0. 들어가기 전에
1. 뭐하는 논문?
- DDPM은 높은 FID와 IS 점수를 기록했지만 높은 log-likelihood를 달성하는 데는 실패
- 실제처럼 보이는 고품질의, 다양하고 시각적으로 우수한 샘플을 생성
- But, 데이터 전체의 확률 분포—특히 픽셀 단위의 세밀한 분포—를 완벽히 설명하지는 못한다
- 본 논문: DDPM에서 조금 개선해서, 더 높은 log-likelihood를 달성
- 학습 데이터의 분포를 더 잘 커버하는 를 학습했다는 뜻
- reverse diffusion process에서,
- DDPM에서는 의 평균을 가 모사하기 위해, 만 학습했었다.
- 분산까지 맞추도록 학습하면, log-likelihood가 더 높게 학습되더라!
- 이유
- diffusion model이 (즉 위 식의 평균)만 학습하도록 DDPM에서는 설계되어 있는데, 이 유추과정이 항상 정확할 순 없습니다.
- 왜냐면 위 사진의 평균은 를 알 때에 대한 수학적 값인데,
- 실제 inference를 할 떄는, 네트워크가 를 모른채 분포의 평균을 유추해야 하기 때문입니다.
- 그래서 네트워크 분산까지 맞추도록 학습하면, 기존 평균 유추 과정의 오차를, 분산 예측값이 보완해줄 수 있습니다. (KL divergence를 더 작게 할 수 있습니다.)
- diffusion model이 (즉 위 식의 평균)만 학습하도록 DDPM에서는 설계되어 있는데, 이 유추과정이 항상 정확할 순 없습니다.
- 분산까지 맞추도록 학습(T step으로 hyperparameter 설정)하니, inference(sampling) 시점에서,
- T-> T-1 -> T-2 -> ... -> 0 step으로 순차적 sampling을 하지 않고
- T -> T-3 -> T-6 -> ... -> 0 step 처럼, 더 적은 step으로 sampling해도, 큰 퀄리티 차이 없이 sampling이 가능하다는 것을 확인!

- DDPM도 model size(학습 parameter 개수)와 연산량을 선형적으로 증가시킬수록, likelihood가 선형적으로 증가하는 것을 확인했다!
- scalability가 좋더라!
- 아래 그림은, 학습 완료한 DDPM 네트워크를, inference(reverse process) 시, 각 step에서 발생한 VLB loss를 그래프로 나타낸 것입니다.
- 그림을 보면, 각 step별로, loss의 발생 크기 정도가 다릅니다.
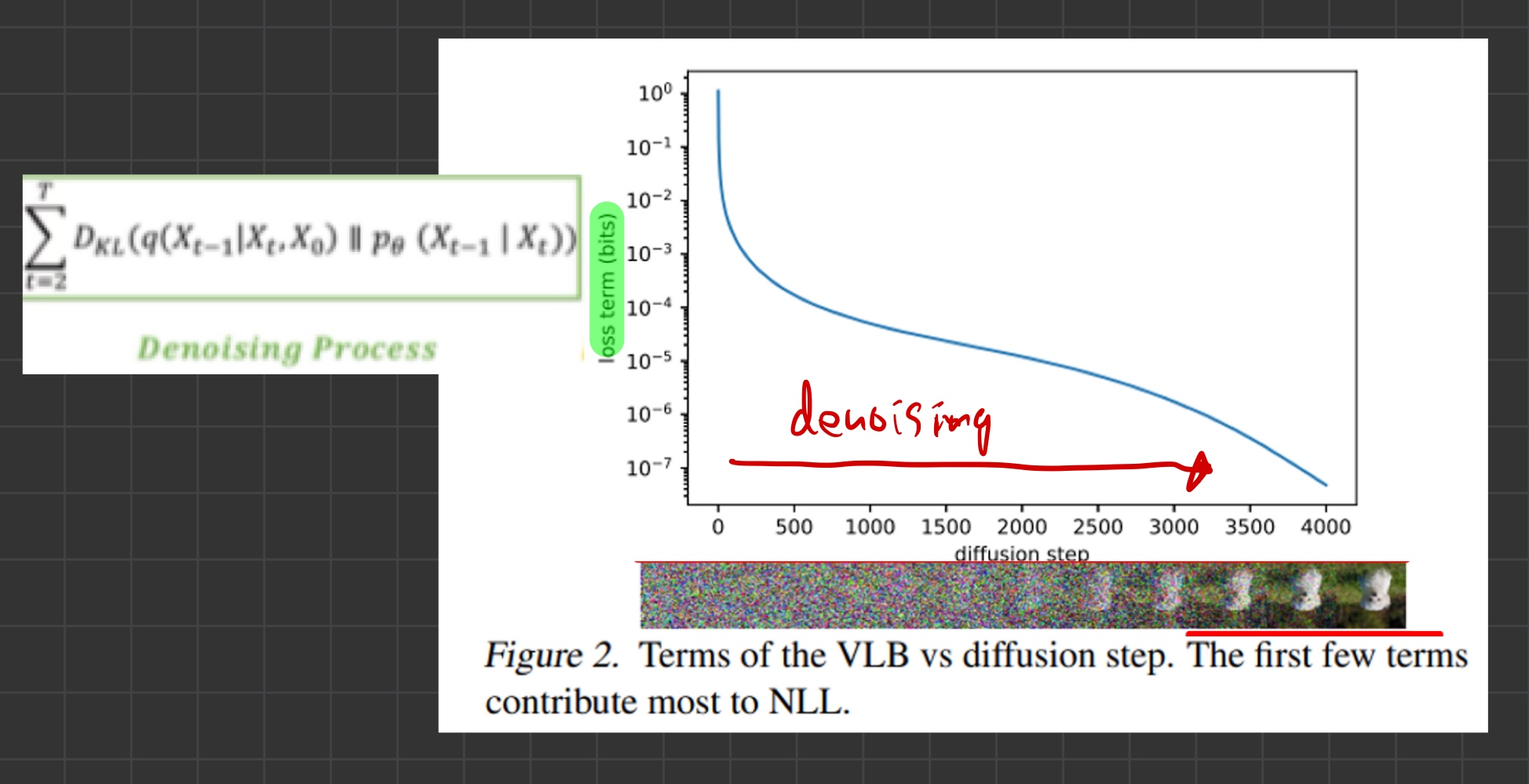
- 노이즈를 제거하는 초반 단계에서는, loss가 크고 -> 갈수록 loss가 줄어드는 결과를 보입니다.
