개요
강화학습과 다이내믹 프로그래밍의 차이는 강화학습은 환경의 모델을 몰라도 환경과 상호작용을 통해 최적 정책을 학습한다는 것이다.
에이전트는 환경과의 상호작용을 통해 주어진 정책에 대한 가치 함수를 학습할 수 있는데 이를 예측이라고 한다.
또한 가치함수를 토대로 정책을 끊임없이 발전시켜 나가서 최적 정책을 학습하려는 것이 제어이다.
예측에는 몬테카를로 예측과 시간차 예측이 있다.
제어에는 시간차 제어인 살사가 있다.
몬테카를로 예측
강화학습의 학습 방법
강화 학습은 환경의 모델 없이 환경이라는 시스템의 입력과 출력 사이의 관계를 학습한다.
강화 학습은 일단 해보고 자신을 평가하며 평가한 대로 자신을 업데이트하며 이 과정을 반복한다.
강화학습에서는 계산을 통해서 가치함수를 알아내는 것이 아니라 에이전트가 겪은 경험으로부터 가치함수를 업데이트 하는 것이다.
강화학습의 예측과 제어
다이내믹 프로그램에서 기존의 가치 함수는 기댓값을 통해 계산한다.
하지만 강화학습에서는 샘플링을 평균하여 가치 함수의 값을 추정한다.
몬테카를로 근사의 예시
원의 넓이를 구하는 방정식을 모른다면 몬테카를로 근사라는 방법을 사용할 수 있다.
몬테카를로라는 말은 '무작위로 무언가를 해본다' 는 의미로 생각하면 된다.
근사라는 것은 원래의 값을 모르지만 '샘플'을 통해 원래의 값에 대해 이럴 것이다라고 추정하는 것이다.

원의 넓이는 S(A)이고 종이의 넓이는 S(B)이다. 이때 S(B)는 이미 안다고 가정한다.
원이 그려진 종이 위에 보라색 점을 무작위로 계속 뿌린다.
그래서 전체 뿌린 점들 중에서 A에 들어가 있는 점의 비율을 구하면 이미 알고 있는 S(B)를 통해 S(A)의 값을 추정할 수 있다.
뿌린 점의 비율로 S(A)/S(B) 를 근사하는 것이다.
샘플링과 몬테카를로 예측
원의 넓이를 구하는 몬테카를로 근사에서 점 하나하나는 샘플이고 그 샘플들의 평균을 통해 원래 원의 넓이를 추정한다.
가치함수를 추정할 때는 에이전트가 한 번 환경에서 에피소드를 진행하는 것이 샘플링이다. 이 샘플링을 통해 얻은 샘플의 샘플의 평균으로 참 가치함수의 값을 추정한다.
벨만 기대 방정식을 계산하려면 조건이 필요하다. 바로 환경의 모델인 보상과 상태변환 확률을 알아야 하는 것이다.
몬테카를로 예측에서는 환경의 모델을 몰라도 여러 에피소드를 통해 평균을 통해 가치 함수를 추정한다.
위의 수식은 여러 번의 에피소드에서 s라는 상태를 방문해서 얻은 반환값들의 평균을 통해 참 가치함수를 추정하는 식이다.
N(s)는 상태 s를 여러 번의 에피소드 동안 방문한 횟수이다. G_i(s)는 그 상태를 방문한 i번째 에피소드에서 s의 반환값이다. s를 방문했던 에피소드에 대해 마침 상태까지의 반환 값을 평균내는 것이다.

