NLP기본 모델
1. BackGround
1) Data의 특성
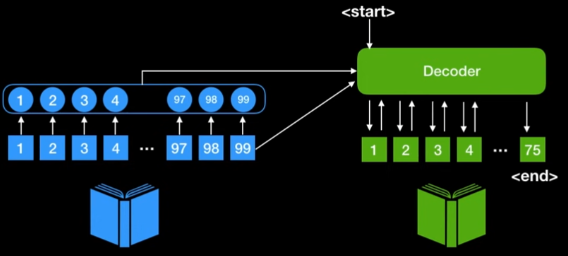
우리가 앞서 배웠던 RNN모델은 Sequential Data를 Fixed Data로 바꾸는 모델이었지만 여기서는 자연어 처리, 즉 Sequential Data를 다른 Sequential Data로 변형해 주는 방법을 알아볼 것이다.
이 때, 가장 큰 문제는 입력의 길이와 출력의 길이가 다르기 때문에 일반적인 RNN 모델들을 바로 사용할 수 없다는 것이다.
예를 들어
"넌 누구니?"와 같이 2개의 입력이 들어갈 경우"Who are you?"와 같은 길이가 3인 출력이 나올 수 없다.
2) Encoder와 Decoder

위의 문제를 해결할 대표적인 방법은 Encoder와 Decoder를 사용하는 것이다.
즉, 1. Encoder를 통해 입력할 Sequential Data를 하나의 정보로 압축하고,
2. Decoder를 통해 이 정보를 사용해 다시 Sequential Data를 만들어내는 것이다.아래에서 설명하는 모델들은 이 과정에서 발생하는 문제를 각각의 독특한 아이디어로 해결해 나가는데, 이 과정을 중점으로 보면 이해하기 쉬울 것이다.
2. Seq2Seq
1) Idea
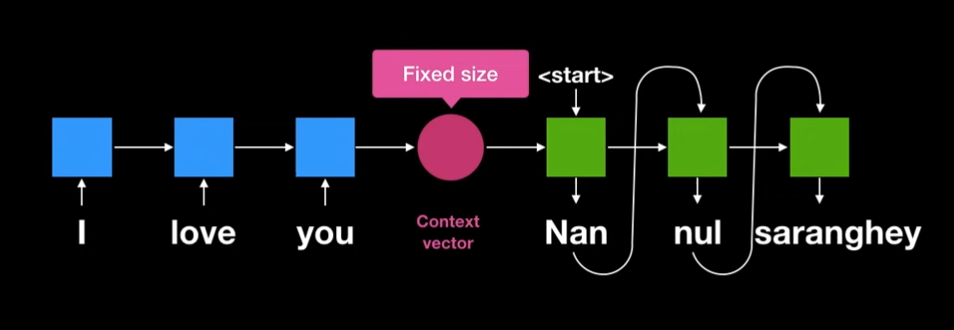
Seq2Seq에서는 RNN기반의 Encoder를 통해 하나의 고정된 크기의 Context Vector를 생성한다는 것이 가장 큰 특징이다.
즉, Sequential Data를 RNN기반의 모델에 넣어 나온 최종 출력을 Context Vector로 정한게 된다.
(이 값을 다음 Encoder에 넣기도 한다.)그 후, 이 Context Vector를 Start Token과 함께 Decoder에 넣어 단어를 하나 생성한다.
그 다음 생성된 단어를 다시 Decoder에 넣는 과정을 End Token이 나올때 까지 반복하게 된다.
2) 개선사항
LSTM
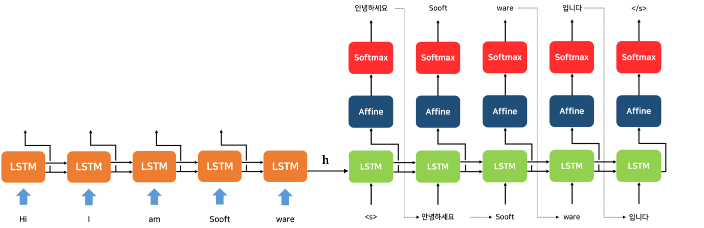
Encoder와 Decoder로 일반 RNN을 사용할 경우 RNN의 단점인 Exploding/Vanishing Gradient에 빠지게 된다.
따라서 보통 LSTM을 가지고 Encoder와 Decoder를 만들게 된다.
