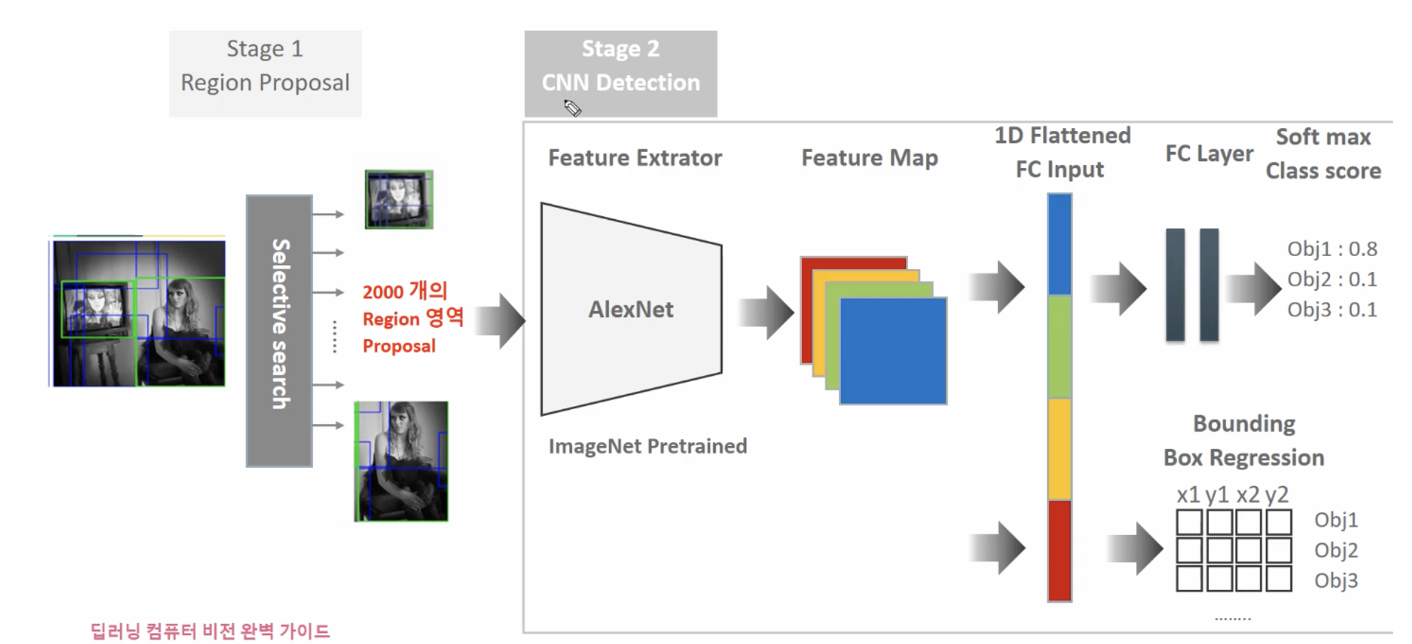
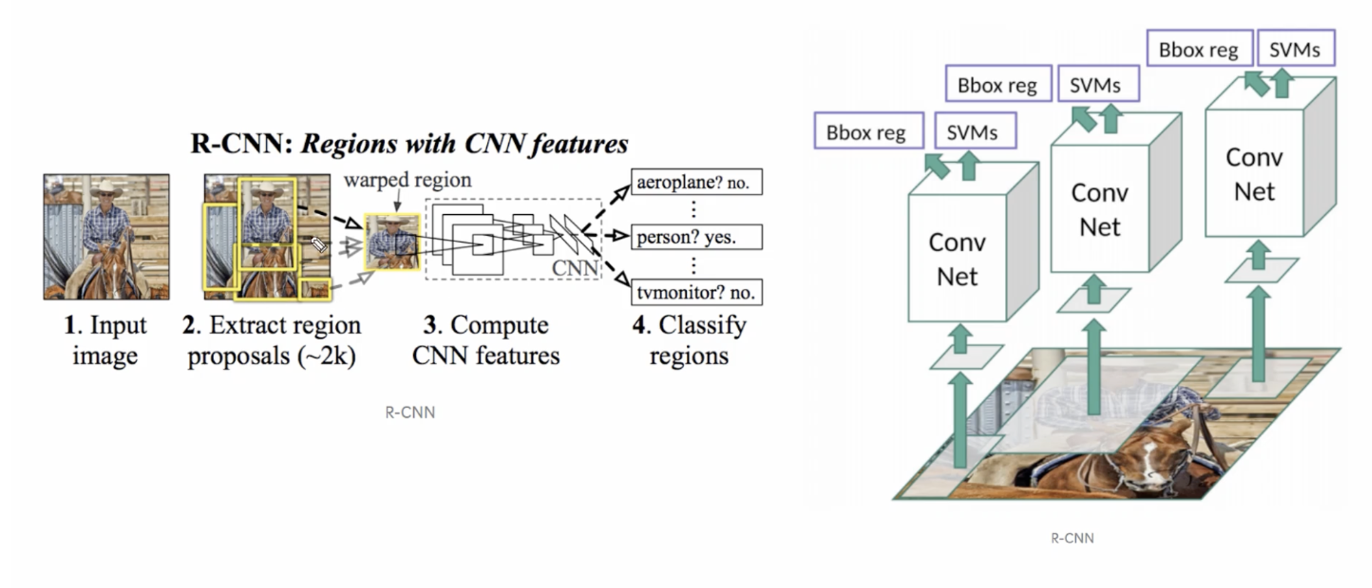
R-CNN (Regions with CNN)
Region Propsal 방식에 기반한 Object Detection - RCNN
RCNN 모델의 Classification Dense layer로 인해서 이미지 크기가 동일해야 