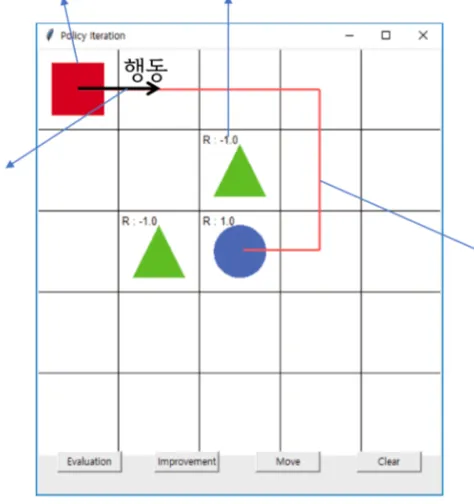
출처 : https://jang-inspiration.com/reinforcement-learning-6
가치함수 입장에서 업데이트를 통해 도달하려는 목표는 반환 값이다. 가치함수는 이 목표로 감으로써 자신을 업데이트하는데 한 번에 목표점으로 가는 것이 아니고 스텝사이즈를 곱한 만큼만 가는 것이다.
몬테카를로 예측에서 에이전트는 이 업데이트 식을 통해 에피소드 동안 경험했던 모든 상태에 대해 가치함수를 업데이트 한다.
어떠한 상태의 가치함수가 업데이트될수록 가치함수는 현재 정책에 대한 참 가치함수에 수렴해간다.
에이전트는 마침 상태에 갈 때까지 아무것도 하지 않는다. 마침 상태에 도착하면 에이전트는 지나온 모든 상태의 가치함수를 업데이트한다.
에피소드 동안 방문했던 모든 상태의 가치함수를 업데이트하면 에이전트는 다시 시작 상태에서부터 새로운 에피소드를 진행한다. 이러한 과정을 계속 반복하는 것이 몬테카를로 예측이다.
에이전트 생성
import numpy as np
import random
from collections import defaultdict
from environment import Env
# 몬테카를로 에이전트 (모든 에피소드 각각의 샘플로 부터 학습)
class MCAgent:
def __init__(self, actions):
self.width = 5
self.height = 5
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
self.samples = []
self.value_table = defaultdict(float)
# 메모리에 샘플을 추가
def save_sample(self, state, reward, done):
self.samples.append([state, reward, done])
# 모든 에피소드에서 에이전트가 방문한 상태의 큐 함수를 업데이트
def update(self):
G_t = 0
visit_state = []
for reward in reversed(self.samples):
state = str(reward[0])
if state not in visit_state:
visit_state.append(state)
G_t = reward[1] + self.discount_factor * G_t
value = self.value_table[state]
self.value_table[state] = (value + self.learning_rate * (G_t - value))
# 큐 함수에 따라서 행동을 반환
# 입실론 탐욕 정책에 따라서 행동을 반환
def get_action(self, state):
if np.random.rand() < self.epsilon:
# 랜덤 행동
action = np.random.choice(self.actions)
else:
# 위 함수에 따른 행동
next_state = self.possible_next_state(state)
action = self.arg_max(next_state)
return int(action)
# 후보가 여럿이면 arg_max를 계산하고 무작위로 하나를 반환
@staticmethod
def arg_max(next_state):
max_index_list = []
max_value = next_state[0]
for index, value in enumerate(next_state):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
if value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
# 가능한 다음 모든 상태들을 반환
def possible_next_state(self, state):
col, row = state
next_state = [0.0] * 4
if row != 0:
next_state[0] = self.value_table[str([col, row -1])]
else:
next_state[0] = self.value_table[str(state)]
if row != self.height -1:
next_state[1] = self.value_table[str([col, row+1])]
else:
next_state[1] = self.value_table[str(state)]
if col != 0:
next_state[2] = self.value_table[str([col-1, row])]
else:
next_state[2] = self.value_table[str(state)]
if col != self.width - 1:
next_state[3] = self.value_table[str([col + 1, row])]
else:
next_state[3] = self.value_table[str(state)]
return next_state
# 메인 함수
if __name__ == "__main__":
env = Env()
agent = MCAgent(actions=list(range(env.n_actions)))
for episode in range(1000):
state = env.reset()
action = agent.get_action(state)
while True:
env.render()
next_state, reward, done = env.step(action)
agent.save_sample(next_state, reward, done)
action = agent.get_action(next_state)
# 에피소드가 완료됬을 때, 큐 함수 업데이트
if done:
print('episode : ', episode)
agent.update()
agent.samples.clear()