입력 데이터 반전
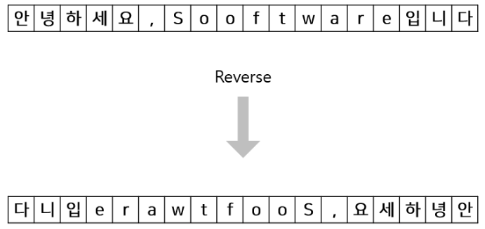
간단한 트릭이긴 하지만, 입력 데이터의 첫 글자는 뒤로 갈수록 변형되기 때문에, Decoder에 처음으로 입력될 때, 이 첫 글자의 정보가 제대로 입력되지 않을 가능성이 있다.
위의 정보가 정확한 근거는 아니겠지만 실제로 입력 데이터를 반전시킬 경우 성능 향상이 있다고 한다.
3) 단점
고정된 Size의 Context Vector를 사용하다 보니 입력 문장의 길이가 길어질 경우 이 Vector가 모든 정보를 포함하지 못하게 되어 성능이 매우 떨어진다.
2. Seq2Seq + Attention
1) Idea
위의 Seq2Seq모델의 단점은, 고정된 크기의 Context Vector를 사용해 발생하였다.
Attention 모델에서는 이 문제를 해결하기 위해 RNN모델에 Sequetial Data를 넣을 때 나오는 모든 Output을 이용하도록 해 주었다.
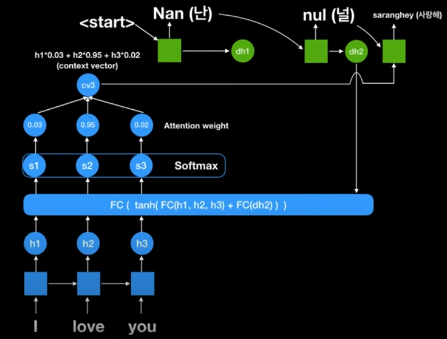
예를들어 "I love You"를 RNN에 입력할 때, "I"를 넣었을 때의 State
a, "love"까지 넣었을 때의 Stateb, "You"까지 넣었을 때의 Statec를 모두 고려해abc라는 Context Vector를 만드는 것이다.
Attention 모델의 장점
Attention모델의 장점은 크게 2개가 있다.
Context Vector가 고정된 Size를 갖지 않고, 문장의 길이에 따라 달라지는 Size를 갖는다.
각각의 State에 가중치를 주어 우리가 집중해야 할 단어들을 선정할 수 있도록 설계할 수 있다.
1번은 앞서 설명했기 때문에 2번을 잠시 언급해 보자면 먼저 Context Vector는 각각의 단어에 대한 Output을 갖고있다.
즉, 이 Context Vector에 대해 가중치 벡터를 곱하게 되면 각 단어에 대해 중요한 단어와 상대적으로 덜 중요한 단어에 대한 단서를 학습시킬 수 있게 된다.
2) Teacher Forcing
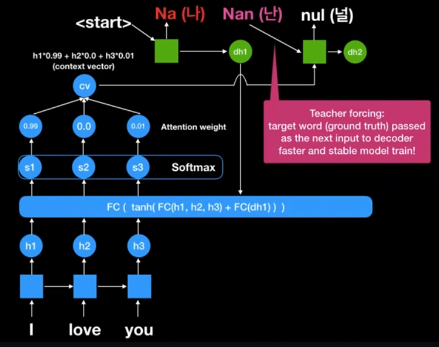
학습이 완료되기 전 우리는 Decoder부분에서 Prediction값을 다음 Decoder에 넣는 작업이 필요하다.
하지만 이 때, 잘못되 Prediction을 넣을 경우 어차피 우리가 원하는 결과가 나오지 않기 때문에 학습하는데 문제가 발생한다.
이 문제를 해결하기 위해 학습시에 예측값을 입력하는 것이 아닌 정답값을 따로 넣어 학습을 시키는 방법을 Teacher Forcing이라고 한다.
3) 단점
Attention을 활용해 많은 장점을 갖게 되었지만 결국 RNN을 활용해 학습 시켜야 한다는 단점이 존재했다.
즉, 입력을 Sequential하게 입력해 학습시켜야 하기 때문에 학습 시간이 오래 걸리고, 입력의 길이가 길어지는데에도 한계가 존재한다는 것이다.
요약
Seq2Seq는 Encoder와 Decoder를 통해 자연어처리에 대한 방법을 제시했지만, 고정된 크기의 Context Vector를 사용해 그 성능이 줄었다.
이를 해결하기 위해 Attention기법이 탄생했는데, 모든 단어에서 각각 Context Vector를 도출하고 이에 Attention을 주는 방법을 통해 성능을 향상시켰다.
