생성적 적대 신경망
생성적 적대 신경망(GAN, Generative Adversarial network)
-
생성자 : 랜덤한 분포(일반적으로 가우시안 분포)를 입력으로 받고 이미지와 같은 데이터를 출력
-
판별자 : 생성자에서 얻은 가짜 이미지나 훈련 세터으세ㅓ 추출한 진짜 이미지를 입력으로 받아 입력된 이미지가 가짜인지 진짜인지 구분
intuition
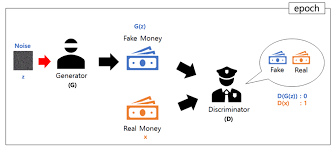
출처 : https://wikidocs.net/146217
위 그림은 GAN을 설명할 때 가장 많이 나오는 그림인데요, 이는 처음 GAN을 제시한 Ian goodfellow 가 GAN을 위조지폐범과 경찰에 빗대어 설명했기 때문입니다. 위조지폐범은 최대한 진짜같은 지폐를 만들어 경찰을 속이고, 경찰은 위조지폐범이 만들어낸 지폐와 진짜 지폐를 대조하면서 둘을 구분할 수 있는 차이점을 계속해서 찾아내게 됩니다. 이 과정에서 위조지폐범은 점점 더 정교한 지폐를 만들어 경찰을 속이기 위해 노력하고 경찰은 완벽히 판별하기 위해 더 노력하게 됩니다. 서로 경쟁적인 학습이 계속되다보면, 어느순간 경찰이 진짜지폐와 구분할 수 없을 정도로 비슷한 지폐를 만들 수 있게 될 것입니다.
GAN의 기본철학을 이해해보자면 , 주어진 문제는, "복잡한 고차원의 training distribution에서 sampling을 하고싶다." 라면 이를 해결하기 위해 , simple distribution(e.g. random noise) 를 샘플링 해서, Training distribution 을 따르는 Transformation을 시킬 수 있는 파라미터를 학습하자! 는 전략을 취하는 것입니다.
Generator and discriminator
GAN에는 위조지폐범에 해당하는 Generator(G) 와 경찰에 해당하는 Discriminator(D) 가 존재합니다.
Generator는 real data의 distribution을 학습해 fake 데이터를 만드는 일을 합니다.
→ 최종적으로 이를 Discriminator가 최대한 헷갈리게 하는 것을 목표로 합니다.
Discriminator는 smaple이 realdata(training)인지 아닌지를 구분합니다.
→ 최종적으로 Fake 이미지를 최대한 잘 판별하는 것 을 목표로 합니다.
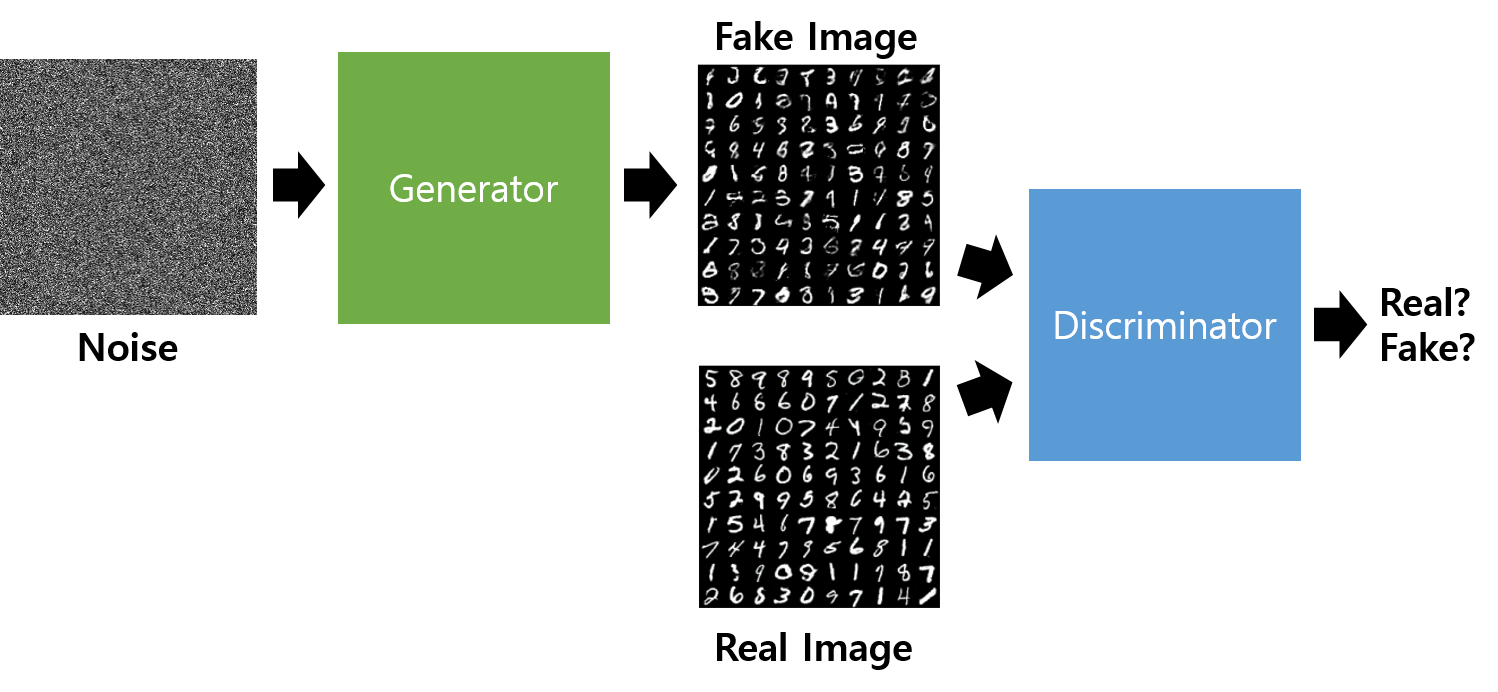
출처 : https://wikidocs.net/146217
Objective function of GAN
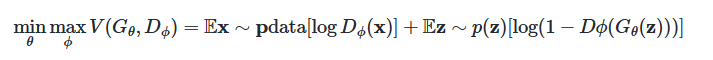
GAN의 objective function입니다.
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
epochs = 30
batch_size = 100
# CUDA 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
trainset = dset.FashionMNIST(root = 'FashionMNIST_data/',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,),(0.5,))
]))
train_loader = DataLoader(dataset = trainset,
batch_size=batch_size,
shuffle=True)
Generator = nn.Sequential(
nn.Linear(64,256),
nn.ReLU(),
nn.Linear(256,256),
nn.ReLU(),
nn.Linear(256,784),
nn.Tanh()
).to(device)
Discriminator = nn.Sequential(
nn.Linear(784,256),
nn.LeakyReLU(0.2),
nn.Linear(256,256),
nn.LeakyReLU(0.2),
nn.Linear(256,1),
nn.Sigmoid()
).to(device)
loss_func = nn.BCELoss()
d_optimizer = optim.Adam(Discriminator.parameters(), lr=0.0002)
g_optimizer = optim.Adam(Generator.parameters(), lr=0.0002)
for epoch in range(epochs):
for (image, _) in train_loader:
image = image.view(batch_size, -1).to(device)
real_label = torch.ones(batch_size, 1).to(device)