break
환경설정
import time
import numpy as np
import tkinter as tk
from PIL import ImageTk, Image
np.random.seed(1)
PhotoImage = ImageTk.PhotoImage
UNIT = 100 # 픽셀 수
HEIGHT = 5 # 그리드 월드 세로
WIDTH = 5 # 그리드 월드 가로
class Env(tk.Tk):
def __init__(self):
super(Env, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('monte carlo')
self.geometry('{0}x{1}'.format(HEIGHT * UNIT, HEIGHT * UNIT))
self.shapes = self.load_images()
self.canvas = self._build_canvas()
self.texts = []
def _build_canvas(self):
canvas = tk.Canvas(self, bg='white',
height=HEIGHT * UNIT,
width=WIDTH * UNIT)
# 그리드 생성
for c in range(0, WIDTH * UNIT, UNIT): # 0~400 by 80
x0, y0, x1, y1 = c, 0, c, HEIGHT * UNIT
canvas.create_line(x0, y0, x1, y1)
for r in range(0, HEIGHT * UNIT, UNIT): # 0~400 by 80
x0, y0, x1, y1 = 0, r, HEIGHT * UNIT, r
canvas.create_line(x0, y0, x1, y1)
# 캔버스에 이미지 추가
self.rectangle = canvas.create_image(50, 50, image=self.shapes[0])
self.triangle1 = canvas.create_image(250, 150, image=self.shapes[1])
self.triangle2 = canvas.create_image(150, 250, image=self.shapes[1])
self.circle = canvas.create_image(250, 250, image=self.shapes[2])
canvas.pack()
return canvas
def load_images(self):
rectangle = PhotoImage(
Image.open("../img/rectangle.png").resize((65, 65)))
triangle = PhotoImage(
Image.open("../img/triangle.png").resize((65, 65)))
circle = PhotoImage(
Image.open("../img/circle.png").resize((65, 65)))
return rectangle, triangle, circle
@staticmethod
def coords_to_state(coords):
x = int((coords[0] - 50) / 100)
y = int((coords[1] - 50) / 100)
return [x, y]
def reset(self):
self.update()
time.sleep(0.5)
x, y = self.canvas.coords(self.rectangle)
self.canvas.move(self.rectangle, UNIT / 2 - x, UNIT / 2 - y)
return self.coords_to_state(self.canvas.coords(self.rectangle))
def step(self, action):
state = self.canvas.coords(self.rectangle)
base_action = np.array([0, 0])
self.render()
if action == 0: # 상
if state[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # 하
if state[1] < (HEIGHT - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # 좌
if state[0] > UNIT:
base_action[0] -= UNIT
elif action == 3: # 우
if state[0] < (WIDTH - 1) * UNIT:
base_action[0] += UNIT
# 에이전트 이동
self.canvas.move(self.rectangle, base_action[0], base_action[1])
# 에이전트(빨간 네모)를 가장 상위로 배치
self.canvas.tag_raise(self.rectangle)
next_state = self.canvas.coords(self.rectangle)
# 보상 함수
if next_state == self.canvas.coords(self.circle):
reward = 100
done = True
elif next_state in [self.canvas.coords(self.triangle1),
self.canvas.coords(self.triangle2)]:
reward = -100
done = True
else:
reward = 0
done = False
next_state = self.coords_to_state(next_state)
return next_state, reward, done
def render(self):
time.sleep(0.03)
self.update()
시간차 예측
강화 학습에서 가장 중요한 아이디어 중 하나가 바로 시간차이다.
몬테카를로 에측의 단점은 실시간이 아니라는 점이다. 가치함수를 업데이트하기 위해서는 에피소드가 끝날 때까지 기다려야 한다. 또한 에피소드의 끝이 없거나 에피소드의 길이가 긴 경우에는 몬테카를로 예측은 적합하지 않다.