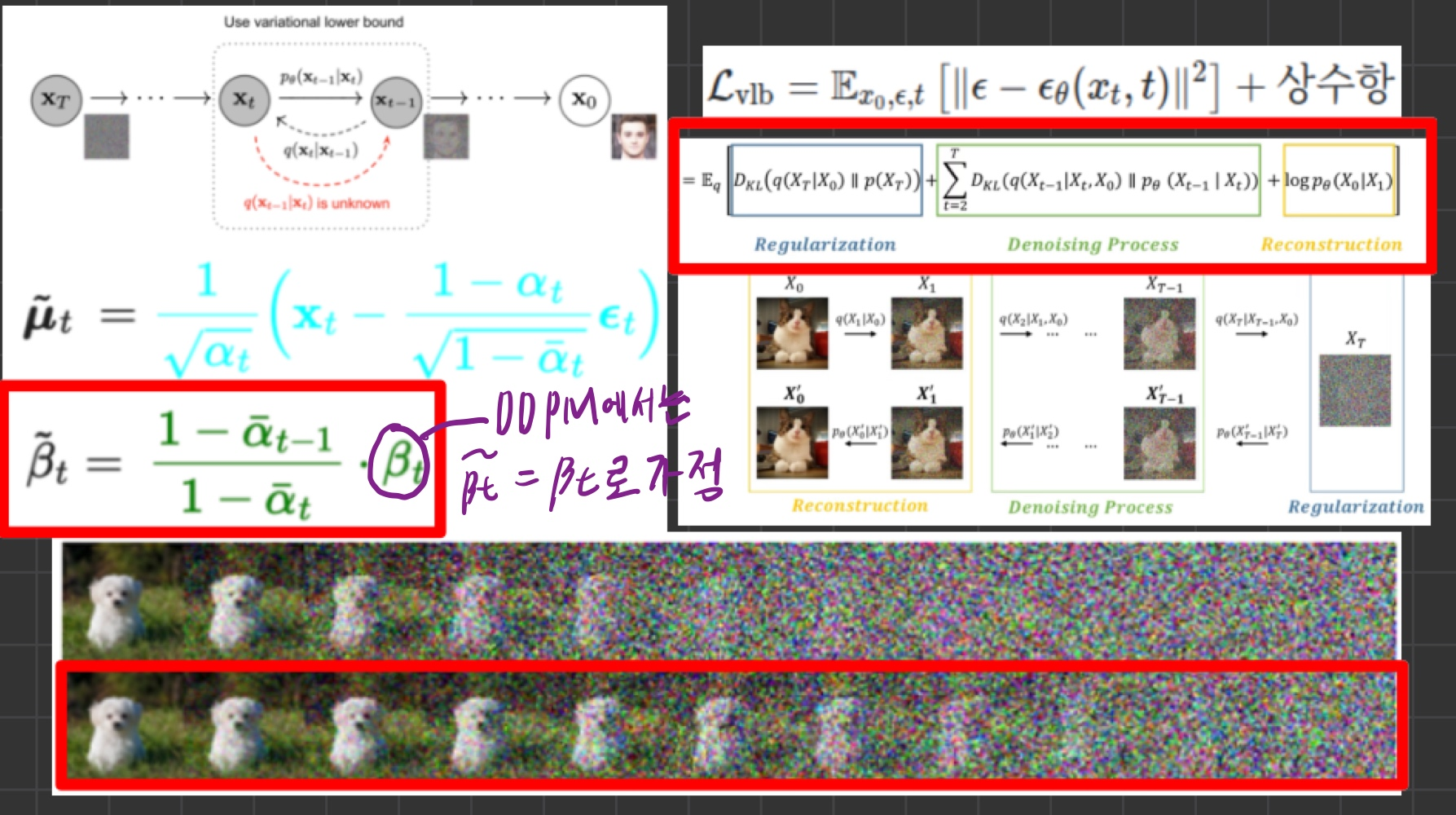
2. VLB를 직접 loss function으로?
- DDPM 에서 배웠듯이, log likelihood를 극대화 하려면, VLB 를 최소화시켜야 합니다.
- 하지만 DDPM에서는 아래의 loss function을 썼습니다.
- 하지만 DDPM에서는 아래의 loss function을 썼습니다.
- 그래서 본 논문에서는 DDPM의 loss function과 달리, VLB 자체를 loss function으로 쓰면 log-likelihood 성능이 좋아질 것을 기대하면서 실험해 보았다고 합니다.
2.0. VLB를 loss function으로 쓰는 구체적 방법
- VLB는 DDPM에서 유도한 대로 아래과 같다.
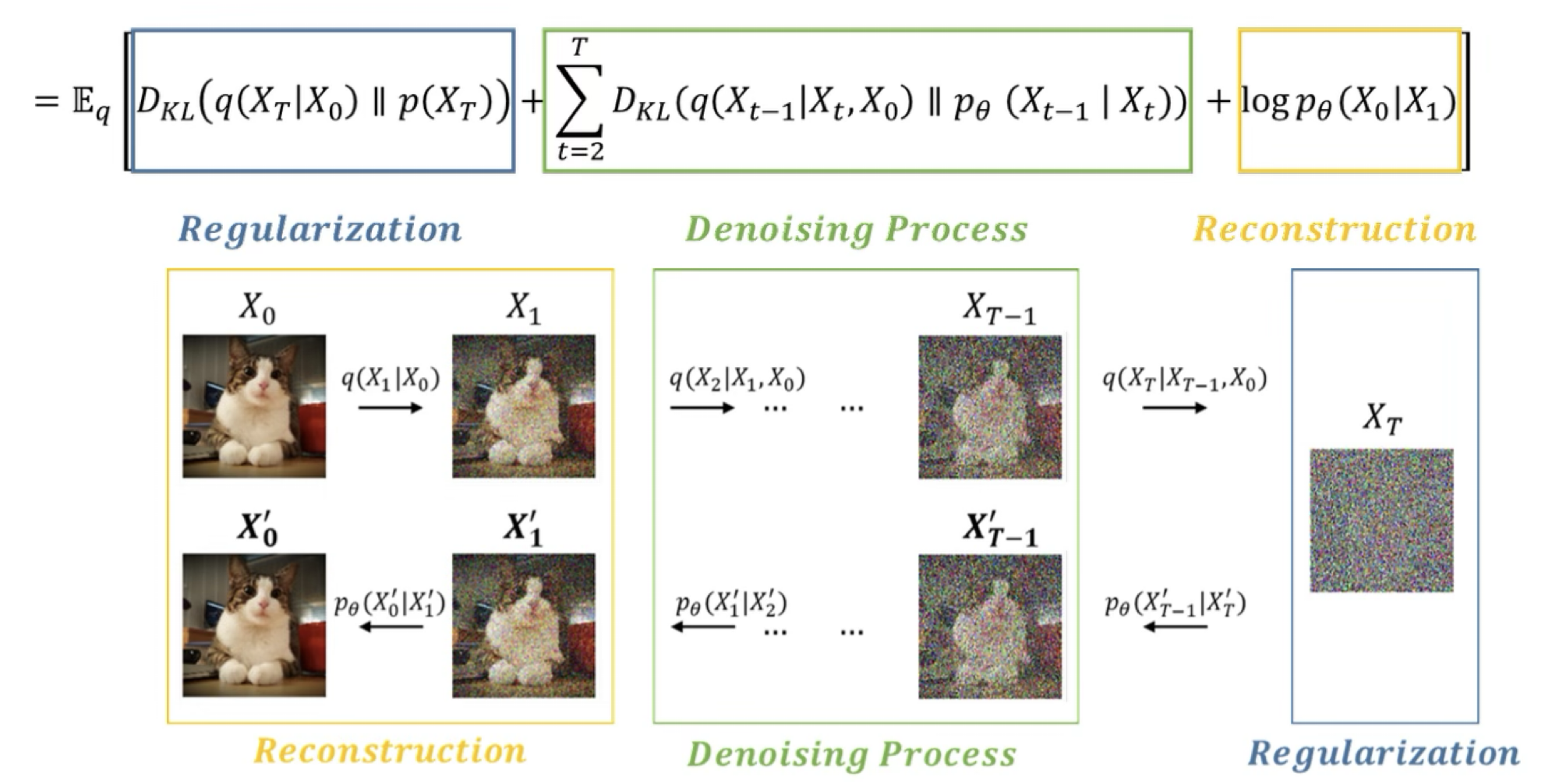
- 위 식을 loss function으로 사용하는 방법은 Appendix A를 참조해라. (매우 중요하니 한번 보는걸 추천)
- 두괄식으로는,
- DDPM에서는 아래의 식을 loss function으로 썼었는데(여기서 = 1로 치환해버리는 DDPM)
- ImprovedDDPM에서는
- w(t)도 1 이 아니라, 원래 식 그대로 쓰고,
- 분산도 학습 대상으로 고려하여 VLB loss function을 씁니다.
