먼저 NeRF에 대해서 알아보려고 한 이유는 프로젝트를 진행하던 중 사람을 3D 공간 상에 어떻게든 렌더링하고 싶었기 때문에.. 회의하다가 언급되기도 했고 굳이 synthesis기반의 모델을 안 쓸 이유도 없다는 생각이 들었기 때문이다.
NeRF란?
쉽게 말하자면 여러 장의 이미지, 정확하게 말하자면 여러 각도에서 바라본 이미지들로 novel view의 이미지를 만들어내는 모델이다.

여러장의 input image를 받고 input image에 없는 새로운 view를 synthesis하여 만들어내는 것인데, input dimension이 특이하다. 5D image라고 표현 되는데 보통 image 처럼 앞에 3개의 dimension은 같고 나머지 두개는 viewing direction이다. 쉽게 말하자면 픽셀값들과 그 대상을 바라보는 카메라의 각도가 필요한 것이다.
Backbone
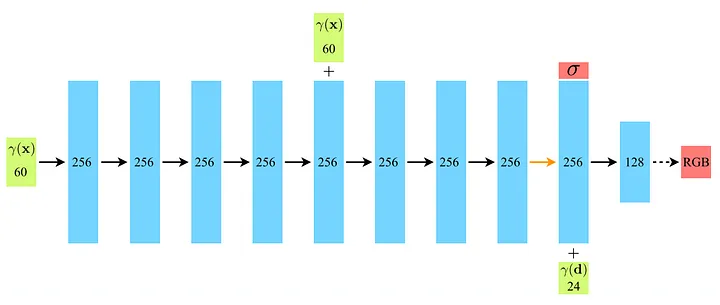
Backbone은 위와 같다. MLP layer 8개로 구성된 모델이고 output에서 density와 RGB값을 함께 얻을 수 있다. 사실 수식이나 복잡한 이해가 필요한 부분은 짚고 넘어가지 않을 예정이다..
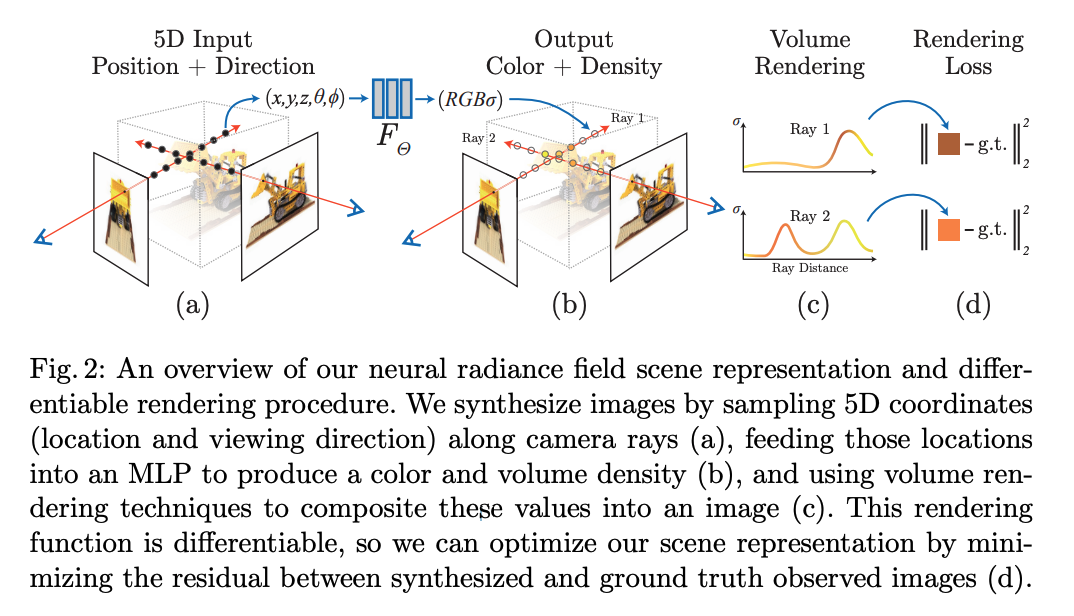
위와 같이 (x, y, z, θ, φ)의 차원을 가진 여러장의 이미지들을 input으로 사용하여 색과 밀도(color & density)를 뽑아낼 수 있다.
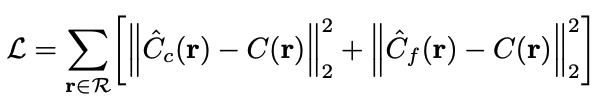
loss는 생각보다 간단하다. prediction과 ground truth의 각 픽셀들을 비교하여 계산하는 squared error이다.
더 내용이 많지만 이번엔 간단하게 알아보고 넘어가고 나중에 보충해야겠다..!
결론은 하나의 대상을 여러 각도로 찍은 이미지들이 있다면 새로운 시점에서 본 이미지를 합성해서 만들어 낼 수 있다는 것. 그리고 최근에는 그 필요한 사진 수가 적어지고 있다는 것.
단점
실제로 original NeRf는 아니지만 AvatarNeRF를 비디오로 데모를 돌려보았는데 상당히 시간이 오래 걸렸다. 물론 사양 문제도 충분히 있지만 조금만 더 가벼운 모델이었으면... 싶은 것도 있다.
느낀점
그래도 이 분야에서는 최신 논문이라고는 할 수는 없지만 접한 지 얼마 되지 않은 입장으로서 2D + synthesis(ex. GAN)도 신선한 충격이었는데 3D + synthesis라니... 이제 더 할 연구가 있을까 싶다. 요즘은 monocular image로도 가능하다던데 정확도를 보니 아직 일반적인 상황은 아닌 것 같다!
