
CNN
1. BackGround
1) Image Data

위의 두 사진은 다른 사진이라고 할 수 있을까??
물론, 엄연히 따지자면 다른 사진이라고도 할 수 있겠지만, 오른쪽 말 사진은 왼쪽 사진에서 잘라낸 사진이므로 다르다고도 할 수 없을 것이다.
하지만 CNN이 아닌 Fully Connected Layer로만 구성된 딥러닝 모델들은 위 두 사진을 전혀 다른 사진으로 판별하게 된다.
따라서 우리는 이미지 데이터를 해석할 만한 다른 방법이 필요하다.
물론 그렇다고 Image Data를 꼭 이러한 방식으로 학습해야 한다는 것은 아니다.
2) Convolution

우리는 위의 문제를 Convolution연산을 통해서 해결해 볼 수 있다.
이 Convolution연산의 의미를 알아보기 전에 먼저 계산 방법부터 알아보자.
식은 위의 그림과 같고, 해당 식을 행렬에 적용해 보면 아래의 그림과 같이 동작한다.
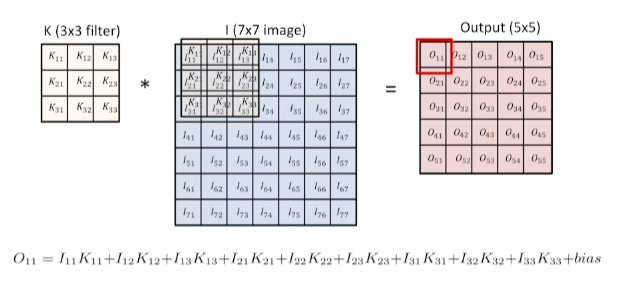
물론 위 그림은
Padding_size=0,Stride=1인 경우이다.
Paddding
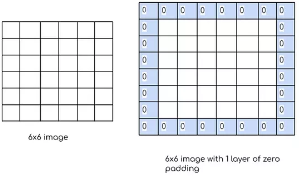
Convolution연산을 잘 살펴보면 행렬의 가장자리에 있는 데이터의 정보는 그렇지 않은 데이터에 비해 연산 횟수가 적다는 것을 확인할 수 있다.
즉, 가장자리데이터의 정보가 비교적 덜 중요하게 처리된다는 것이다.
이를 방지하기 위해 가장자리에 임의의 데이터를 추가적으로 채워 넣어주는 것을 Padding이라고 한다.
Stride
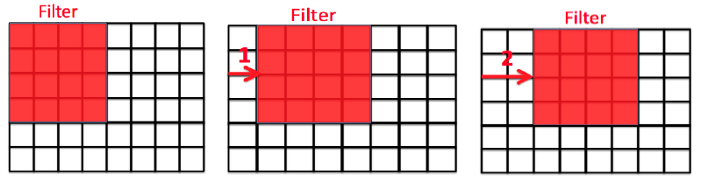
Stride는 filter가 Convolution 연산 후 이동하는 거리를 의미한다.
따라서 row, column방향 모두 Stride설정이 가능하다.
Receptive Field
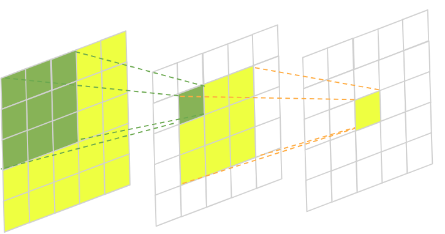
Layer를 여러개 쌓을 때 결과 값에 대한 Input Data를 의미한다.
예를들어, 위의 마지막 Layer의 노란색 Pixel에 대한 Receptive Field는 맨 처음 Layer의 전체 Data가 될 것이다.
3) CNN
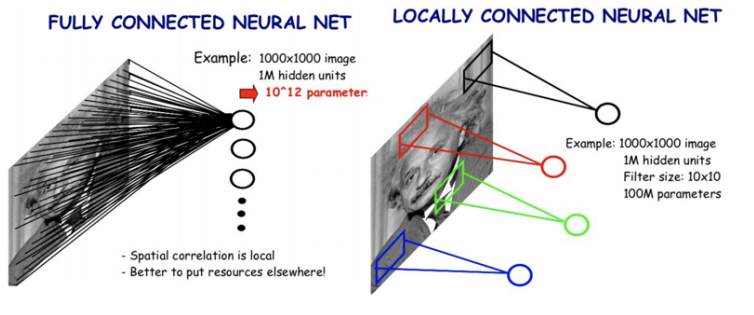
Convolution연산을 통해 얻은 데이터는 연산 과정을 보면 알 수 있듯이 이미지 전체에 대한 데이터라기 보다는, "부분 이미지에 대한 데이터의 모음"이라고 봐야 할 것이다.