- DDPM에서는 아래의 식을 loss function으로 썼었는데
2.1. VLB 자체를 loss로 사용 -> 결과 별로였음
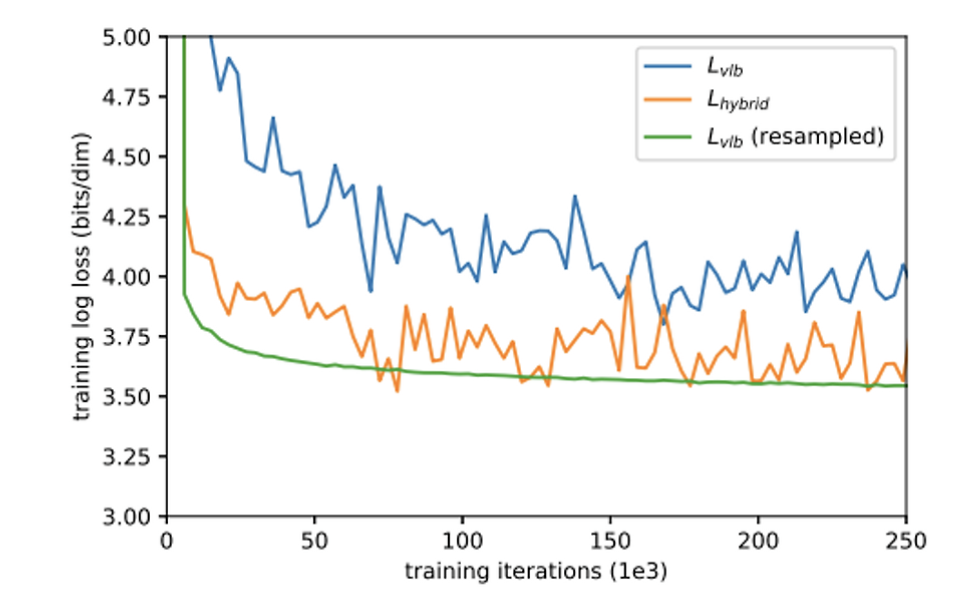
- VLB 자체를 loss로 사용하여 학습한 결과는 학습 성능이 별로였습니다. 아래 그래프와 같이, VLB 학습 시 많은 gradient noise가 생겼습니다.
2.2. 해결책
- 학습 시 t를 uniform sampling 하면서 학습하는 대신, importance sampling을 수행합니다.
- 쉽게 얘기하면, 학습 초반일수록 더 많이 sampling하여 학습한다는 뜻입니다.
- 좀 더 구체적으로 어떻게 하는거냐면, (필요하면 보세요)
- T hyperparamter을 설정한 후에(예: 100),
- 먼저, 0, 1, ..., 100이 모두 각각 최소 10번 이상 sampling 될 떄까지, uniform sampling하면서 학습시킵니다.
- 위 과정이 끝나면, 이제 그림 2와 같이 t 별 loss 분포를 알 수 있습니다.
- 이제부터, 위 그림2를 확률분포처럼 사용해서 t를 sampling하면서 학습합니다.
- 대신, 확률이 큰 t의 loss가 자주선택될테니, p_t로 나누어 작게 반영합니다.
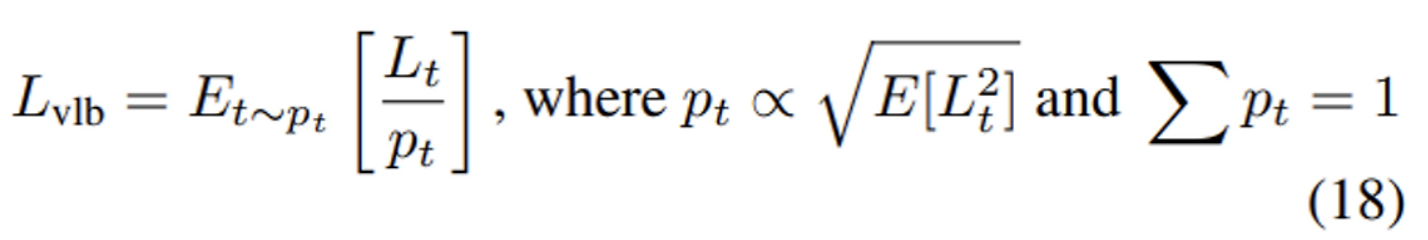
- Importance sampling을 적용하여 VLB loss로 다시 학습해보니, 아래와 같은 그래프가 나왔다!
- 위 그래프를 해석해보면
- VLB loss는 gradient noise가 심해 학습이 불안정하나,
- resampled VLB loss는 안정적으로 학습되어 loss가 가장 많이 줄어듭니다.
- 다만, 이 importance sampling 방식은, L_hybrid(아래에서 서술할것임) 에는 먹히지 않는 방법이었다.
2.3. 1차 결론
- DDPM이 log-likelihood 측면에서 성능이 아쉬웠고, 이를 극복하기 위해
log-likelihood를 direct하게 극대화시킬수 있는 VLB loss를 도입하였다. - VLB loss의 단점인 gradient noise로 인한 학습 성능 저하를 극복하기 위해, importance sampling을 적용하였고, 결과적으로 log likelihood를 극대화할 수 있었다.!
2.4. VLB loss의 side effect?
- 실험을 돌려보니, vlb loss를 이용하면 log-likelihood는 더욱 좋아지지만,
FID 성능이 안 좋아졌습니다. (현실성과 diversity를 측정하는 metric) - 결론: VLB loss 만 적용해서는 성능 향상에 한계가 있다
- 기존 DDPM과 비슷한 FID 성능을 유지하면서도, log-likelihood 만 성능을 높일 수 있는 방법은 없을까?