fake_label = torch.zeros(batch_size, 1).to(device)
outputs = Discriminator(image)
d_loss_real = loss_func(outputs, real_label)
z = torch.randn(batch_size, 64).to(device)
fake_images = Generator(z)
outputs = Discriminator(fake_images)
d_loss_fake = loss_func(outputs, fake_label)
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
fake_images = Generator(z)
outputs = Discriminator(fake_images)
g_loss = loss_func(outputs, real_label)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
print(f'epoch:{epoch+1}, d_loss:{d_loss.item():.4f}, g_loss{g_loss.item():.4f}')
z = torch.randn(batch_size, 64).to(device)
fake_images = Generator(z).cpu()
import numpy as np
for i in range(3):
plt.subplot(1, 3, i + 1)
fake_image_img = np.reshape(fake_images.data.numpy()[i],(28,28))
plt.imshow(fake_image_img, cmap='gray')
plt.show()
epoch:1, d_loss:0.0429, g_loss4.7057
epoch:2, d_loss:0.0385, g_loss4.9938
epoch:3, d_loss:0.0203, g_loss7.8400
epoch:4, d_loss:0.0748, g_loss4.8845
epoch:5, d_loss:0.0554, g_loss5.8406
epoch:6, d_loss:0.0768, g_loss6.1372
epoch:7, d_loss:0.1630, g_loss5.1263
epoch:8, d_loss:0.1269, g_loss3.2783
epoch:9, d_loss:0.1769, g_loss5.7192
epoch:10, d_loss:0.1459, g_loss3.9362
epoch:11, d_loss:0.2454, g_loss4.5920
epoch:12, d_loss:0.2950, g_loss5.5559
epoch:13, d_loss:0.2527, g_loss2.9671
epoch:14, d_loss:0.3562, g_loss4.1084
epoch:15, d_loss:0.3815, g_loss4.6581
epoch:16, d_loss:0.5482, g_loss4.4181
epoch:17, d_loss:0.5106, g_loss4.0508
epoch:18, d_loss:0.4269, g_loss3.0310
epoch:19, d_loss:0.6599, g_loss3.4177
epoch:20, d_loss:0.3557, g_loss3.1786
epoch:21, d_loss:0.3420, g_loss3.5643
epoch:22, d_loss:0.3114, g_loss3.5947
epoch:23, d_loss:0.3338, g_loss3.4016
epoch:24, d_loss:0.3268, g_loss3.8578
epoch:25, d_loss:0.7407, g_loss2.5798
epoch:26, d_loss:0.5078, g_loss3.3556
epoch:27, d_loss:0.5675, g_loss3.6473
epoch:28, d_loss:0.6642, g_loss4.1832
epoch:29, d_loss:0.4217, g_loss2.8065
epoch:30, d_loss:0.5051, g_loss3.0436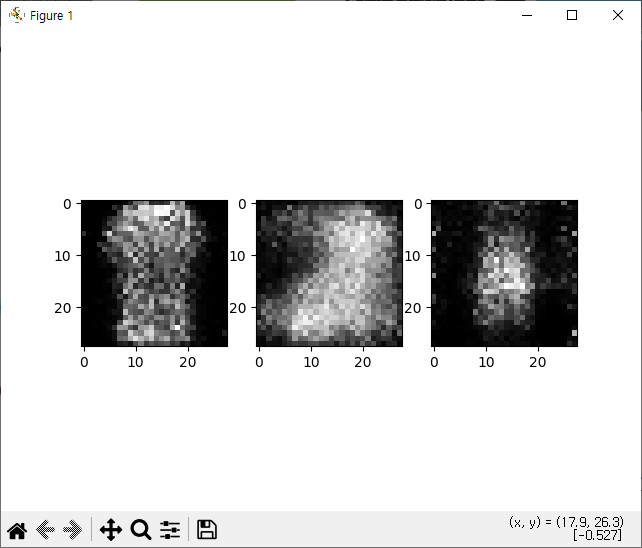
GAN Reference 및 추천자료
https://arxiv.org/pdf/1406.2661
GAN 예제
import torch.nn as nn
import torch.utils.data
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from PIL import Image, ImageFont, ImageDraw
import os
# 하이퍼파라미터 설정
num_epoch = 200 # 학습 횟수
