Generalization
데이터를 가지고 Model을 학습하기 전, 생각해보아야 할 것이 있다.
우리는 이 세상의 모든 데이터를 가지고 우리의 Model을 학습시킬 수 없다. 예를들어 이 세상의 모든 사과사진을 구할 수 없기 때문에 모든 변수를 고려해 Model을 학습 시킬 수 없다는 것이다.
즉, Data의 결핍으로 인해 Model은 항상 불확실성을 가진다는 것을 의미한다.
이를 해결하기 위해 Generalization이라는 방법을 통해 우리가 가지고 있는 데이터를 가지고, 우리가 학습시키지 못한 Sample에 대해서도 비슷한 성능을 가지도록 하는것이 중요하다.
1. Generalization이란?
우리가 가지고 있는 DataSet을 Training Set과 Test Set으로 나눈다. 그리고 이 Training Set을 기준으로 Model을 학습시킨 뒤, 이것을 Test Set에 적용해 다음의 목표를 달성하도록 하는 것을 말한다.
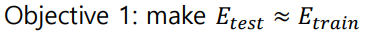
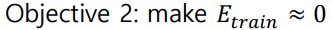
Training Error
: Training Set으로 학습시켰을 때의 Error를 의미한다.
Test Error
: Test Set으로 주어진 모델을 평가해 보았을 때의 Error를 의미한다.
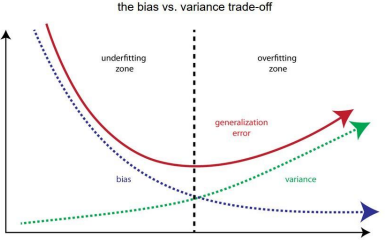
2. Over Fitting / Under Fitting
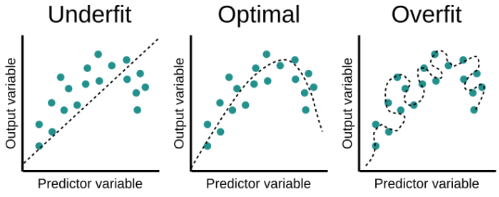
1) Over Fitting
다음의 목표는 우리가 학습시킨 모델이 실제 생활의 데이터에서도 잘 작동하기 위해서 필요한 조건이다.
만약, 이 목표를 고려하지 않고 학습시킬 경우, Over Fitting의 문제가 발생한다.
Over Fitting이란, 학습시킨 우리의 모델이 Training Set에서는 적합하지만 Test set에서는 그렇지 못하게 작동하는 것을 의미한다.
2) Under Fitting
다음의 목표는 우리의 모델이 학습이 되었다고 하기 위해서 반드시 필요한 조건이다.
만약, 이 목표를 고려하지 않고 학습시킬 경우, Under Fitting이 발생한다.
Under Fitting이란, 학습시킨 우리의 모델이 Training Set에서 좋은 성능을 내지 못하는 것을 의미한다.
3) 해결책
- Over Fitting 해결책
- Regularization(정규화)
: 특정 Feature에 대해서 가중치를 설정해 중요도를 설정하는 방법- 앙상블
- 더 많은 데이터
- Under Fitting 해결책
- 더 복잡한 모델 사용
- Optimization(최적화)
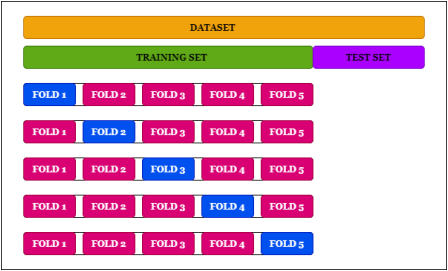
3. Cross-Validation
모델 학습 과정에서 Training Set을 n개로 쪼개서, 이중 n-1개로 학습을 시킨 후, 나머지 1개로 평가를하며 학습을 진행하는 것을 의미한다.
4. 정규화
1) Normalization
1. Normalization
2. Batch Normalization
2) Standardization
3) Regularization
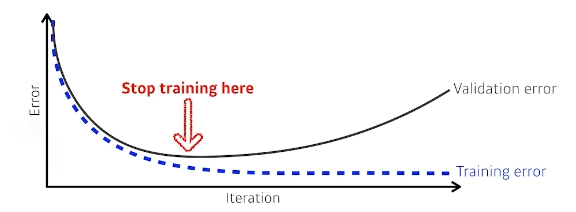
1. Early Stopping
학습을 빨리 멈춰 과적합을 막는 방법
2. Data Augmentation
Data에 약간의 변형을 주어 Data양을 늘리는 방법
(Mnist Data Set과 같이 위 아래의 방향이 중요한 경우도 있으니 각 Data의 성질을 잘 고려해랴 한다)
3. Noise Robustness
Data의 Input뿐만 아니라 Weight에 대해서도 학습 중간중간에 Noise를 주는 방법

(이 방법은 실험적으로 학습에 도움이 된다는 것이 알려졌다.)
4. Label Smoothing
Input Data를 다른 Input Data와 섞어 학습에 사용하는 방법으로 이를 통해 Decision Boundary를 부드럽게 만들어 줄 수 있다.
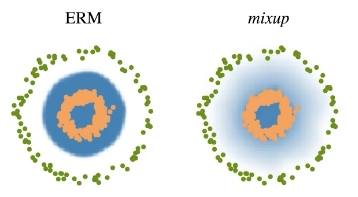
(Mixup, Cutout, CutMix등의 방법이 존재한다.)

(들이는 노력 대비 많은 성능 향상을 가져오므로 매우 추천)
5. Dropout
Forward(적용)과정에서 무작위로 몇개의 Weight를 0으로 만들어 사용하는 것.