즉, 전체적인 이미지에 대한 특징을 나타내는 Fully Connected Layer보다 해당 이미지를 해석하는데 도움이 된다.
이렇게 Convolution 연산을 활용하는 Layer로 구성된 Neural Network를 CNN이라고 한다.
관련된 재미있는 주제: 이미지 필터링
4) 활용
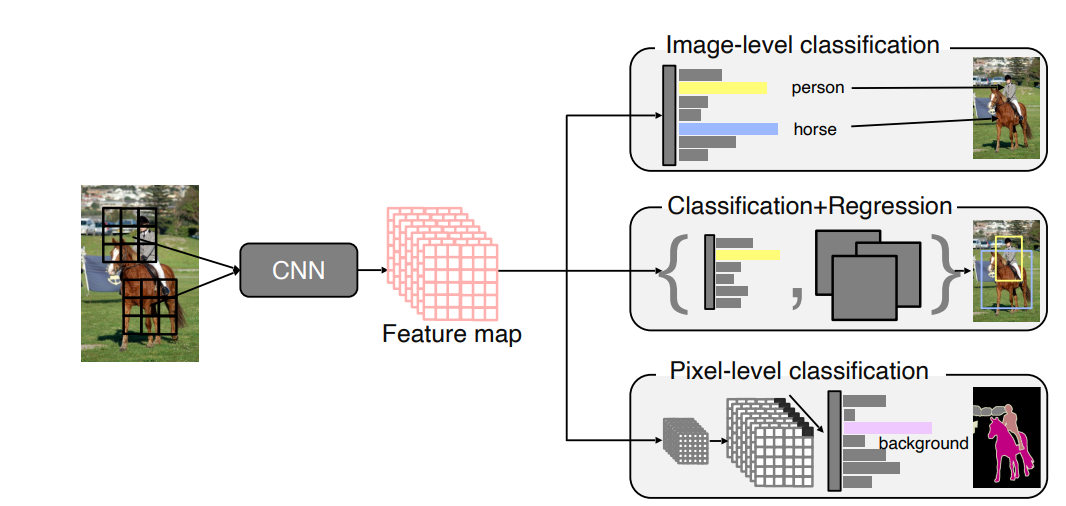
CNN을 활용한 이미지 분류 Task는 크게 다음과 같이 나눠 볼 수 있다.
- Image Level Classification
: 어떤 이미지에 대해 그 이미지가 어떤 Label에 속하는 이미지인지 판별하는 문제
- Classification + Regression
: 이미지의 어떤 부분이 내가 원하는 Label에 속하고 있는지 찾아내는 문제
(Detection이라고도 한다.)
- Pixel-Level Classification
: 이미지를 Pixel단위로 Classification하는 문제
(Semantic Segmentation라고도 한다.)
2.Image Level Classification
1) Preview
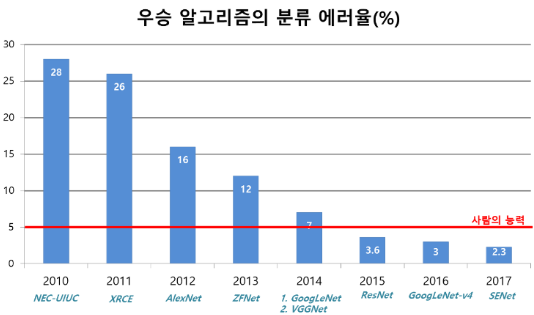
여기서는 Large Scale Visual Recognition Challenge(이미지넷 이미지 인식 대회) 이하 ILSVRC에서의 우승작들에 대해 알아보면서 CNN의 Image Level Classification이 어떻게 발전해왔고 어떤 방향으로 발전할 것인지 알아보고자 한다
앞으로 배우겠지만 CNN은 주로
Convolution Layer,Pooling Layer,Fully Connected Layer로 이루어져있다.여기서 모델들의 발전과정을 잘 살펴 보면
Fully Connected Layer의 크기를 줄이는 방향으로 점점 바뀌게 된다는 것을 확인할 수 있다..이 이유를 간단하게 설명하자면, Parameter의 수가 늘어나면 늘어날수록 학습이 어렵고, Generalization성능이 줄어드는데,
Fully Connected Layer는 그 특성상 매우 많은 수의 Parameter를 갖기 때문이다.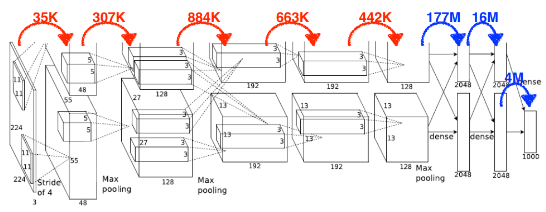
(Parameter수 비교 그림)
ILSVRC
이미지넷 이미지 인식대회, ImageNet Large-Scale Visual Recognition Challenge의 약자로 Classification, Detection, Loclaization, Segmentation의 성능을 가지고 경쟁하는 대회이다.