하며, 이로 인해 2000개 Region Proposal로 예측된 영역의 이미지 사이즈를 동일하게 가짐
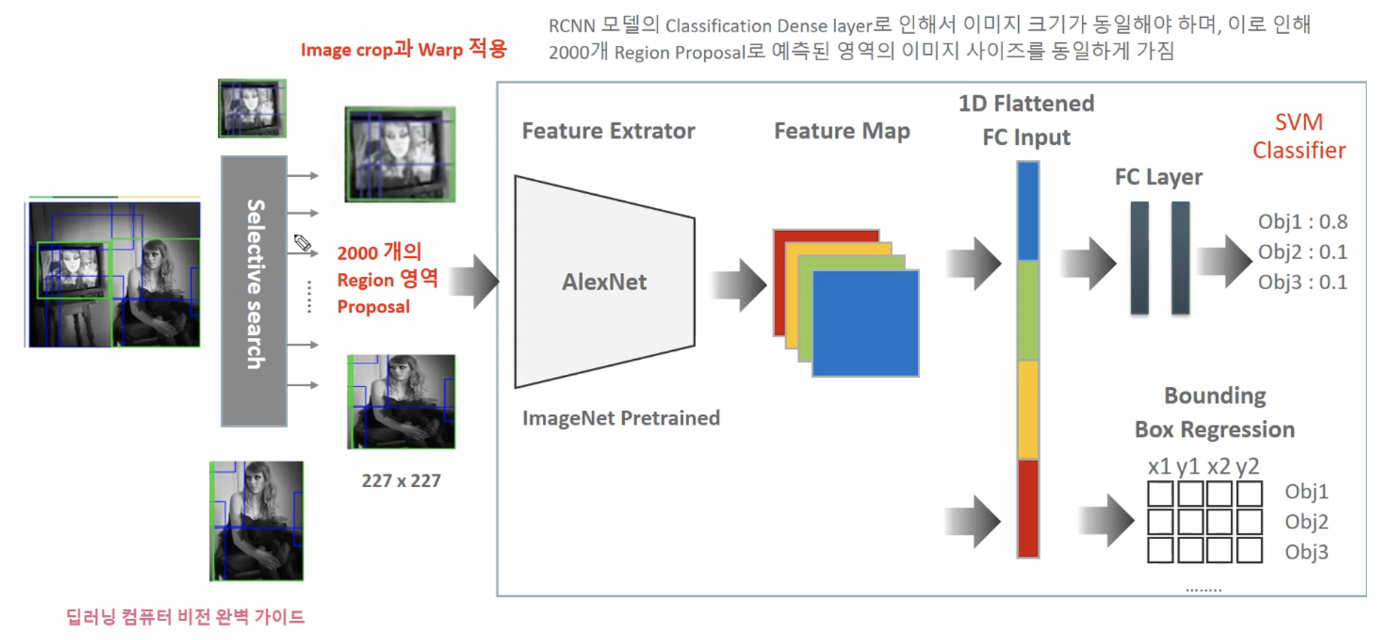
특이한 점은 보통 FC Layer(Fully Connected Layer) 다음에 Softmax를 사용해 Clssification하지만 R-CNN에서는 SVM Classifier을 사용한다.