몬테카를로 예측에서와 같이 에피소드마다가 아니라 타임스텝마다 가치함수를 업데이트하는 방법이 시간차 예측이다.

출처 : https://jang-inspiration.com/reinforcement-learning-6
살사
큐함수에 따라서 행동을 선택하려면 에이전트는 가치함수가 아닌 큐함수의 정보를 알아야 하므로 업데이트 대상은 가치함수가 아닌 큐함수가 되어야 한다. 때문에 시간차 제어 의 식은 다음과 같다
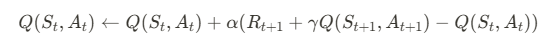
시간차 제어에서 큐함수를 업데이트 하려면 샘플이 필요하다. 시간차 제어에서는

샘플의 형태 때문에 시간차 제어를 다른말로 살사(SARSA)라고 부른다. 살사는 현재 가지고 있는 큐함수를 토대로 샘플을 탐욕 정책으로 모으고, 그 샘플로 방문한 큐함수를 업데이트하는 과정을 반복하는 것이다.

출처: https://jang-inspiration.com/sarsa-qlearning
import numpy as np
import random
from collections import defaultdict
from environment import Env
class SARSAgent:
def __init__(self, actions):
self.actions = actions
self.step_size = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
# 0을 초기값으로 가지는 큐함수 테이블 생성
self.q_table = defaultdict(lambda : [0.0, 0.0, 0.0, 0.0])
# <s, a, r, s', a'>의 샘플로부터 큐함수를 업데이트
def learn(self, state, action, reward, next_state, next_action):
state, next_state = str(state), str(next_state)
current_q = self.q_table[state][action]
next_state_q = self.q_table[next_state][next_action]
td = reward + self.discount_factor * next_state_q - current_q
new_q = current_q + self.step_size * td
self.q_table[state][action] = new_q
# 입실론 탐욕 정책에 따라서 행동을 반환
def get_action(self, state):
if np.random.rand() < self.epsilon:
# 무작위 행동 반환
action = np.random.choice(self.actions)
else:
# 큐함수에 따른 행동 반환
state = str(state)
q_list = self.q_table[state]
action = arg_max(q_list)
return action
# 큐함수의 값에 따라 최적의 행동을 반환
def arg_max(q_list):
max_idx_list = np.argwhere(q_list == np.amax(q_list))
max_idx_list = max_idx_list.flatten().tolist()
return random.choice(max_idx_list)
if __name__ == "__main__":
env = Env()
agent = SARSAgent(actions=list(range(env.n_actions)))
for episode in range(1000):
state = env.reset()
action = agent.get_action(state)
while True:
env.render()
next_state, reward, done = env.step(action)
next_action = agent.get_action(next_state)
# <s, a, r, s' ,a'> 로 큐함수를 업데이트
agent.learn(state, action, reward, next_state, next_action)
state = next_state
action = next_action
env.print_value_all(agent.q_table)
if done:
break
init 을 통해 학습에 필요한 변수들을 할당해 주었다. 추가로 SARSAgent 에 어떤 함수가 필요한지를 알기 위해서는 에이전트가 환경과 어떻게 상호작용하고 학습하는지를 알아야 한다. 에이전트는 다음과 같은 순서로 상호작용한다.
-
현재 상태에서 ϵ-탐욕 정책에 따라 행동을 선택
-
선택한 행동으로 환경에서 한 타임스텝을 진행
-
환경으로부터 보상과 다음 상태를 받음
-
다음 상태에서 ϵ-탐욕 정책에 따라 다음 행동을 선택
-
(s,a,r,s',a')을 통해 큐함수 업데이트
get_action 함수는 ϵ-탐욕 정책에 따라 state를 입력으로 받아 action을 반환한다. q_table 에 따라서 탐욕적으로 행동을 선택하며 이때 의 확률을 반영하여 무작위 행동을 반환하기도 한다.
