운영체제란?
운영체제는 하드웨어 자원 관리, 응용 프로그램과 하드웨어 사이를 중재하는 인터페이스이다.
인터페이스: 서로 다른 시스템사이에서 정보나 신호를 주고받는 접점을 말함
커널이란?
프로그램이 실행되기 위해서 메모리에 올려야됨.
운영체제도 프로그램이기 때문에, 메인메모리에 적재해야되나, 크기가 너무 커서, 커널이라는 항상 필요한 운영체제의 핵심부분만 메인메모리에 적재하여 운영체제가 사용
즉, 메모리에 상주하는 운영체제의 핵심부분
운영체제도 커널의 data stack code가 있음
메모리의 구조를 영역에 따라서 설명
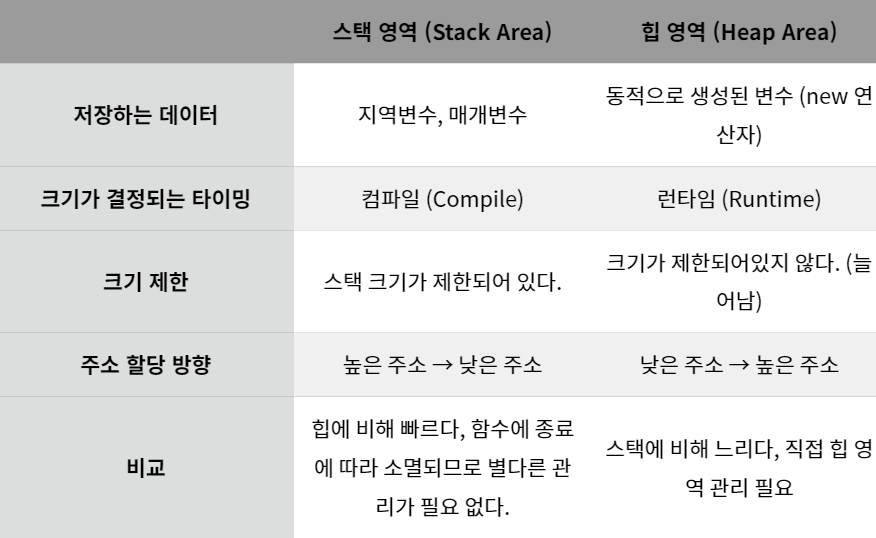
code: 프로그램의 코드가 저장, cpu는 해당 코드영역의 명령어를 하나씩 가져가서 처리
data영역: static영역, 전역과 정적 변수가 저장, 프로그램 시작하는 동시에 할당, 프로그램이 종료하면 소멸
Heap영역: 메모리 공간 동적으로 할당 및 해제,런타임에 크기 결정
Stack영역: 함수 호출에 따른 지역변수와 매개변수가 저장, 컴파일시 크기가 고정, 함수 호출과 함께 할당, 호출 종료시 소멸
스택영역과 힙 영역 차이
힙 영역이 너무 크게 잡으면 어떻게되나?
힙영역은 동적할당과 같이 직접 메모리에 적재하는 방식이므로, free같은 메서드로 변수 제거를 통해 메모리관리 필요,
메모리의 힙영역이 너무 크면, 넓은 힙 영역에 존재하는 동적 변수에 대해서 참조여부를 파악해야하므로 Garbage Collect 수행시간이 너무 길어진다.
따라서, JAVA의 JVM에서도 힙영역을 크게 잡지않고, Heap영역이 꽉차면 GC하고 Heap영역확장함
프로세스 vs 쓰레드
-
프로세스
메인메모리에 적재되어 실행
PCB,code,data,stack,heap가짐
각 프로세스마다 영역을 가지므로 동기화 작업x
context switching비용 큼
한 프로세스에서 오류가 생기더라도 다른 프로세스에 영향x -
쓰레드
한 프로세스 내의 실행 단위, 실행 흐름
stack영역만 별도로 가지고 나머지 영역은 해당 쓰레드를 포함한 프로세스의 자원 공유
stack영역 외부의 공유자원 접근시 동기화 작업필요
stack영역 외부를 공유하므로 컨텍스트 스위칭 비용이 적다.
한 쓰레드에서 오류가 생기면 나머지 프로세스내의 쓰레드에 영향을 줌
컨택스트 스위칭에대해서 설명하고 왜 필요한가?
컨택스트 스위칭이란,
인터럽트 설명하고, 그다음에 CPU한테 뺏길때 처음부터 수행하지 않기 위해서 PCB에 상태저장하고, 다음 수행한 작업 상태를 레지스터에 적재하는과정
CPU다시 받으면, PCB를 통해 복원후, Program counter가르키는 위치부터 수행
PCB란?
