오토인코더
어떤 지도 없이도(즉, 레이블되어 있지 않은 훈련 데이터를 사용해서) 잠재 표현 또는 코딩이라 부르는 입력 데이터의 밀집 표현을 학습할 수 있는 인공 신경망
- 오토인코더에 제약을 가해서 데이터에 있는 패턴을 찾아 활용
- 재구성
- 재구성 손실
- 과소완전
과소완전 선형 오토인코더로 PCA 수행하기
오토인코더가 선형 활성화 함수만 사용하고 비용 함수가 평균 제곱 오차(MSE) 라면, 이는 결국 주성분 분석을 수행하는 것으로 볼 수 있음
- 오토인코더 수행 학습
3D 데이터셋에 PCA를 적용해 2D에 투영하는 간단한 선형 오토인코더 생성
가상으로 생성한 간단한 3D 데이터셋에 훈련
동일한 데이터셋을 인코딩(즉 2D로 투영)
오토인코더
오토인코더 (또는, 심층 오토인코더)
- 여러 개의 은닉층을 가진 오토인코더
케라스를 사용하여 적층 오토인코더 구현하기
- 일반적인 심층 MLP와 매우 비슷하게 적층 오토인코더를 구현
재구성 시각화
- 입력과 출력을 비교하여 오토인코더가 적절히 훈련되었는지 확인
적층 오토인코더
패션 MNIST 데이터셋 시각화
- 적절한 수준으로 차원을 축소한 후 다른 차원 축소 알고리즘을 사용해 시각화
적층 오토인코더를 사용한 비지도 사전훈련
- 기존의 네트워크에서 학습한 특성 감지 기능을 재사용
가중치 묶기
한 번에 오토인코더 한 개씩 훈련하기
- 탐욕적 방식의 층별 훈련 (greedy layerwise training)
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
train_epochs = 20
batch_size = 100
learning_rate = 0.0002
mnist_train = dset.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dset.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True)
class AutoEncoderNet(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256,20)
)
self.decoder = nn.Sequential(
nn.Linear(20,256),
nn.ReLU(),
nn.Linear(256,784)
)
def forward(self,x):
x = x.view(batch_size, -1)
eoutput = self.encoder(x)
y = self.decoder(eoutput).view(batch_size, 1, 28, 28)
return y
AEModel = AutoEncoderNet()
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(AEModel.parameters(), lr=learning_rate)
for epoch in range(train_epochs):
for idx, (x_data, y_data) in enumerate(data_loader):
optimizer.zero_grad()
hypothesis = AEModel(x_data)
loss = loss_func(hypothesis, x_data)
loss.backward()
optimizer.step()
if idx % 100 == 0:
print(f'loss:{loss.item():.4f}')
out_img = torch.squeeze(hypothesis.data)
for i in range(3):
plt.subplot(121)
plt.imshow(torch.squeeze(x_data[i]).numpy(), cmap='gray')
plt.subplot(122)
plt.imshow(out_img[i].numpy(), cmap='gray')
plt.show()
loss:0.1132
loss:0.0547
loss:0.0385
loss:0.0337
loss:0.0277
loss:0.0260
loss:0.0242
loss:0.0250
loss:0.0243
loss:0.0215
loss:0.0220
loss:0.0212
loss:0.0221
loss:0.0208
loss:0.0218
loss:0.0208
loss:0.0211
loss:0.0211
loss:0.0201
loss:0.0190
loss:0.0196
loss:0.0211
loss:0.0205
loss:0.0193
loss:0.0196
loss:0.0196
loss:0.0199
loss:0.0190
loss:0.0184
loss:0.0196
loss:0.0183
loss:0.0178
loss:0.0193
loss:0.0180
loss:0.0187
loss:0.0188
loss:0.0181
loss:0.0171
loss:0.0194
loss:0.0181
