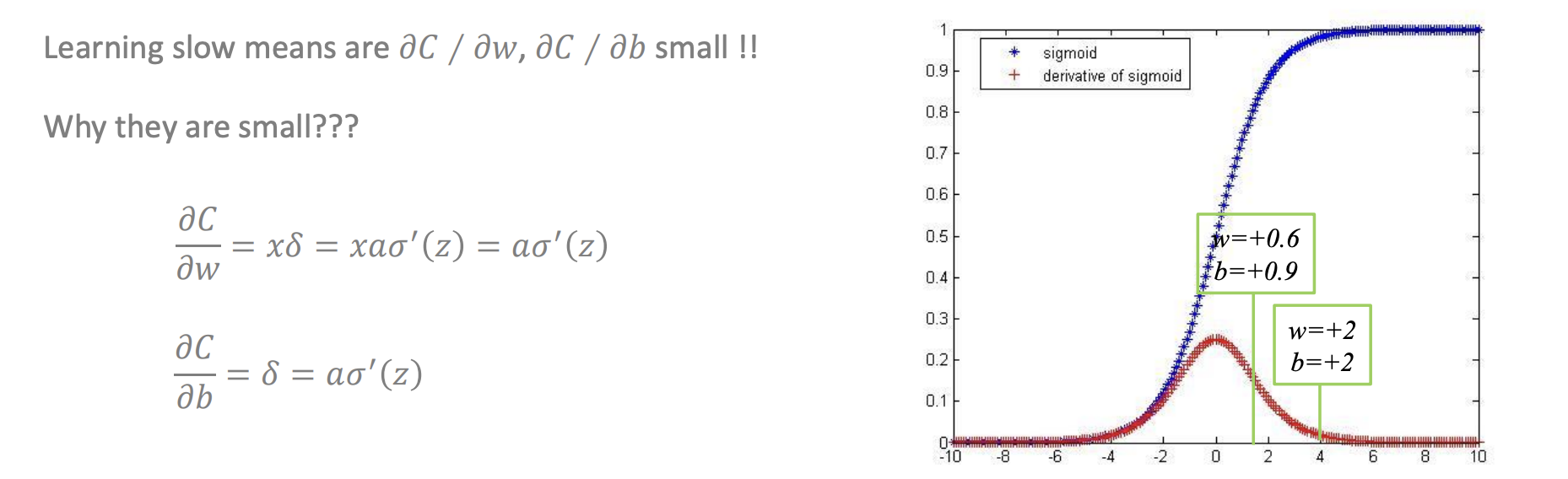
기본적으로 backpropgation 과정에서 weights와 bias가 업데이트 되는데 학습 과정에서 input layer에 가까워졌을 때 더 이상 update되는 값이 0에 가까워지는 현상이다. 위 그림에서 derivative of sigmoid는 최소 0, 최대 0.25 정도로 나올 수 있다. 여기서 학습이 거의 안되는 경우 이 값이 0에 수렴하기 때문이다. 이 현상을 backpropagation의 가장 큰 문제점이라고 짚어주셨다. 작성자 역시 간단한 resnet이나 densenet과 같은 single model 하나로 classification 연구를 해볼 기회가 있었는데 너무 빨리 수렴하거나 이상한 local minimum에서 학습을 멈추는 경우가 많아 어려움을 겪은 적이 꽤 있었다.
Maximum likelihood estimation

Maximum likelihood란 말 그대로 확률분포에서 확률 값을 maximize하는 것이다. Maximum likelihood 관점에서 보면 확률분포에서 평균에 위치한 값이 정답과 같아져야(가까워져야) 한다는 것이다. 이는 전통적인 관점에서 정답과 오차가 적어야 한다는 의미와 통한다. 그리고 이로부터 얻을 수 있는 이점은 sampling을 할 수 있다는 것인데, 이 부분이 잘 이해가 가지 않았다. 만약 GAN을 예로 들면 단순하게 여러 강아지들의 이미지로 학습했을 때 학습이 수렴하고 멈추기 때문에 모두 비슷한 이미지를 생성할 수 있을 것이다. 그런데 maximum likelihood라면 모델에서의 확률분포를 알 수 있기 때문에 매번 다른 강아지의 형태들을 생성할 수 있다.
Gaussian vs Bernoulli

Gaussian를 전개해보면 mean-squared와 같고, Bernoulli는 식을 전개해보면 cross entropy와 같아진다. 반대로 생각해보면 지금 사용하고 있는 모델이 Gaussian 확률분포를 따르면 mean-squared를 사용하는 것이 좋고, Bernoulli 확률분포를 따르면 cross entropy를 사용하는 것이 좋다고 판단할 수 있다. cross entropy는 discrete한 모델에 사용하면 좋을 것이다.
다음 챕터는 manifold이다. 이제 강의의 실질적인 시작인 것 같은데.. 더욱 꼼꼼히 봐야겠다.