R-CNN 개요
왜 Softmax가 아니라 SVM(Support Vector Machine)을 사용했나? → 이유는 모르지만 성능이 개선되서 사용.
RCNN Training - Classification
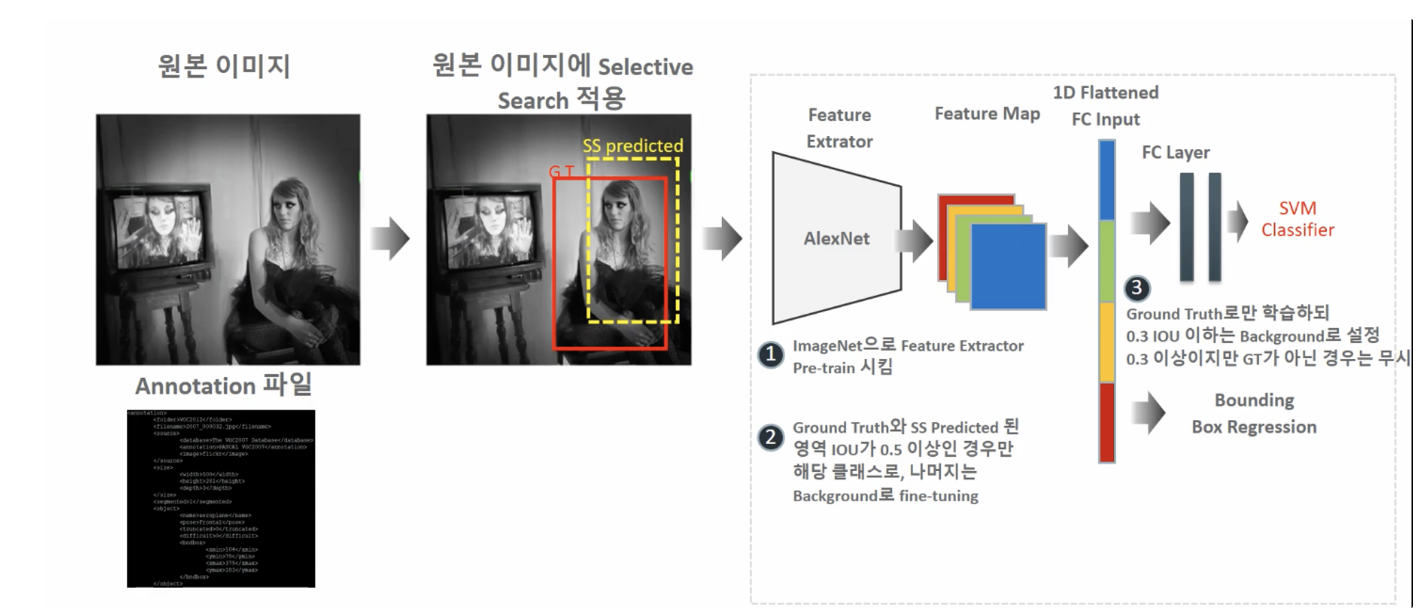
- ImageNet으로 Feature Extractor Pre-train시킴
- Ground Truth와 SS Predicted 된 영역 IOU가 0.5 이상인 