2) AlexNet
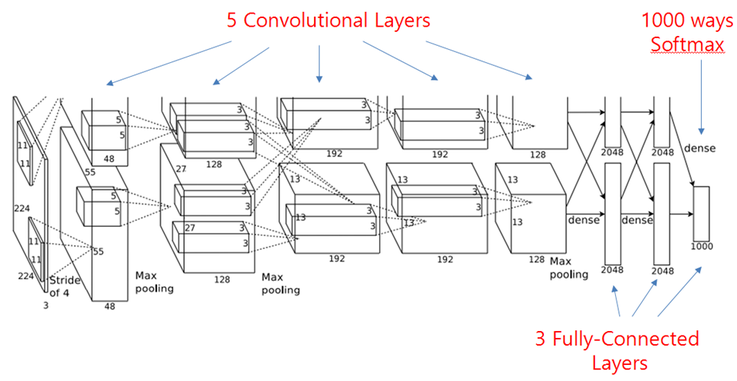
2012년도 ILSVRC 우승 논문
처음으로 딥러닝방식을 통해 기존 알고리즘들을 이기고 우승을 차지했고, 이 논문 이후로는 모두 딥러닝방식들이 ILSVRC에서 우승하게 된다.
주요 특징
- 2개의 GPU사용
: 당시에는 GPU성능/용량이 좋지 않았기 때문에 2개의 GPU에 나누어 학습하도록 구성하였다.
11 * 11 Convolution filter사용
: 현재에는11*11은 좋지 않다고 알려져 있으나 이 논문에서는11*11의 filter를 사용하였다.
- 5개의 Convolution Layer와 3개의 FCL을 사용하였다.
- ReLU 활성화 함수 사용
- Data Augmentation을 활용하였다.
- DropOut을 사용하였다.
지금은 당연한 세팅이지만 당시에는 그렇지 않았다.
즉, 이 AlexNet이 현재 딥러닝 모델들의 기본적인 틀을 만들었다는 평가를 받고 있다.
3) VGGNet
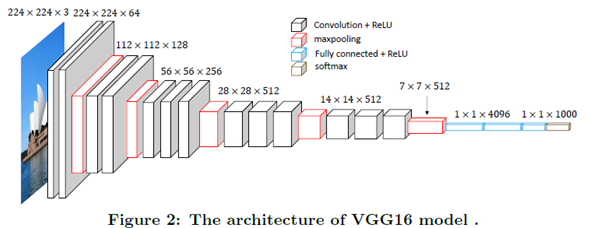
2014년도 ILSVRC 준우승 논문
ILSVRC에서 우승한 것은 아니지만, 후에 나올 딥러닝의 방향을 제시한 논문으로 모델은 Layer의 수에따라 VGG16, VGG19로 나뉜다.
주요 특징
3 * 3 Convolution Filter만을 사용하여 Convolution Layer를 구성
:3*3은 Parameter의 수를 줄이는데 아주 효과적이다.
- Fully Connected Layer에
1*1Convolution filter사용
: 여기서1*1을 사용한 것은 Parameter의 수를 줄이고자 한 것은 아니었다고 한다.
- DropOut을 사용하였다.
3*3 Filter와
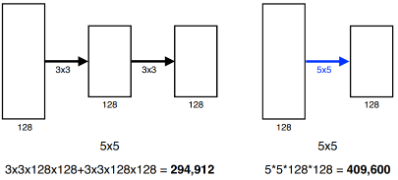
위의 그림을 보면 알 수 있듯이 Receptive Fields가 같고, 그에 대한 Output의 크기가 동일하지만
5*5를 1개 활용하는 것보다3*3을 2개 활용하는 것의 Parameter의 수가 훨씬 더 작다이 때문에 최근까지도 Convolution Filter의 크기는 커봐야
7*7을 넘어가지 않는다고 한다.