하지만 Attention기법도 결국 RNN Cell을 이용해야 하기 때문에 번역 시간이 오래걸린다는 단점이 존재했다.
이에 2017년도에 Attention is All You Need라는 제목으로 발표된 논문에서는 RNN Cell을 아예 제거하고, 오직 Attention만을 통해 학습시키는 Transforemr구조를 제시하게 된다.
3. Transformer
1) Idea
Transformer는 RNN모델들을 아예 제거하고 Attention 기법으로만 Input Data를 해석한다.
이 때, RNN이 사라지면서 문장에서 단어의 순서를 고려할 수 없게 되었기 때문에 Input값에 위치 정보도 추가해주도록 하는 Positional Encoding이라는 방법을 사용한다.
Transformer의 장점
- 계산의 효율성
: 기존의 RNN기반의 복잡하고 시간이 걸리는 모델에서 벗어났다.
Saturating Performance가 없음
: 데이터셋의 크기가 많더라도 성능 향상의 한계가 있다는 것을 Saturating Performance라고 한다.Transformer는 데이터 셋의 크기가 적으면 그 성능이 매우 떨어지지만 그만큼 많으면 많을수록 성능이 다른 모델들보다 좋아진다.
- 큰 싸이즈의 모델도 훈련이 가능하다.
: 데이터를 순서대로 처리하는 RNN과는 달리 한번에 처리하기 때문에 모델의 크기와 상관없이 사용 가능하다.
(단, 그만큼 많은 용량의 메모리가 필요하다.)위와 같이 많은 장점들을 가지고 있기 때문에 Transformer는 NLP뿐만 아니라 CV에서도 사용하고자 한다. 대표적으로 Vision Transformer(VIT)가 있다.
2) Positioinal Encoding
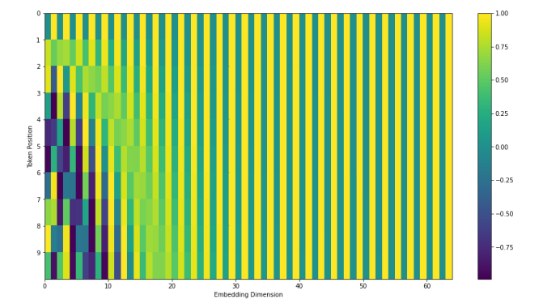
앞서 말했듯이 Transformer는 RNN을 사용하지 않기 때문에 Positional Encoding이 필요하다.
이때, 해당 논문에서는 아래의 그림과 같은 Cosine과 Sine함수를 이용해 Positional Encoding을 한다.
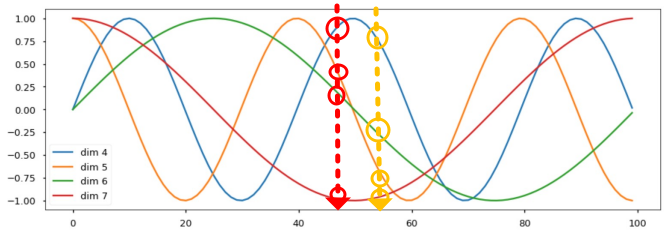
이때, Cosine과 Sine은 주기함수여서 위치값이 겹치지 않을까 생각할 수 있지만, 여러 주기의 Sine과 Cosine함수를 동시에 사용함으로써 해당 문제를 해결하였다.
예를 들어 위의 그림에서 서로 다른 두 위치를 정할 경우 해당 위치에서의 Sine과 Cosine함수의 집합은 다른 위치의 벡터와 전혀 다르다는 것을 확인할 수 있다.
자세한 내용은 다음의 블로그를 참조
3) Encoder - Multi Headed Attention
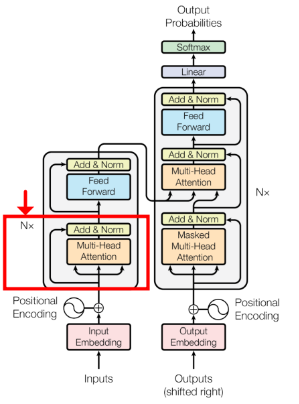
-- Self Attention --
Preview
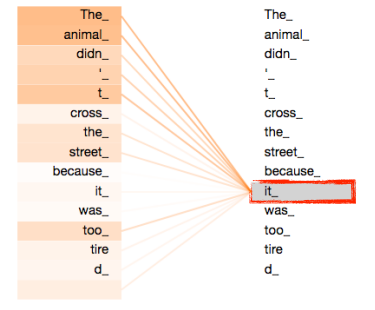
문장 속에서 어떤 단어를 이해할 때에는 그 단어 자체만으로 이해하면 안되고 그 단어가 문장에서 어떤 역할을 하는지, 즉 다른 단어들과 어떤 연관을 갖는지 알아야 한다.