loss:0.0179
loss:0.0170
loss:0.0185
loss:0.0168
loss:0.0181
loss:0.0186
loss:0.0166
loss:0.0176
loss:0.0180
loss:0.0177
loss:0.0180
loss:0.0172
loss:0.0173
loss:0.0169
loss:0.0170
loss:0.0176
loss:0.0166
loss:0.0172
loss:0.0184
loss:0.0176
loss:0.0166
loss:0.0159
loss:0.0167
loss:0.0164
loss:0.0163
loss:0.0166
loss:0.0178
loss:0.0156
loss:0.0150
loss:0.0172
loss:0.0170
loss:0.0174
loss:0.0171
loss:0.0173
loss:0.0159
loss:0.0180
loss:0.0162
loss:0.0168
loss:0.0163
loss:0.0173
loss:0.0144
loss:0.0155
loss:0.0161
loss:0.0154
loss:0.0174
loss:0.0151
loss:0.0153
loss:0.0159
loss:0.0155
loss:0.0173
loss:0.0162
loss:0.0179
loss:0.0165
loss:0.0172
loss:0.0153
loss:0.0149
loss:0.0159
loss:0.0157
loss:0.0155
loss:0.0169
loss:0.0169
loss:0.0152
loss:0.0155
loss:0.0162
loss:0.0156
loss:0.0154
loss:0.0154
loss:0.0152
loss:0.0158
loss:0.0164
loss:0.0149
loss:0.0154
loss:0.0162
loss:0.0147
loss:0.0142
loss:0.0150
loss:0.0151
loss:0.0164
loss:0.0144
loss:0.0142
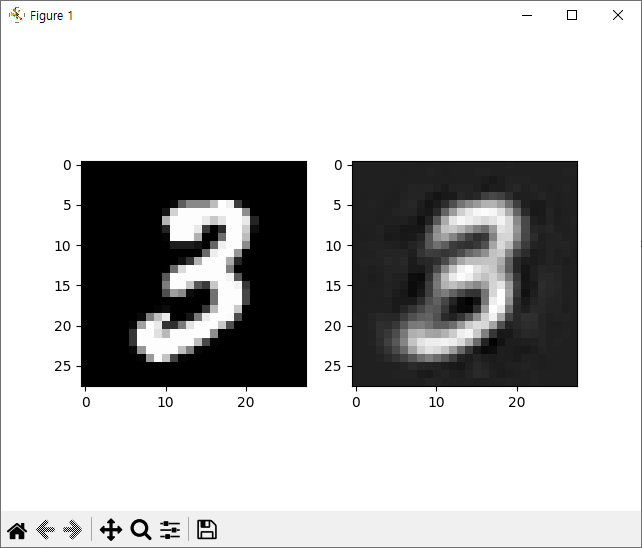
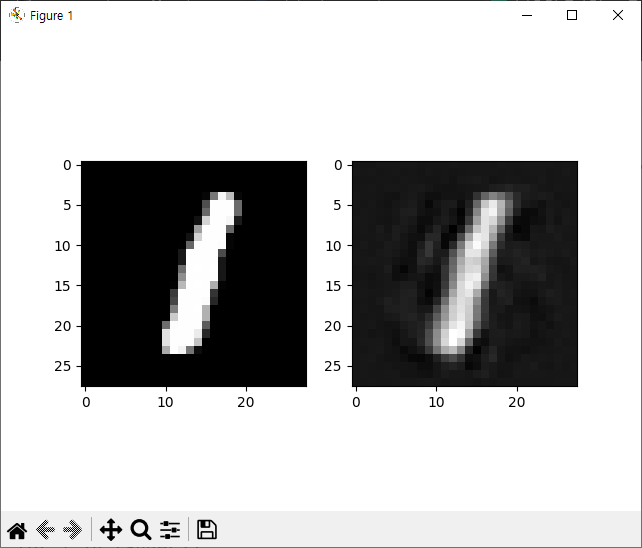
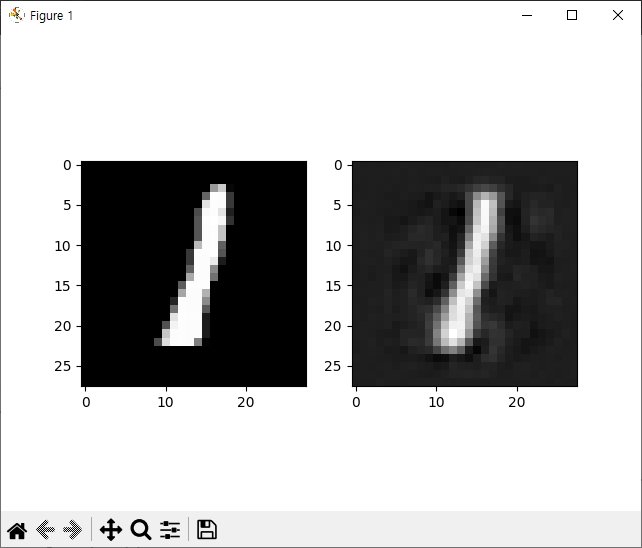
합성곱 오토인코더
이미지를 다룰 때는 합성곱 신경망이 밀집 네트워크보다 훨씬 좋은 성능
합성곱 오토인코더
-
합성곱 층과 풀링 층으로 구성된 일반적인 CNN
-
일반적인 인코더 입력: 공간 방향의 차원(즉, 높이와 너비)을 줄이고 깊이(즉, 특성 맵의 개수)를 늘림 디코더는 거꾸로 동작 (이미지의 스케일을 늘리고 깊이를 원본 차원으로 되돌림)
-
이를 위해서 전지 합성곱 층을 사용(또는 합성곱 층과 업샘플링 층을 연결)
-
패션 MNIST 데이터셋에 대한 간단한 합성곱 오토인코더 학습
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
train_epochs = 20
batch_size = 100
learning_rate = 0.0002
mnist_train = dset.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dset.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True)
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,16,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(16),
nn.Conv2d(16, 32, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32,64,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2,2) # 64 * 14 * 14
)
self.layer2 = nn.Sequential(
nn.Conv2d(64,128,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2,2), # 128 * 7 * 7
nn.Conv2d(128,256,3, padding=1), # 256 * 7 * 7
nn.ReLU()
)
def forward(self,x):
out = self.layer1(x)
out = self.layer2(out)
y = out.view(batch_size, -1)
return y
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(256, 128,3,2,1,1), #128 * 14 * 14
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128,64,3,1,1), # 64 * 14 * 14
nn.ReLU(),
