운영체제 개요
OS란?
컴퓨터 하드웨어 바로 위에 설치되어 소프트웨어와 사용자를 연결하는 계층
좁은 의미 - 메모리에 상주하는 커널부분
넓은 의미 - 커널 뿐만 아니라 주변 시스템 유틸리티까지 포함
커널이란?
운영체제는 커널과 시스템 프로그램으로 구분.
커널은 컴퓨터 자원(cpu,메모리,하드디스크등)들을 관리하는 역할을 함. 커널은 항상 컴퓨터 자원을 바라봄. 사용자와의 상호작용 지원 x->시스템프로그램(쉘)을 통해서 자원에 접근
만약 개별 프로그램이 컴퓨터 자원에 직접적으로 접근할 수 있다면, 악성코드가 컴퓨터 자원을 점거할 수 있음
사용자->시스템프로그램(shell등)->커널->컴퓨터자원접근
OS의 목적?
효율성: 주어진 자원으로 최대한 성능을 내야함
형평성: 특정 user/프로그램이 지나친 불이익을 받지 않도록함
저장 장치 계층구조와 캐싱
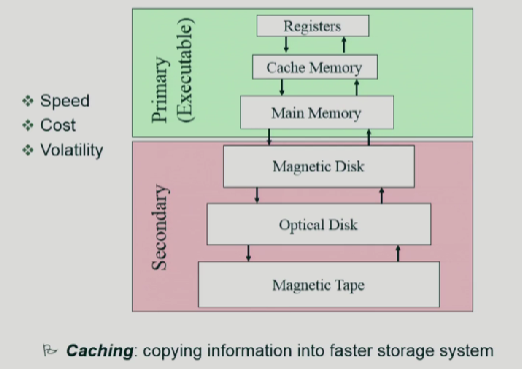
윗단은 휘발,빠름 아랫단은 비휘발 느림
Caching: 속도차이를 완충시키기 위한 방법
저장을 하기위해서는 위에서 아래로 내리고 불러오는건 밑에서 위로 올려야하니까 너무 오래걸림, 중간에서 저장->밑까지 안내려가도 중간에서 만약 요청본이 있으면 가져다 씀
캐시 메모리: 속도가 빠른 장치와 느린장치간의 속도차로 인한 병목현상을 줄이기 위한 메모리
메인메모리와 CPU사이에 위치
메인메모리에서 자주사용하는 데이터나 프로그램을 저장해둔다.
CPU가 어떤 데이터를 원하는지 어느정도 예측을 해야하는데 이를 위해 Locality를 사용한다.
공간지역성: 최근에 사용했던 데이터와 인접한 데이터가 참조될 가능서잉 높다.
시간지역성: 최근에 사용했던 데이터가 재참조 될 가능성이 높다.
메인메모리에 비해 캐시 메모리는 매우 작으므로, 메인메모리의 데이터를 그대로 캐시 메모리에 올려놓을 수는 없다.
고로, 캐시라인이 64bit라면 메인 메모리의 0번지부터 63번지를 가져와서,
캐시메모리 001번지에 0번지부터 63번지 묶음을 저장하고 태그를 1번으로 답니다.(이렇게 묶음으로 저장하는 이유는 1번지를 참조하면 비슷한 번지를 참조할 가능성이 높기 때문이다.)
(태그를 다는 이유는 태그를 안달면, 캐시메모리에서 데이터를 찾기위해 for문으로 다 돌아야하기 때문이다.)
그래서 프로그램이 메인메모리 4번지 데이터를 요청하면 캐시메모리 태그 1번으로 가서 4번지에 해당하는 데이터를 가져옵니다.
그리고 해당 묶음을 캐시라인이라고 합니다.
-
Direct Mapping
메인메모리를 일정한 크기의 블록으로 나누어 각각의 블록을 캐시의 정해진 위치와 매핑, 간단 but 적중률 낮음 -
Full Associative Mapping
캐시 메모리의 빈 공간에 마음대로 주소를 저장, 저장은 간단한데, 찾을때는 모든 태그를 병렬으로 검사해야하므로 복잡 -
Set Associative Mapping
1,2번 섞음, 빈공간에 마음대로 주소를 저장하되, 미리 정해둔 특정 행에만 저장하는 방식.
그러면 특정 행만 검사하면 되므로 2번보다는 탐색이 빠르고 1번보다는 저장이 빠르다.
컴퓨터 시스템 구조
운영체제의 분류
동시작업 가능여부: 단일작업,다중작업(마치 동시에 하는것 처럼)
사용자수: 단일사용자,다중사용자
처리방식: 일괄처리(모았다가 한번에),시분할(시간단위로 분할해서),실시간
mode bit이란?
운영체제가 있는 위치에서 실행하는 기계어 미리 정의해놓은 안전한 기계어 믿고 맏겨서 실행, 사용자 프로그램 무한루프 실행하면 cpu가 사용자 프로그램한테 넘어간상태 이므로 운영체제가 제어할 방법x -> mode bit을 설정하여서
- 운영체제가 cpu실행시 0
- 사용자 프로그램을 수행하면 1
권한을 넘는기계어 실행 x -> interrupt,exception
레지스터란?
CPU는 그냥 기계어를 수행하는 역할만 할뿐 자체적으로 데이터를 저장할 방법이 없기때문에 cpu가 요청을 처리하는데 필요한 데이터를 일시적으로 저장하는 기억장치, program counteremd
인터럽트란?
예외상황이 발생하여 처리가 필요한 경우, cpu한테 알려 처리후 실행중인 작업으로 복귀하는것. 인터럽트가 걸리면 CPU가 OS한테 넘어간다.
예외상황
1. 하드웨어 인터럽트 -> 프로그램A가 cpu가지고 계속 쓰지 못하게 timer Interrupt를 걸어서 cpu독점권을 막는것
2. 소프트웨어 인터럽트 -> 프로그램 A가 disk에서 I/O를 요청
-> CPU가 바로 disk가서 file못가져옴
-> 프로그램 A가 disk controller로 요청 바로 못보냄 cpu가 I/O해달라는 기계어는 특권명령이므로
-> 프로그램 A가 OS로 cpu를 넘기기 위해서 programCounter를 OS로 못넘김(가상메모리에 있는 프로그램 A가 메모리를 가로질러서, 이 file가져다달라고 OS로 못넘김)
-> OS로 cpu가 넘어가는 1가지방법 interrupt
-> 프로그램 A가 systemcall(사용자 프로그램이 운영체제의 서비스를 받기위해서 커널함수 호출하는것) 호출
-> 해당 프로그램 interrruptline세팅
-> OS가 대신 파일 읽어달라는 요청하고
-> disk가 file다읽으면 diskcontroller가 cpu한테 interrupt검
-> 운영체제는 가만히 왜 interrupt걸렸지? 보니까 아 file이 다 읽혔구나 그러면 운영체제는 자신의 code를 사용해 메모리에 file을 카피하고 메모리에 이 file이 올라와서 프로그램A가 사용
운영체제로 cpu가 넘어가는 3가지경우
인터럽트 라인 세팅할때
1. 하드웨어 장치들이 인터럽트를 걸때
2. 소프트웨어가 인터럽트 라인을 거는것 syscall
3. timer
동기식 입출력이란?
사용자 프로그램이 io를 요청하고, io작업이 끝나면, disk컨트롤러가 인터럽트걸고, disk file을 읽어온걸 보고, file을 읽어올때까지 기다리는거, 왜냐하면 file을 읽어와야 뭘 하는데 뭘 읽어올지 모르니까 비동기로 못한다.
비동기식 입출력
I/O결과를 확인하지 않고, 그 이전에 작업할 수 있는것들이 있다면 작업을 수행하는것, IO결과과 무관한 것들이나, write같은것들이 disk에 꼭 써지던 안써지던 상관없이 다음일 처리가능->쓰기작업은 비동기처리가능
DMA
Block 단위로 인터럽트 발생시키는것(1byte마다 읽고 쓰고 인터럽트걸고 복잡)
device에서 buffer에 어느정도 용량들이 다 차면, DMA가 직접 buffer access해서 memory에 올려주고 인터럽트까지 건다.
프로세스 관리
virtual memory(가상메모리) vs physical memory
file system에서 실행파일 더블클릭 하면 메모리에 올라가면서 실행됨
근데 다안올라감, 가상메모리에 자기 자신만의 address가 만들어지고, 일부분만 physical memory에 올라가고 나머지는 swap영역으로감.
가상메모리는 0번지부터 쭉, 물리적메모리는 0번지부터 하나의 주소로 쭉
code data stack
가상메모리에서 각 프로세스의 code data stack
- code
cpu에서 수행해야할 기계어들이 들어있음-실제 실행 파일코드 - data
변수 배열 등등, 전역변수위치 - stack
지역변수, 함수 호출과 return에 관한 정보
커널도 당연히 code data stack이 있음
- code
운영체제가 자원을 잘 관리하기위한 로직이 code영역에 들어있음 ex) interrupt를 어떻게 처리할것인지, 사용자 프로그램이 사용 못하는 명령 IO같은 특권명령은 어떻게 수행할지 code - data
모든 하드웨어를 관리하기위한 자료구조,현재 실행중인 프로세스를 관리하기위한 자원구조(PCB) - stack
각 프로세스의 커널 스텍이 있다.
