- https://arxiv.org/pdf/2112.10741
- 2021, 12
- 3400회 인용
- GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models


0. 요약
- 확산 모델은
다양성과 품질 간의 균형을 조정할 수 있는 가이드 기법과 결합될 때 -> 특히 고품질의 합성 이미지를 생성하는 것으로 최근에 입증 - guidance diffusion model 논문들 (아래 그림 참조)
- classifier-guided (c 카테고리): Diffusion Models Beat GANs on Image Synthesis
- classifier-free (d 카테고리): CLASSIFIER-FREE DIFFUSION GUIDANCE
- 우리는
텍스트 조건부 이미지 합성을 위한 문제에서 확산 모델을 탐구하고,CLIP 가이드와Classifier 없는 가이드([d])라는 두 가지 다른 가이드 전략을 비교
- 결과적으로, 사진 실재감과 캡션 유사성 모두에서 후자(
Classifier 없는 가이드)가 더 뛰어남 Classifier 없는 가이드를 사용하는 35억 매개변수 텍스트 조건부 확산 모델에서 생성된 샘플은,비용이 많이 드는 CLIP 재정렬을 사용하는 DALL-E의 샘플보다 더 뛰어남- 참고: DALL-E
- 또한, 우리의 모델이 이미지 인페인팅에 대해 fine tuning을 수행할 수 있음을 발견했으며, 이는 강력한 텍스트 기반 이미지 편집을 가능하게 함
- image impainting
- 손상되거나 누락된 부분이 있는 이미지를 복원
- 특정 영역을 수정 및 편집하여 자연스럽게 보이도록 만드는 기술 (물체 제거 등)
- image impainting
- 우리는
필터링된 데이터셋으로, 더 작은 모델을 학습시킴 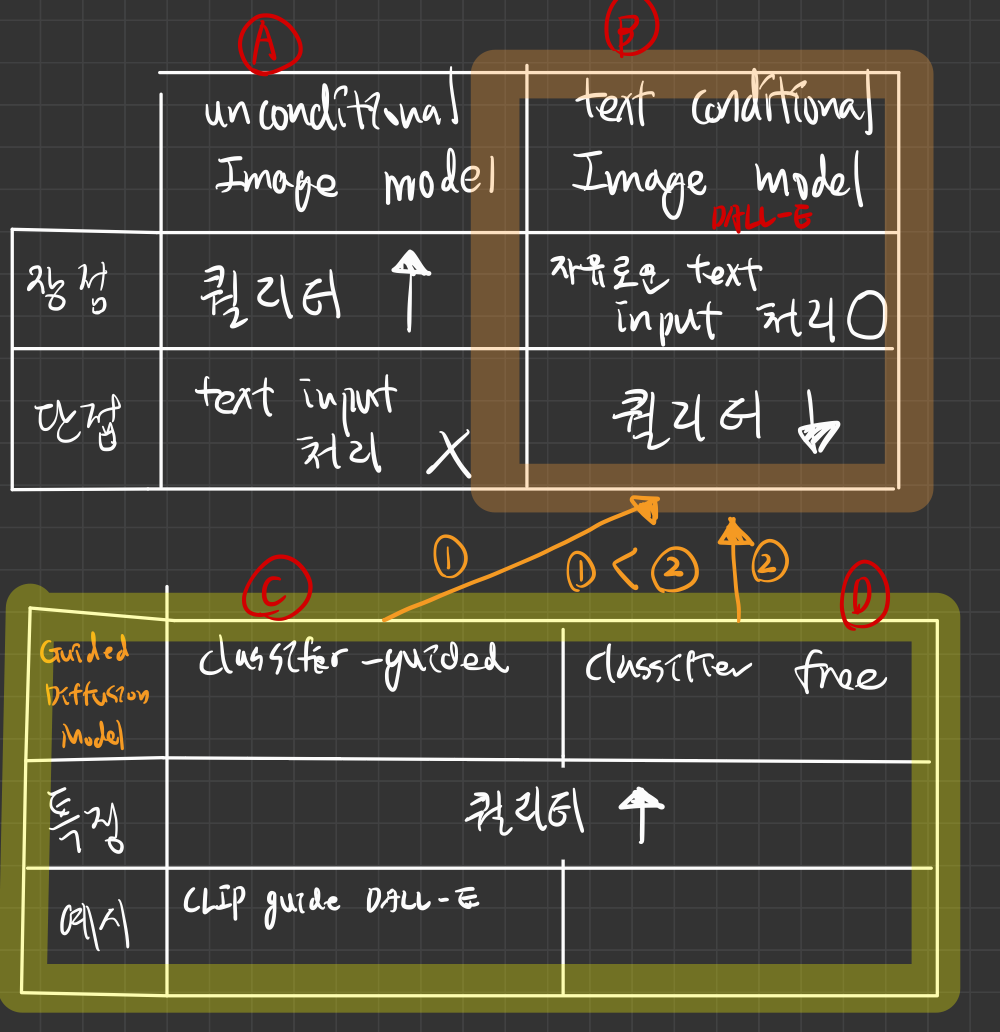
1. 도입
- 자연어를 사용한 이미지 편집 능력은 반복적인 수정과 세부적인 조정이 가능하게 하여, 실제 애플리케이션에 매우 중요
- 최근의
텍스트 조건부 이미지 모델(b 카테고리)은자유로운 텍스트 프롬프트로부터 이미지를 합성할 수 있으며,- 관련 없는 객체를 의미적으로 그럴듯하게 조합할 수 있음
- 그러나, 이러한 모델들은 아직 성능이 떨어집니다.