3. log-likelihood 성능을 개선하는 또 다른 접근법!
3.1. log-likelihood가 낮은 원인 분석 (복습)
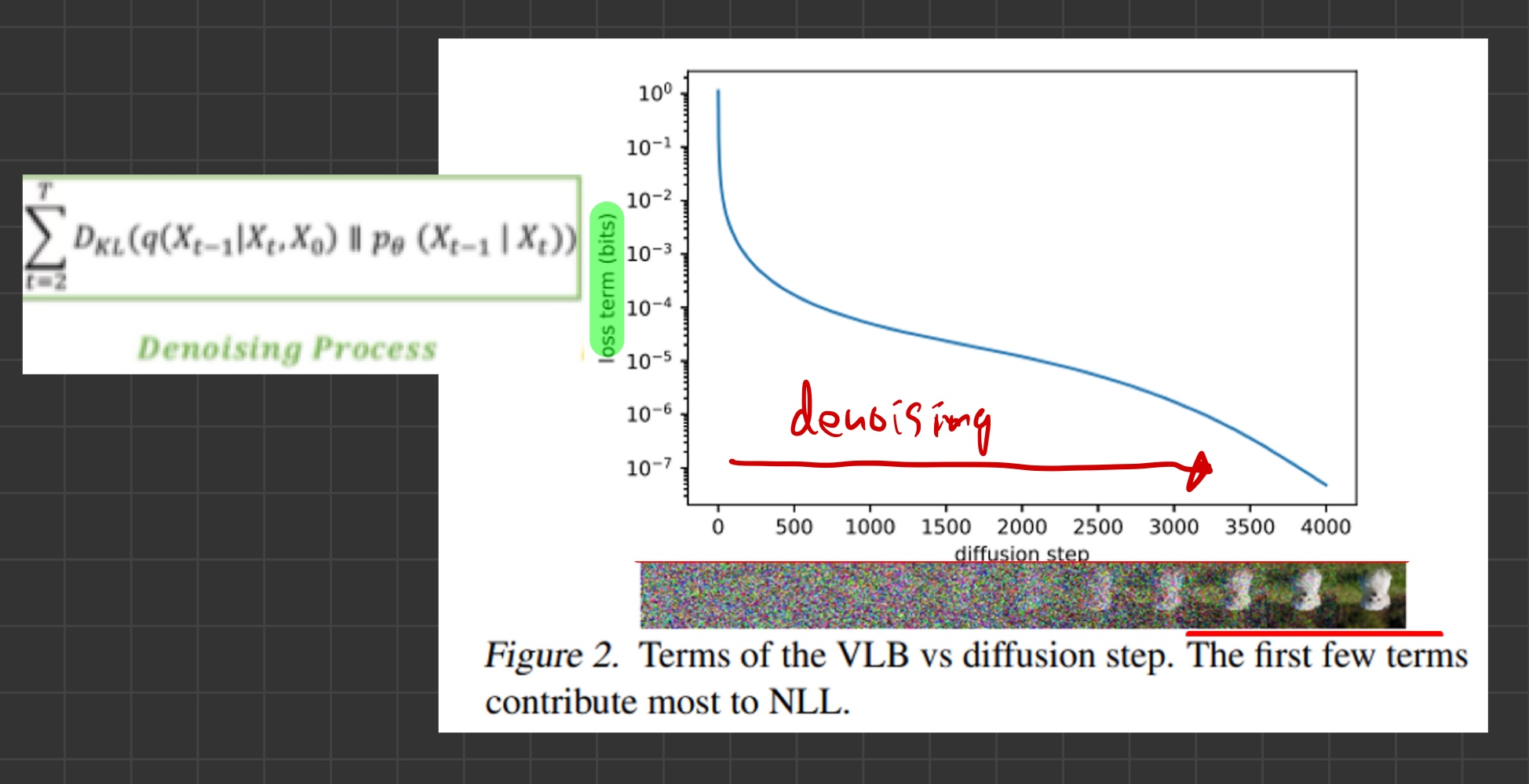
- 위 그림은 학습 완료한 DDPM 네트워크를, inference(reverse process) 시, 각 step에서 발생한 VLB loss를 그래프로 나타낸 것입니다.
- 위 그림을 보면, VLB loss는 초기 phase(noise가 엄청 많은 시점)에서 크게 나타난다는 것을 볼 수 있습니다.
- 초기 phase의 Loss를 많이 줄일 수 있다면, 우리는 log-likelihood를 극대화할 수 있을 것입니다.
- VLB가 log-likelihood의 lower bound이기 떄문입니다.
- 그렇다면 왜 초기 phase의 loss는 클까요?
이유 1: 분산까지 맞추도록 학습하지 않아서

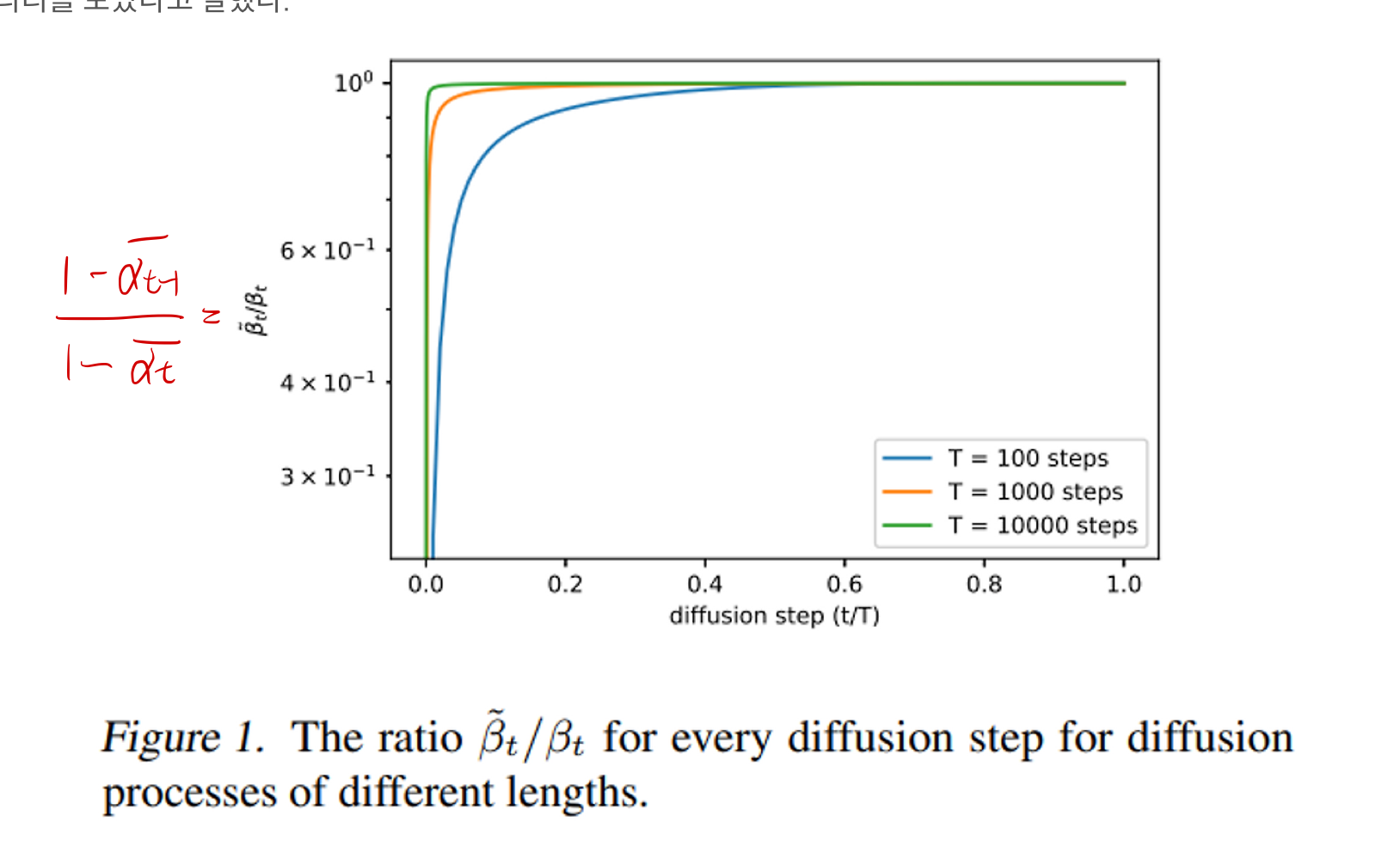
- 위 그림은
- DDPM을 다른 T hyperparameter로 설정하여 각각 학습 시킨 뒤, (3가지 실험)
- inference(sampling)을 각각하면서 가 어떻게 변화하는지 그린 그래프
- 참고로 은 normal distribution의 variance로써, DDPM에서 아래 수식과 같이 유도했습니다.