경우만 해당 클래스로, 나머지는 Background로 fine-tuning
- Ground Truth로만 학습하되 0.3 IOU 이하는 Background로 설정 0.3 이상이지만 GT가 아닌 경우는 무시
Bounding Box Regression
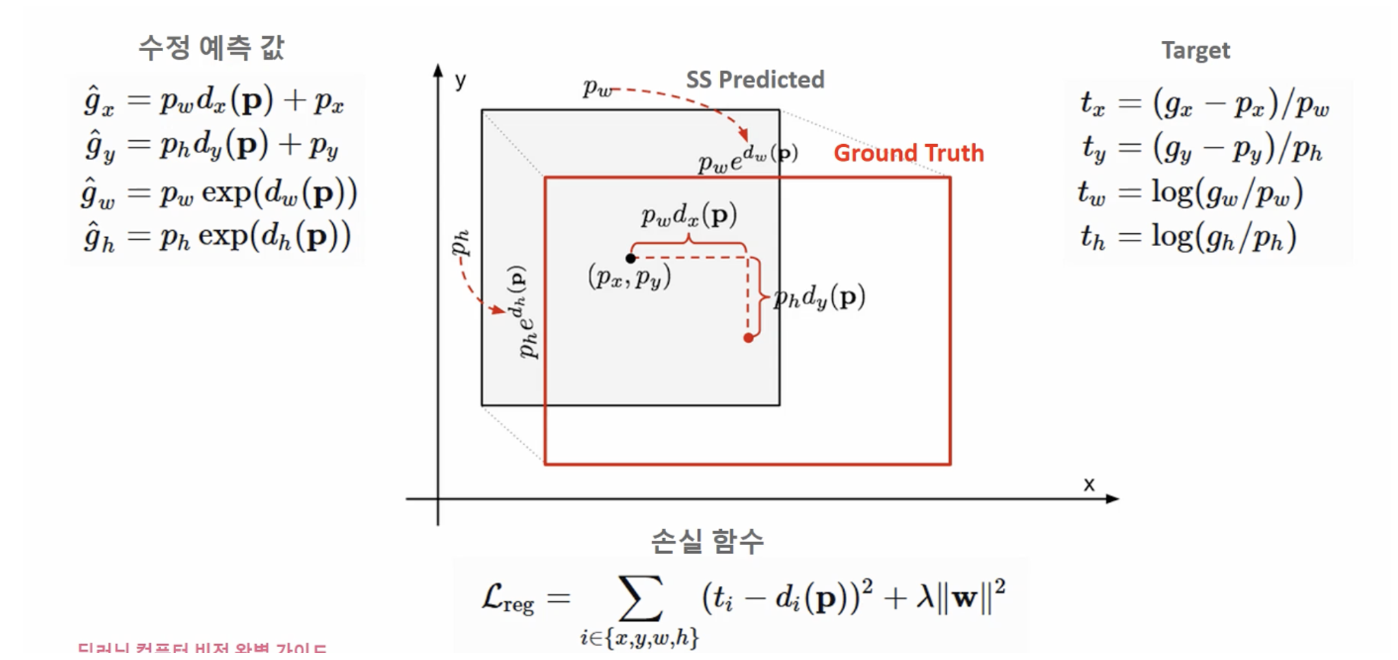
모델의 목표는 SS Predicted의 중심과 GT의 중심의 거리와 width를 최소로 만들도록 하는 것이다.