프로그램 A가 실행되다가 IO요청시 운영체제로 넘어와서 운영체제의 code가 실행됨(systemcall 어떻게 처리할건지 등)->근데 운영체제도 함수구조로 되어있음 -> 어떤함수가 다른함수 호출시 stack써야함 -> 다만, 프로그램 A때문에 OS가 호출된거면 A의 커널 스텍을 사용, 만약 B를 실행하다가 운영체제가 호출되면 B의 커널 스택을 사용
프로세스의 일생
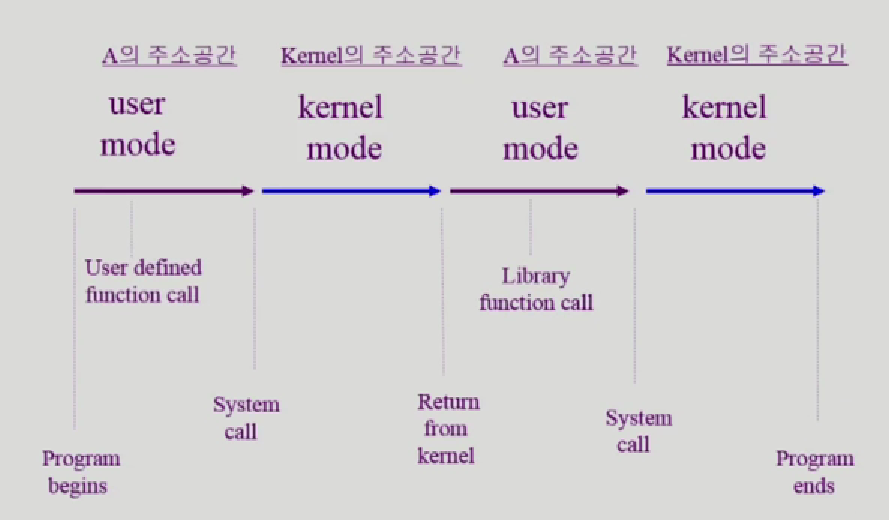
사용자 정의함수, 외부 라이브러리 call은 usermode에서 실행, IO작업을 하려면 systemcall사용 kernel mode로 커널의 주소공간으로 이동, IO작업 처리후 return해서 cpu를 다시 프로그램 A한테 줌
modebit 0이면 커널모드, 운영체제 처리 다 끝나면 1로 바꿔서 cpu를 사용자프로그램한테 넘김
프로세스 문맥이란?
프로세스 - 실행중인 프로그램
프로세스 문맥 - 특정 시점을 탁 짤라서, cpu의 상태를 나타내기 위한것, program counter가 어디를 가르키나? process메모리에는 무슨 내용이 담겨있는가? stack 영역에서 어떤 함수를 호출해서 어디까지 쌓아두었는가? 등등
PCB란?
커널도 code,data,stack이 있다.
여기서 code는 운영체제가 자원을 관리할때 사용되는 기계어가 들어가있고, 이것도 함수니까 stack에다가 함수 호출,return등을 써야한다.
data 영역에 이제 pcb가 저장된다.
pcb-운영체제가 각 프로세스를 관리하기위해서 각 프로세스마다 유지하는정보
왜 사용? 프로세스 A를 실행하다 뺏기고 다시 실행할때 프로세스 문맥을 저장해놓지 않으면 처음부터 다시 시작해야하니까.
프로세스식별자, 프로세스 상태, program counter, cpu 스케쥴링 우선순위 ,메모리관리정보, 입출력상태 등등의 정보가 있다.
다양한 프로세스 A,B,C가 syscall로 인터럽트 걸수 있으니까 각 프로세스별로 어떤 프로세스가 호출했는지에 따라 별도로 커널스택을 쌓는다.
프로세스의 상태는 어떤것이 있는가?
- running - cpu잡고 기계어 수행
- ready - cpu를 기다리는 상태 - 당장 cpu를 얻으면 기계어 수행가능, disk에서 file을 읽어오는것을 기다리는상태 x
- blocked(wait,sleep) - cpu를 줘도 수행이 불가능한 상태, IO 만족이 안되서 기다리는 경우
- new - 프로세스가 생성중인 상태
- terminated - 프로세스가 종료중인 상태
- suspended - cpu뿐만 아니라 외부에서 강제로 프로세스 정지 통채로 disk로 swap out됨
프로세스가 cpu를 언제 내놓는가
- 자진해서 프로그램이 끝나서 내놓는경우 - exit
- IO같은 오래걸리는 작업을 하러 cpu를 내놓는경우
- 더쓰고 싶은데 timer가 종료, timer Interrupt
문맥교환이란?
프로세스 A가 cpu잡고 실행 -> syscall, timerinterrupt 들어오면, 각 프로세스마다 커널 주소공간에서 Data영역에다가 각 프로세스의 PCB에다가 programCounter나 Register에 있는값을 기록 -> 다시 프로세스가 cpu를 얻게 되면 이 PCB정보를 가지고 복원해서 다시 실행
쓰레드란?
쓰레드란 프로세스내에서 실행되는 흐름중 하나이다.
프로세스마다 하나의 PCB가 만들어져서 운영체제가 관리, 프로세스 하나당 쓰레드가 여러개 있으면, CPU 수행과 관련된 정보만 각각 쓰레드 마다 별도의 카피를 가지게 됨, 이것이 programCounter나 register에 해당한다.
생각해보면 당연한게 각각 다른 code를 수행하고 그 수행한 값이 register에 담겨있으니까
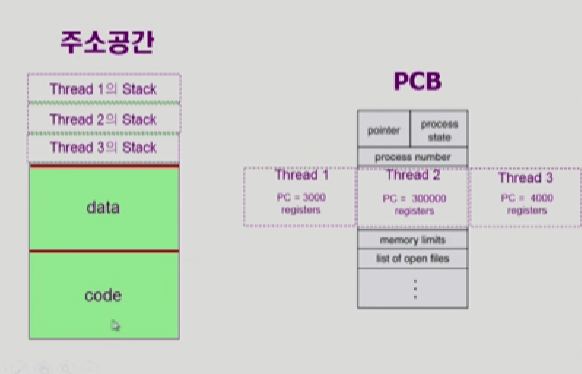
그림과 같이 PCB에서는 programcounter,register를 독자적으로 가지고 주소공간에서는 code와 data를 공유하고 stack영역만 독자적으로 가지고있다.
장점 4가지
응답성, 자원공유, 경제성(문맥교환비용 적음)
쓰레드 종류
커널쓰레드 -> 쓰레드가 여러개 있다는 사실을 운영체제 커널이 알고 있음, 하나의 쓰레드에서 다른 쓰레드로 넘어갈때 CPU스케쥴링 하듯이 넘겨줌
USER 쓰레드 -> 프로세스안에 쓰레드가 여러개 있다는걸 운영체제는 모르고, 라이브러리의 지원을 받아서 관리
쓰레드에 대한 더 자세한 내용
Process Management
프로세스의 생성
부모 프로세스의 주소공간이 있고, 운영체제에 있는 데이터들 pcb라던지 code data stack까지 싹다 자식이 복사한다. 그뒤에 덮어쓴다.
사실 write전까지는 동일하니까 부모의 code,data,stack을 공유하면서 쓰다가, write를 만나면 그때 복사해서 새롭게 만든다.
생성단계
1. fork
2. exec로 덮어쓰기
과제할때 이전 템플릿 가져다가 그다음에 제목 내용 바꾸는것과 비슷
프로세스의 종료
exit라는 시스템콜을 하면된다. 종료될때 자식이 부모에게 output-data를 보냄, 각종 자원들 반납
강제종료된는경우 - 자식이 할당 자원 한계를 넘어섬, 할일이 없는경우, 부모가 종료되는경우(자식을 전부 죽이고 부모가 종료)
Fork란?
fork실행시 자식 프로세스 실행 후 다음시점부터 실행
why? programcounter도 복사되는데 자식이 만들어지면 처음부터 안읽고 다음줄인 if문부터 수행 부모가 fork하면 자식 id는 0 부모 양수

exec
exelp 일종의 exec systemcall 함수 그럼 파라미터로 전달된 main으로부터 다시 실행.
그럼 그림과 같이 data라는 프로그램으로 덮어쓰는 형식

execlp 뒤의 코드는 실행 불가

파라미터 파일의 main부터 시작해서 끝나므로 이전으로 못돌아옴
wait
해당 프로세스를 blocked상태로 바꿈
보통 자식 프로세스를 만들고 부모가 wait systemcall을 함 언제까지? 자식이 종료될때까지. 종료되면 blocked에서 ready로 변화
IPC(프로세스간 협력 메커니즘)
message passing: 커널을 통해서 메시지 전달
프로세스 A가 B한테 메시지 보내고 이 메시지를 바탕으로 B가 무언가 수행
Direct coummunication : 목적지를 적어주면 커널을 통해서 메시지가 간다.
Indirect communication: mailBox에다가 메시지를 넣고 mailBox를 꺼내볼 수 있는 대상이 전부 메일박스에서 꺼내본다.
Shared memory
원칙적으로 각 프로세스는 독자적인 주소공간인 code,data,stack을 가지고 프로세스를 수행하므로, 자신의 주소공간만 볼 수 있는데
일부 주소공간을 두 프로세스가 공유하는 방식 그러면 공유 되는 메모리에 자원이 올라가면 그 자원은 프로세스 두개가 접근이 가능하다.
CPU Scheduling
I/O bound job vs CPU bound job
I/O bound job이 크다 -> 사람과 interactive 많음 -> I/O 횟수 많음 -> CPU burst time 짧음,횟수 많음
CPU bound job이 크다 -> 사람과 interactive 적음 -> I/O 횟수 적음 -> CPU burst time 김, 횟수 적음(행렬 1000*10000곱셈)
CPU 스케쥴링이 필요한 이유
CPU bound job이 큰애들이 한번 CPU잡고 안놔주면 너무 오래걸리니까
CPU scheduler & dispatcher
둘다 운영체제의 code에 적혀있다.(그래야 운영체제가 운영체제 code를 보고 CPU를 어떤 놈한테 줄지 결정할테니까)
CPU scheduler - Ready 상태 프로세스중에 어떤 놈한테 줄지 고르는거
Dispatcher-> 실제 선택된놈한테 넘기는 과정(context switch)
CPU 스케쥴링이 필요한경우
- Running -> Blocked (I/O작업)
- Running -> Ready (할당시간 만료)
- Blocked -> Ready (I/O 작업 완료후 인터럽트)
- Terminated (종료)
PreEmptive vs NonPreEmptive - NonPreemptive
강제로 뻇지 않고 자진반납 - Preemptive
강제로 빼앗음
그럼 어떤게 좋냐? Pre NonPre
선정 척도를 가지고 나눠보자.