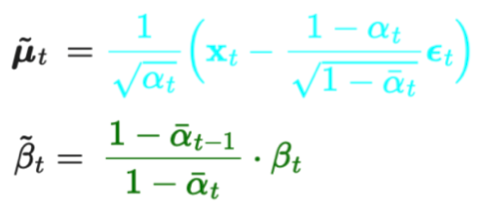
- DDPM을 다른 T hyperparameter로 설정하여 각각 학습 시킨 뒤, (3가지 실험)
- 우리는 DDPM에서, 분산을 따로 학습시키지 않았었습니다.
- reverse process에서 우리는 만을 출력하도록 학습했고,
- 이는 의 평균을 의 평균과 유사하게 학습시키는 과정이었습니다.
- 분산은 학습시키지 않고, 아래와 같이 고정시켰었습니다.
- Σₜ(xₜ, t) = σₜ²I
- 여기서 σₜ는 학습되지 않고 σₜ= βₜ
- reverse process에서 우리는 만을 출력하도록 학습했고,
- 위 그래프를 다시 보면,
- inference 초반 (sampling 시) 에는 βₜ가 와 차이가 크다가, sampling이 진행될수록 차이가 줄어들어서 같아지게 됩니다.
- T hyperparamter가 클수록, 차이의 영향은 줄어들긴 합니다.
- 여기서 알 수 있는 점은,
- Figure 2를 보면 inference 초반 (sampling 시)에 VLB loss가 큰데,
- Figure 1을 보면, inference 초반 (sampling 시)에 variance estimation 성능이 떨어진다는 것을 볼 수 있습니다.
- 그러므로, 우리는
분산까지 학습시켜서 esimation하면 VLB loss, 즉 log-likelihood가 개선될까? 라는 생각을 가질 수 있습니다.
위 이유 1의 해결책
- 자 이제 denoising process를 담당하는 deep learning network가 기존 ϵ_t (즉, 평균) 만을 출력하는 것에서 개선하여,
- ϵ_t (즉, 평균) 와 Σₜ(xₜ, t) 까지 학습하도록 해봅시다.
- 다만, Σₜ(xₜ, t)는 유효한 범위가 매우 작아서, direct 학습을 하면 학습이 잘 안되었다고 합니다.
- 이를 해결하기 위해 모델의 output을
v를 출력하도록 학습합니다.v는 아래와 같습니다. - 모델의 output에
v를 추가했으니, 이를 학습되게 하기 위해서 loss function도 수정해봅시다. - 기존 DDPM의 loss는 아래와 같았습니다.
- L_simple에는, 분산을 학습시키는 term이 없어서 추가해줘야 합니다.
- Improved DDPM에서는 아래와 같이 변경하였습니다.
- L_vlb loss 계산 시, μ 에서는 stop gradient를 사용하여,
- simple loss가 μ (평균) 에 영향을 끼치는 메인 loss,
- vlb loss가 분산에 대한 학습을 담당하도록 유도
- 실험을 통해 λ 가 0.001일 때 vlb loss가 simple loss를 overwhelming하지 않는다는 것을 찾았다.
- 결론
- 이렇게 의 분산까지 학습시키므로써, log-likelihood 성능이 개선되었다고 한다!
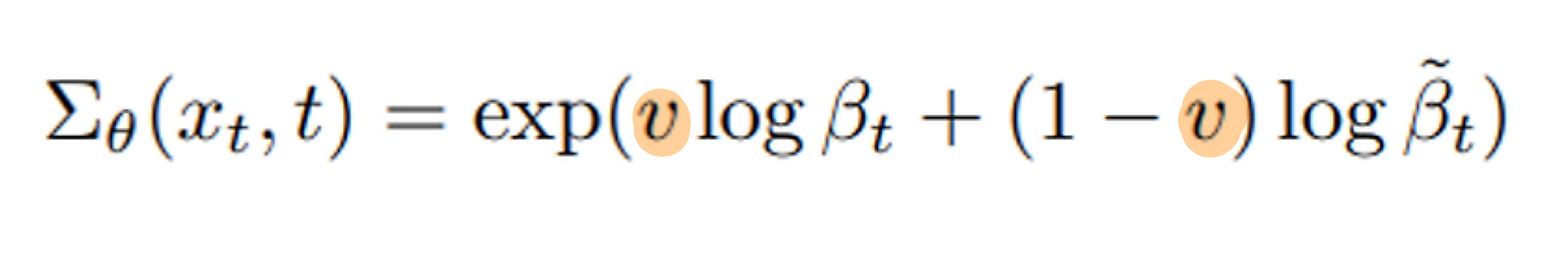

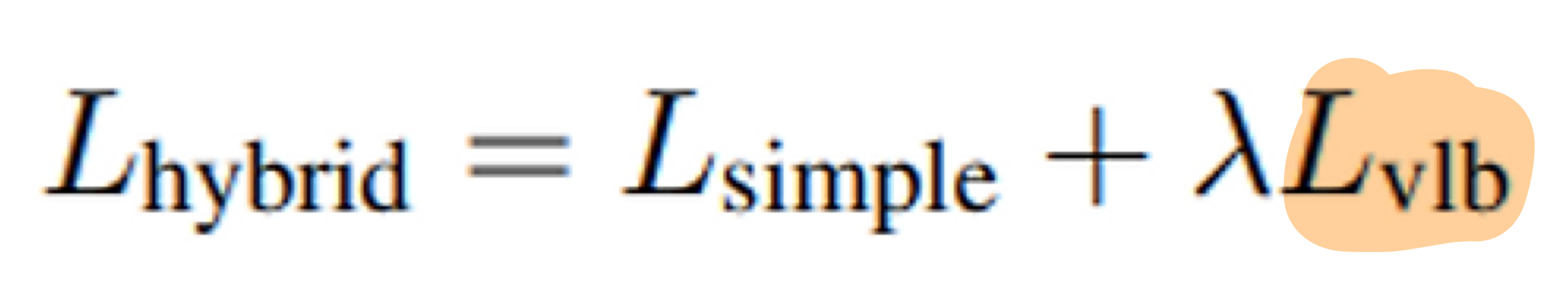
이유 2: Noise schedule이 별로였어서
- 앞선 그림 2를 보면, VLB loss는 초기 phase(noise가 엄청 많은 시점)에서 크게 나타난다는 것을 볼 수 있습니다.
