ML
1.Machine Learning Evaluation Tools

for skewed datasets, We need more evaluation techniques for learning model than accuracy. Confusion Matrix Precision and Recall > precision = TP /
2022년 9월 12일
2.Data Visualization Basic

histplot -> axes 객체displot -> figure객체x, y 둘 중 하나는 이산형 (문자형 가능)estimator로 mean, median, sum등 가능수평그래프도 가능hue로 groupbyx에 넣으면 수평, y에 넣으면 수직groupby하려면 x에
2022년 9월 12일
3.[추천 시스템] CF, CBF
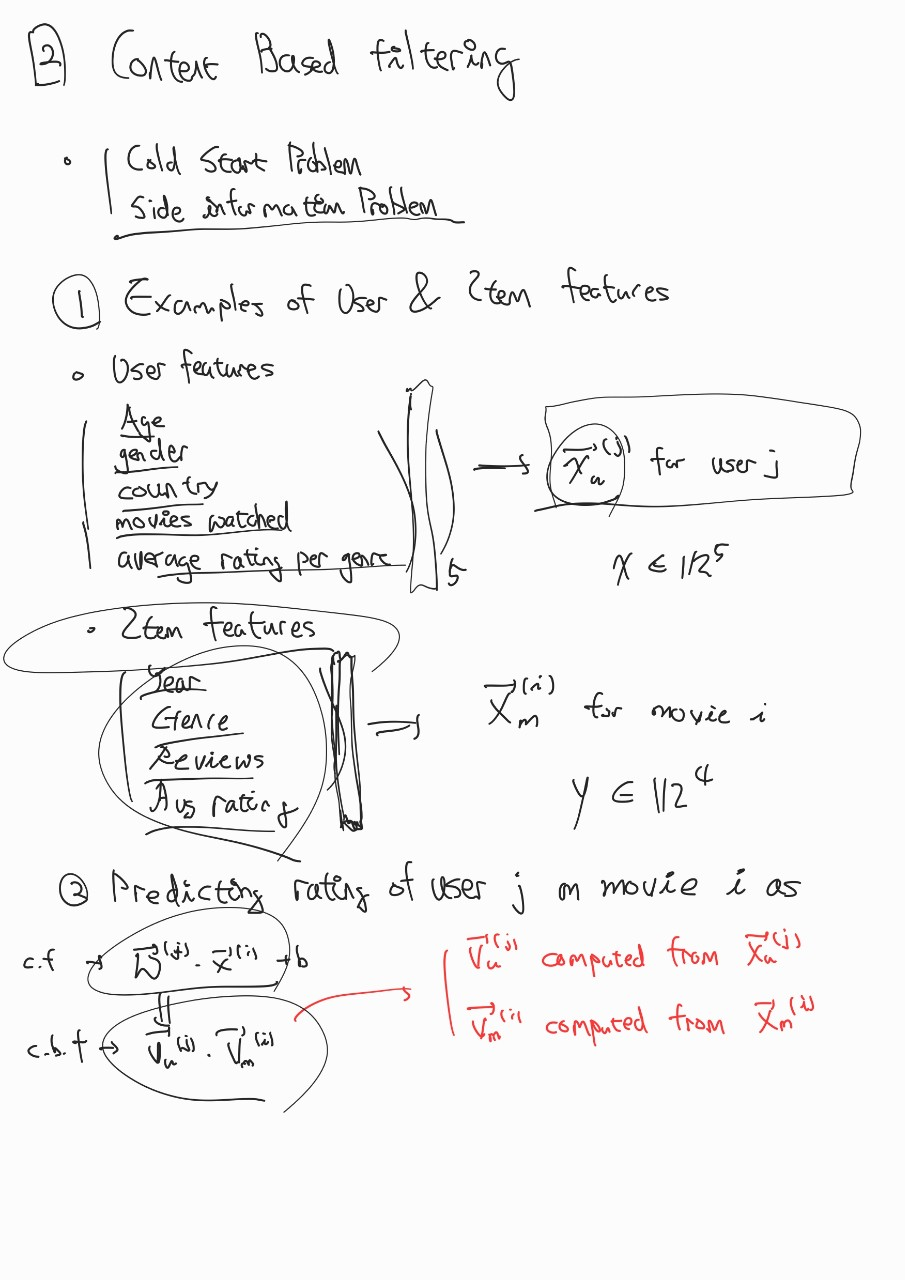
Content Based Filtering 1 > 1. 아이템의 피처들을 추출해서 벡터화한 후, 아이템 간의 유사도를 계산한다. 유사도 함수 Jaccard Similarity sim(A,B) = $\| r{A} \cap r{A} \| / \| r{A} \
2022년 10월 10일
4.[추천시스템] Matrix Factorization, Factorization Machine
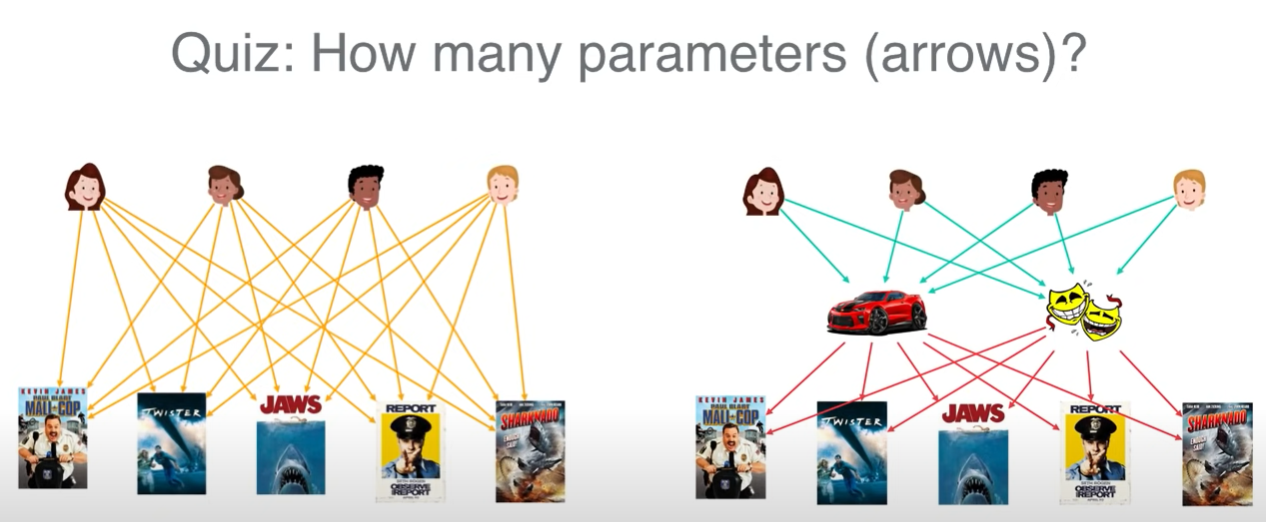
잠재 요인이 분명 있을 것이다. 무엇인진 알 수 없지만, 잠재 요인 (사진에서는 2개로 가정)에 대응되는 유저의 가중치, 그리고 영화의 특성 값을 찾아내는 것이 목적이다.특이값 분해를 이용하여 행렬을 분해하는 알고리즘이다. 하지만 이론적인 배경이 될 뿐 특이값 분해는
2022년 10월 13일