시스템 입장 - CPU Utilization(CPU이용률)
중국집 오픈시간에서 주방장 일한시간 - Throughput
주어진 시간에 몇개의 작업을 수행? - 중국집에서 단위시간당 손님을 얼마나 받음?
**고객입장** - Turn around Time(반환시간)
CPU를 쓰러 딱 들어와서 다쓰고 나갈때 까지 걸린시간
손님이 중국집에 와서 밥먹고 나간시간
참고: main함수를 전부 끝내는 시간 x, 만약 cpu를 쓰다가 syscall 갈기고 Wait For IO 하러 ready queue로 이동했다면 이때까지의 시간이다.
즉, 매 CPU burst 건마다. wait For IO부터 Wait For IO까지 여러 프로세스가 번갈아서 뺏고 쓰고 뺏고 쓰고 하는 과정에서 얼마나 많은 프로세스를 처리했는지를 판별 - Waiting Time -기다리는시간
CPU를 쓰고자 하더라도 ReadyQueue에서 기다리는 시간
고객이 중국집에서 음식이 나올때까지 기다린시간 - Response Time
ready queue에 들어와서 처음으로 cpu를 얻기 까지 걸린시간
waiting time과 다른점이 io와 io사이에서 여러 프로세스들이 cpu를 돌려쓰는데
Wait For IO-process1-process2-process3-process1-process2 reauest IO- waitFOrIO
waiting time - prcess1이 사용을 하고 난 뒤에 process2,3이 반납하기를 기다려야하므로 process2가 1초 3이 3초를 쓰면 waiting time이 4초가 되는거고
response time - process1은 0초 2는 10초 process3은 20초가 될것이다.
CPU sheduling
- FCFS - 먼저온놈 먼저 처리
- SJF - 짧은 시간 걸리는 프로세스 먼저 처리, starvation 발생
preemptive버전: 내가 쓰고있는데 더 짧은애가들어오면 새로온놈한테줌
nonpreemptive버전: 더 짧은애가 들어와도 내가 안내놓음 - Priority Scheduling - 우선순위가 높은 프로세스한테 cpu줌
preemptive 버전: 나보다 우선순위가 높은애가 들어오면 뻇어서 새로 들어온놈한테 줌
nonpreemptive 버전: cpu를 쓰고있으면 우선순위가 높은얘가 들어와도 안줌
starvation발생 - Aging기법 도입 - 오래기다릴수록 우선순위를 높여줌 - Round Robin
Queue에 n개의 프로세스 q라는 시간을 사용하게 함 - 어떤 프로세스라고 (n-1)*q시간내에 cpu 맛봄 - response time 짧아짐
아주 짧은시간 프로세스쓰는놈들은 빨리 한번쓰고 나가버림, 긴놈은 썻다 뺏꼇다 반복 - Multi Level Queue
여러줄로 cpu를 줄서기, 하나의 큐가 아니라 여러개의 큐를 놓고 우선순위가 높은 queue부터 cpu를 할당, 우선순위가 높은 줄이 비어있으면 그 밑에 줄의 큐에서 꺼내서 처리
프로세스가 아에 설정된 줄에서 벗어나지 못하면 Starvation발생 FeedbackQueue이용 - Aging고 같음 오래기다리면 한줄 위로 올려줌
Multiple-processor Scheduling
CPU가 여러개 있는경우
각 CPU가 알아서 큐에서 프로세스 꺼내서 처리
반드시 특정 CPU에서 수행되야하는 프로세스 처리 복잡
Load Sharing - 일부 CPU에 job이 몰리지 않게 하기
SMP(symmetric multiprocessing) - 각 프로세서가 알아서 스케쥴링을 결정
Asymmetric multiprocessing - 하나의 프로세서가 시스템 데이터의 접근과 공유 책임, 나머지는 이것을 따름
Process Synchronization
Process Synchronization(동기화)가 필요한이유?
processA가 syscall을 해서 커널의 코드가 실행되고 커널에 있는 data값을 바꾸기위해서 읽어들이는 도중 cpu를 뺏기고 다른 프로세스가 또 syscall을 해서 커널의 코드를 실행하면서 커널의 data에 접근하는 경우
즉, userlevel에서는 독자적공간이므로 문제 x -> 커널에 있는 data는 여러프로세스들이 동시에 사용하는 공유데이터이므로 문제 발생
문제 3가지
1. Interrupt Handler vs kernel
운영체제 커널의 data에 count가 있음
count++은 1. 메모리에 있는 변수 count를 cpu 레지스터로 불러들이고 2. 증가시키고 3. register값을 다시 메모리에 적재함
근데 1번 읽어올때 interrupt가 들어와서 count값을 불러온다음에 다른 프로세스가 실행을 하면 이 프로세스의 값이 반영이 안됨
해결방법 - 작업이 끝날때까지 interrupt를 disable시킴
2. preempt a process running in kernel
Pa가 syscall을 하고 kernel mode에서 쓰고있다가 타이머 인터럽트가 걸림.
즉 커널의 data인 count를 증가시키는중 이었다.
그리고 Pb가 count++하고 Pa한테 cpu를 돌려주면 count가 2가 되야할거 같지만, Pb에서 count++한거 반영이 안됨.
왜? 이미 count값을 불러들이고 뺏긴거니까.
해결방법 - 커널모드에서 수행중일때는 CPU를 preempt하지 않음
3. Multiprocess
cpu가 여러개인경우 - lock고 unlock을 사용
매순간 한번에 하나의 cpu만 커널에 들어갈 수 있게하기
1). 커널 전체에 lock을 걸어서 cpu1이 커널에 들어갈때 lock걸고 cpu2는 못들어가고 cpu1이 나올때 unlock해줘야 들어감 - 커널 전체에 lock거는건 비효율
2). 커널 내부의 각 공유데이터에 접근할때, 그 공유데이터에 lock/unlock걸기
Critical-Section이란?
커널에 data에 count가 있다면 count 변수가 Critical - Section인게 아니라, 공유데이터를 접근하는 code가 크리티컬 sectino ex). count+=1;
Critical-section이 아닌 나머지를 remainder-section이라함
Process Sychronization 충족조건
1. Mutual Exclusion:상호배재
한 프로세스가 critical section에 있으면 다른 프로세스는 그 critical section에 들어가면 안됨
2. Process
아무도 critical section에 없으면 들어가고자하는 프로세스는 들여보내줘야함
3. Bounded waiting: 유한대기
critical Section에 들어가려고 너무 오래기다리면안된다. starvation이 없어야함
Critical - section 예시
피터슨 알고리즘
do{
flag[i]=ture; //나 들어가고싶어
turn = j; //상대를 확인하기위해
while(flag[j] && turn ==j); //상대를 확인
critical section
flag[i]=false;
remainder section
}while(1);process i가 critical Section에 들어가려하면, 깃발을 true로 세워서 나 드가고싶어, 상대를 확인하기위해서 turn을 바꾸고 critical Section앞에 while문에서 상대의 flag과 turn을 확인 만약 turn과 flag가 1이라면 상대가 쓰고있으니까 while문에서 뺑뺑돌면서 대기,
그다음 critical section쓰고 flag를 false로 만듬
문제점: spinlock cpu와 메모리를 쓰면서 계속 wait
해결법
read instruction
cpu interrupt
write instruction
이 방식이라 문제,
고로 하드웨어를 하나 둬서 read instruction write instruction이 하나의 instruction으로 수행되게 함
예를들어, a를 읽으면 동시에 하드웨어가 a값을 true로 바꾸는것
do{
while(Test_and_Set(lock))
critical section
lock = false;
remainder section
}현재 0인상태에서 while문을 돌면서 Test_and_Set에서 0을 읽고 1로 바꿈, critical section으로 들어가면 다른놈은 내가 1이라 들어오지못하고 while문에서 대기, 내가 나와서 lock을 false로 바꿔줘야함
Semaphore란?
추상자료형
P: 공유데이터를 획득하는 과정
V: 공유데이터를 다쓰고 반납하는 과정
S: 자원의 갯수

critical section에 들어갈 수 있는 프로세스는 1개 mutex를 1로 설정
P연산을통해 0으로 만들고 나오면 V연산으로 1로 만들어서 critical Section접근
근데 이것도 while문을 돌듯이 기다려야하니까 애초에 그냥 프로세스를 Block시키는게 효율적
typedef struct{
int value;
struct process * L;
}semaphore;value는 세마포어값, L은 BLock되어서 기다리고있는 queue
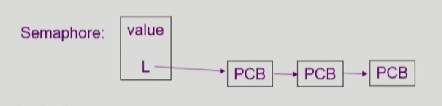
P(S): s.value--;
if(S.value <0) 해당 프로세스 s.L;, block();V(S): s.value++;
if(s.value <=0) S.L에서 P제거
wakeUp(P);Synchronization의 문제 3가지
Bounded - Buffer Problem
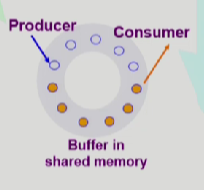
생산자: 버퍼의 비어있는 갯수가 자원의 갯수
소비자: 내용이 들어있는 버퍼의 갯수가 자원의 갯수
semaphore full - 0
semaphore empty - N 처음에는 다 비워져있으니까
Producer
do{
P(empty)
P(mutex)
add x to buffer
V(mutex)
V(full);
}while(1);생산자는 빈버퍼가 있는지 확인, P(mutex)로 lock걸기 mutex는 1이므로 하나의 프로세스만 접근가능
Consumer
do{
P(full)
P(mutex)
remove an item from buffer Y
V(mutex)
V(empty)
}while(1);Reader - writer Problem
공유 데이터를 DB, Read는 동시에 해도됨 , 한 프로세스가 DB에서 write하면 다른 프로세스는 접근 못하게 막기
readcount: 현재 DB에 있는 Reader수
mutex : 공유변수 readcount를 접근하기 위해서 lock을 걸때 사용
db: reader와 writer가 DB를 올바르게 접근하게 하는역할
Writer
P(db)
wirting DB
V(db)P(db)로 lock을 걸고 누가 들어가 있으면 P연산 통과못하고 대기
그후 write하고 V연산을통해서 lock을 품
Reader
P(mutex);
readcount++;
if(readcCount==1) P(db)
V(mutex);
reading Db is performed
P(mutex);
readcount--;
if(readcount==0) V(db)
V(mutex);일단 Reader입장에서도 DB에다가 lock을 걸어야한다. 왜냐하면 Lock을 안걸고 그냥 디비 접근해서 읽으면 Writer가 P(db)했을때 lock안걸려있으니까 reader가 있던말던 쓸것이기 때문이다.