R-CNN 장단점
장점
- 높은 Detection 정확도
단점
- 너무 느린 Detection 시간과 복잡한 아키텍처 및 학습 프로세스
프로세스 과정
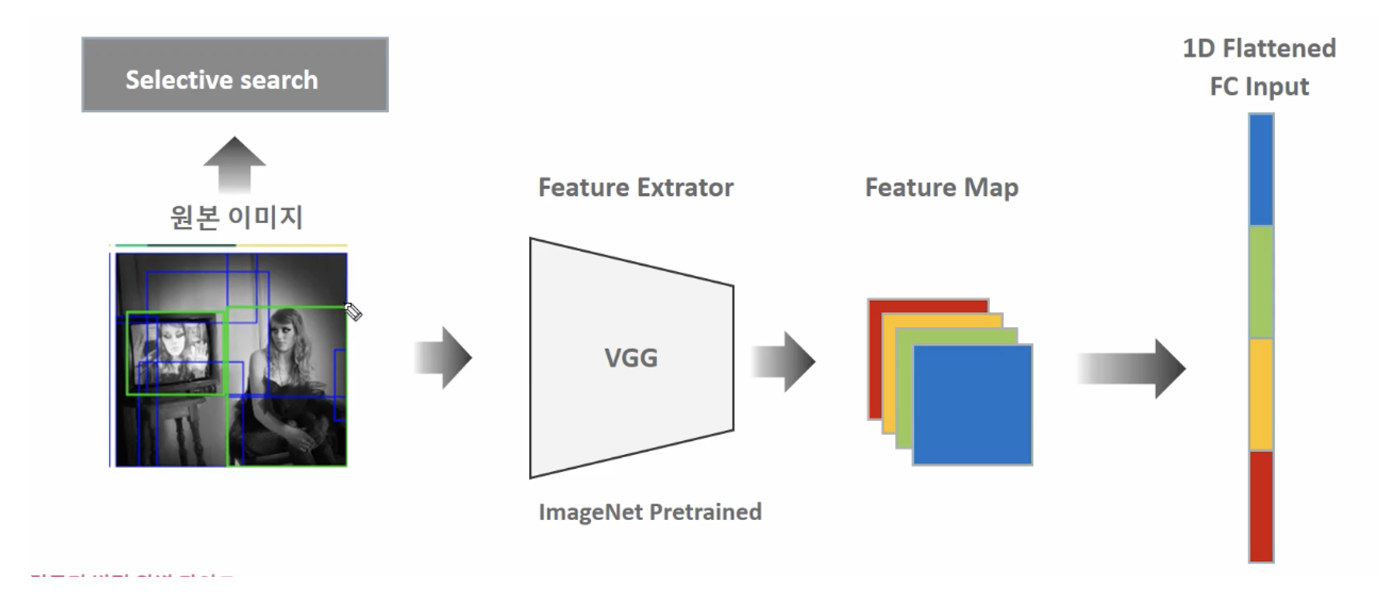
- 하나의 이미지마다 SS를 수행하여 2000개의 region 영역 이미지들 도출
- 개별 이미지별로 2000개씩 생성된 region 이미지를 CNN Feature map 생성
- 각기 따로 노는 구성 요소들, SS, CNN Feature Extractor, SVM과 Bounding box regressor로 