Adjacency Node를 표현하는 방법
- Array
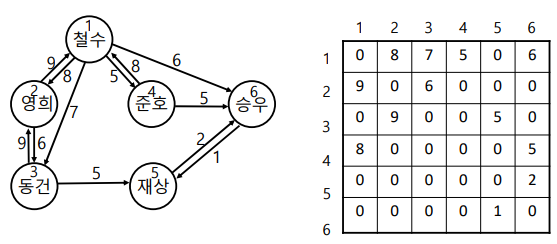
- 간선의 정보가 dense한 경우 주로 사용
A[출발지][목적지]에가중치를 저장
- list

- 간선의 정보가 sparse한 경우 주로 사용
A[출발지]에{목적지, 가중치}를 리스트 형태로 저장
그래프 탐색 방법
1. BFS

1) 설명
위의 그림과 같이 한 노드에 대해 인접 노드들을 모두 넣어가면서 차례대로 검사하는 방식이다.
2) Code
준비물
- Queue
- Map배열
: 각 노드들의 연결관계를 표현한 배열
- visited배열
: 노드별 방문여부를 체크한 배열
int Map[100][100]; // 1차원 노드들의 연결관계 표현 bool visited[100]; // 현재 방문 완료한 노드 표현 void BFS(int start, int node_num) { visited[start] = true; queue<int> q; q.push(start); while(!q.empty()) { int now = q.front(); //###################### //# 현재 노드에서 할 행동 # //###################### // now와 연결된 노드들에 대해 방문하지 않았으면 enqueue for(int i=0; i<node_num; i++) { int next = Map[now][i]; if(next!=0 && !visited[next]) { q.push(next); visited[next] = true; } } } }
2. DFS

1) 설명
위의 그림과 같이 한 노드에서 일단 끝까지 검사하고 그다음 노드들을 검사하는 방식이다.
2) Code
준비물
- Stack
- Map배열
: 각 노드들의 연결관계를 표현한 배열
- visited배열
: 노드별 방문여부를 체크한 배열
int Map[100][100]; bool visited[100]; void DFS(int start, int node_num) { stack<int> s; s.push(start) while(!s.empty()) { int now = s.top(); if(!visited[now]) { visited[now] = true; //###################### //# 현재 노드에서 할 행동 # //###################### // now와 연결된 노드들에 대해 방문하지 않았으면 enqueue for(int i=0; i<node_num; i++) { int next = Map[now][i]; if(next!=0 && !visited[next]) s.push(next); } } } }
(DFS는 재귀함수방식을 사용해서도 구현 가능하다.)
최소 비용 신장 트리 알고리즘

신장트리란?(Spanning Tree)
신장 트리는 위의 그림과 같이 N개의 노드를 가지는 "
가중치를 가지는",
"무방향 그래프"에서 간선의 개수를 "N-1"개를 골라 "트리"가 되도록 만든 것을 의미한다.⭐️ Tree이기 때문에
사이클이 생성되어서는 안된다.또, 위의 그림을 보면 알 수 있듯이 한 그래프에 대해서 신장트리는 여러개가 존재할 수 있다.
최소 비용 신장트리란?(MST)
이 여러개의 신장 트리 중 모든 간선의 합이 최소인 것을 최소비용 신장트리라고 한다.
(이 알고리즘은 코드 구현이 너무 길어 개념만 집고 넘어갈 예정이다.)
1. Kruskal 알고리즘