그렇기 때문에 P(db)를 하기위해서 공유변수 readCount를 사용한다.
readCount또한 공유변수기때문에 mutex를 사용한다. mutex는 1,0이라 한 프로세스만 접근이 가능하다.
Starvation문제가 생긴다.
10명이 들어와서 읽고있는데 9명이나가고 1명남아있는데 이제 DB가 슬슬 쓰려고 하니까 100명의 reader가 또들어오면 이제 나갈때까지 계속 기다려야한다. starvation발생가능
Dining-Philosophers Problem
5명의 철학자가 원탁에 앉아서 식사를 하는데 꼭 포크는 두개를 들고밥을 먹어야한다.
1. 왼쪽 포크가 사용 가능할때까지 생각을함, 사용 가능해지면 집어듬
2. 오른쪽 포크가 사용 가능 해질때까지 생각을함, 사용가능하면 집어듬
3. 양쪽 포크를 잡으면 정해진 시간만큼 식사
4. 오른쪽 포크 내려놓기
5. 왼쪽포크 내려놓기
해결방안
젓가락을 두개 모두 집을 수 있을때에만 젓가락을 잡을 수있게, 하나만 잡을 수 있으면 젓가락을 잡는 권한을 부여하지 않음
비대칭 - 짝수 철학자는 왼쪽 젓가락부터집고, 홀수 철학자는 오른쪽 젓가락부터집음
monitor 사용
모니터 내부에 공유변수와 공유변수에 접근할 수 있는 operation을 둔다.
이 operation은 동시에 수행이 안되므로 우리가 직접 lock을 걸지 않아도됨
- ConditionVariable
x.wait() x라는 condition variable에가서 줄을 섬 - 오래기다려야할때 프로세스 잠들게 하기위해
x.signal() 누군가 x다 써고 나가서 condition variable에서 자고있는놈 깨워서 데려오라는거

test에서 보면 자신이 일단 hungry인지 확인 왼쪽,오른쪽 젓가락을 집을수있는지 확인 if문 통과하면 상태바꾸고 self[i].signal()호출 혹시 i번째 철학자가 잠들어있으면 signal로 깨워줘라, 근데 지금 젓가락 집으러 들어왔는데 잠들어있을수가 없다. 지나간다.
다시 돌아와서 test 상태가 eating이니까 if문안들어가고 통과 못했으면 wait로 바꿔서 기다린다.
putdown도 동일하다 thinking으로 바꿔주고 test메서드를 내 양 옆의 철학자를 실행하는데 내가 젓가락을 내려놓는것이기 때문에 혹시 내 인접 철학자가 내가 밥먹느라 기다리고 있으면 안되니까 깨워주기 위함이다.
DeadLock
DeadLock이란?
프로세스들이 서로가 가진 자원을 기다리며 block된 상태
DeadLock 발생 조건 4가지
1. Mutual Exclusion- 상호배제
매순간 하나의 프로세스만 자원사용가능
2. No Preemption
비선점 프로세스는 자원을 스스로 내어놓지 뺏기지 않음
3. Hold and Wait - 보유대기
자원을 가진 프로세스가 다른 자원을 기다릴때 보유 자원을 놓지 않고 계속 가지고 있음
4. Circular Wait - 순환대기
자원을 기다리는 프로세스간에 사이클 형성
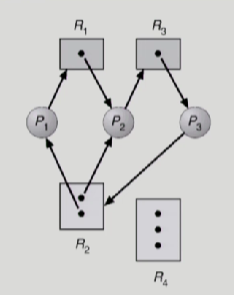
자원 할당 그래프란?
cycle생성여부에 따라 deadlock판단
자원당 instance가 1개면 deadlock, 많은 instance가 있으면 deadlock 아닐 수 있음
deadlock
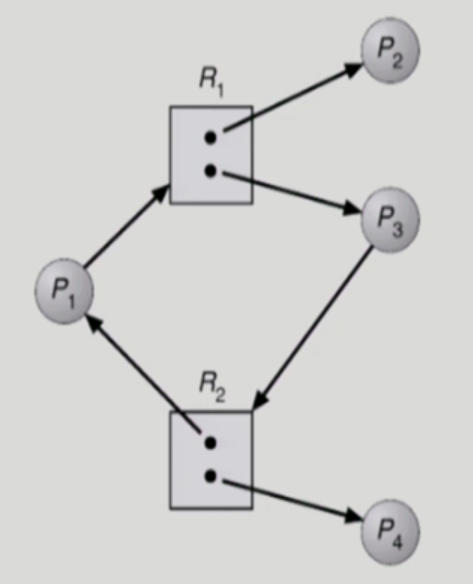
deadlock X
DeadLock 처리방법
-
Deadlock Prevection
deadlock의 4가지 조건중 하나를 원천적으로 차단해서 안생기게함
MutualExclusion: 애초에 공유자원에서 문제가 생기므로 해결방법x
Hold and Wait: 자원이 필요한 경우 보유자원을 모두 놓고 다시 요청
No preemption: 자원을 기다려야하면 자원을 뺏어올수있게함
Circular wait: 항상 정해진 순서대로 자원할당 내가 4번 자원을 가지고 싶으면 1,2,3번 자원을 가져야만 4번 요청가능 -
DeadLock Avoidance
프로세스가 시작부터 종료까지 자원 최대 사용량을 안다고 가정하에 Deadlock방지
자원이 1개있는경우: 앞에서 배운 Resource Allocation Graph Algorithm사용
자원이 여러개 있는 경우 Banker's Alogrithm사용
Banker's Alogrithm이란?

Need를 Available이 줄수있는지 확인하고 주기, P1은 1,2,2라서 Available가능, P0가 A 1개만 요청하더라도 Available에서는 가능할지라도 Need의 총갯수를 만족x이기 때문에 요청 받지않음
Deadlock Detection and Recovery
- Deadlock Detection
- 자원이 1개있는경우 - 자원할당 그래프로 사이클 생성 유무로 확인
- 자원이 여러개있는경우 - Table을 그려서 Deadlock여부 판단
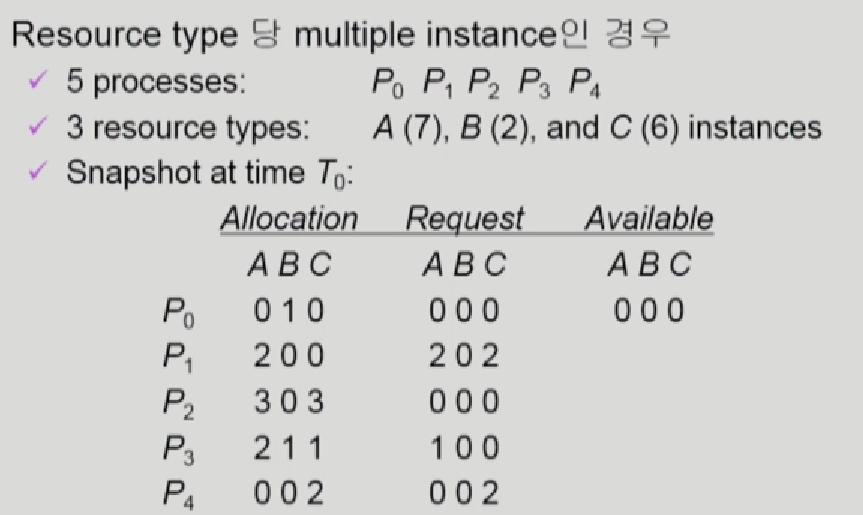
available이 0,0,0이지만 P0와 P2가 자원을 반납한다고 가정하고 available을 3,1,3으로 만든다음에 Request를 판단한다.
그런데 갑자기 P2가 C를 1개 요청한다면 지금 현재 available이 갑자기 P0만 반납하니까 0,1,0으로 줄어들게 되면 P1,2,3,4 전부 요청을 받아들이지 못하는 DeadLock발생
- Recovery
- DeadlockProcess 전부 죽임
- 하나씩 Deadlock Process를 죽여보면서 Deadlock 풀리는지 확인
- 비용을 최소화 할 victim을 선정, 자원을 뺏어서 deadlock풀기
그러나 계속 victim으로 선정되면 starvation 고려
Deadlock Ignorance
대부분 OS가 채택하는방식
DeadLock 자체가 애초에 드물게 발생, 예방,해결조치가 더 큰 오버헤드
그래서 안일어난다고 가정하고, 발생하면 User가 process 직접 kill
Memory Management
Logical address vs Physical address
Logical address(가상메모리): 각 프로세스마다 독립적으로 가지는 주소공간,
각 프로세스마다 0번지 시작, cpu가 보는 주소는 logical address이다.