예를들어, 위의 그림에서는 문장 속에서
it이The Animal과 가장 큰 관련성을 가진다는 것을 나타내 준다.자세한 과정을 설명하기에 앞서 그 과정을 요약하자면 다음과 같다.
- 각 단어에 대해 Query, Key, Value라는 정보를 만든다.
- 이것과 다른 단어의 Key, Value를 곱해 다른단어들과의 연관성을 구한다.
- 다른 단어들과의 연관성 정보를 합해 해당 단어의 Encoding Vector를 구한다.
- 각 단어별로 Query, Key ,Value Vector를 만든다.
- Vector의 크기는 하이퍼 파라미터로, 사용자가 직접 설정한다.
- Query와 Key는 항상 차원이 같아야 하지만 Value는 같을 필요는 없다.

Query, Key, Value의 의미
Query: 단어에 대한 Embedding값?
Key:
Value:
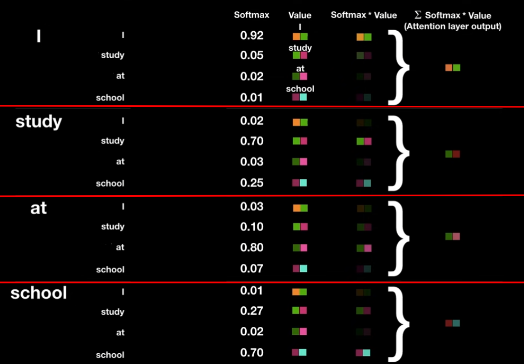
- 각 단어의 Query에 대해 나머지 단어의 Key를 곱해
Attention Score를 만든다.
- Normalize
: Score Vector를 구한 후sqrt(Key Vector의 Dimension)로 나누어 SoftMax연산시 값이 잘 나오도록 해준다.
이 Score는 후에 Attention Weight로 변해 각 단어가 다른 단어에 대해 얼마나 집중해야 하는지 결정하는 역할을 한다.
- Score Vector를 Normalize해주고
Attention Weight를 구한다.
- Attention Weight
: Normalize한 Score에 Softmax연산을 취해준다.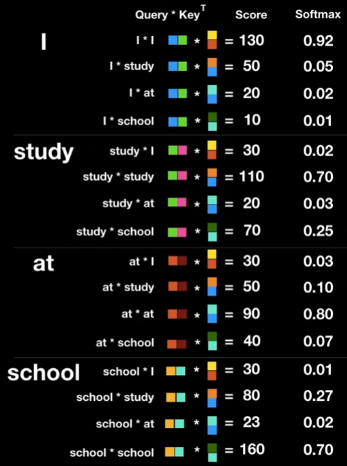
이 Attention Weight는 현재 단어에 대해서 다른 각 단어들에 대한 가중치를 표현하게 된다.
- Attention Weight에 각각의 단어의 Value를 곱해준다.
여기서 현재 단어가 각 단어의 정보를 얼만큼 표현해야 하는지 결정된다.
- 위에서 구한 값들을 모두 더해 해당 단어에 대한 Encoding Vector를 구한다.
이제 우리는 각 단어에 대한 Encoding Vector를 얻었다.
이 때, 이 Encoding Vector는 우리가 미리 설정한 Value Vector와 차원이 같다는 것을 유의해야 한다.
Self Attention 그림 요약
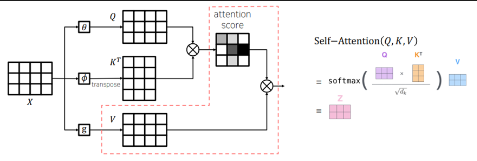
-- Multi Headed Attention --
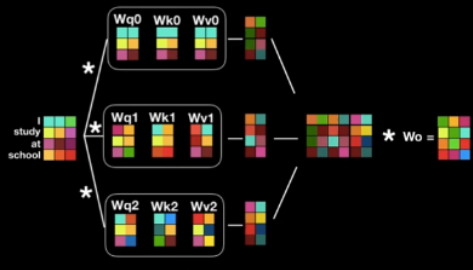
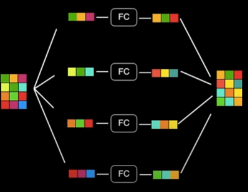
사람의 문장은 모호할 때가 훨씬 많고, 다양한 해석의 가능성이 존재한다.