- 초기 phase의 Loss를 많이 줄일 수 있다면, 우리는 log-likelihood를 극대화할 수 있을 것입니다.
- 그렇다면 왜 초기 phase의 loss는 클까요?
- 우리는 DDPM에서 를 linear schedule로 설정하였습니다.
- t=0에서 제일 작고, t=T으로 갈 수록 선형적으로 증가하게

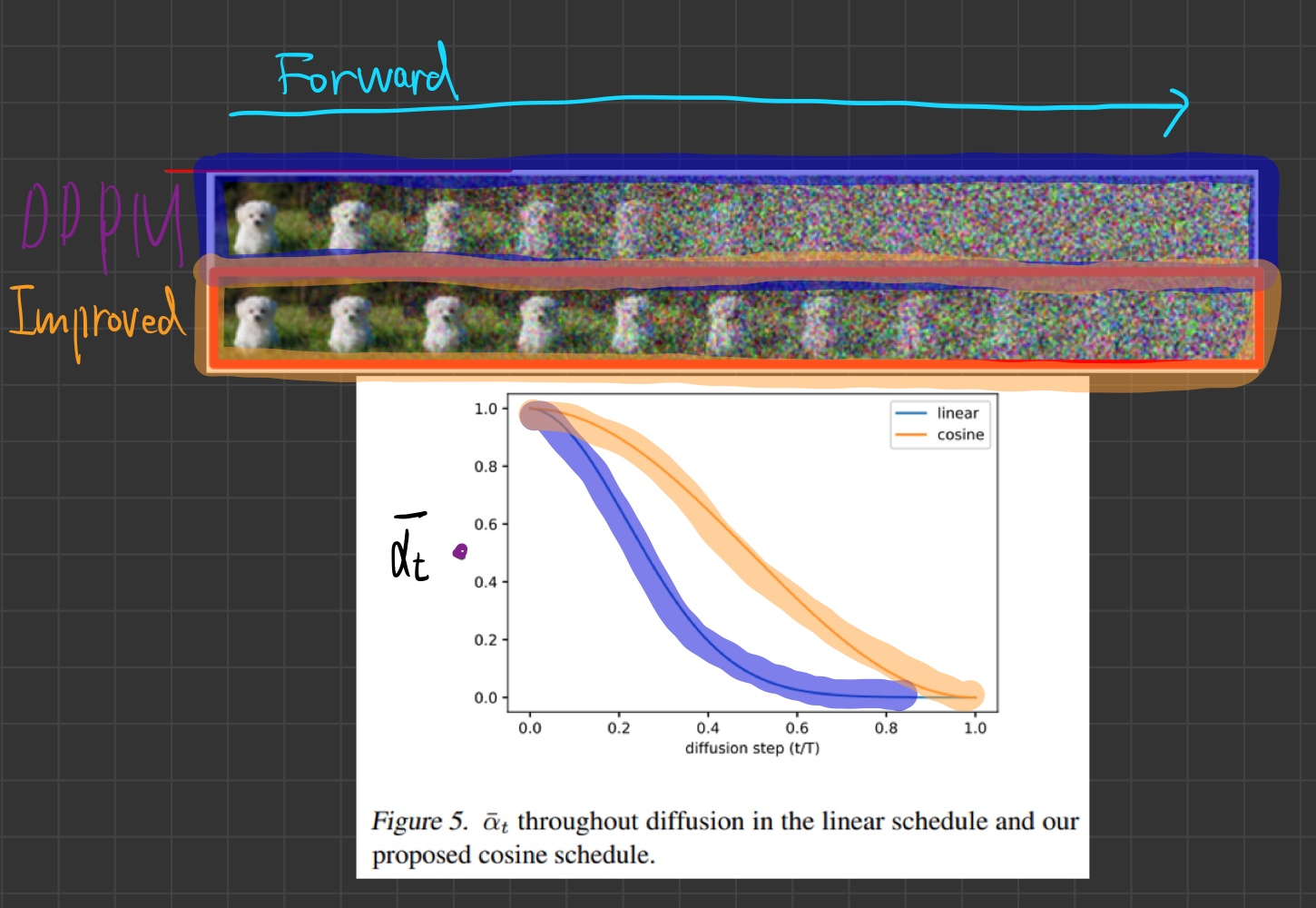
- 위 그림 해석
- 첫번쨰 줄(linear schedule): 중간 단계에서부터 벌써 almost noisy
- 두번쨰 줄(DDIM의 제안 schedule)
- 첫번쨰 줄(linear schedule)이 왜 문제가 될까요? 실험을 통해 알아봅시다.
- DDPM을 학습 다 시킨 후, inference(sampling)시,
- reverse process의 초기 부분을 몇 % 생략하는지에 따라, 성능(FID)가 얼마나 안좋아지는지를 실험해보았습니다. (FID는 낮을수록 좋음)
- 생략을 어떻게 했는지 설명
- 참고: ( = )
- 딥러닝 네트워크의 인풋에 를 넣어서 noise와 분산을 구하고, noise를 기반으로 평균을 계산할 때에도, 를 넣어서 계산
- 생략을 어떻게 했는지 설명
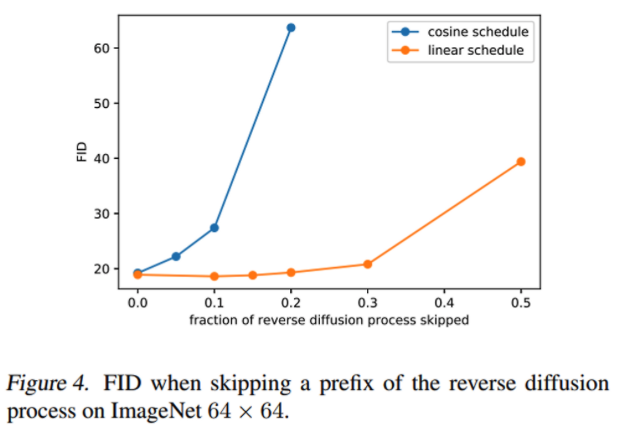
- 주황색 그래프(DDPM)를 보면, 초반 부분을 skip을 해도, reverse process가 생성하는 이미지의 퀄리티는 별 차이가 없었습니다.