4) GoogleNet
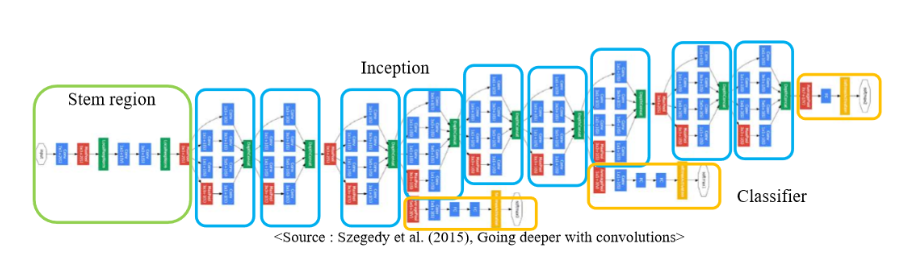
2014년도 ILSVRC 우승 논문
Network-In-Network 구조를 가지는 22 Layer로 구성되었다.
VGG나 이전 모델들과 비교해보면 Layer는 제일 깊지만, Parameter의 수는 제일 적다는 것을 확인할 수 있다.
주요 특징
- Inception Block을 통해 Parameter의 수를 획기적으로 줄였다.
: 관련 내용은 밑에서 자세히 설명
Inception Block
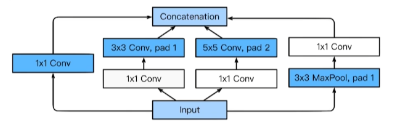
- 하나의 입력에 대해 여러 결과를 만들고 이를 Concatenate한다.
1*1 Convolution을 활용해 Parameter의 수를 매우 줄였다.
1*1 Convolution
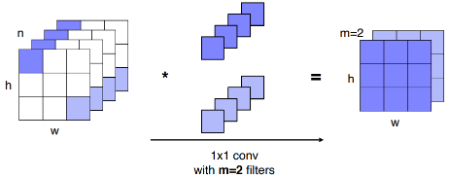
위의 그림을 보면 알 수 있듯이
1*1Convolution은 Channel의 깊이를 줄이는 역할을 한다.즉, layer중간중간 이
1*1Convolution를 잘 활용할 경우 Parameter의 수를 줄이는데 매우 효과적이다.
5) ResNet

2015년도 ILSVRC 우승 논문
그 유명한 Kaiming He가 2015년도에 낸 논문으로 이전까지는 모델의 깊이가 깊어지면 오히려 성능이 안좋아 진다는 단점이 있었는데 이 논문은 이것을 해결하여 처음으로 사람의 능력을 이기는 모델을 만들었다.
주요 특징
- Residual Block사용
: 뒤의 내용 참조
- Skip Connection사용
: 한 Layer의 Output을 몇개의 Layer를 건너뛴 후에 Input으로 추가하는 것을 말한다.
- Bottleneck Architecture사용
: 뒤의 내용 참조
Residual Block
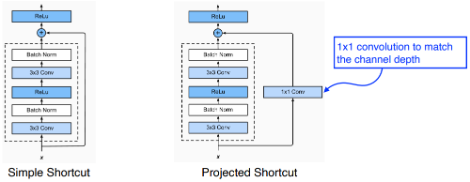
이전까지는 층이 깊어질수록 BackPropagate를 하면서 과거의 정보를 잃어 버리기 때문에 층을 늘리는데 한계가 존재했다.
ResNet에서는 이를 해결하기 위해 Residual Block을 활용했는데 Residual Block에서는 Skip Connection을 활용해 과거의 정보를 잃지 않도록 보완해 주었다.
Bottleneck Architecture
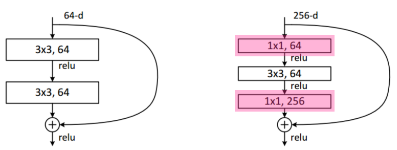
GoogleNet에서 보았던 Inception Block과 비슷한데, 전체 Parameter의 수를 줄이기 위해
3*3 Convolution을 하기 전과 후에1*1 Convolution을 사용해 주는 구조를 말한다.
Layer가 깊어질수록 발생하는 문제
- Overfitting
- gradient vanishing
즉, Generalize performance
결과
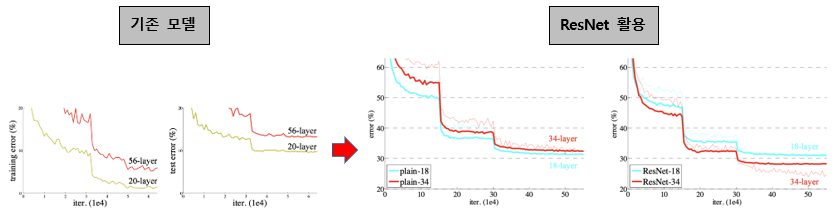
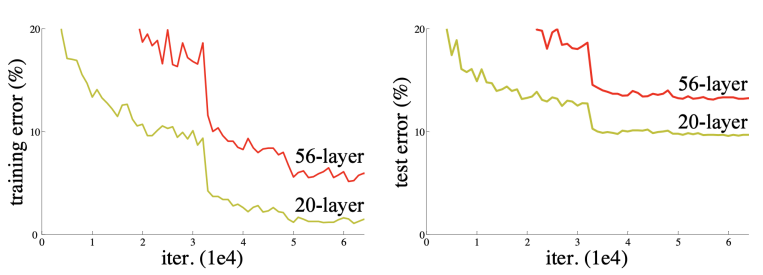
위의 그림을 보면 알 수 있듯이 기존 모델에서는 OverFitting이 일어나지 않더라도 어느정도 층이 깊어지면 성능이 오히려 떨어지게 되는 경우가 많았다.