OS 커널의 자료구조임
프로세스생성과 동시에 각각 프로세스마다 PCB생성
프로세스로 부터 CPU를 받으면 해당 프로세스의 정보를 PCB에 저장, 그리고 나중에 다시 프로세스가 CPU를 받으면 PCB정보로 복원
정보
- PID
- 프로세스 상태
- 프로그램 카운터
- CPU 레지스터
- 메모리 관리 정보: 페이지 테이블, 세그먼트 테이블 등
크롬은 한 탭에 오류 -> 다른탭 영향x
그럼 크롬은 프로세스지
멀티 쓰레드와 멀티 프로세스를 비교
멀티 쓰레드: 하나의 프로세스를 여러개의 쓰레드로 구성, 자원을 공유하면서 작업 수행
멀티 프로세스보다 적은 메모리 공간, context switching빠름, 오류로 인해 하나의 쓰레드 종료 -> 전체 쓰레드 종료 가능
멀티 프로세스: 하나의 프로그램을 여러개의 프로세스로 구성해서 병렬적으로 작업수행, 하나의 프로세스가 죽더라도 다른 프로세스의 영향x, 멀티쓰레드보다 많은 메모리공간 차지
쓰레드마다 독립적으로 할당하는 2가지
스택영역 ,PC Register
스택영역: 당연히 쓰레드마다 독립적으로 작업수행시 함수 호출하면서 변수를 적재해야하니까.
PC Register: 쓰레드가 명령어를 어디까지 수행했는지를 나타낸다. 쓰레드도 당연히 CPU가 한번에 하나만 처리 가능하니까 뺏기고 다시 얻었을때 어디까지 실행됬는지 알아야하므로
멀티쓰레드에서 주의해야할점
한 프로세스내에서 쓰레드들이 자원을 공유하므로 동기화 고려
동기와 비동기 차이
동기: 요청을하면 시간이 얼마나 걸리던 요청한 자리에서 결과가 주어져야함.
read같은거 read요청을 보내면 cpu뺏기고 disk에서 I/O해서 가져올때까지 아무것도 못함
비동기: 요청과 결과가 동시에 일어나지 않아도됨, 그시간에 다른작업 가능하므로 효율적 write같은거 꼭 disk에 써졌는지 안써졌는지 확인하지 않아도 다른거, 그냥 해도됨
Blocking, Non-Blocking
Blocking: A가 B호출 , B는 자신의 작업이 종료되기 전까지 A에게 제어권을 돌려주지 않음
Non-Blocking: A가 B를 호출, B가 A에게 곧바로 제어권을 돌려줌
A는 제어권을 가지고 있으므로 곧바로 다른 일을 수행할 수 있음
프로세스의 종류
자식 프로세스: fork로 자식프로세스를 만든 상태, 부모의 데이터,힙,스택,PCB등 다 똑같이 복사
데몬 프로세스: 백그라운드에서 동작하면서 특정한 서비스를 제공
고아 프로세스: 부모 프로세스가 먼저 종료되어 고립된 자식 프로세스
좀비 프로세스: 자식 프로세스가 종료되었음에도 부모프로세스로부터 작업 종료에 대한 승인을 받지 못한 프로세스
Race condition, Critical Section, 경쟁상태를 막기위해서 어떤 방법사용?
두개 이상의 쓰레드가 공유자원에 접근하려고 서로 경쟁하는것을 RaceCondition이라고 한다.
이 공유자원에 접근하는 코드 즉 x=3;같은게 Critical Section이라고함
Critical Section에 대한 경쟁상태를 제거하기위해서, 하나의 공유자원에 대해서 하나의 쓰레드만 접근허용하는 상호배재 Mutual Exclusion을 사용
Mutual Exclusion
- 두 프로세스는 동시에 공유 자원에 진입 할 수 없다.
- 프로세스의 속도나 프로세서 수에 영향을 받지 않는다.
- 공유 자원을 사용하는 프로세스만 다른 프로세스를 차단할 수 있다.
- 프로세스가 공유 자원을 사용하려고 너무 오래 기다려서는 안된다.
DeadLock이 무엇이고 해결방법은 무엇인가?
두개 이상의 프로세스나 쓰레드가 서로 자원을 기다리면서 무한이 대기
발생조건
- 상호배제: 하나의 자원에 여러 프로세스 접근 불가
- 점유대기: 하나의 자원을 소유한 상태에서 다른자원을 기다림
- 비선점: 프로세스가 어떤 자원의 사용을 끝낼때까지 프로세스의 자원을 뺏을수없다.