Physical address: 메모리에 실제 올라가는 위치
주소바인딩: 주소를 결정하는것 int a = 3; 이건 symbolic address이고 이걸 physical address로 변환이 일어는과정을 주소바인딩이라함
Binding의 종류
- Compile time binding: 컴파일 시점에 미리 실제 물리적 메모리에 올려야할 주소를 결정 -> 하나의 프로세스밖에 사용 못함 -> 논리적주소는 항상 0번지부터시작인데 이미 하나 올라가면 다음 프로세스의 0번지는 안비어있음
- Load Time Binding: 컴파일 타임에는 논리적 주소만 결정(0,10,20) 그다음 실행할때 메모리가 500번지부터 비어있으면 이때 밀어넣음
- Run time Binding: 실행되는 도중에 주소가 그때그때 바뀜. 300번지에 넣었다. 메모리에 쫒겨났다가 700번에 올라오고 이런식
MMU란?
하드웨어 디바이스
Logical address를 Physical address로 매핑시켜줌
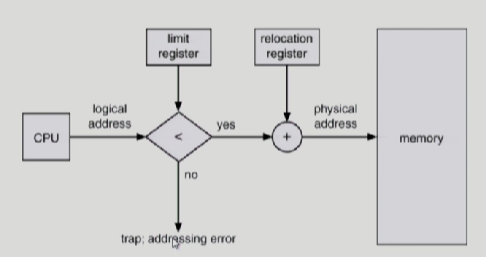
limit register(3000)가 먼저 더 큰 주소공간을 요청한게 아닌지 확인
relocation register(1400)에서 요청주소를 더해서 physical memory에서 확인
Allocation of Physical Memory
앞에서는 이제 MMU를 통해 논리적 주소를 물리적 주소로 바인딩 하는걸 알아봤고, 이제 physical memory에 어떻게 올려놓을건지 알아 볼것임
- Os상주영역 - 낮은 주소 사용
- 사용자 프로세스 영역 - 높은 주소영역 사용
할당방법 두가지
1. Contiguous Allocation - 메모리에 올라갈때 통채로 올라감
2. Non Contiguous Allocation - 프로그램의 일부마다 서로 다른 위치의 메모리에 올라감
Contiguous Allocation
- 고정분할 방식
미리 메모리를 파티션 해놓고, A,B를 파티션에 맞게 할당하는 방법
외부조각: 프로그램이 파티션보다 커서 못들어가고 남은 조각
내부조각: 프로그램이 파티션보다 작아서 생기는 남는 조각 - 가변 분할 방식
프로그램이 실행될 때 마다 차곡차곡 메모리에 올려둠,
만약 A,B,C,D순서로 실행되는데 C가 끝나고 B가 나감
그럼 D를 B자리에 올릴라했는데 size 매치 안되면 C뒤에 놓음
남은 B자리가 Hole이 됨
Non Contiguous Allocation
- Paging
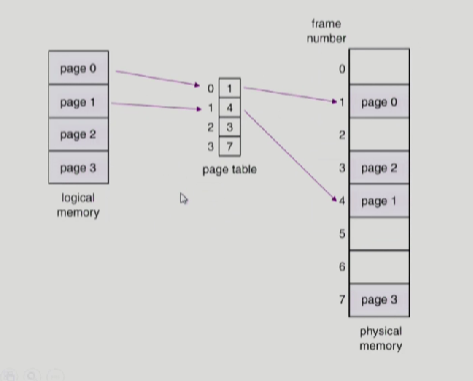
주소변환을 위해서 page table 사용.
논리적 메모리를 동일한 크기의 페이지로 짜르고, memory에서 비어있는 공간 어디던지 밀어넣음
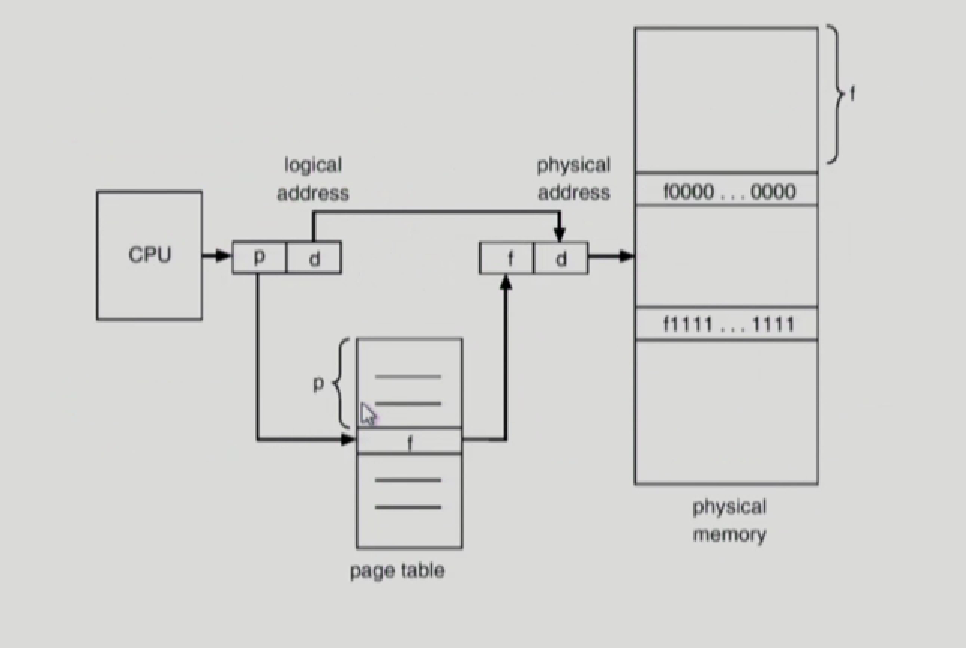
d는 논리적인 페이지 내에서 얼만큼 떨어져있는지 나타내는 offset
어차피 논리적인 페이지의 size나 물리적 페이지의 size가 동일하므로
page를 frame으로만 바꾸면, d는 변화 x
Page table
Main memory에 있음
모든 메모리 접근연산에는 2번의 메모리 access 필요, 속도 향상을 위해서 TLB사용
TLB
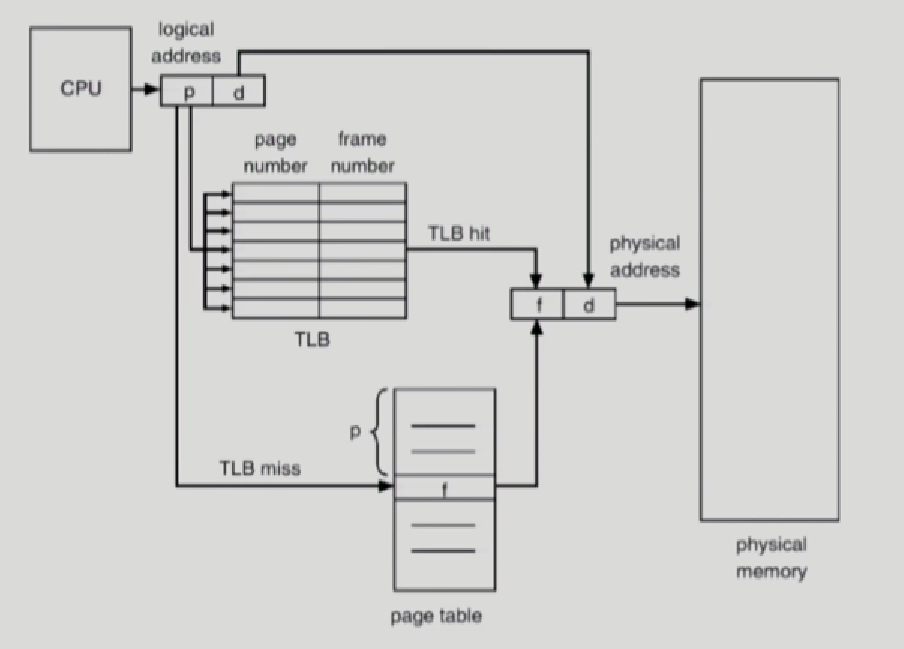
주소변환을 위한 캐시 메모리,
Page table에서 빈번히 참조되는 일부 엔트리를 TLB에서 캐싱하고있음