batch_size = 100 # 배치 크기
learning_rate = 0.0002 # 학습률
num_channel = 1 # 입력 채널 수 (MNIST는 흑백 1채널)
noise_size = 100 # 생성기의 입력 노이즈 크기
hidden_size1 = 256 # 첫 번째 은닉층 크기
hidden_size2 = 512 # 두 번째 은닉층 크기
hidden_size3 = 1024 # 세 번째 은닉층 크기
condition_size = 10 # 조건(클래스 레이블) 크기 (0~9까지 10개)
dir_name = 'CGAN_results'
# 결과 저장 폴더 생성
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 생성기 정의
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(noise_size + condition_size, hidden_size1)
self.fc2 = nn.Linear(hidden_size1, hidden_size2)
self.fc3 = nn.Linear(hidden_size2, hidden_size3)
self.fc4 = nn.Linear(hidden_size3, 784) # MNIST 28x28 이미지를 펼친 크기
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, x):
out = self.relu(self.fc1(x))
out = self.relu(self.fc2(out))
out = self.relu(self.fc3(out))
y = self.tanh(self.fc4(out)) # MNIST는 -1~1 범위로 정규화됨
return y
# 판별기 정의
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784 + condition_size, hidden_size3)
self.fc2 = nn.Linear(hidden_size3, hidden_size2)
self.fc3 = nn.Linear(hidden_size2, hidden_size1)
self.fc4 = nn.Linear(hidden_size1, 1) # 이진 분류 (진짜/가짜)
self.leaky_relu = nn.LeakyReLU(0.2)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.leaky_relu(self.fc1(x))
out = self.leaky_relu(self.fc2(out))
out = self.leaky_relu(self.fc3(out))
y = self.sigmoid(self.fc4(out)) # 확률값 반환
return y
# MNIST 데이터셋 로드
import torchvision.datasets as dset
mnist_data = dset.MNIST(root='MNIST_data/',
train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5) # 정규화
]),
download=True)
data_loader = DataLoader(dataset=mnist_data,
batch_size=batch_size,
shuffle=True)
# 모델 초기화
discriminator = Discriminator()
generator = Generator()
# 옵티마이저 및 손실 함수 설정
import torch.optim as optim
d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
loss_func = nn.BCELoss() # Binary Cross Entropy Loss 사용
# 학습 루프
for epoch in range(num_epoch):
for i, (images, label) in enumerate(data_loader):
real_label = torch.full((batch_size, 1), 1, dtype=torch.float32) # 진짜 데이터 레이블 (1)
fake_label = torch.full((batch_size, 1), 0, dtype=torch.float32) # 가짜 데이터 레이블 (0)
real_images = images.reshape(batch_size, -1) # 28x28 이미지를 1D 벡터로 변환
label_encoded = F.one_hot(label, num_classes=10) # 원-핫 인코딩 변환