하지만 ResNet에서 제안한 방법을 사용할 경우, 층을 깊게 쌓더라도 성능이 떨어지지 않았고 오히려 적게 쌓은 모델보다 더 좋은 성능을 낼 수 있게 되었다.
6) DenseNet
마지막으로, ILSVRC우승 논문은 아니지만, 컴퓨터 비전 분야에서 3대 학회로 불리는 CVPR에서 2017년도에 Best Paper를 받은 "Densely Connected Convolutional Networks"에 대해 알아보자.
주요 특징
- Dense Block을 사용
- Dense Block의 문제를 해결하기 위해 Transition Block을 사용
- Bottleneck Architecture사용
Dense Block
Dense Block의 큰 특징은 다음 두가지와 같다.
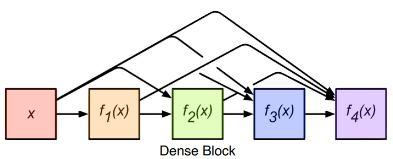
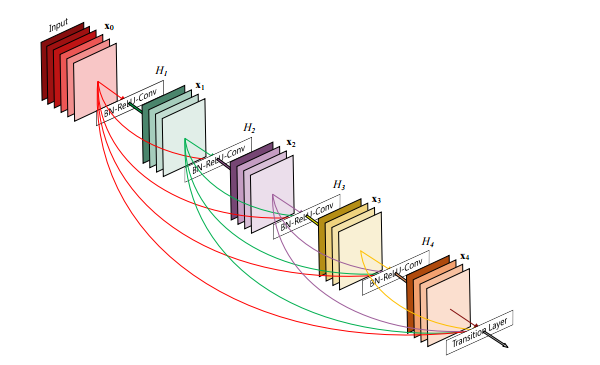
- Feed Forward시 각 Layer들을 다른 모든 Layer들과 연결한다.
ResNet에서는 다음의 Layer와 한번만 연결해 주었었다.
DenseNet에서는 다음 Layer뿐만 아니라 그 뒤의 모든 Layer와 연결해 주고 있는 것을 확인할 수 있다.
이를 통해 얻을 수 있는 이점은 다음과 같다.
- Vanishing-Gradient 문제를 완화 할 수 있다.
- Feature Propagation을 강화 할 수 있다.
- Feature 의 재사용을 할 수 있다.
- Parameter 의 수를 줄일 수 있다.
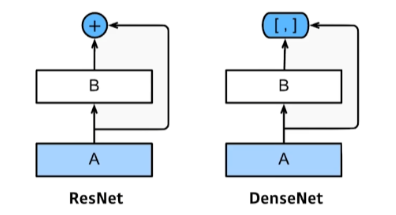
- Skip Connection시에 Resnet에서 제안했던 Addition방법을 하는 대신에 Concatenation을 활용한다.
Resnet은 이전 값을 다음에 더해줌으로써 층을 쌓았는데, 이는 층이 깊어질 수록 계산량이 증폭되어 정보의 흐름(Information Flow)가 지연된다는 단점이 있었다.
이를 해결하기 위해 DenseNet에서는 Addition을 하는 것이 아니라, Contcatenate해 줌으로써 이를 해결해 주었다.
물론 Concatenate해 줌으로써 Output의 크기가 비약적으로 향상된다는 단점이 있는데, 이는 뒤의 Transition Block을 활용해 해결하고자 하였다.
Transition Block

DensBlock을 지날 경우 Concatenate연산에 의해 그 Output의 크기가 매우 커진다.
이를 해결하기 위해 위의 그림처럼 중간중간마다 Transition Block을 활용해 주었다.
Transition Block은
1*1 Convolution과 Pooling작업을 통해 커진 Output을 다시 알맞은 크기로 변형시켜주는 역할을 한다.
추후 공부해볼 것
1) SENet
2) EfficientNet
3) Deformable Convolution