- 즉, 다른 말로 하면, reverse process의 초반부 (forward process의 후반부)의 학습이 잘 안되었다는 뜻입니다.
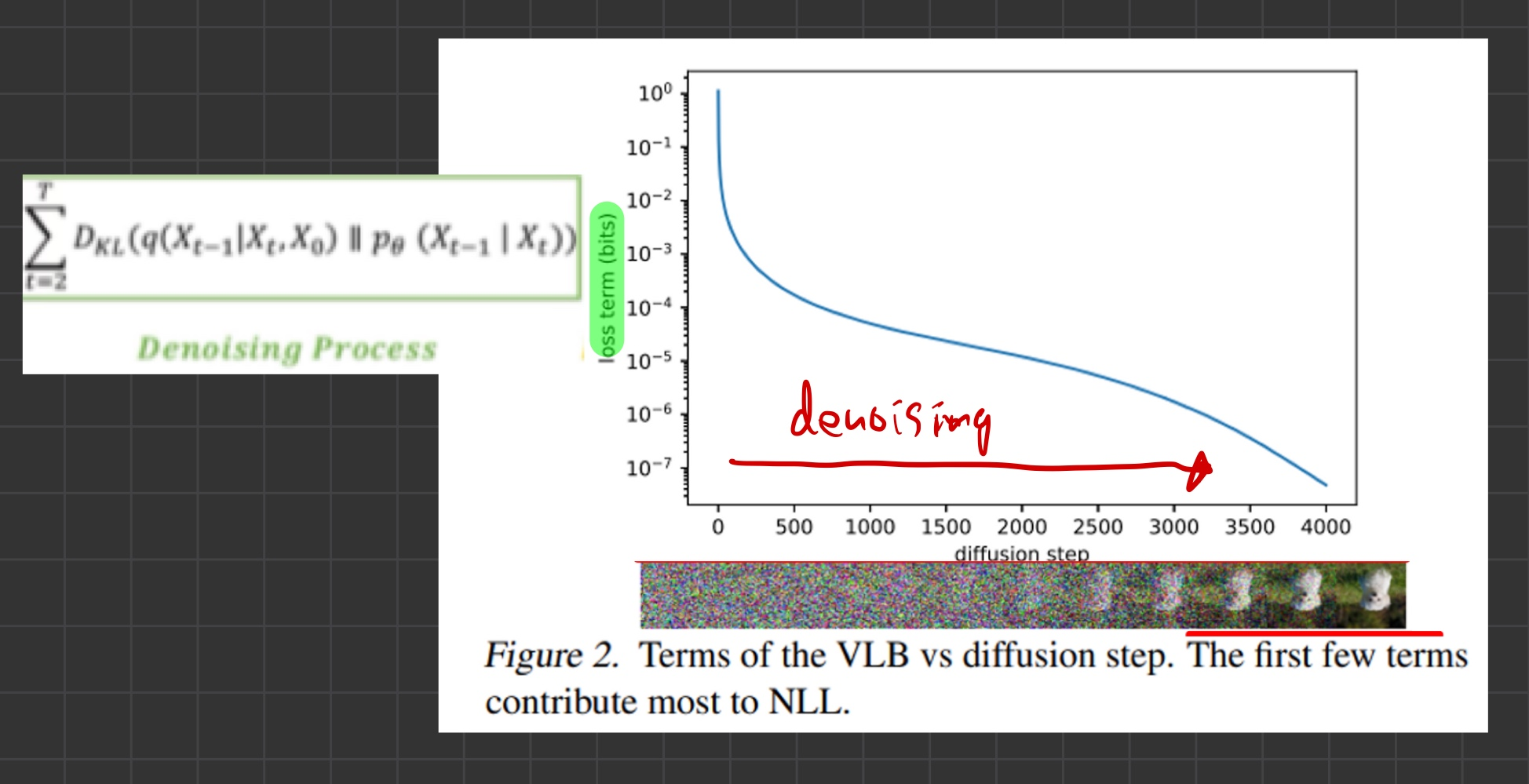
- Figure 2를 보면, 학습 다 시킨 DDPM을 sampling 했을 때, 초반부의 VLB loss가 가장 크다고 했죠?
- 즉, 의미 없는 학습 과정이 있었기에, VLB loss(즉 negative log likelihood loss)가 크게 나온 겁니다.
- 이를 개선하기 위해 beta sampling을 아래와 같이 새롭게 제시합니다.
- 스케줄링 함수의 선택은 임의적일 수 있지만,
알파 헷은 아래의 규칙을 따르는게 좋다고 합니다. (아래 그래프 세로축 처럼)- 훈련 과정 중간에 거의 선형적인 감소를 제공하고
- t=0 및 t=T 근처에서는 미묘한 변화를 제공해야 합니다.
- 스케줄링 함수의 선택은 임의적일 수 있지만,
- 대표적인 예가
코사인 기반 분산 스케줄을 사용하는 것입니다. 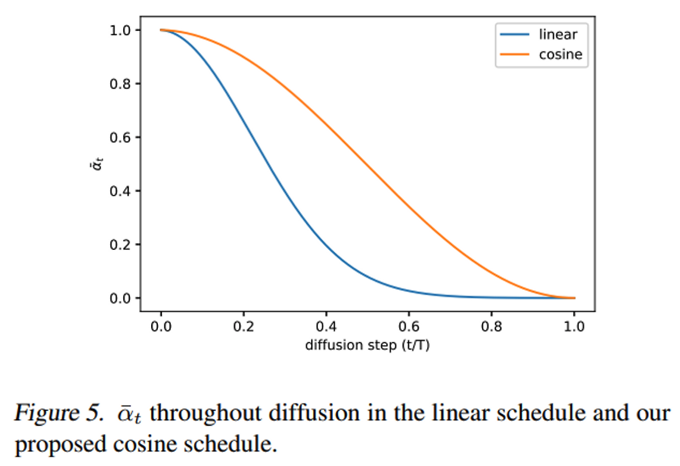
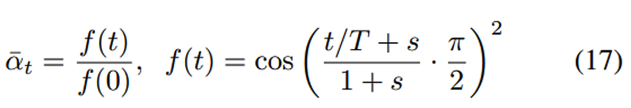
3.2. 위 개선점 2개로 얼마나 log-likelihood가 좋아졌을까?
- 2가지 실험을 비교해보았다고 함
- 후보군 1:
cosine schedule + hybrid loss(분산 까지 학습)(importance sampling없이)- DDPM과 비교해서
- FID를 유지
- log-likelihood 개선
- DDPM과 비교해서
- 후보군 2:
cosine schedule+VLB loss only+importance sampling- DDPM과 비교해서
- FID 감소
- log-likelihood 가장 많이 개선
- DDPM과 비교해서
- 저자는
후보군1이 더 좋은 선택지라고 주장한다!