- 순환대기: 각 프로세스가 순환적으로 다음 프로세스가 요구하는 자원을 가지고있다.
이 4가지 조건중 하나라도 제거하면 막을 수 있음
상호배제는 제거 힘듬
-
Deadlock Prevection
deadlock의 4가지 조건중 하나를 원천적으로 차단해서 안생기게함
MutualExclusion: 애초에 공유자원에서 문제가 생기므로 해결방법x
Hold and Wait: 자원이 필요한 경우 보유자원을 모두 놓고 다시 요청
No preemption: 자원을 기다려야하면 자원을 뺏어올수있게함
Circular wait: 항상 정해진 순서대로 자원할당 내가 4번 자원을 가지고 싶으면 1,2,3번 자원을 가져야만 4번 요청가능 -
Avoidance
자원이 1개있는경우: Resource Allocation Graph Algorithm사용
여러개있는경우: Banker's Algorithm사용 -
Detection
자원이 1개있는경우 자원할당 그래프로 사이클 생성 유무로 판단
자원이 여러개있는 경우 Table을 그려서 DeadLock여부 판단 -
Recovery
DeadLock Process를 전부 죽임
하나씩 DeadLock을 죽여보면서 Deadlock풀리는지 확인
비용을 최소화할 victim을 선정, 자원 뺏어서 deadlock풀기, 계속 victim선정시 starvation고려
식사하는 철학자 문제에서, Deadlcok이 어떨때 발생하는지 설명, 해결하기위한 방법?
각자 왼쪽포크 부터 5명전부 드는경우 오른쪽 포크를 대기하는 DeadLock발생(왼쪽 포크 자원은 내려놓지 않고, 기다림)
- 5명 모두 자신의 왼쪽 포크를 들고있음: 점유대기
- 남의 포크를 뺏어주지 않음: 비선점
- 서로 오른쪽 포크를 놓기를 기다림: 환형대기
- 각 포크에 대해서 한사람만 들수 있음: 상호배제
카운팅 세마포어를 사용 -> 최대 4명만 들어오면 모든 사람이 왼쪽 포크를 든다 하더라도 Deadlock발생 x
Mutex와 Semaphore가 뭐냐?
-
뮤텍스
오직 1개의 쓰레드, 프로세스만 접근가능
1개만 접근가능하므로, 반드시 락을 획득한 프로세스가 락을 해제해야함 -
세마포어
세마포어 변수만큼 스레드 또는 프로세스가 접근가능
현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어 헤제할수있다.
이진 세마포어는 뮤텍스와 동일
뮤텍스와 세마포어를 사용해 임계영역에서 경쟁상태를 제거할 수 있다.
ex) 뮤텍스: 임계영역전에 mutex를 사용하여 Lock을 걸고 들어감

ex). 세마포어:
Consumer
do{
P(full)
P(mutex)
remove an item from buffer Y
V(mutex)
V(empty)
}while(1);P(full)->세마포어, 즉 갯수로 접근가능한 공유변수가 있는지 판단
그리고 P(mutex)로 공유자원 Lock걸고 Lock 풀고 V(empty)로 자원 줄임
CPU Scheduling이 무엇인지 설명하고, CPU 스케쥴링의 종류에 대해서 설명해주세요
Read Queue에 있는 프로세스중에 다음에 CPU를 할당한 프로세스를 선택하는 알고리즘
FCFS: 비선점, 먼저온놈 처리
SJF: 짧은 시간 걸리는 프로세스 처리, 비선점, 선점 가능
Priority Scheduling: 우선순위가 제일 높은 프로세스한테 cpu주기, 선점 비선점 가능
Round Robin: quque에 n개의 프로세스 q라는 시간을 각 프로세스마다 사용하게 하는것, 어떤 프로세스든 (n-1)*q시간에 맛볼수있음
Multi Level Queue: 여러줄로 cpu줄서기 우선순위 높은 줄 안빠지면, 못씀, 너무 오래기다리면 Aging고려해서 윗 queue로 올려줌
CPU 성능 척도에는 무엇이 있는가?
CPU 이용률 : CPU가 놀지 않고 일한 시간
Throughput: 단위 시간당 처리시간, 얼마나 많은일을 했는가
Turnaround Time: CPU 사용시간 + 기다린 시간
Waiting Time: 프로세스가 Ready Queue에서 기다린 전체 시간
Response Time: 프로세스가 Ready Queue에 들어가서 최초로 CPU 얻기까지 기다린 시간
선점? 비선점?