real_images_concat = torch.cat([real_images, label_encoded], dim=1) # 입력 이미지와 레이블 결합
# 생성기 학습
d_optimizer.zero_grad()
g_optimizer.zero_grad()
z = torch.randn(batch_size, noise_size)
z_concat = torch.cat([z, label_encoded], dim=1)
fake_images = generator(z_concat)
fake_images_concat = torch.cat([fake_images, label_encoded], dim=1)
g_loss = loss_func(discriminator(fake_images_concat), real_label) # 생성기가 1로 판별되도록 학습
g_loss.backward()
g_optimizer.step()
# 판별기 학습
d_optimizer.zero_grad()
g_optimizer.zero_grad()
z = torch.randn(batch_size, noise_size)
z_concat = torch.cat([z, label_encoded], dim=1)
fake_images = generator(z_concat)
fake_images_concat = torch.cat([fake_images, label_encoded], dim=1)
fake_loss = loss_func(discriminator(fake_images_concat), fake_label)
real_loss = loss_func(discriminator(real_images_concat), real_label)
d_loss = (fake_loss + real_loss) / 2
d_loss.backward()
d_optimizer.step()
if (i + 1) % 150 == 0:
print(f'epoch:[{epoch + 1}/{num_epoch}] step[{i + 1}/{len(data_loader)}] d_loss :{d_loss.item():.5f} g_loss:{g_loss.item():.5f}')
# 생성된 이미지 저장
samples = fake_images.reshape(batch_size, 1, 28, 28)
save_image(samples, os.path.join(dir_name, f'CGAN_fake_samples{epoch + 1}.png'))
def check_condition(l_generator):
test_image = torch.empty(0)
for i in range(10):
test_label = torch.tensor([0,1,2,3,4,5,6,7,8,9])
test_label_encoded = F.one_hot(test_label, num_classes=10)
z = torch.randn(10, noise_size)
z_concat = torch.cat([z, test_label_encoded], dim=1)
test_image = torch.cat([test_image, l_generator(z_concat)], dim=0)
result = test_image.reshape(10, 1, 28, 28)
save_image(result, os.path.join(dir_name, 'CGAN_test_result.png'), nrow=10)
# 학습된 생성기 검증
check_condition(generator)
GAN 예제 2
import glob
import os
from PIL import Image
import matplotlib.pyplot as plt
path_to_imgs = './GANIMG/img_align_celeba'
imgs = glob.glob(os.path.join(path_to_imgs, '*'))
# print(imgs)
#
# for i in range(9):
# plt.subplot(3,3,i+1)
# img = Image.open(imgs[i])
# plt.imshow(img)
#
# plt.show()
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch
dataset = ImageFolder(
root='./GANIMG',
transform=transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
)
data_loader = DataLoader(dataset=dataset,
batch_size=128,
shuffle=True)
it = iter(data_loader)
data = next(it)
