AI의 종류
우선 머신러닝을 배우기에 앞서 AI(Artificial Intelligence)의 큰 틀을 알아보자.
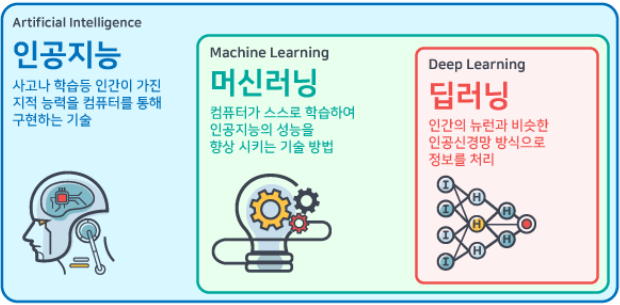
1) 인공지능(AI)
AI는 인공지능을 갖는 모든 기술들을 의미한다.
즉, 이것은 규칙을 기반한 추론, 자연어 처리, 이미지 처리, 계획, 머신러닝 등 다양한 모델을 표현하는 단어라고 생각하면 된다.
2) Machine Learning
머신러닝은 위의 인공지능의 한 분야로써, AI와 궁극적인 목표가 살짝 다르다.
AI는 어찌됐던 인간을 닮은 시스템을 개발하는 것이 목표였다면 머신러닝은 스스로 학습하는 알고리즘을 개발하는 것이 목표이다.
참고) AI와 Machine Learning의 차이점

3) Deep Learning
딥러닝은 머신러닝의 한 분야로써 머신러닝과는 구현 방법에 대한 목표의 차이가 존재한다.
머신러닝은 어찌됐던 스스로 학습하는 알고리즘을 만드는 것이 목표이지만, 딥러닝은 인공신경망 방식으로 스스로 학습하는 알고리즘을 만드는 것이 목표이다.
머신러닝 개요
우리는 이제부터 인공지능 모델 중, 머신러닝에 대해 알아보려고 한다.
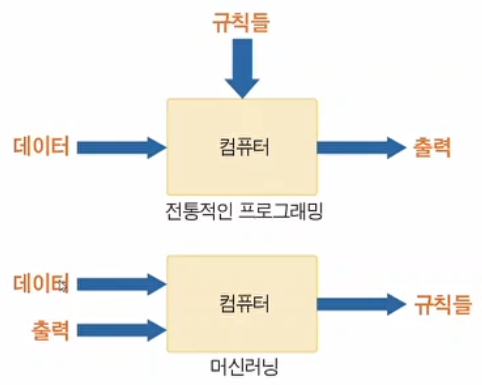
전통적으로 프로그래밍은 주어진 데이터에 대해 이미 정해 놓은 가공 과정을 거쳐 출력을 생성하는 것이었다.
하지만, 머신러닝은 데이터와 출력을 입력해 놓으면 이를 통해 컴퓨터가 규칙을 생성하는 것을 말한다.
머신러닝의 종류
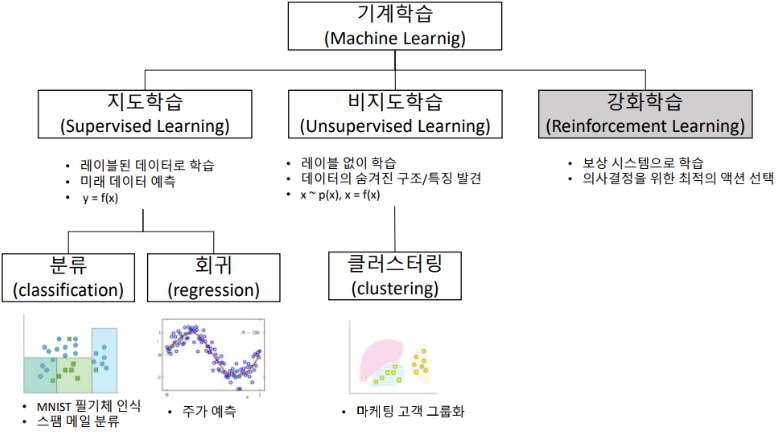
머신러닝은 스스로 학습하는 알고리즘을 의미했다. 즉, 이 학습하는 방법에 따라 머신러닝의 종류가 나뉘게 되는데, 이는 위와 같다.
참고로, 여기서는 딥러닝을 제외한 머신러닝을 알아보도록 할 것이다.
1. 지도 학습
1) 정의
지도학습이란, 어떤 데이터와 해당 데이터에 대한 출력값을 동시에 제공하여 학습시키는 것을 의미한다.
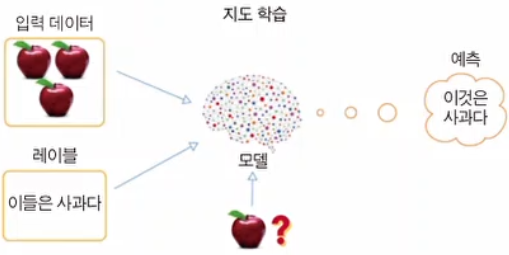
예를 들어, 위와같이 사과의 특징(색깔, 모양, 크기 등등) 데이터와 함께, 그 결과가 사과여야 한다는 것을 동시에 제공해 학습시키는 것을 의미한다.