1. TLB에 있는경우 -> TLB에 접근해서 바로 주소변환을 한다. -> 메모리에 접근 1번
2. TLB에 없는경우 -> pageTable을 통해서 주소변환 -> 메모리에 접근 2번
TLB는 병렬탐색가능, page talbe에서는 탐색이 애초에 필요가 없음. 배열형태라 p라는 index에 가보면 frame number존재
Effective Access Time
a: hit ratio
e: look up time
메모리 접근시간 1
EAT = (1+e)a + (2+e)(1-a) = 2 + e -a
Two-Level Page Table
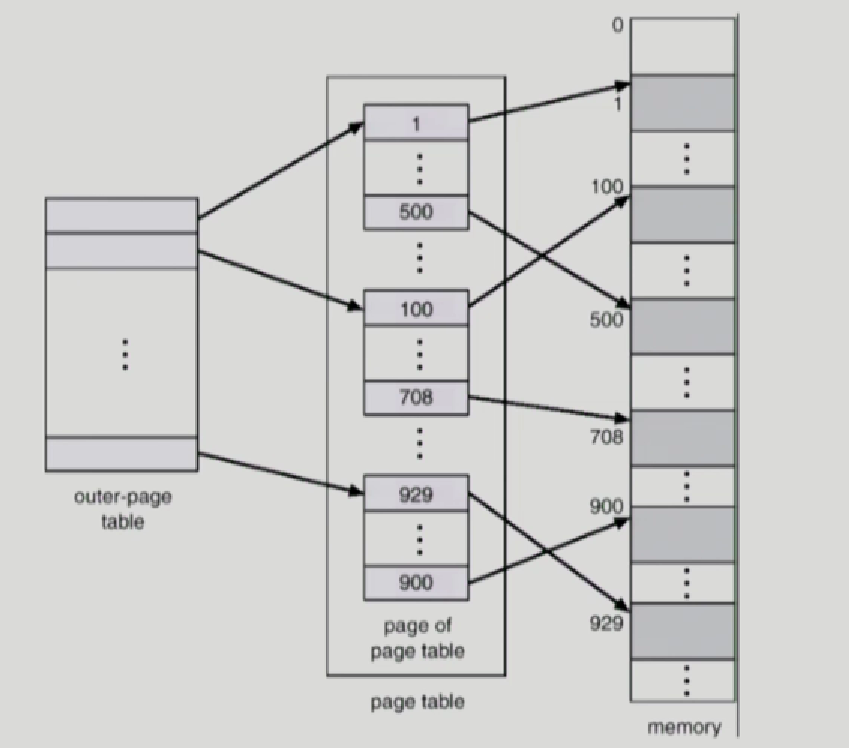
32bit 주소공간 가정 -> 0~2^32-1번지 -> 4G의 주소공간
하나의 프로세스마다 4G차지,하나의 page마다 4k라 가정하면,1M개의 page table entry 필요
근데 가상메모리에서 사용하는 공간은 극히 일부분, page table공간 낭비 심함
이전에는 서울 하나였지만 2단계로 서울 강남구 11-2번지로 paging
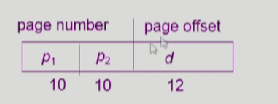
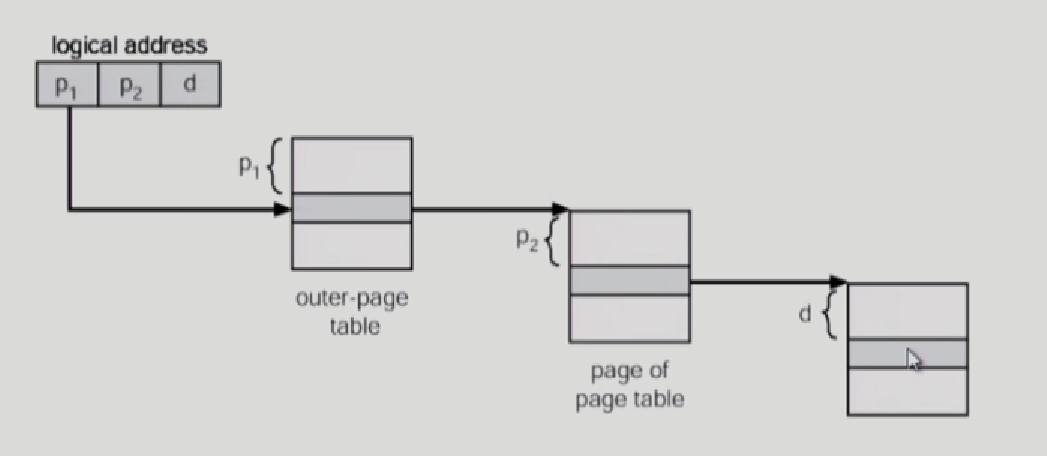
바깥 페이지에서 찾는게 p1-> 안쪽 page tablㄷ에서 어던 페이지에 해당하는지 찾고 -> 안쪽 page table에서 pageframe번호를 찾아서 p1,p2에다가 덮어씌우면 physical address얻을 수 있음
Multilevel Paging and Performance
2단계가아니라 MultiLevel도 가능
4단계면 memory access가 5번이고
TLB hit ratio가 98%, 메모리 접근시간은 100ns, tlb접근시간은 20ns라 가정한다면, effective memory access time = 0.98 120 + 0.02(1005+20) = 128ns가 된다.
메모리 접근시간이 100초라고 하면 28ns밖에 걸리지 않으므로 효율적이다.
valid/invalid
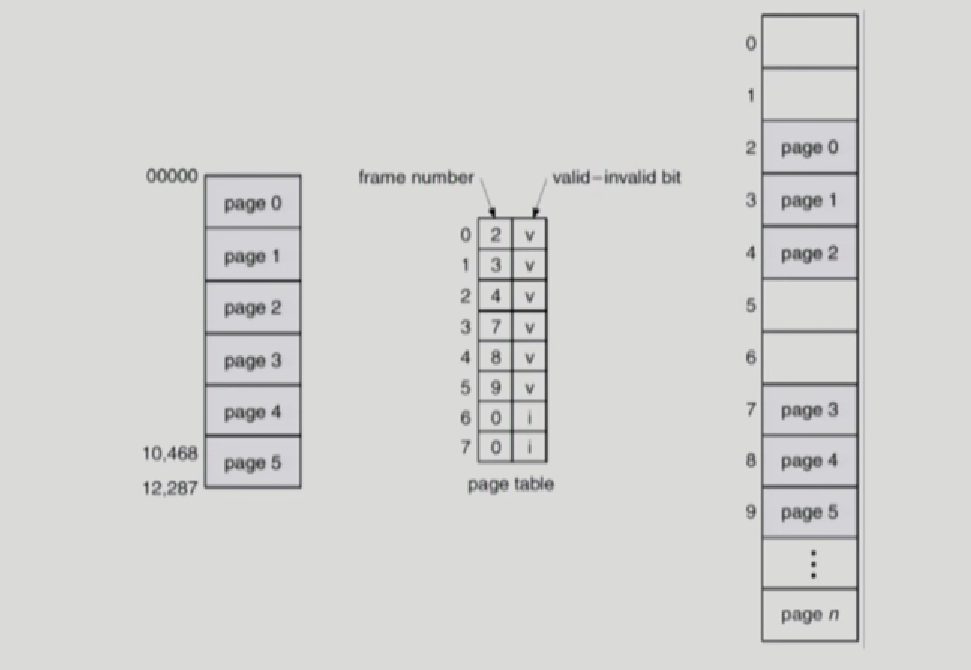
페이지 테이블에서 부가적 비트 하나 더있음
상위 부분에 code,data구정 중간에 쭉 null 아주아래에 stack 있음
사용하지 않는 페이지도 , page table에서는 엔트리가 만들어져야함
-> 왜냐하면 페이지 테이블 자료구조상 위에서부터 index접근하기 때문
그림처럼 page 6,7이 없더라도 page table에는 만들어지고,
6,7번 페이지에 해당하는 frame 넘버가 0 이더라도
이게 null이라 0 인건지 실제 frame number가 0인건지 구분하기위해서 valid bit사용
Protection bit
page 접근권한 read/write/read-only
Inverted page table
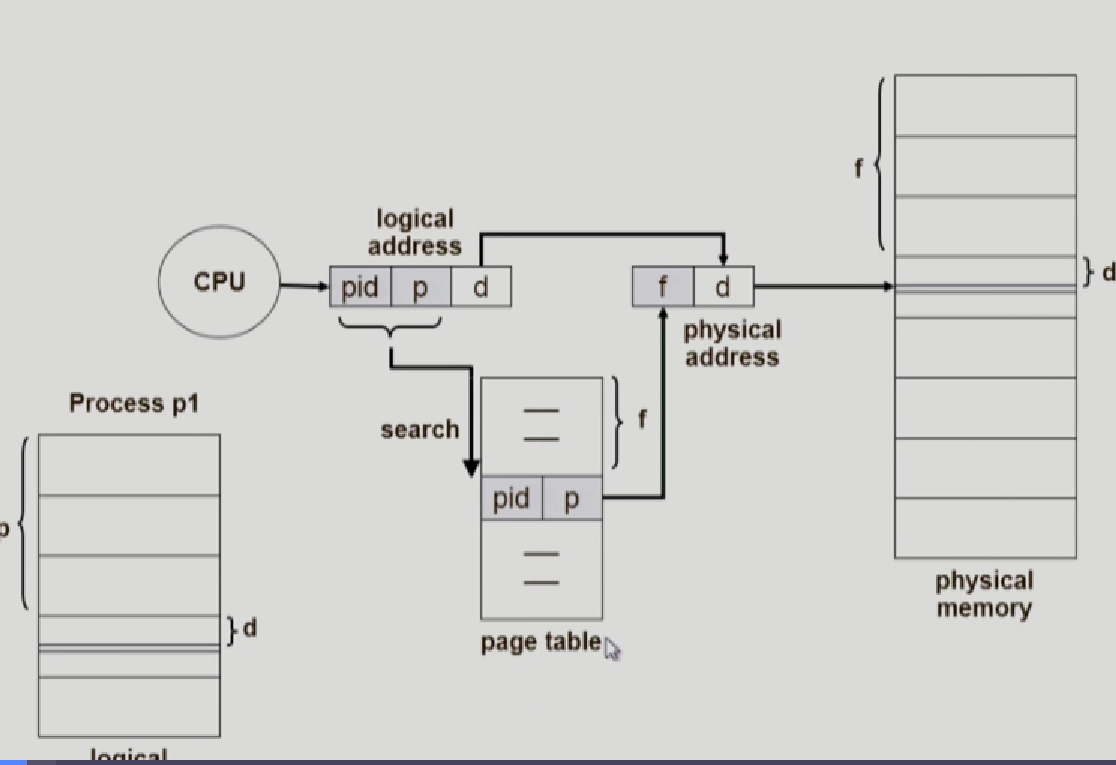
지금까지는 각 프로세스마다 page table이있었음.
이제는 시스템 안에 페이지 테이블이 딱 1개 존재
physical memory의 frame갯수만큼 page table에서 엔트리 갯수가있음.
page number는 다른 여러개의 process가 있을 수 있으므로 pid를 같이 저장해서 어떤 프로세스의 page number인지 확인
f를 구하고 physical address f/d로 변환
이전에는 index 접근이므로 탐색시간이 없었지만, 이제는 pid에 해당하는 걸 탐색으로 찾아야함.
