- https://arxiv.org/pdf/2207.12598
- 2021, 12
- 3300회 인용
- 분류기-비의존적 확산 가이던스 (CLASSIFIER-FREE DIFFUSION GUIDANCE)
- 이해도: 하
- 필요 시, 지속적 업데이트 예정입니다.
-1. 3줄 요약
- classifier-guidance 는 평가 metric 점수가 잘 나오도록 직접적으로 가이드하지만, 막상 생성된 조건부 데이터의 quality는 별로일 수 있다는 문제를 제기함
- classifier를 별도 학습 및 사용하지 않아도 conditional guidance 가 가능한 classifier-free guidance 로직을 제시함
- 그 과정 자체는 매우 간단하며, 아래 pseudo code 2개만 보면 금새 이해할 수 있음. 다만, 논문의 그 외 부분 내용은 매우 어려워서 이해에 실패 (예:
2. Background)
0. 초록(Abstract)
- classifier guidance: https://velog.io/@ad_official/Diffusion-Models-Beat-GANs-on-Image-Synthesis
- 분류기 가이던스(classifier guidance)는 조건부 확산 모델에서 학습 후 다양성(mode coverage)와 샘플 정확도(sample fidelity)를 조정하는 방법으로,
- 다른 유형의 생성 모델에서 사용하는
낮은 온도 샘플링(low temperature sampling)이나절단(truncation)과 유사한 개념
- 다른 유형의 생성 모델에서 사용하는
- 분류기 가이던스는 diffusion 모델의 점수 추정(score estimate)과 이미지 classifier의 기울기(gradient)를 결합하며,
- 이를 위해 확산 모델과는 별도로 이미지 classifier를 학습해야 합니다.
- 분류기 가이던스(classifier guidance)는 조건부 확산 모델에서 학습 후 다양성(mode coverage)와 샘플 정확도(sample fidelity)를 조정하는 방법으로,
- 우리는 classifier 없이도 순수 생성 모델을 통해 가이던스를 수행할 수 있음을 증명
- 우리가 분류기-비의존적 가이던스라고 부르는 이 방법은,
조건부 확산 모델과비조건부 확산 모델을 동시에 학습하며, (reverse 과정에서 노이즈를 추정하는 딥러닝 네트워크를 말함)- 결과적으로 sampling 시, 생성된 조건부 및 비조건부 점수 추정을 결합
- 논문에서는
- 하나의 neural network를 이용하여 위 2가지 모델을 학습했다.
- 구체적으는 unconditional model을 학습할 때, 단순히
null token을 input 에 할당합니다.
- 물론, 논문과 다르게 2개 모델을 jointly training 하지 않아도 됩니다.
- 다른 표현:
라벨이 input에 있는 딥러닝 모델과라벨이 input에 없는 딥러닝 모델의 예측 사이를 interpolation하는 -> 분류기 없는 가이드를 활용
1. 서론(Introduction)
- 기존 classifier guidance에서 IS, FID 의 성능 지표가 높아지는 이유가,
분류기 기울기를 혼합하기 때문이고, 실제로는 생성된 데이터는 현실성이 떨어질 수도 있다는 우려를 논문에서 제기합니다.
-IS, FID 같은 평가 지표는, 사전에 학습된 분류 모델(예: Inception 네트워크)을 기반으로 합니다.- IS의 경우, “생성된 이미지를 Inception 모델로 분류했을 때” 클래스 불확실성이 낮고(=한 클래스로 확신) 전체 클래스 분포(=여러 이미지를 봤을 때)는 고르게 분포되어야(다양성) 점수가 올라가는 식입니다.
- FID 역시 사전에 학습된 임베딩 공간(Inception에서 뽑은 특징 벡터 등)에서 “실제 이미지 분포”와 “생성 이미지 분포” 간 거리를 측정합니다.
- 우리의 궁극적 목표는 특정 클래스의 "현실성 있는" 데이터를 생성하는게 목표인데,
- classifier guidance는 채점관(예: Inception 네트워크)의 채점기준표를 파악하여,
- 채점기준표의 점수가 높게 나오도록 guidance를 주는 것으로 의심할 수 있습니다.
- 우리는 이를 classifier(예: Inception 네트워크)를 적대적 공격한다고 합니다. (분류기를 속이고 있다는 의미)
- 분류기 가이던스에서 "분류기 기울기를 따라가는" 방식이, 마치 GAN에서 생성 모델(Generator)이 감별기(Discriminator, Classifier)를 속이려고 하는 과정과 비슷하다고 논문에서 주장
- 즉, 분류기 기반 척도에 최적화된 이미지를 만들어내는 점에서, 이미 “GAN과 흡사한 최적화 루프”가 생겨버렸다는 것입니다.
-
이 질문들을 해결하기 위해 우리는 분류기-비의존적 가이던스라는 가이던스 방법을 제안합니다. 이 방법은 분류기를 완전히 배제합니다.
-
이미지 분류기의 기울기 방향으로 샘플링하는 대신,
분류기-비의존적 가이던스는조건부 확산 모델의 점수 추정치와 동시에 학습된비조건부 확산 모델의 점수 추정치를 혼합- 혼합 비율을 조정함으로써, 분류기 가이던스와 유사한 FID/IS 균형을 달성할 수 있습니다.
2. background
- 아래 사진은, DDPM을 continuos time에 정의한 것이다.