(이렇게 결과값을 설정해 주는 것을 "레이블링"이라고 한다)
참고) 지도학습의 장단점
- 장점
- 결과값이 주어지므로 비지도 학습에 비해 정확도가 높다.
- 구현이 비교적 간단하다.
- 다양한 유형의 문제에 대한 적용이 가능하다.
- 단점
- 결과값을 같이 주어야 한다.
보통, 지도학습의 경우 매우 방대한 양의 데이터를 가지고 학습을 시킨다. 이 때, 이 방대한 양의 데이터에 일일이 레이블링을 해주어야 한다는 것은 매우 많은 시간을 필요로 한다.
2) 지도학습의 종류
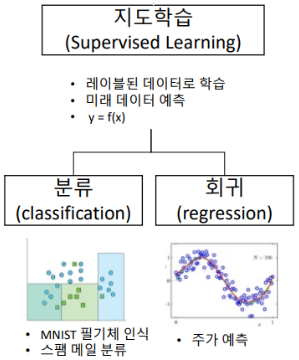
지도학습은 목표로하는 정답 값 y의 성질에 따라 크게 2종류로 나누어 볼 수 있다.
1. 분류(Classification)
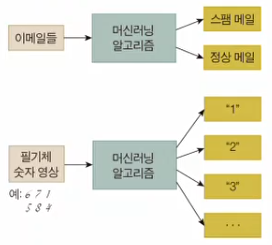
y의 Domain이 정해져있는 지도학습을 의미한다.즉, 우리가 목표로하는 정답값인
y가 특정 상수 k개로 정의될 수 있는 경우를 말한다.예를들어, 어떤 Feature를 입력받은 후 해당 입력 값이 사과인지 아닌지를 판별할 때 분류에 속한다고 할 수 있다. (k==2)
(k가 2인 경우 Binary Classification이라고도 한다.)
(k가 2이상인 경우 Multiclass Classification이라고도 한다.)이 Classification은 다시 Hypothesis를 어떤 방식으로 설정하느냐에 따라 다음과 같이 나누어진다.
- 선형 분류(Linear Classification)
- 로지스틱 회귀(Logistic Regression)
- K-최근접 이웃(K-Nearest Neighbors)
- 서포트 벡터 머신(SVM, Support Vector Machine)
- 결정 트리(Decision Tree)
- 랜덤 포레스트(Random Forest)
- 신경망(Neural Network)
- ...
2. 회귀(Regression)
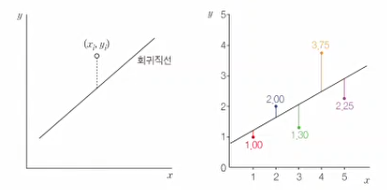
분류와는 다르게
y의 Domain이 따로 정해져 있지 않는 지도학습을 의미한다.예를들어, 날씨에 관한 입력 Feature에 대해, 결과값 이 사과의 수확량이라고 할 때, 이
y는 정해진 값에 대해서만 발생하는 것이 아니므로 회귀에 속한다고 할 수 있다.
분류와 마찬가지로 Hypothesis의 설정 방식에 따라 다음과 같이 나누어 볼 수 있다.
- 선형 회귀(Linear Regression)
- 로지스틱 회귀(Logistic Regression)
- 리지 회귀(Ridge regression)
- 라쏘 회귀(Lasso regression)
- 다항 회귀(Polynomial regression)
- 신경망(Neural Network)
- ...
3) 딥러닝
지도학습에도 분류와 회귀가 있었고, 이 문제를 해결하는 방식에 따라 KNN, SVM등 그 종류를 다양하게 나눌 수 있었다.
딥러닝은 지도학습을 구현하는 한가지 방법으로써 퍼셉트론을 이용하는 방식으로, 이 퍼셉트론은 인간의 뉴런을 모방하고 있다.
또 이 때, 이 퍼셉트론을 연결해 딥러닝을 구현할 수 있는데, 이 연결 순서/방법에 따라 딥러닝의 종류를 나눌 수 있다.
자세한 내용
2. 비지도 학습
비지도 학습은 지도학습의 반대라고 생각하면 된다. 즉, 어떤 데이터에 대해 출력값 없이 제공하여 학습시키는 것을 의미한다.
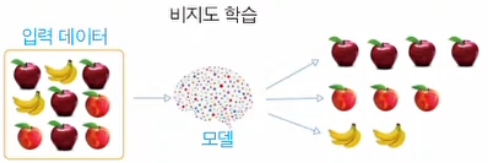
예를 들어, 위와같이 여러 과일들에 대한 데이터만을 주고 해당 데이터를 특정 기준으로 분류하는 것이 있을 수 있다.
(유튜브의 영상 추천 알고리즘과 같은 곳에 활용된다.)
참고) 비지도학습의 장단점
- 장점
- 데이터의 레이블링이 필요없다.
- 단점
- 지도학습에 비해 정확성이 떨어진다.