구성되어 복잡한 프로세스를 거쳐서 학습 및 Object Detectio이 되어야 함 → 1장의 이미지를 Object Detection 하는데 약 50초 소요
R-CNN 개선 방안
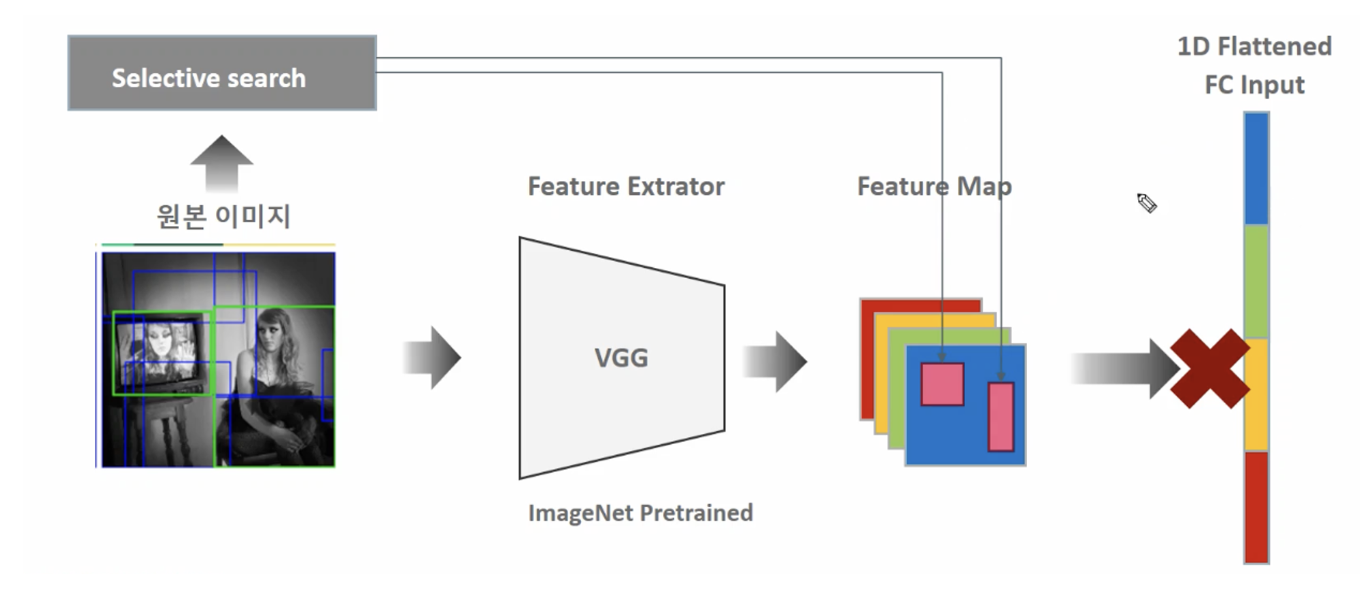
2000개의 Region Proposal 이미지를 CNN으로 Feature Extraction 하지 않고 원본 이미지만 CNN으로 Feature Map 생성 뒤에 원본 이미지의 Selective search로 추천된 영역의 이미지만 Feature Map으로 매핑하여 별도 추출