선점: 특정프로세스가 CPU잡고 실행중이어도, 뺏어서 다른 프로세스한테 부여가능
비선점: 특정프로세스가 CPU잡고 실행중이면, 안끝나면 안뺏김
동시성 vs 병렬성
동시성은 Multi Programming에서 나옴, 주기억장치에 여러가지 프로세스를 적재해놓고, CPU가 Context Switching을 통해 마치, 동시에 실행 시키는 것처럼 보이는것, 싱글 코어 멀티 프로세스, 멀티 쓰레드 둘다 가능
병렬성은 Multi Processing에서 나옴, 실제로 cpu가 멀티코어라 여러 프로세스를 병렬적으로 수행
인터럽트란?
프로세스가 수행하지 못하는, 특권명령 ex IO같은것이나, 예외사항을 처리하기 위해서 CPU를 OS한테 넘기고, 운영체제가 커널에있는 운영체제 코드에 따라서 대신 처리해주는것,
System Call이란?
사용자나 응용프로그램이 커널에서 제공하는 기능을 사용하기 위한 인터페이스,
운영체제는 커널이 제공하는 서비스를 시스템 콜을 사용해야 사용가능하게 하여 자원을 보호.
메모리의 종류, 종류가 여려가지인 이유
CPU에 가까운 순서대로, 레지스터, 캐시, 주기억장치, 보조기억장치
접근속도 차이: 레지스터>캐시>주기억장치>보조기억장치
쓰고 읽고 할때 쭉 내려갔다 올라오기 귀찮아서 캐시를 둠 hit하면 바로 올려줌
OS가 메모리 관리 하고, 메모리 관리 전략을 어떤 식으로 수행?
프로세스마다 독자적인 virtual memory를 가지고 이걸 physical memory에 올려서 수행
Logical address -> Physical address로 매핑을 MMU라는 하드웨어 디바이스가 해줌
실제로 physical memory에 어떻게 올려놓는가?
Paging
page table을 사용하여 논리적 메모리를 동일한 크기의 페이지로 짜르고, 메모리에 비어있는 공간 어디든지 밀어넣음
TLB
주소변환을 위한 캐시메모리, Page Table에서 빈번히 참조되는 일부 엔트리를 TLB에서 캐싱
Multilevel Paging
Paing을 여러단계로 할 수 있음
valid/invalid bit
page table에서 쓰는 부가적인 비트, 실제 frame number가 0인지 아니면 아직 페이지 테이블에 안올라와서 0인지 확인하기위해서 사용,
만약 invalid bit이라면 page fault발생후 page fault handler를 통해서 가져와야함
Inverted page table
각 프로세스마다 page table이 있는게 아니라, 시스템 내에 딱하나의 page talbe이 존재
pid를 같이 저장해서 어떤 process의 page number인지 확인
segmentation
동일한 사이즈로 page를 나누느게 아니라 segment번호, 다른하나는 그 세그먼트로 부터 떨어진 offset으로 하여 hole을 줄이는데 용이
외부 단편화, 내부단편화
단편화, 프로세스들이 차지하는 메모리사이에서 사용하지 못할 만큼의 작은 공간을 의미
내부 단편화: 고정길이 할당/페이지에서 나타남, 물리메모리를 고정적인 길이의 파트로 짤랐을때, 해당파트의 길이보다 더 작은 조각이 들어가서 생기는 여백
외부 단편화: 가변길이 할당/세그멘테이션에서 나타남, 프로그램을 올리고 싶은데, 올리려는 프로그램보다 분할된 메모리 조각의 크기가 작아서 사용이 되지 않는 것
가상메모리
멀티 프로그래밍에서 나온 기법, 프로세스전체가 메모리에 올라가지 않음, 프로그램의 일부부만 올라가여 동시에 많은 프로그램을 실행가능, 왜냐? 가상메모리가 없으면 한 프로세스를 전부 물리적 메모리에 적재해야하므로 메모리 용량보다 큰 프로그램 실행불가.
고로 물리적 메모리에 여러개의 프로세스가 올라가므로, 일부분을 공유메모리로 지정하면, 공유메모리를 통해 통신가능
요구 페이징이란?