그래도 page의 저장공간을 줄이므로 이득
Segmentation
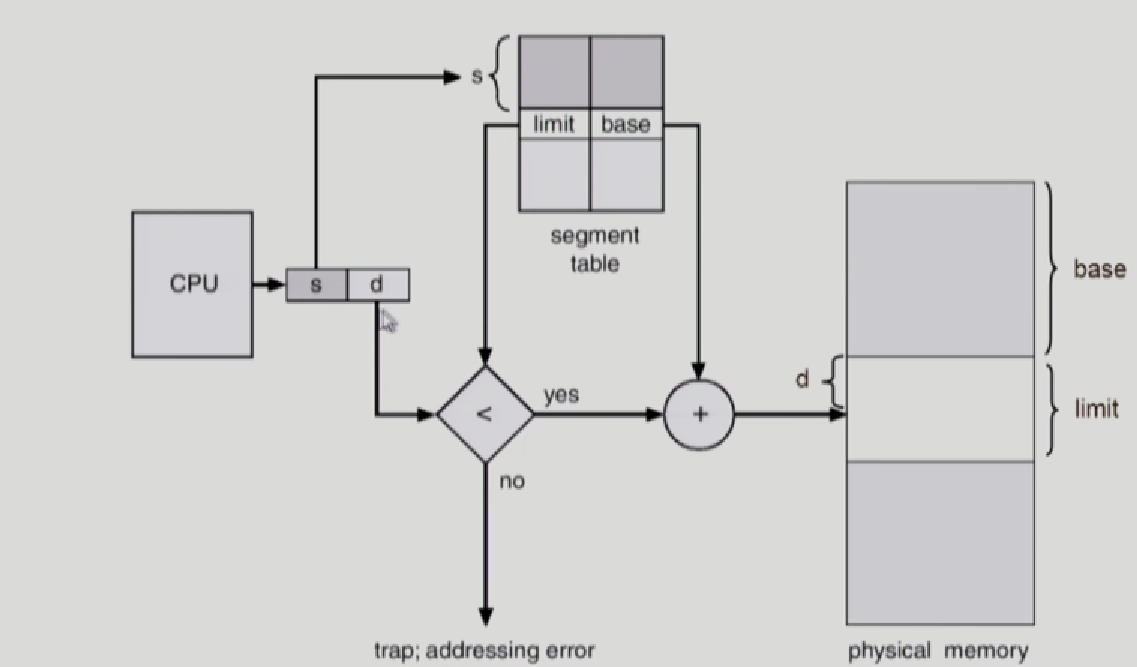
하나는 segment번호, 다른 하나는 그 세그먼트로부터 떨어진 offset
segment table 시작 위치는 register가 가지고 있음
STBR 레지스터: segment table 자체가 어디에 있는지 확인
STLR 레지스터 : segment table 길이가 얼만큼인지 확인
base: segment의 시작위치
limit: segment의 길이를 나타냄
두가지 체크
1. segment번호가, Segment-table length register(STLR)보다 작은지 확인
2. limit보다 d가 크지 않은지 확인
Paging vs Segmentation
page: offset의 크기가 page크기(균일)에 의해 결정
segmentation: d라는 offset의 길이가 32bit이내면 전부 가능
page: 시작주소가 frame으로 주어짐
segmentation: segment마다 크기가 다르므로 정확한 base의 위치가 필요, 크기가 다 다르므로 hole이 생김
Segmentation 장점
1. 크기가 가변적이므로 , read/write/execution등 의미 단위로 짤라서 메모리에 올릴 수 있음
2. 어떤 프로세스와 주소공간을 공유할때 의미 단위로 해야지 동일한 크기단위로 짜르는건 의미가 없다.
Segmentation with Paging 혼합기법
segment 하나가 여러개의 page로 구성되어있다.
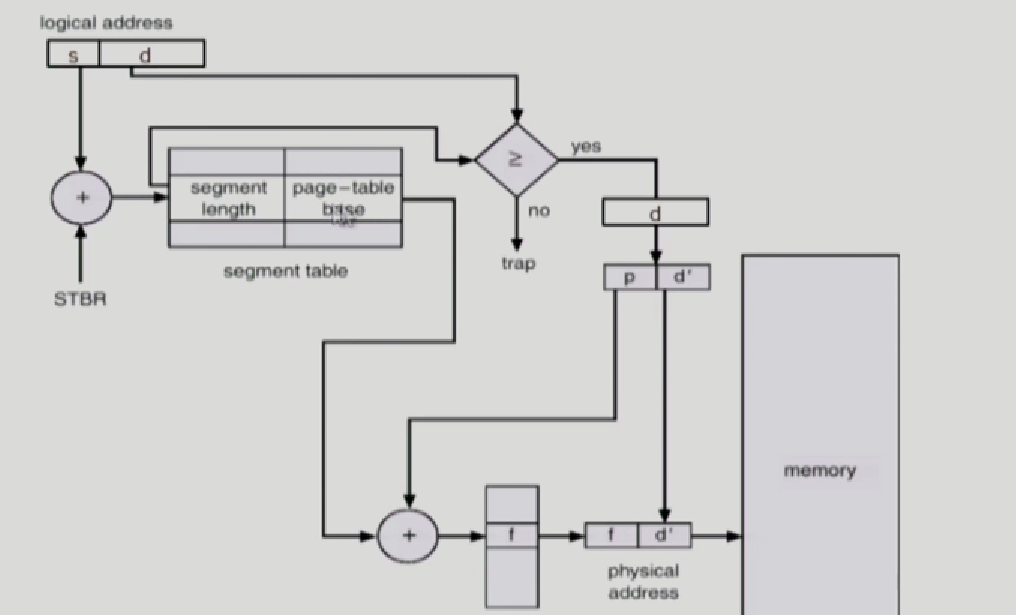
segmentation의 단점인 hole을 방지하기 위해서
하나의 segment에 각 페이지가 구성되어있고 메모리에 올라갈때는 각 page단위로 쪼개져서 올라간다.
자 s/d를 얻었다 치자 그러면 STBR에서 segment table 확인후에 하나의 segment가 페이지 여러장으로 쪼개지니까, page table을 얻는다.
그다음에 d를 p/d'로 짤라서 앞부분은 페이지 번호 d'는 이 페이지에서 얼마나 떨어졌는지 offset으로 쓴다.
그래서 page table에서 p로가서 frame넘버인 f를 찾고 f/d'로 physical address를 구한다.
중요
지금까지 논리적 주소에서 물리적 주소로 변환하는 모든 과정은 OS가 전혀 관여하지 않는다.
이건 MMU라는 register 하드웨어가 해주는것이다.
생각해보면, 프로세스가 cpu를 잡으면서 주소변환을 할때 OS가 해주면 CPU가 OS로 넘어가게되는데, 이건 말이 안된다.
고로, physical address로 변환은 register가 관여하고, virtual memory에서 OS가 관여하다.
Virtual Memory
Page fault란?
앞에서 page table에서 valid/invalid bit이 있다고했는데 모든 page들을 한꺼번에 memory에 올리는것 x -> 일부 올리고 필요할때마다 backing store에서 가져와서 올림
invalid page에 접근 -> MMU가 Trap 발생 -> CPU가 운영체제로 넘어감(해당 프로세스 block) -> 커널모드로 들어가서 pageFault handler실행 -> disk에서 해당 page read -> page tables entry에 기록하고 valid로 변경 -> ready queue로 process insert-> 다시 running
Free frame이 없는경우
page table이 꽉차면 replacement필요
victim을 선정하고 backin store로 swap out, 만약에 disk에서 올라온뒤로 write했으면, backing store로 가서 write해주고 swap해야함
그리고 쫒아낸놈 자리에 요구한 page를 들고와서 frame번호와 valid bit설정
어떤 놈을 쫒아낼까?
-
Optimal Algorithm
가장 적은 page fault 발생
이론적인 내용, 가장 먼 미래에 참조되는 page를 replace(실제로 미래에 참조되는 페이지는 알지 못함)
다른알고리즘의 upper bound제공 -
FIFO Algorithm
먼저 들어온걸 먼저 내쫒음
frames를 늘릴수록 오히려 page fault가 더 많이 발생 -
LRU
가장 오래전에 참조된걸 내쫒음
구현 -> Linked LIst 쵠근에 참조한것은 그냥 맨처음 head로 이동, 쫒아내려고 하면 그냥 tail에 있는것 쫒아내면됨 -
LFU
참조 횟수가 가장 적은 페이지를 지움
단점: 최근에 많이 슬슬 참조되는 페이지를 반영하지 못한다.
구현: 이건 탐색을해야함 head부터 끝까지 나보다 더 많이 참조가 일어났는지 판단해야하니까. 그래서 List형식이아니라, Heap으로 구현
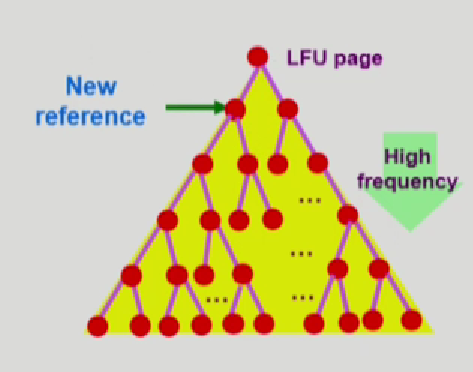
그러면 List처럼 다 뒤지는게 아니라 자기 직계 자식하고만 비교 -
중요: 근데 결국 LRU LFU못씀 왜? OS가 가장 오래전에 참조된 페이지, 가장 적은 참조횟수를 가진 Page를 알지 못하기 때문
Why?