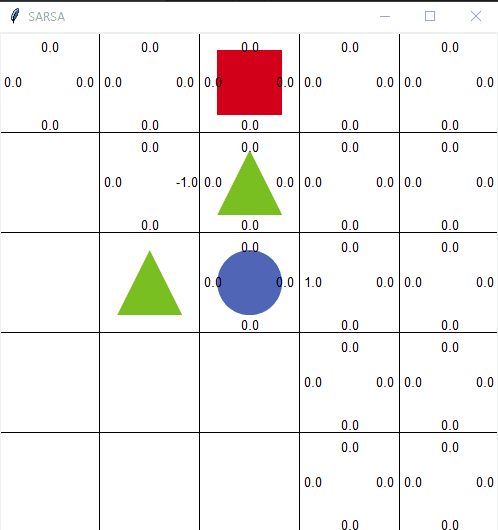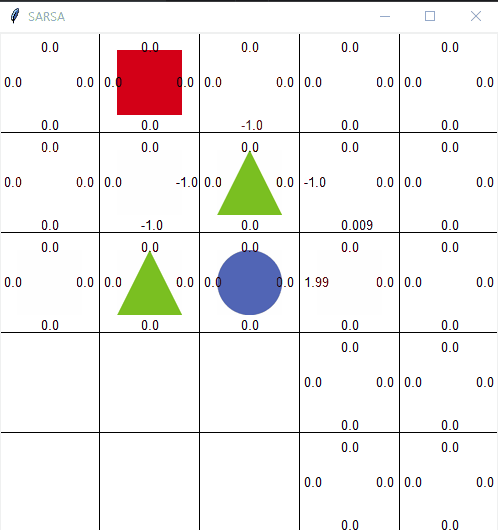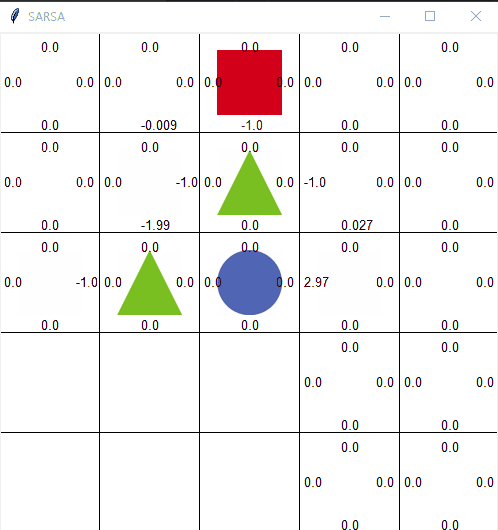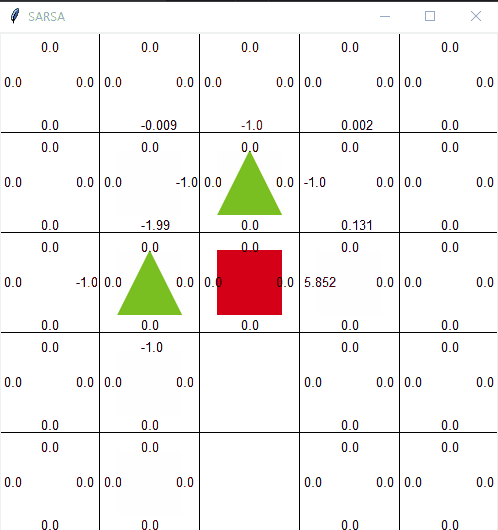
살사의 한계
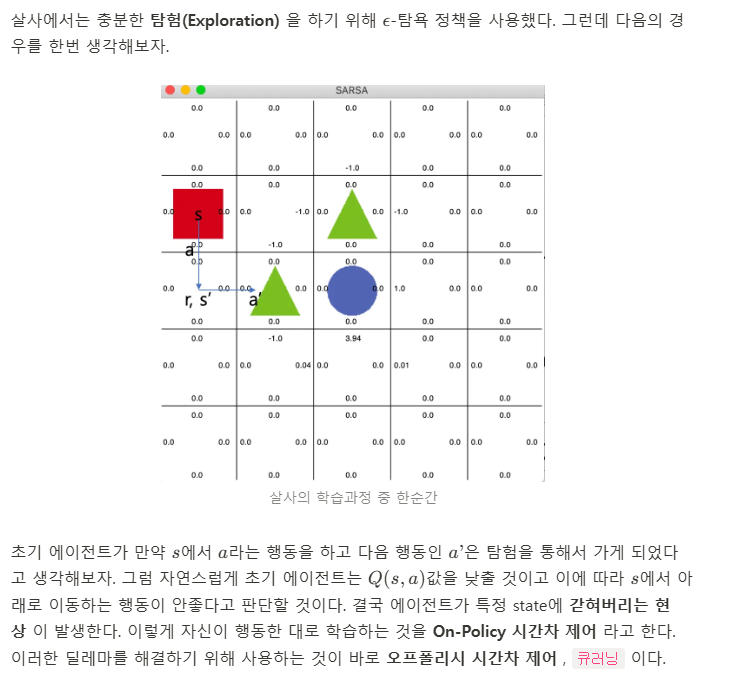
출처: https://jang-inspiration.com/sarsa-qlearning
큐러닝
큐러닝의 아이디어는 간단하다. 오프폴리시 의 말 그대로 현재 행동하는 정책과는 독립적으로 학습한다는 것이다. 즉, 행동하는 정책과 학습하는 정책을 따로 분리 한다. 이게 무슨 말일까? 예시로서 이해해보자.
에이전트가 현재 상황 s에서 행동 a 를 ϵ-탐욕 정책에 따라 선택했다고 하자. 그러면 에이전트는 환경으로부터 보상 r을 받고 다음 상태 s'을 받는다. 여기까지는 살사와 동일하다. 하지만 살사 에서는 다음 상태에서 또다시 ϵ-탐욕 정책에 따라 다음 행동을 선택한 후에 그것을 학습에 샘플로 사용한다. 큐러닝 에서는 에이전트가 다음 상태 s'을 알게 되면 그 상태(s')에서 가장 큰 큐함수를 현재 큐함수의 업데이트에 사용한다. 살사의 학습과정과 다르게 큐러닝은 아래와 같이 학습한다.