3. classifier free GUIDNACE
3.1. 학습


3.2. sampling (inference)


- 식 (5)는,
2. background를 이해하면, 쉽게 이해할 수 있다.
5. 논의 (DISCUSSION)
- 우리의 분류기-비의존적 가이던스 방법의 가장 실용적인 장점은 그 극도의 단순함
- 학습 시에는
조건부 정보를 랜덤하게 제외시키는 한 줄의 코드 변경만 필요 - 샘플링 시에는
조건부 및 비조건부 점수 추정치를 혼합하는 한 줄의 코드만 추가
- 학습 시에는
- 반면, 분류기 가이던스는 추가적인 분류기를 학습해야 하므로 학습 과정이 복잡
- 이 분류기는 노이즈가 포함된
z_lambda에서 학습해야 하므로, 기존의 사전 학습된 분류기를 사용할 수 없습니다.
- 이 분류기는 노이즈가 포함된
- 분류기-비의존적 가이던스는 추가로 학습된 분류기 없이도, 분류기 가이던스와 마찬가지로 IS(Inception Score)와 FID(Frechet Inception Distance)를 조정할 수 있으므로,
- 순수 생성 모델을 통해 가이던스를 수행할 수 있음을 입증
- 또한, 우리의 확산 모델은 제약이 없는 신경망으로 매개변수가 지정되기 때문에,
- 점수 추정치가 반드시 보존적 벡터장(conservative vector field)을 형성하지는 않습니다.
- 이는
분류기 기울기와 달리,분류기-비의존적 가이던스 샘플러가 전혀 분류기 기울기와 닮지 않은 방향으로 이동하며,- 따라서 이를 분류기에 대한 기울기 기반의 적대적 공격으로 해석할 수 없습니다.
- 결과적으로, 분류기 기반의 IS 및 FID 지표를 향상시키는 것은
- 분류기 기울기를 사용하지 않고도
- 순수 생성 모델과 적대적이지 않은 샘플링 절차를 통해 달성할 수 있음을 보여줍니다.
- 우리는 또한
가이던스가 작동하는 방식에 대한 직관적인 설명에 도달 - 가이던스는
- 샘플의 비조건부 가능도를 줄이는 동시에
- 조건부 가능도를 증가
- 분류기-비의존적 가이던스는 음수 점수 항을 사용하여 비조건부 가능도를 줄임으로써 이를 달성
- 이러한 접근 방식은 아직 연구되지 않은 영역이며, 다른 응용 분야에서도 활용될 가능성이 있음
- 여기서 제시된
분류기-비의존적 가이던스는- 비조건부 모델을 학습하는 것에 의존하지만,
- 경우에 따라 이를 피할 수도 있습니다.
- 만약 클래스 분포가 알려져 있고 클래스의 수가 적다면, 아래 수식을 이용해
비조건부 점수를조건부 점수로부터 계산할 수 있습니다. - 단, 이 방법은 가능한 모든 c 값에 대해 순전파를 수행해야 하므로
- 클래스 수가 많거나 조건부 정보가 고차원인 경우 비효율적일 수 있습니다.
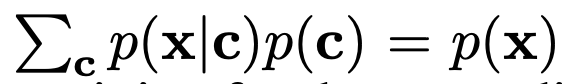
limitation
분류기-비의존적 가이던스의 잠재적 단점중 하나는 샘플링 속도- 일반적으로 분류기는 생성 모델보다 작고 빠르기 때문에,
- 분류기-기반 샘플링이 분류기-비의존적 가이던스보다 빠를 수 있습니다.
- 분류기-비의존적 가이던스는 조건부 점수와 비조건부 점수를 위해 두 번의 순전파를 수행해야 하기 때문
- 그러나 네트워크의 후반부에 조건부 정보를 주입하는 방식으로 아키텍처를 변경하면 이러한 문제를 완화할 수 있으며, 이는 향후 연구 과제로 남겨둡니다.
- 마지막으로,
샘플 정확도를 높이는 모든 가이던스 방법은 샘플 다양성을 희생해야 한다는 점에서,- 감소된 다양성이 수용 가능한지에 대한 질문에 직면
sample 다양성을 유지하는 것은 데이터의 특정 부분이 다른 데이터에 비해 덜 나타나는 경우- 중요한 응용 분야에서 부정적인 영향을 미칠 수 있습니다.
- 샘플 다양성을 유지하면서 샘플 품질을 향상시키는 방법을 찾는 것은 향후 연구에서 흥미로운 방향이 될 것입니다.

ad_official