-
Physical 메모리에 이미 올라가 있는 경우: OS가 관여하지 않으므로 언제 올렸는지, 몇번 참조되었는지 알 수 없음
-
없어서 운영체제로 넘어간경우: 그때 Backing store에서 메모리로 가지고올라옴
결국 OS는 반쪽짜리 정보만 가지고 있음
- Clock Algorithm
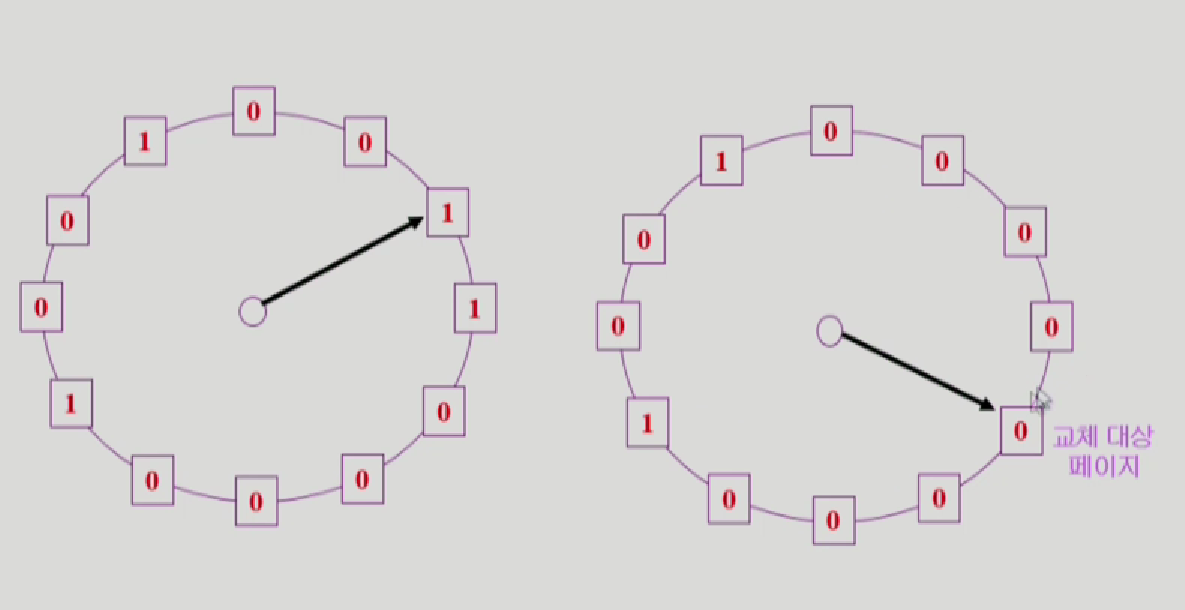
사각형이 page fram
valid라서 이미 메모리에 올라와있으면 page를 읽으면서 reference bit을 1로 바꿈
page fault 발생하면, reference bit이 1이면 0으로 바꾸고 넘어가고, 0이면 교체대상 페이지가 됨
modified bit: 교체대상 페이지중에 write발생안한(0bit)페이지는 그냥 쫒아냄, 1이면 backing store에 바뀐내용 저장 하고 쫒아냄
Replacement
Global Replacement: Replacement를 하면서 자동적으로 page frame이 조정이 됨
Local Replacement: 자신에게 할당된 frame내에서만 replacement
Thrashing
CPU Utilization이 올라가다 어느순간 뚝떨어짐
process한테 page frame이 너무 적게 할당되는경우
한프로세스가 page찾으러 IO가고 또 다른 프로세스가 page찾으러 IO가고 cpu가 노는 상황발생
OS는 CPU가 계속노니까 프로세스 추가 -> 프로세스당 할당되는 frame수 감소
Working-set Algorithm
각 프로세스마다 어느정도 frame을 메모리에 올릴지 결정하는 알고리즘
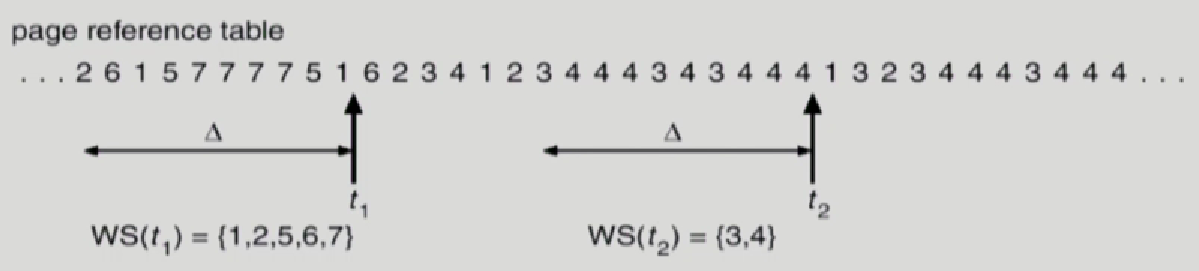
델타시간 동안 참조된 페이지 12567을 메모리에 전부 올려놓을 수있으면 올려놓고, 전부 올리지 못한다면 전부다 disk로 swap out하고 프로세스를 suspended시킴
t1,t2시점마다 윈도우를 미니까 working set이 바뀜 working set에 속한 page만 유지
Page Size 결정
요즘은 page를 키우고 있음
page 크기가 작으면 -> 잘게 썰수록 page fault 많이 발생 -> Disk에서 seek빈도 증가 -> seek는 매우 오래걸림
File and File System
파티셔닝이란?
하나의 디스크안에 여러개의 파티션을 둔다. 각 파티션마다 file system을 깔거나 swapping등 다른 용도로 사용가능.
open("/a/b")
Open()은 메모리에 파일의 메타데이터(저장위치등, 파일에 대한 정보)가 올라가는것이다
루트의 metada는 알고있으므로, Open file table에 올림 -> 실제 content찾으러감 -> a의 메타데이터 찾고 table에 올림 반복
b 메타데이터는 해당 프로세스의 PCB에 fire descriptor로 저장.
그러면 이제 fd = open("/a/b")하면 해당 프로세스의 pcb에 있는 fd index로 접근가능
핵심
버츄얼 메모리와 다르게 read,write던 systemcall 방식이므로 어떤 요청이던 운영체제가 처리 -> LRU같은 알고리즘 쓸수 있음
Protection
누구한테 권한을 줄것인가 -> Grouping
전체 user를 owner,group,public 세그룹으로 구분 3비트 표현
rxxr r-- r--
Mount
하나의 물리적 디스크를 파티셔닝을 통해 각 논리적 디스크 1,2,3으로 나눔
각 disk마다 file system 설치, 하나의 파티션에서 다른 파티션으로 접근하기 위해서 mount사용해서 연결
디스크에다 파일 설치하는방법
- 연속할당
file A가 start 5 길이3이면 5,6,7저장 -> blank 생기고, grow 제한 - Linked Allocation
start 9번이면 다음 블럭위치를 해당 9번 블락에 저장 - Indexed Allocation
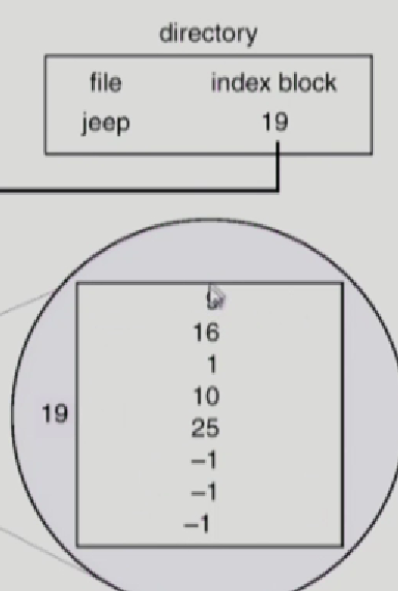
index block을 지정 해당 index block에는 파일 조각들이 있음, 외부조각 안생김, 직접 접근가능, 단점: small file인경우 index block만들필요없는데 만듬
Fat file system
메타데이터 일부를 FAT에다가 저장.
원래는 data block에 있는 directory file이 메타데이터를 가지고 있음
Fat다가 다음에 오는 블락의 위치를 저장.
217번 출발 -> 217번 블락의 data 확인 -> FAT으로 가서 217번 다음 블락의 위치를 찾고 -> 616이니까 다시 block 616으로와서 data확인
장점: direct 접근가능, FAT은 아주 작은 Table이므로 Disk전부 seek안해도됨
Directory 구현
file의 메타데이터를 디렉토리에 저장하는데, 디렉토리에는 해당 메타데이터의 주소인 포인터를 두고 다른곳에 보관하는 방법 ex) inode, FAT
file에도 cache가 있다!
Page cache는 이전에 배워서 안다. 당장 필요한 부분만 table에다 올리고 필요할때마다 가져다 쓰는거 이걸 cache관점에서 page cache라고 한다.
buffer cache
Disk에서 file을 가져오면 OS가 커널 메모리 영역에 카피를 해두고 사용자 프로그램한테 전달. 동일한 file요청이오면 disk까지 안가고 처리
Memory-Mapped I/O
프로세스의 주소공간 일부에다가 file을 mapping해두는 것이다.
다시 file을 접근시 Disk접근이 아닌 메모리 접근 연산을 통해서 파일 입출력을 수행한다.
Disk Management and Scheduling
Disk Access time의 구성
Seek time-헤드를 해당 실린더로 움직이는데 걸리는시간
Rotational latency - 헤드가 원하는 섹터까지 도달하는데 걸리는 회전 지연시간
Transfer time- 데이터 전송시간
Disk Scheduling Algorithm
FCFS - 들어온 순서대로 처리
SSTF - 현재 헤드에서 가장 가까운 위치 요청처리 - starvation
C-Scan - 다른쪽 끝에 도달시 곧바로 출발점으로 이동해서 처리
N-Scan - 가는 도중에 요청이 들어오면 처리하지 않고, 다음번에 처리
C-Look - 끝까지가서 arm을 턴하는게아니라 요청까지만 처리하고 turn함