- 지도학습에 비해 구현이 더 복잡하다.
1) 클러스터링
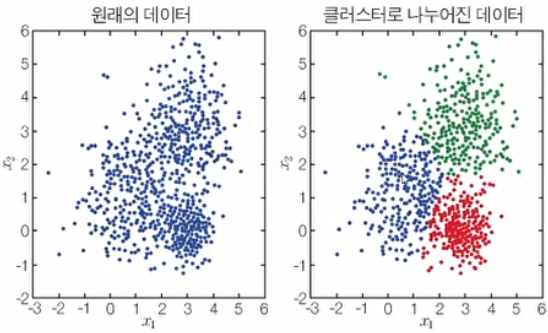
3. 강화 학습
어떤 행동에 대해 가산점, 벌점을 부여하여 학습시키는 방법
EX) 실시간 판단, 내비게이션, 인공지능 게임(알파고),
용어
학습 과정
: 임의의 w와 b를 설정
-> y값 도출 -> loss 계산 -> loss를 줄이는 방향으로 w와 b를 재설정 -> 이를 반복시행
딥러닝, Neaural Network
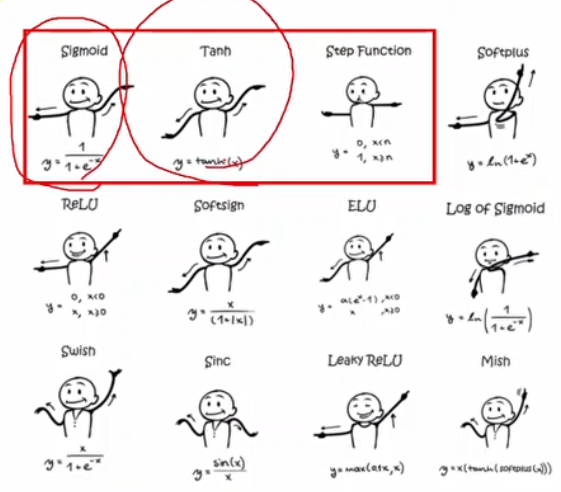
activate function

퍼셉트론
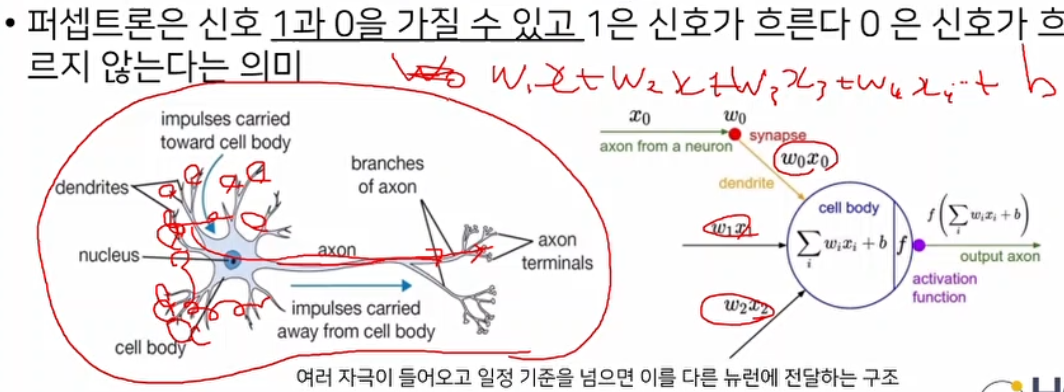
인간의 뉴런을 본따 wx + b를 여러개 붙인것
단층 퍼셉트론의 한계
: xor problem(인공지능의 겨울 초래)
-> 단층 퍼셉트론은 곡선을 표현할 수 없다.
-> 이것은 다층 퍼셉트론으로 해결 가능
-> 하지만 다층 퍼셉트론은 중간 퍼셉트론(hidden layer)의 학습이 불가능
해결방법
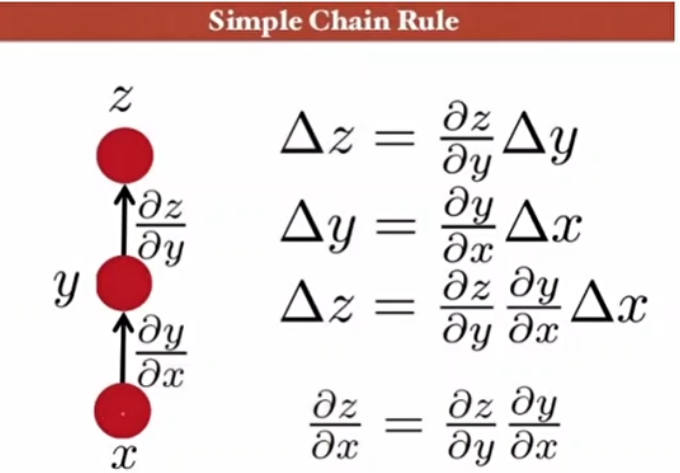
: 역전파 알고리즘(Back Propagation)
-> 역전파 알고리즘의 핵심은 chain rule