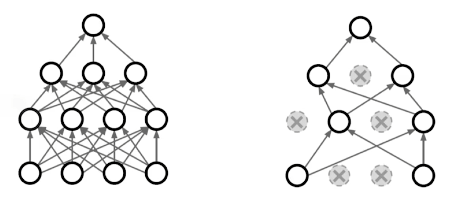
(이 방법 또한 실험적으로 학습에 도움이 된다는 것이 알려졌다.)
지도학습
1. 지도학습 개요
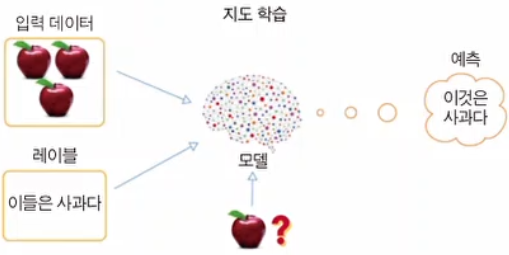
머신러닝의 목표는 입력x로 부터 우리가 원하는 정답y로 가는 함수 h를 구하는(학습시키는) 것이라고 할 수 있다.
(h는 Hypothesis의 약자로 Target Function을 의미한다)
즉, y = h(x)를 만족하는 h를 찾는 것이 목표인 것이다.
이때, 지도학습은 입력 x와 그에 대한 정답y를 모두 활용하여 학습시키는 방법을 의미한다.
(비지도학습은 x만 가지고 학습시키게 된다.)
이때, 모델의 입력
x를 입력 Feature라고 한다.
즉, 예를들어 사과를 학습시킬 때 입력 Feature로는 사과의 모양, 크기, 색깔 등을 사용할 수 있다.
이 입력 Feature는 풀고자 하는 문제에 대한 사전지식이 있어야 효과적으로 결정할 수 있다. 즉, 관련 분야의 전문가와 함께 결정하는 것이 좋다.
(최근의 Deep Learning Model의 경우에는 이 Feature를 스스로 학습하기도 한다.)
2. 학습 과정
1) Feature Selection
위에서 잠깐 이야기 했듯이 먼저 모델에 입력할 데이터를 뽑아내야 한다.
이때 이 의미있는 Feature를 정하는 것이 가장 중요한데, 이를 위해 논문이나, 전문가의 도움을 받는 것이 좋다.
(참고)
과거에 URL만 보고 Phishing Site인지에 대한 여부를 결정하는 프로그램을 만든적이 있었다.
이때, 여러 논문을 보고 URL에 Symbolic문자의 개수, Subdomain의 수 등이 Phishing Url을 결정하는 요건이 될 수 있음을 확인했고 이를 입력 Feature로 정할 수 있었다.
2) Model Selection
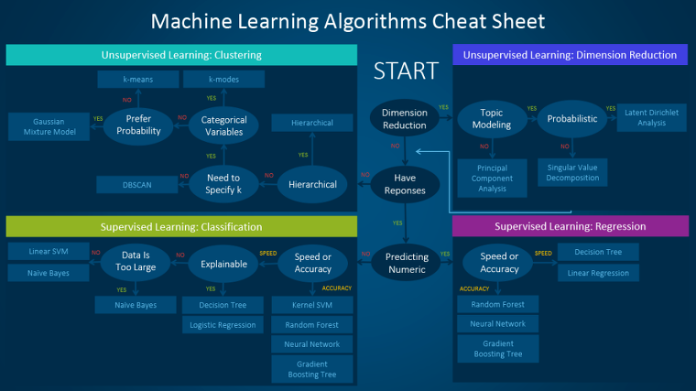
그 다음 풀고자 하는 문제에 가장 적합한 Hypothesis Model을 결정해야 한다.
예를 들어 O/X문제를 풀고자 할 경우, Binary Classification에 관한 Model을 결정해야 할 것이다.
3) Optimization
정답값과 예측값에 대한 loss를 정의하고 이 loss를 줄이는 방식으로 학습을 진행한다.
이 방법은 각각의 모델마다 다르다.
3. 지도학습 모델
1) Classification
Linear Classification
SVM
XOR문제에 대해 문제점 보유
-> SVM
-> ANN으로 해결
In DeepLearning
1. batch size
정의
데이터를 학습 시킬 때, 시간 단축을 위해 데이터를 묶음 단위로 학습시키는 것을 의미
즉, 학습은 다음과 같이 이루어 진다.
for i in range(EPOCH):
for inputdata, label in dataset[batchsize*i : batchsize*(i+1)]:(위의 코드는 이해를 돕기 위한 것으로 실제로 저렇게 사용되는 것이 아니다.
실제 코드는 보통 DataLoader라는 객체를 이용해 구현한다.)
장점
-> batch size를 줄이면 generallize performance가 좋아진다.
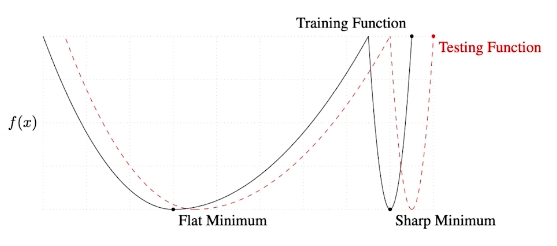
(이유: batch size를 줄이면 클 때에 비해 비교적 아래의 그림에서 보이는 Flat Minimum에 도달할 가능성이 높다 -> 즉 Testing Function에서도 Minimum근처에 있을 확률이 높다.)
2. gradient descent