- 반면,
비조건부 이미지 모델(a 카테고리)은 사진 실재감이 높은 이미지를 합성할 수 있습니다.
클래스 조건부 설정(c 카테고리)에서 사진 실재감을 달성하기 위해, ( https://velog.io/@ad_official/Diffusion-Models-Beat-GANs-on-Image-Synthesis ) 은 확산 모델에분류기 가이드를 추가했으며,- 이 기법은 확산 모델이
학습된 분류기의 라벨에 따라 조건화할 수 있게 합니다. - 분류기는 처음에 노이즈가 포함된 이미지로 학습되며,
확산 샘플링 과정에서 분류기의 그래디언트는 샘플이 라벨로 향하도록 안내하는 데 사용됩니다.
- 이 기법은 확산 모델이
- https://velog.io/@ad_official/CLASSIFIER-FREE-DIFFUSION-GUIDANCE 은
별도로 학습된 classifier 없이도 비슷한 결과를 달성했으며,라벨이 있는 모델과 없는 모델의 예측 사이를 보간하는 분류기 없는 가이드를 활용
가이드 확산 모델(c, d)이 사진 실재감이 높은 샘플을 생성하는 능력과텍스트-이미지 모델이 자유로운 프롬프트를 처리하는 능력에 자극받아,- 우리는
가이드 확산(c, d)을텍스트 조건부 이미지 합성 문제에 적용
- 우리는
- 먼저,
자연어 설명에 따라 조건화하는 텍스트 인코더를 사용하는 35억 매개변수 diffusion 모델을 학습 - 다음으로,
CLIP 가이드와분류기 없는 가이드라는 두 가지 확산 모델 가이드 기법을 비교분류기 없는 가이드가 더 높은 품질의 이미지를 생성한다는 것을 발견 (세계 지식의 폭넓은 범위를 반영)- clip guided DALL-E(https://velog.io/@ad_official/Zero-Shot-Text-to-Image-Generation) 보다 더 좋은 성능을 보임
- 우리의 모델은 제로샷으로
다양한 텍스트 프롬프트를 렌더링할 수 있지만, 복잡한 프롬프트에 대해 현실적인 이미지를 생성하는 데 어려움을 겪을 수 있음 - 따라서, 제로샷 생성 외에도
편집 기능을 모델에 추가하여,사용자가 모델 샘플을 반복적으로 개선해복잡한 프롬프트와 일치하도록 할 수 있도록 함 - 구체적으로,
- 우리는 모델을 이미지 인페인팅을 수행하도록 fine-tuning했으며,
- 이를 통해 자연어 프롬프트를 사용해 기존 이미지에 현실적인 편집을 수행할 수 있음을 발견
- 모델이 생성한 편집은
주변 맥락의 스타일과 조명을 일치시키며, 설득력 있는 그림자와 반사를 포함
- 우리는
필터링된 데이터셋으로 학습된 소형 확산 모델과노이즈가 포함된 CLIP 모델을 배포
- 우리는 우리의 시스템을 GLIDE(Guided Language to Image Diffusion for Generation and Editing)라고 부르며, 필터링된 소형 모델은 GLIDE (filtered)라고 지칭
7. 한계
- 우리의 모델은 종종 복잡한 방식으로 다양한 개념을 조합할 수 있지만,
- 매우 특이한 객체나 시나리오를 설명하는 특정 프롬프트를 포착하지 못하는 경우가 있음
- 최적화되지 않은 모델은, 단일 A100 GPU에서 이미지를 샘플링하는 데 15초가 걸립니다.
- 이는 관련된 GAN 방법보다 훨씬 느리며, GAN은 실시간 응용에 더 적합합니다.

ad_official