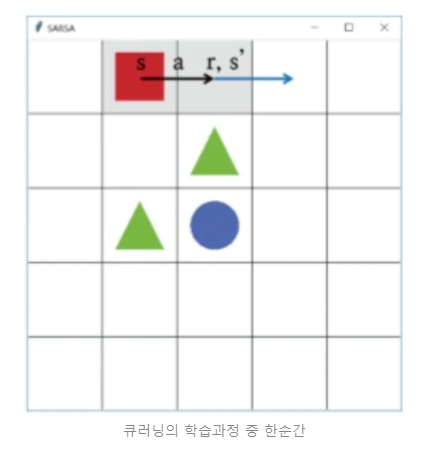

출처: https://jang-inspiration.com/sarsa-qlearning
import numpy as np
import random
from environment import Env
from collections import defaultdict
class QLearningAgent:
def __init__(self, actions):
self.actions = actions
self.step_size = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
self.q_table = defaultdict(lambda : [0.0, 0.0, 0.0, 0.0])
def learn(self, state, action, reward, next_state):
state, next_state = str(state), str(next_state)
q_1 = self.q_table[state][action]
# 벨만 최적 방정식을 사용한 큐함수의 업데이트
q_2 = reward + self.discount_factor * max(self.q_table[next_state])
self.q_table[state][action] += self.step_size * (q_2 - q_1)
def get_action(self, state):
if np.random.rand() < self.epsilon:
action = np.random.choice(self.actions)
else:
# 큐함수에 따른 행동 반환
state = str(state)
q_list = self.q_table[state]
action = arg_max(q_list)
return action
def arg_max(q_list):
max_idx_list = np.argwhere(q_list == np.amax(q_list))
max_idx_list = max_idx_list.flatten().tolist()
return random.choice(max_idx_list)