프로그램 실행 시작시에 초기에 필요한것만 적재하는 전략, 가상메모리와 페이지 개념을 활용해 관리
주소변환과 페이징
논리적 주소를 물리적 주소로 변환하는건 항상 MMU가 해줌
물리적 메모리에 없는걸 논리적 메모리에서 가져와서 올리는건 OS가 해줌 (virtual memory)
페이지 교체가 언제 발생하고, 어떤 교체 알고리즘이 있는가?
page talbe에 만약 invalid bit으로 페이지 엔트리가 없으면, page fault 발샐 OS가 커널 모드에서 page fault handler를 사용하여서 하드디스크의 swap area에서 원하는 페이지를 가져옴
if 물리적 메모리가 모두 사용중이라서 적제가 불가능 하면 페이지 교체
FIFO: 가장 오래된것 교체
LFU : 가장 사용 빈도가 적은 페이지 교체
MFU : 가장 사용 빈도가 많은 페이지를 교체
LRU : 가장 오랫동안 사용되지 않은 페이지 교체
Clock Algorithm : valid라서 이미 메모리에 올라와있으면 page를 읽으면서 reference bit을 1로 바꿈
page fault 발생하면, reference bit이 1이면 0으로 바꾸고 넘어가고, 0이면 교체대상 페이지가 됨
참고: LFU,LRU는 사용 불가 OS가 해당 정보를 알지 못함
- Physical 메모리에 이미 올라가 있는 경우: OS가 관여하지 않으므로 언제 올렸는지, 몇번 참조되었는지 알 수 없음
- 없어서 운영체제로 넘어간경우: 그때 Backing store에서 메모리로 가지고올라옴
결국 OS는 반쪽짜리 정보만 가지고 있음
쓰레싱에 대해서 설명해주세요
CPU utilization이 올라가다가 어느 지점 뚝 떨어지는것,
하나의 프로세스에 page frame이 너무 적게 할당되면, page fault 비율 증가
한 프로세스가 page를 찾으러 갔는데 없어서 IO를 하러가고 또 다른 프로세스가 CPU를 받아서 page를 찾으러 갔는데 없어서 IO하고 이런과정이 반복되면 CPU가 계속 놀게 된다.
그러면 어떠한 프로그램이 CPU를 잡더라도 전부 IO를 하러 가버리니까 CPU Utilization이 낮아지고, OS는 어? CPU가 계속 노네 하면서 다른 프로세스를 시스템에 계속 추가하게 되고, 그러면 또 프로세스 당 할당되는 frame 수가 더욱 감소하는 방식으로 진행된다.
해결방안
working-set Algorithm
대부분의 프로세스가 특정 페이지만 집중적으로 참조, 일정시간동안 참조되는 페이지수를 세고, 그 페이지들을 모두 올려놓을 수 있으면 그때 올려놓는것,
Page Fault Frequency: Page Fault의 상한과 하한을 두고, 상한을 넘기면 해당 프로세스한테 프레임 갯수를 늘리고, 하한을 넘으면 프레임 갯수를 줄임
캐시 메모리를 왜 사용하고, CPU 적중률을 높이려면 어떻게 해야합니까?
CPU는 너무 빠른데 메모리에서 가져오는게 너무 오래걸림
속도차이 완화를 위해서 자주사용되는 데이터를 캐시메모리에 저장,
요청 데이터가 캐시메모리에 이미 있어서 사용하는것을 적중
적중률을 높이기 위해서 참조 지역성의 원리를 사용한다.
최근에 참조된 주소의 내용은 곧 다음에 다시 참조가 됨 -> 반복문
참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성 -> 배열
DMA란 뭐고 왜 씁니까?
가져올때 Block 단위로 인터럽트 발생시키는것(1byte마다 읽고 쓰고 인터럽트걸고 복잡)
device에서 buffer에 어느정도 용량들이 다 차면, DMA가 직접 buffer access해서 memory에 올려주고 인터럽트까지 건다.
메모리 할당시 연속방식과 불연속 방식에 대해서 설명해주세요
연속할당(하나의 프로세스 1,2,3,4,5,6,,,)
-
고정길이 할당: 메모리를 고정된 길이로 짜르고 해당 프로세스를 순서대로 적재, 해당 메모리 파티션이 남는 내부조각 발생
-
가변 길이 할당: 프로세스를 의미단위로 짜르고, 이걸 메모리에 순서대로 적재, 가변된 길이이므로 내부 조각은 안생기지만 남는 조각에 프로세스를 올릴수가 없는 외부조각이 생김
불연속 할당방식
-
페이징: 프로세스를 동일한 크기의 페이지로 분리 -> page table에 해당 page number와 framenumber 적고 해당 framenumber에 페이지 적재, 즉 프로세스의 가상메모리 pagesize와 물리적 메모리의 frame size가 동일함
내부 조각 발생 -
세그멘테이션: 프로세스를 가변적인 크기의 세그멘트로 분리하고 적제
외부 조각 발생 -
페이징 세그멘테이션 둘다 연속할당이 아니므로 table이 존재