1) 설명
- 모든 간선들 중 "
가중치가 가장 작은 간선"을 신장트리에 넣는다.
- 만약 1번의 결과 사이클이 형성될 경우 해당 간선을 제외하고 앞으로 고려하지 않는다.
- 1~2번 과정을 신장트리 안에서 모든 노드가 연결될 때까지 반복한다.
2. Prim 알고리즘
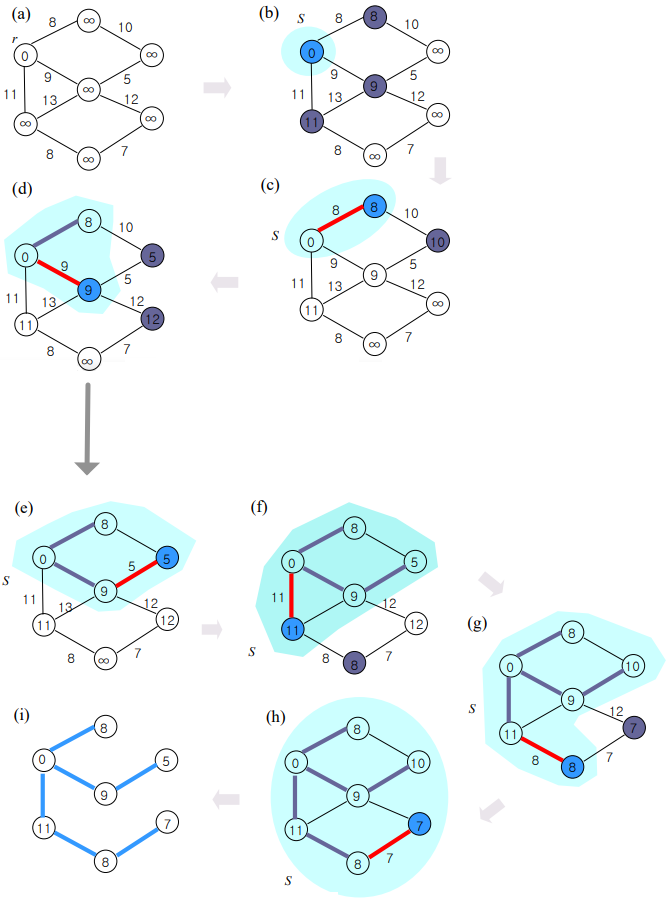
1) 설명
- 임의의 한 노드를 선택해 신장트리에 넣는다.
- 신장트리와 연결된 간선들 중 가중치가 가장 작은 것을 고른다.
- 해당 간선과 연결된 노드와 간선을 신장트리에 넣는다.
- 3번의 결과 사이클이 형성될 경우 해당 간선을 제외하고 앞으로 고려하지 않는다.
- 2~4 과정을 모든 노드가 연결될 때까지 반복한다.
3. Kruskal VS Prim
1) 시간 복잡도

2) 결론
Kruskal
: 간선이 Sparse하게 존재할 경우 Prim보다 더 나은 성능을 가진다.
Prim
: 간선이 Dense하게 존재할 경우 Kruskal보다 더 나은 성능을 가진다.
3) Sollin
kruskal과 prim을 적절히 섞어 사용하는 알고리즘
위상정렬
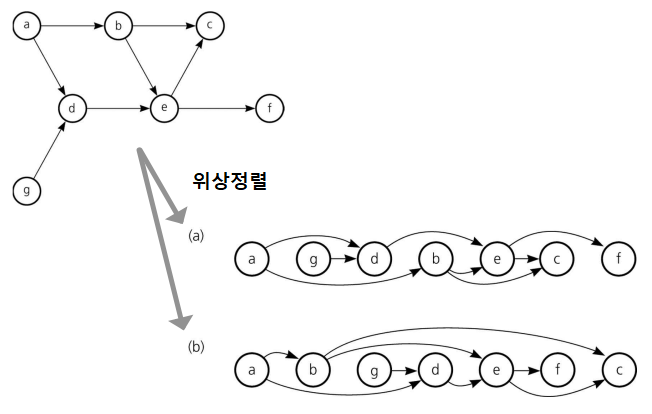
위상정렬이란? (Topological Sorting)
"
싸이클이 없는 유향 그래프" 즉,DAG를 정렬하는 알고리즘으로, a->b인 간선에 대해 a, b순서를 가지도록 정렬하게 된다.또, 위의 그림을 보면 알 수 있듯이 한 그래프에 대해 위상의 순서는 여러개가 존재할 수 있다.
1. 진입차수 이용

1) 설명
- 진입 간선이 없는 정점을 모두 선택한다.
- 해당 정점들을 정렬된 배열에 추가한다.
- 배열에 추가한 정점들에 대해 해당 정점과 연결된 간선들을 삭제한다.
- 1~3을 반복 수행한다.
2. DFS 이용

1) 설명
- 랜덤한 정점을 하나 선택한다.
- 해당 정점에 대해 DFS를 수행하되 BackTracking을 수행할 때, 배열에 추가한다.
- 배열에 추가한 정점들에 대해 해당 정점과 연결된 간선들을 삭제한다.
- 1~3을 반복 수행한다.
(참고)
: 진입차수를 이용하는 방법과는 다르게, 결과적으로 가장 뒤에 있는 값들부터 채워진다.
BackTracking
Branch-And-Bound
A* 알고리즘
컬러링 문제