nn.BatchNorm2d(64)
)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(64,16,3,1,1), # 16 * 14 * 14
nn.ReLU(),
nn.BatchNorm2d(16),
nn.ConvTranspose2d(16,1,3,2,1,1), # 1 * 28 * 28
nn.ReLU()
)
def forward(self,x):
x = x.view(batch_size, 256, 7, 7)
out = self.layer1(x)
y = self.layer2(out)
return y
encoder = Encoder()
decoder = Decoder()
loss_func = nn.MSELoss()
parameters = list(encoder.parameters()) + list(decoder.parameters())
optimizer = torch.optim.Adam(parameters, lr=learning_rate)
for epoch in range(train_epochs):
for idx, (x_data, _) in enumerate(data_loader):
optimizer.zero_grad()
eoutput = encoder(x_data)
hypothesis = decoder(eoutput)
loss = loss_func(hypothesis, x_data)
loss.backward()
optimizer.step()
if idx % 100 == 0:
print(f'{epoch+1} / {idx+1} loss:{loss.item():.4f}')
out_img = torch.squeeze(hypothesis.data)
for i in range(3):
plt.subplot(121)
plt.imshow(torch.squeeze(x_data[i]).numpy(), cmap='gray')
plt.subplot(122)
plt.imshow(out_img[i].numpy(), cmap='gray')
plt.show()
예제2
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
train_epochs = 10
batch_size = 64 # 이미지를 5장만 출력하려면 batch_size를 5로 설정
learning_rate = 0.005
Fmnist_train = dset.FashionMNIST(root='FashionMNIST_data/',
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor()])
)
Fmnist_test = dset.FashionMNIST(root='FashionMNIST_data/',
train=False,
download=True,
transform=transforms.Compose([transforms.ToTensor()])
)
data_loader = DataLoader(dataset=Fmnist_train,
batch_size=batch_size,
shuffle=True)
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(784,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64,12),
nn.ReLU(),
nn.Linear(12,3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12,64),
nn.ReLU(),
nn.Linear(64,128),
nn.ReLU(),
nn.Linear(128,784),
nn.Sigmoid()
)
def forward(self,x):
eoutput = self.encoder(x)
doutput = self.decoder(eoutput)
return eoutput, doutput
autoencoder = AutoEncoder().cuda()
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=learning_rate)
def train(autoencoder, train_loader):
for x_data, _ in train_loader:
x_data = x_data.view(-1,784).cuda()
eoutput, doutput = autoencoder(x_data)
loss = loss_func(doutput, x_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
import numpy as np
view_data = Fmnist_train.data[:5].view(-1, 28*28)
view_data = view_data.type(torch.FloatTensor) / 255.