따라서 본 논문에서는 위의 각 단어에 대해 Self Attention의 과정을 여러개의 Query-Key-Value쌍을 만들어 수행하도록 하여 여러 관점에서 그 문장을 해석하도록 해 주었다.
그림에서 보면 알 수 있듯이, 이 여러 Self Attention의 결과를 Concatenate한 후, 다시 Linear연산을 통해 다음 Encoder에 들어갈 수 있도록 크기를 조절해 주는 것을 확인할 수 있다.
(Multi Headed Attention 과정은 병렬적으로 처리되기 때문에 계산 속도에 대해서는 거의 영향을 주지 않는다.)
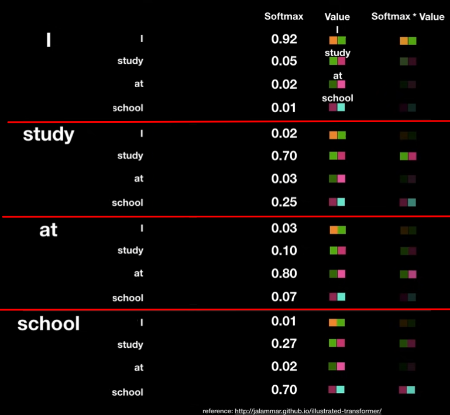
5) Encoder
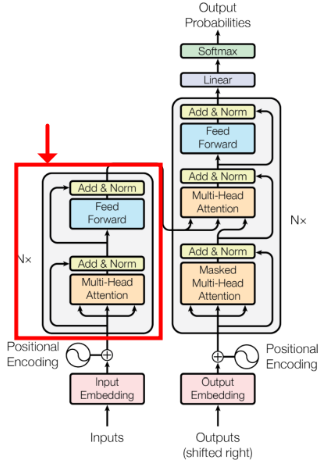
Feed Forward
Multi Headed Attention의 결과값은 다시 Fully Connected Layer를 거쳐 Encoder의 최종 출력으로 전달 되게 된다.
이때, Encoder의 최종 출력의 모양은 최초 입력의 모양과 같다는 점을 기억하자.
(각 단어의 Encoding Vector는 Value Vector의 모양과 같았다는 점과 헷갈리지 말자)
Residual Connection
word embeding + positional encodnig
해당 모델을 학습시키다 보면 역전파과정에 의해 이 Positioinal Encoding의 정보가 많이 손실 될 가능성이 크다.
이를 보완하기 위해 Residual Connection을 사용해 주었다
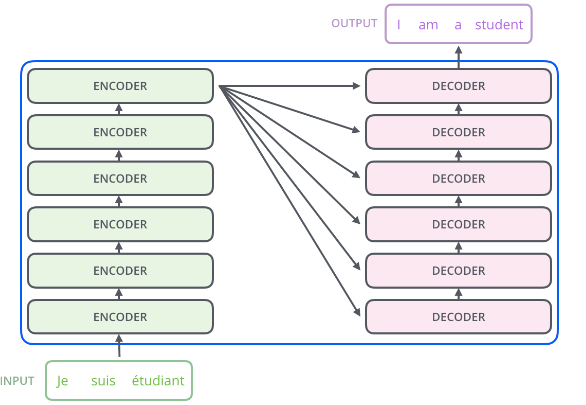
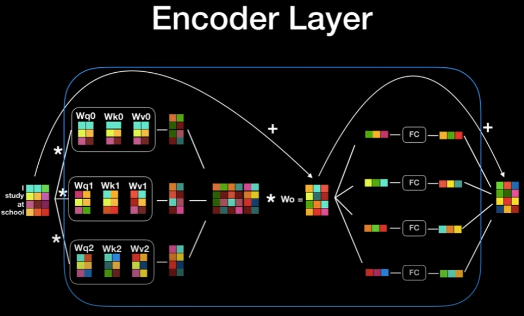
Encoder Layer

Ecoder의 입력과 출력의 모양이 같다는 점을 이용하여 위 그림과 같이 서로다른 Encoder여러개를 쌓아줄 수 있다.
본 논문에서는 6개의 층을 쌓았다고 한다.
6) Decoder - Masked Self Attention
Encoder의 경우 예측을 위해 사용할 수 있는
7) Decoder - Masked Multihead Attention
8) Decoder
Feed Forward
코드