R-CNN 수행 시간 개선 방안 문제점
CNN은 서로 다른 사이즈의 Image를 수용하지 않는데, 가장 큰 이유는 Flatten Fully Connection Input의 크기가 고정이 되어야 하기 때문이다.
SPP(Spatial Pyramid Pooling) Net
SPP는 CNN Image Classification에서 서로 다른 이미지의 크기를 고정된 크기로 변환하는 기법으로 소개되었고, 오래전부터 컴퓨터 비전 영역에서 활용된 Spatial Pyramid Matching 기법에 근간을 둠.
SPM(Spatial Pyramid Matching) 개요
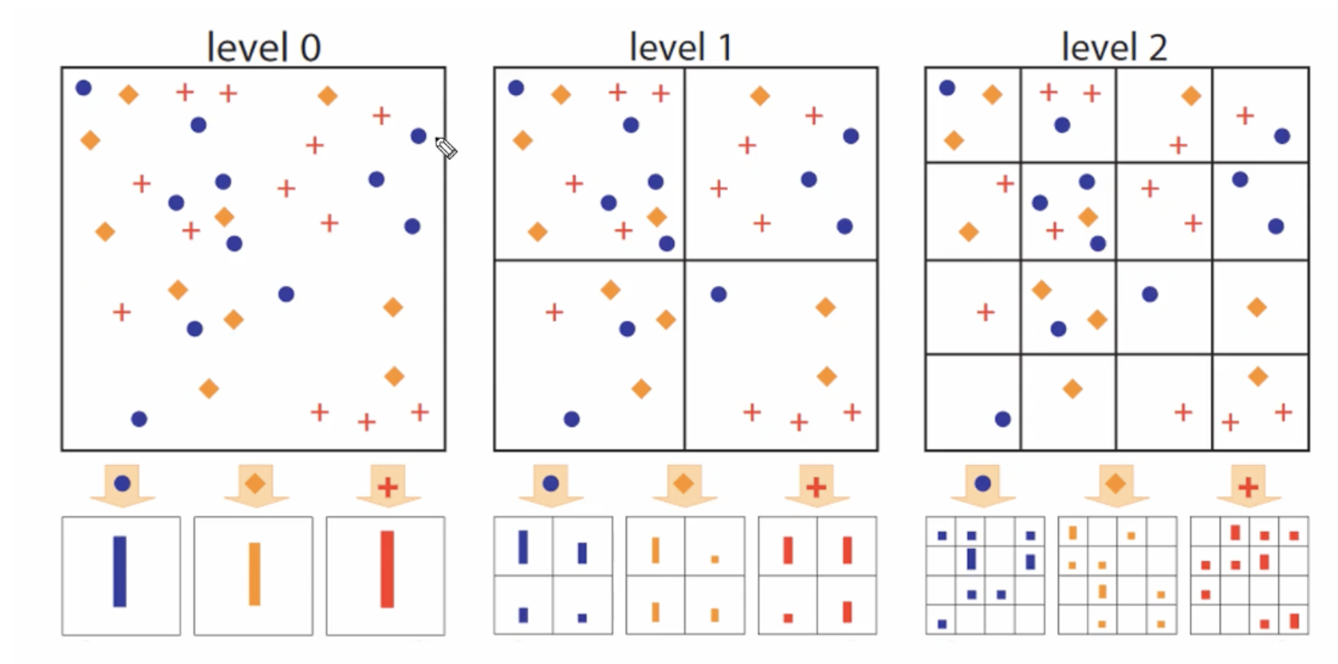
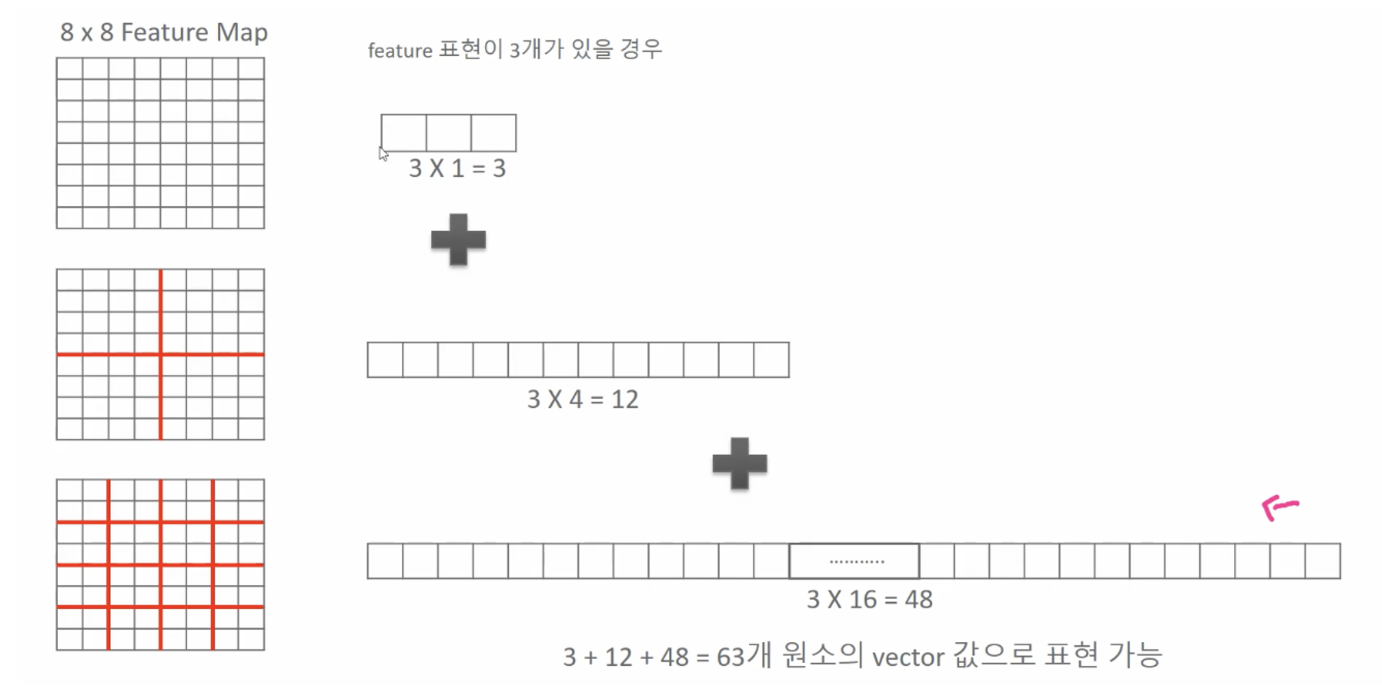
위치 정보를 감안해서 spatial한 공간 정보를 감안해서 개별 픽셀값에 대한 정보들을 히스토그램 레벨로 추출
SPM으로 서로 다른 크기의 Feature Map을 균일한 크기의 Vector 표현
SPP-Net을 RCNN에 적용
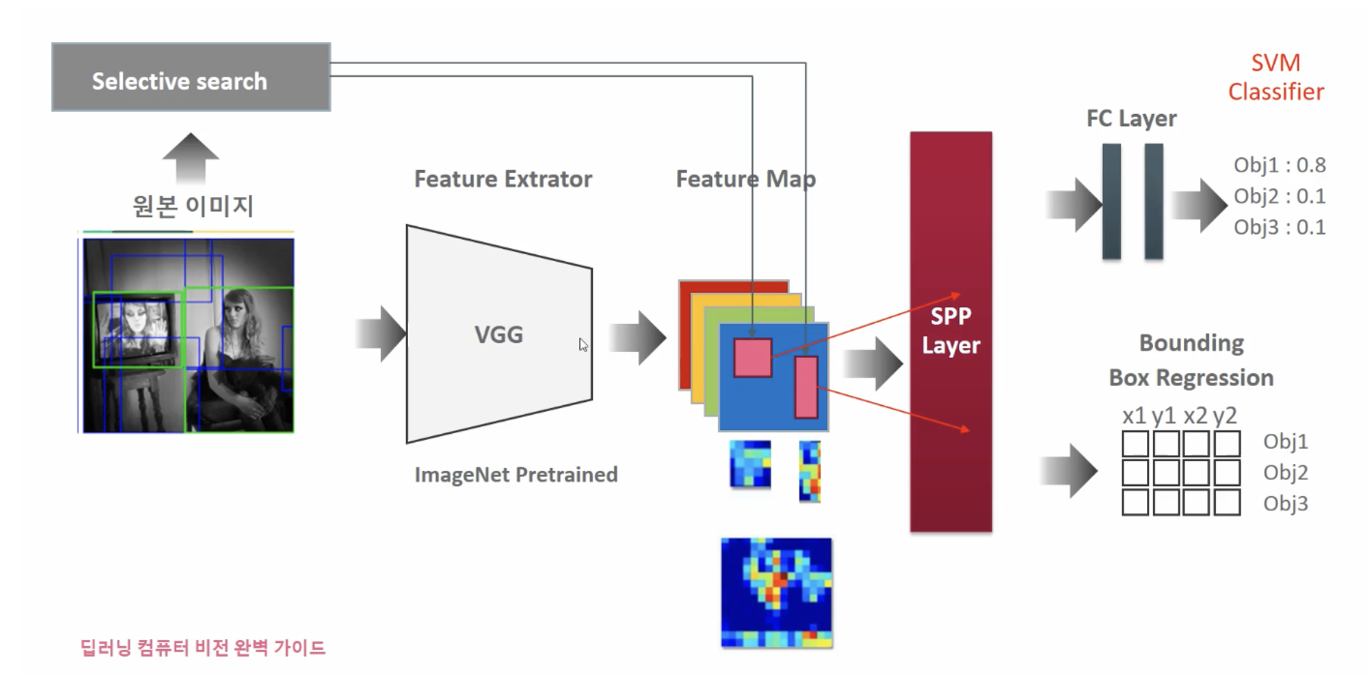
SPP-Net을 적용시킴으로써 수행시간을 줄일 수 있게 되었다.