if __name__ == "__main__":
env = Env()
agent = QLearningAgent(actions=list(range(env.n_actions)))
for episode in range(1000):
state = env.reset()
action = agent.get_action(state)
while True:
env.render()
action = agent.get_action(state)
next_state, reward, done = env.step(action)
agent.learn(state, action, reward, next_state)
state = next_state
env.print_value_all(agent.q_table)
if done:
break
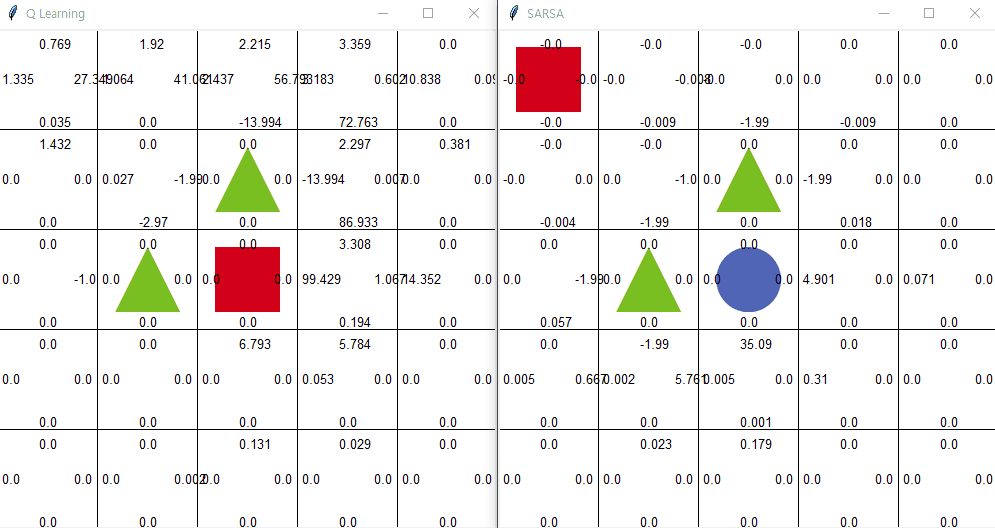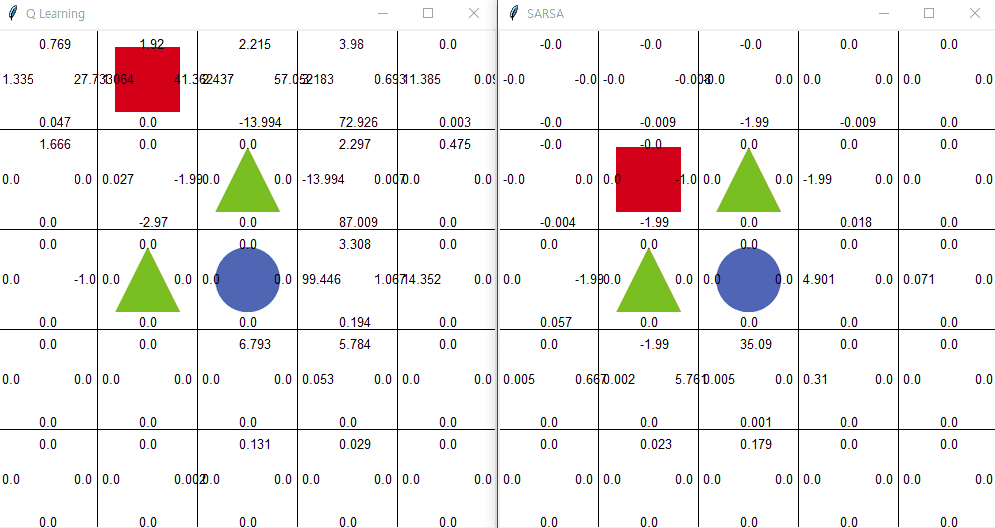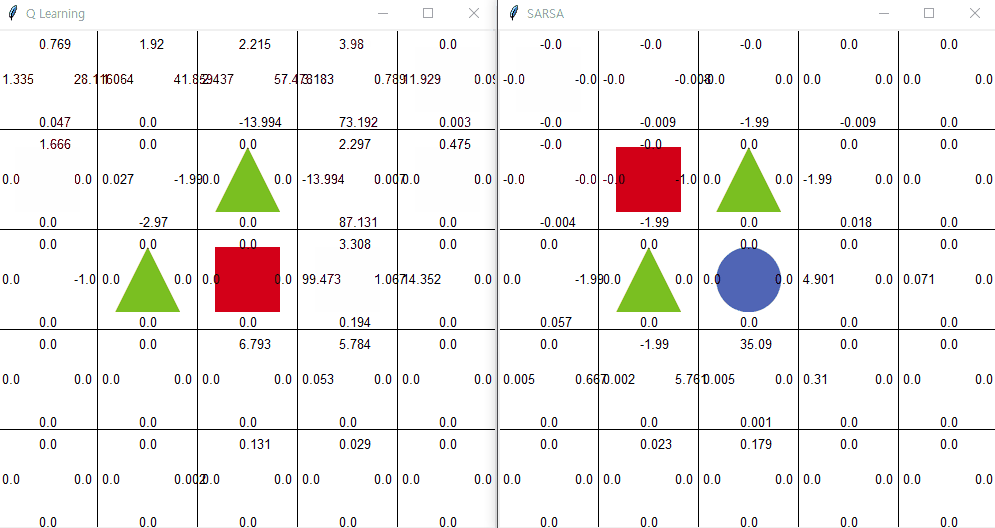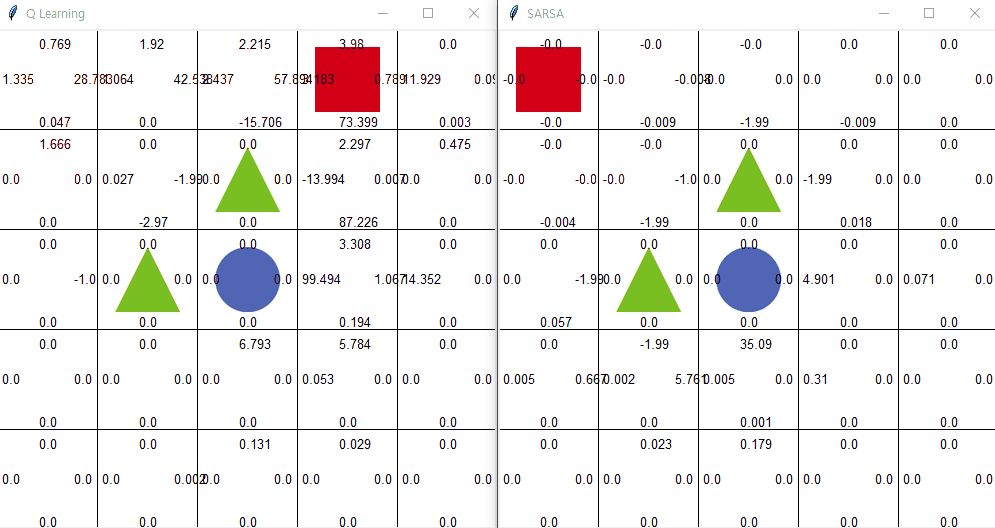
큐러닝 좌측 | 살사 우측