print(data)
print(data[0].shape)
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.gen = nn.Sequential(
nn.ConvTranspose2d(100, 512, kernel_size=4, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.ConvTranspose2d(512, 256,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.ConvTranspose2d(256, 128,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128, 64,
kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, 3,
kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
y = self.gen(x)
return y
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.disc = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512, 1, kernel_size=4),
nn.Sigmoid()
)
def forward(self, x):
y = self.disc(x)
return y
def weight_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
G = Generator()
G.apply(weight_init)
D = Discriminator()
D.apply(weight_init)
# import torch.optim as optim
#
# G_optimizer = optim.Adam(G.parameters(), lr=0.0001, betas=(0.5, 0.999))
# D_optimizer = optim.Adam(D.parameters(), lr=0.0001, betas=(0.5, 0.999))
#
# for epoch in range(50):
# for data in data_loader:
# D_optimizer.zero_grad()
#
# label_real = torch.ones_like(data[1], dtype=torch.float32)
# label_fake = torch.zeros_like(data[1], dtype=torch.float32)
#
# hypothesis = D(data[0])
#
# d_loss_real = nn.BCELoss()(torch.squeeze(hypothesis), label_real)
# d_loss_real.backward()
#
# noise = torch.randn(label_real.shape[0], 100, 1, 1)
# fake_img = G(noise)
#
# hypothesis2 = D(fake_img.detach())
#
# d_loss_fake = nn.BCELoss()(torch.squeeze(hypothesis2), label_fake)
# d_loss_fake.backward()
# D_optimizer.step()
#
# d_loss = d_loss_real + d_loss_fake
#
# G_optimizer.zero_grad()
# hypothesis3 = D(fake_img)
# g_loss = nn.BCELoss()(torch.squeeze(hypothesis3), label_real)
# g_loss.backward()
# G_optimizer.step()
#
# print(f'epoch:{epoch+1} d_loss:{d_loss.item():4f} g_loss:{g_loss.item():4f}')
#
# torch.save(G.state_dict(), 'Generator.pth')
# torch.save(D.state_dict(), 'Discriminator.pth')
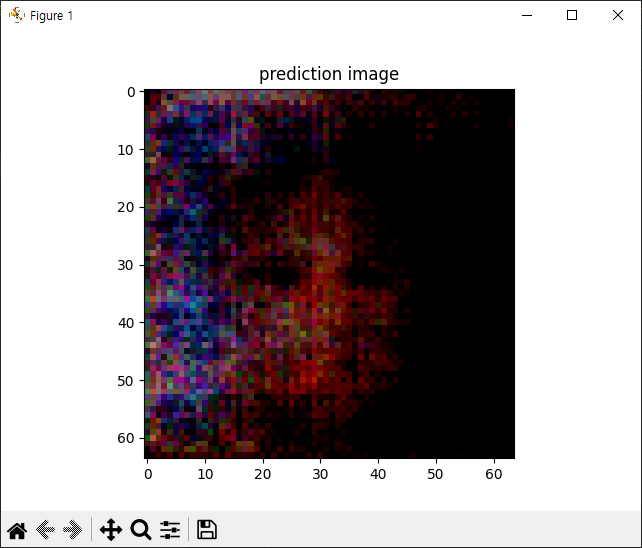
with torch.no_grad():
G.load_state_dict(torch.load('./Generator.pth'))
noise = torch.randn(1, 100, 1, 1)
pred = G(noise).squeeze()
pred = pred.permute(1, 2, 0).numpy()
plt.imshow(pred)
plt.title('prediction image')
plt.show()