👨🏫
결측치 데이터를 파악해서 제거하고
우리가 가진 데이터를 토대로 평균도 내보고 이러한 과정을 거쳐보도록 하겠습니다.
1) Null(결측) 데이터 파악하기
isnull().sum()은 해당 데이터프레임의 각 열에서 Null 데이터가 총 몇 개인지를 출력합니다.
👨🏫
isnull()이라는 것 자체가 총 몇개의 Null 행이 있는지를 출력하기 위한 어떤 준비작업이다.- 그뒤에
.sum()을 붙이면, 이제 그 Null(비어있는 그 데이터의 개수를) 쭉 더해서 출력해 주는 것.
print(drink_df.isnull().sum())
>>>>>>>>>>>>결과>>>>>>>>>>>
country 0
beer_servings 0
spirit_servings 0
wine_servings 0
total_litres_of_pure_alcohol 0
continent 23
dtype: int64continent라는 열에서 총 23개의 Null(결측) 데이터가 있음을 확인할 수 있습니다.
이러한 결측 데이터가 포함된 행은 dropna() 라는 함수를 통해서 제거할 수 있습니다.
drink_df.dropna()
빈 데이터가 있었던 행 총 23개가 사라진 것을 확인할 수 있습니다.
👨🏫 제거를 하고 나면 이런식을 원래 193개의 행이 있어야 하는데 빈데이터가 있었던 23개 행이 사라지고 170개의 행만 남은 것을 확인할 수 있다.
2) 각 열의 수치적 정보 파악하기
이제 본격적으로 데이터프레임을 통해서 데이터를 파악해가는 과정을 시작해볼텐데요. 숫자와 같은 수치 데이터를 다루고 있다면, 해당 데이터의 최솟값, 최댓값, 평균값 등을 파악하는 것은 데이터 파악의 가장 첫 걸음입니다.
👨🏫 이렇게 각 열별로 평균이라든지 데이터 갯수나 표준편차나 이런 4분위 수라던가 다 계산을 해서 출력해주는 역할 해주는 것이
describe()입니다. 종합적인 정보를 한번에 볼 수 있다.
데이터가 데이터프레임 형태로 저장된 상황에서 이를 가장 빠르게 파악할 수 있는 방법은describe()를 사용하는 것입니다.
drink_df.describe()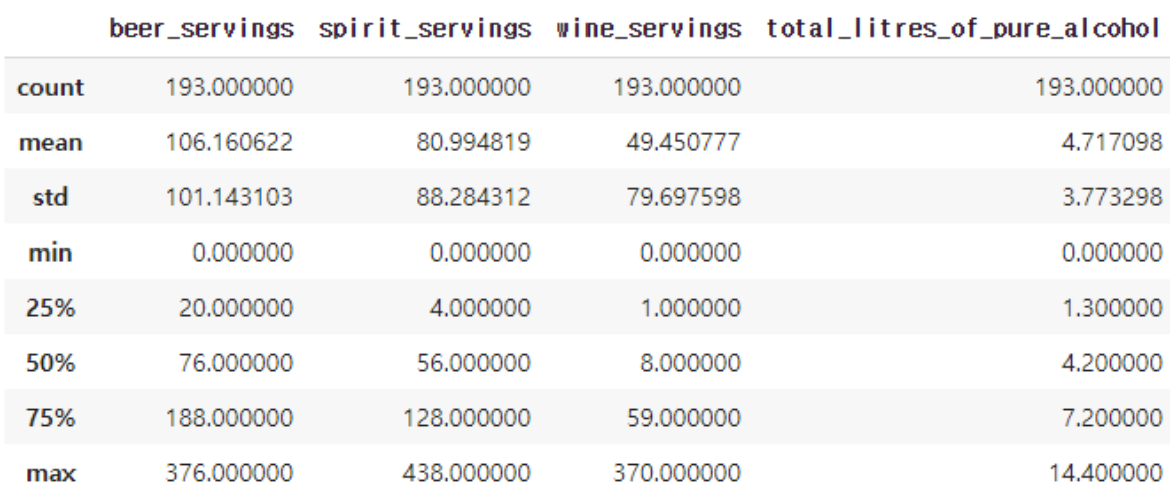
describe()는 데이터프레임의 총 데이터의 수(count), 평균(mean), 표준편차(std), 분위수(25%, 50%, 75%)를 파악하여 출력합니다. 하지만 이는 숫자. 즉, 수치 정보에 국한되어서 계산하므로 문자열 타입의 데이터였던 country 열과 continent 열은 제외되었습니다.
특정 열에 대해서만 출력해볼 수도 있습니다.
👨🏫이렇게 열에 접근한 다음에
describe()를 쓰면 된다.
drink_df[beer_servings.describe()]도 동일한 결과 출력
drink_df.beer_servings.describe()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
count 193.000000
mean 106.160622
std 101.143103
min 0.000000
25% 20.000000
50% 76.000000
75% 188.000000
max 376.000000
Name: beer_servings, dtype: float64
- 하나하나식 접근하고 싶다면 👇
특정 열의 최대값, 최소값, 평균값, 총 합, 카운트도 계산가능합니다.
# beer_servings의 평균
drink_df.beer_servings.mean()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
106.16062176165804
# beer_servings의 최댓값
drink_df.beer_servings.max()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
376
# beer_servings의 최솟값
drink_df.beer_servings.min()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
0
# beer_servings의 총 합
drink_df.beer_servings.sum()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
20489
# beer_servings의 카운트
drink_df.beer_servings.count()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
193
이렇게 바로 계산한 수치를 뽑을 수 있다면, 이 수치를 가지고 계산도 가능하겠죠? mean()으로 평균을 바로 구할 수 있긴 하지만, sum()과 count()를 이용하여 평균을 계산해봅시다.
drink_df.beer_servings.sum()/drink_df.beer_servings.count()
>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>
106.16062176165804