4. Sampling 속도 높이는 전략
hybrid loss(분산도 함께 학습)을 적용하면, 우리가 학습때 hyperparamter T로 학습했다고 할지라도,- inference(sampling)시
- 0, 1,2, ..., T 로 샘플링하지 않고
- subsequence인 S를 사용하여 샘플링 해도 (일정한 stride로 timestep을 줄이는 방식임)
- 고품질의 결과를 생성할 수 있다는 것을 보였다.
- inference(sampling)시
- 학습 때 사용한 noise schedule는 0, 1,2, ..., T 에 관한 스케줄이었는데,
- 빠르게 inference 하기 위해 우리는 subsequence인 S에 관한 스케줄을 아래와 같이 도입한다.
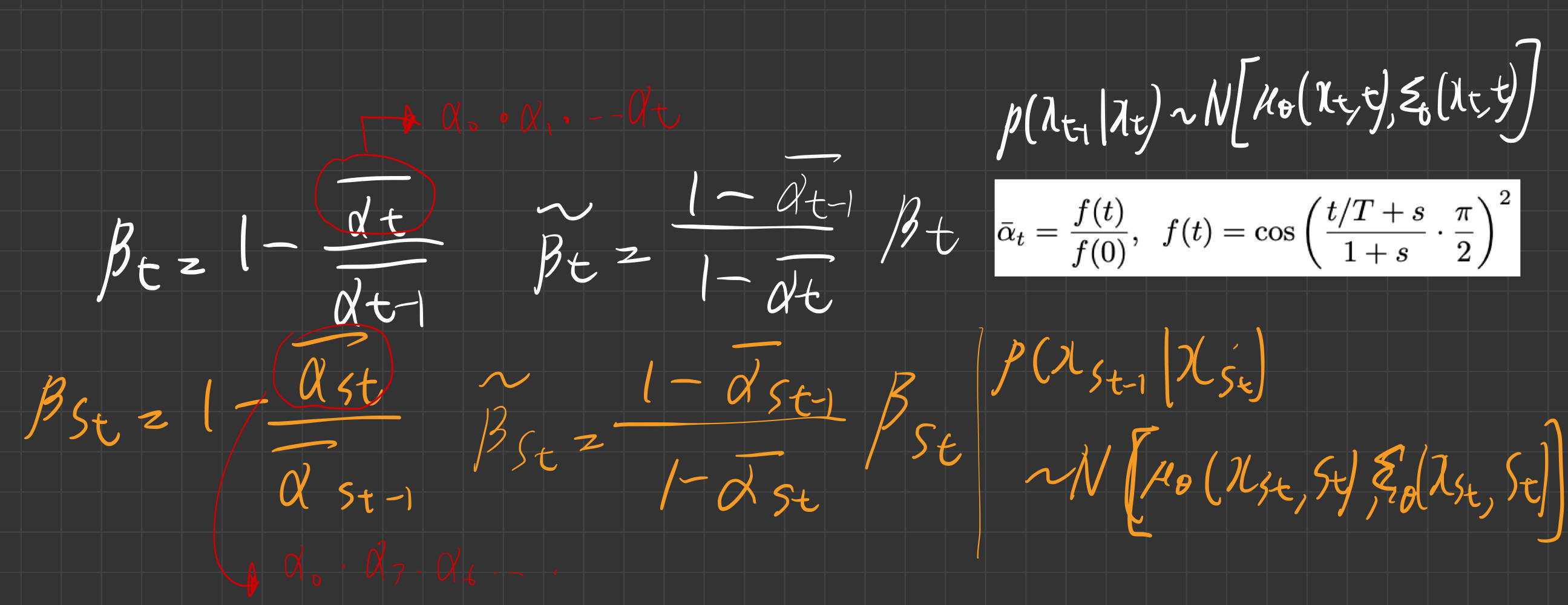
- 위와 같이 새로 sampling variance가 정의됨
- 원래 DDPM은 아래와 같이 inference(sampling) 했는데,

- 4번 수식의 알파 값에,
위 새로운 정의인 알파를 넣어주면 Xt_3 등을 X_0로 부터 한번에 생성할 수 있다는 뜻
4.1. 실험 결과
- sigma가 고정된 모델은 샘플링 timestep이 줄어듬에 따라 성능에 큰 타격을 받았지만,
- sigma를 학습하며 를 사용하는 모델은 좋은 샘플 퀄리티를 유지
- 제시한 세팅(learned sigmas, hybrid loss)은, 학습에 사용한 4000 steps의 1/40인 100 step에서도 좋은 성능을 보였다.
- DDIM과 비교해 보면
- DDIM은 50보다 적은 steps에서는 더 좋은 샘플 퀄리티를 보였지만
- 더 많은 steps을 사용하면, 본 논문에서 제시한 방법이 더 좋은 샘플 퀄리티틀 보였다.
일정한 stride로 timestep을 줄이는 해당 논문의 방식을 DDIM에 적용해 보았는데- 성능이 크게 하락하여
DDIM 논문에서 제시한 quadratic striding 방식을 그대로 사용하였다.- quadratic striding
- noise가 많은 초기 부분에서 timestep을 더 많이 샘플링하고, 후반부로 갈수록 성기게 sampling 하는 방식
- quadratic striding
- 성능이 크게 하락하여
- 반대로
DDIM의 quadratic striding 방식을 본 논문의 방식에 사용해 보았는데- cosine schedule과 quadratic striding의 조합은 샘플 퀄리티를 저하시켰다.
6. DDPM의 scalability 입증
- DDPM은 model size가 커짐에 따라, 연산량이 클 떄 성은이 더 좋아짐 (scaling에 따른 성능 개선이 에측 가능)
Appendix
A. VLB loss 수식
1. Reconstruction Loss (L₀)
목적: 최종 이미지 의 복원 오차 계산
수식:
계산 방법:
1. 모델 출력: 에서 를 예측하는 디코더 네트워크 사용.
2. 이산화: 픽셀값을 256-bin 이산 분포로 모델링 (DDPM[15]).
- 각 픽셀 에 대해 256개 구간 중 하나의 확률 분포 생성.
- Cross-Entropy: 실제 픽셀값과 예측 분포 간의 CE 계산.
2. Reverse Process KL 항 (Lₜ)
목적: 역과정 분포 와 실제 posterior 의 차이 측정
수식:
계산 방법 (Gaussian KL 공식 활용):
1. Forward Posterior:
- 평균:
- 분산:
-
Reverse Process:
- 평균 : 로부터 유도 ()
- 분산 : 학습 또는 로 고정[15].
-
KL Divergence 계산:
- 분산이 고정된 경우(예: ) → 항만 남음[4].
3. Regularization(Prior Matching) 항 (L_T)
목적: 최종 latent 가 표준 정규 분포와 일치하도록 제약
수식:
계산 방법:
1. Forward Process:
- KL 공식 적용:
- 여기서 ,
→ 최종적으로 상수항으로 단순화[6].
- 여기서 ,

ad_official