view_data = view_data.cuda()
for epoch in range(train_epochs):
train(autoencoder, data_loader)
_, doutput = autoencoder(view_data)
fig, axes = plt.subplots(2,5,figsize=(5,2))
for i in range(5):
img = np.reshape(view_data.cpu().data.numpy()[i],(28,28))
axes[0][i].imshow(img,cmap='gray')
axes[0][i].set_xticks(())
axes[0][i].set_yticks(())
for i in range(5):
img = np.reshape(doutput.data.cpu().numpy()[i],(28,28))
axes[1][i].imshow(img,cmap='gray')
axes[1][i].set_xticks(())
axes[1][i].set_yticks(())
plt.show()
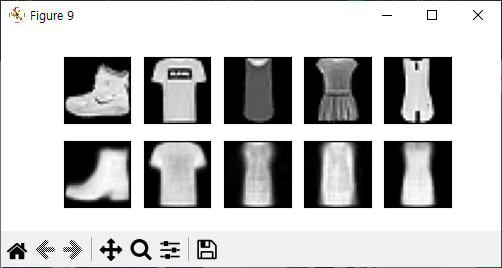
잡음 제거 오토인코더
입력에 잡음을 추가하고, 잡음이 없는 원본 입력을 복원하도록 훈련
-
데이터 시각화나 비지도 사전훈련을 위해 사용할 뿐만 아니라 간단하고 효율적으로 이미지에서 잡음을 제거한느데 사용
-
적층 잡음 제거 오토인코더
-
잡음은 입력에 추가된 순수한 가우시안 잡음 또는 드롭아웃처럼 무작위로 입력을 꺼서 발생시킬 수도 있음
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
train_epochs = 20
batch_size = 100
learning_rate = 0.0002
# MNIST 데이터셋 로드
mnist_train = dset.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
data_loader = DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True)
# 노이즈 추가 함수
def add_noise(img):
noise = torch.randn_like(img) * 0.3 # 랜덤 노이즈 생성
noise_img = img + noise
return noise_img
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 784),
nn.Sigmoid() # Sigmoid 활성화로 출력값을 0-1 범위로 제한
)
def forward(self, x):
eoutput = self.encoder(x)
doutput = self.decoder(eoutput)
return eoutput, doutput
# 모델, 손실 함수, 최적화 설정
autoencoder = AutoEncoder().cuda()
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=learning_rate)
# 학습 함수
def train(autoencoder, train_loader):
avg_loss = 0
for (image, _) in train_loader:
image = image.view(-1, 784).cuda() # 이미지를 784 차원 벡터로 변환하고 CUDA로 이동
x_data = add_noise(image) # 노이즈 추가
y = image # 원본 이미지를 목표값으로 설정
# 오토인코더로 입력을 디코딩
_, decoded = autoencoder(x_data)
# 손실 계산
loss = loss_func(decoded, y)
optimizer.zero_grad() # 기울기 초기화
loss.backward() # 역전파
optimizer.step() # 가중치 업데이트
avg_loss += loss.item()
return avg_loss / len(train_loader)
# 학습 루프
for epoch in range(train_epochs):
loss = train(autoencoder, data_loader)
print(f'epoch:{epoch + 1} loss:{loss:.4f}')
# 예시 이미지 처리
sample_data = mnist_train.data[1].view(-1, 784).type(torch.FloatTensor) / 255.0
original_x = sample_data.cuda() # CUDA로 이동
noise_x = add_noise(original_x) # 노이즈 추가
_, recovered_x = autoencoder(noise_x) # 재구성된 이미지
# Matplotlib을 이용해 원본 이미지, 노이즈 추가된 이미지, 재구성된 이미지 시각화
fig, axes = plt.subplots(1, 3, figsize=(10, 5))
original_img = original_x.cpu().data.numpy().reshape(28, 28) # CPU로 이동 후 numpy로 변환
noise_img = noise_x.cpu().data.numpy().reshape(28, 28)
recovered_img = recovered_x.cpu().data.numpy().reshape(28, 28)
# 원본 이미지
axes[0].set_title('Original Image')
axes[0].imshow(original_img, cmap='gray')
axes[0].axis('off')
# 노이즈가 추가된 이미지
axes[1].set_title('Noisy Image')
axes[1].imshow(noise_img, cmap='gray')
axes[1].axis('off')
# 복원된 이미지
axes[2].set_title('Recovered Image')
axes[2].imshow(recovered_img, cmap='gray')
axes[2].axis('off')
plt.show()
epoch:1 loss:0.0877
epoch:2 loss:0.0613
epoch:3 loss:0.0572
epoch:4 loss:0.0554
epoch:5 loss:0.0542
epoch:6 loss:0.0531
epoch:7 loss:0.0510
epoch:8 loss:0.0485
epoch:9 loss:0.0471
epoch:10 loss:0.0456
epoch:11 loss:0.0444
epoch:12 loss:0.0431
epoch:13 loss:0.0422
epoch:14 loss:0.0414
epoch:15 loss:0.0408
epoch:16 loss:0.0403
epoch:17 loss:0.0399
epoch:18 loss:0.0396
epoch:19 loss:0.0393
epoch:20 loss:0.0391
변이형 오토인코더(VAE)
변이형 오토인코더의 속성
-
확률적 오토인코더: 즉 , 훈련이 끝난 후에도 출력이 부분적으로 우연에 의해 결정 (이와는 반대로 잡음 제거 오토인코더는 훈련 시에만 무작위성을 사용)
-
생성 오토인코더: 마치 훈련 세트에서 샘플링된 것 같은 새로운 샘플을 생성할 수 잇음
-
입력이 복잡한 분포를 가지더라도 간단한 가우시안 분포에서 샘플링된 것처럼 보이는 코딩을 만드는 경향
패션 MNIST 이미지 생성하기
-
가우시안 분포에서 랜덤한 코딩을 샘플링하여 디코딩
-
변이형 오토인코더는 시맨틱 보간을 수행
