👨🏫 조건을 걸어서 해당 조건에 만족하는 데이터만 출력하려면 어떻게 코드를 작성해야 하는지.
1) 조건부 로직 사용하기
데이터프레임에 우리가 원하는 조건을 걸어서 해당 조건을 충족하는 값들만을 뽑아오는 것도 가능합니다. 우선 특정 열에 대해서 조건을 걸었을 때 어떤 값을 반환하는지를 봅시다.
데이터프레임의 이름.특정 열의 이름 == '특정값'
이라는 코드는 각 행에서 해당 조건을 만족하는지를 판단하여 만족한다면 True, 아니라면 False의 값을 가지는 시리즈(Series)를 리턴합니다
👨🏫 == 은 파이썬에서 같냐 라고 물어보는 것이다.
drink_df.continent=='EU'
# 같냐고 물어보는 것
>>>>>>>>>>>>결과>>>>>>>>>>>>
0 False
1 True
2 False
3 True
4 False
...
188 False
189 False
190 False
191 False
192 False
Name: continent, Length: 193, dtype: bool
하지만 일반적으로 저런 조건을 걸었을 때 우리가 원하는 건 True와 False로 구성된 시리즈(Series)가 아니라 continent의 값이 'EU'일 때의 데이터프레임 값을 뽑아내는 것일텐데요.
이 경우에는 저렇게 True와 False로 구성된 Series를 다음과 같이 사용해주면 됩니다.
데이터프레임의 이름[True와 False로 구성된 시리즈]
# 출력이 너무 길어져서 상위 20개의 행만 뽑도록 했습니다.
drink_df[drink_df.continent=='EU'].head(20)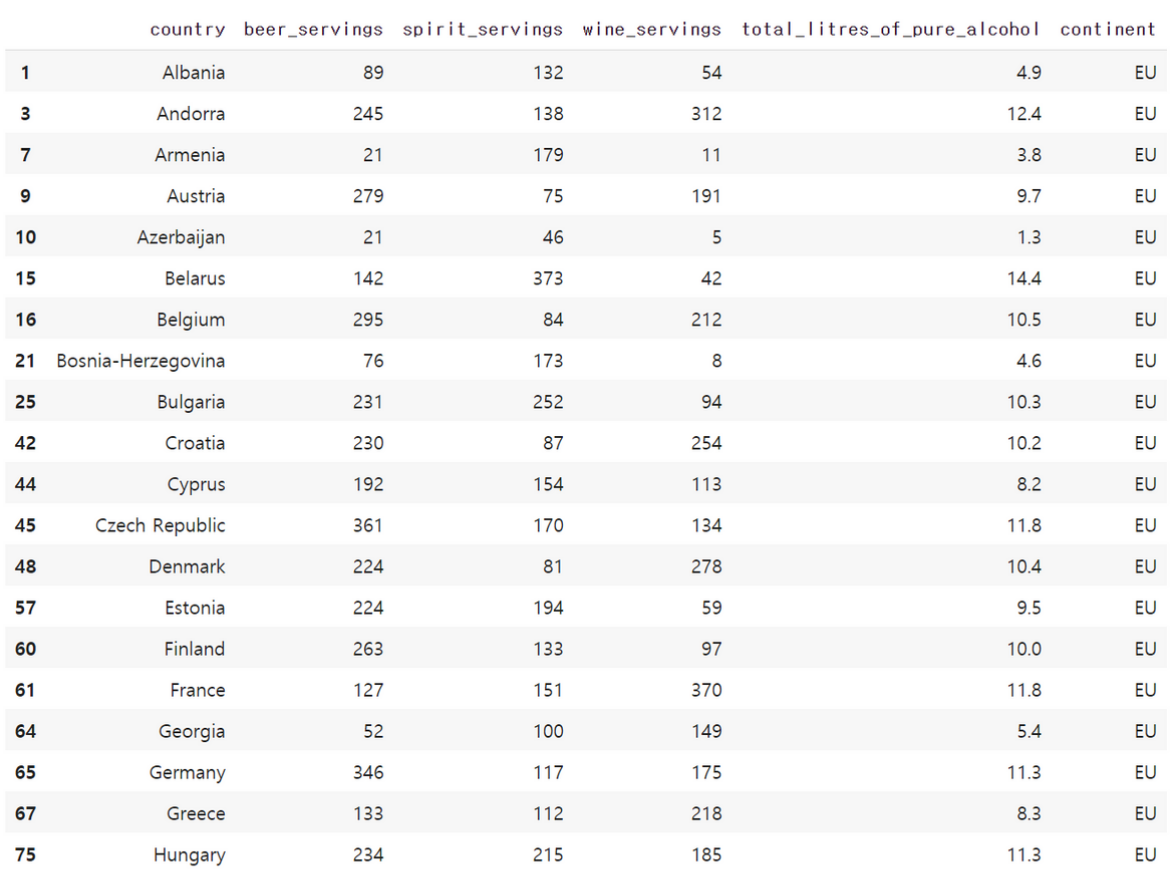
continent의 값을 보면 전부 값이 'EU'인 것을 확인할 수 있습니다. 데이터프레임에서 continent의 값이 'EU'인 경우만을 필터링하여 뽑은 것입니다.
그렇다면 만약 beer_servings의 값이 158보다 큰 경우만을 필터링하고 싶다면 어떨까요?
앞서 데이터프레임의 열을 호출하는 방법으로 다음과 같이 두 가지를 소개했습니다.
데이터프레임의 이름.열의 이름
=데이터프레임의 이름['열의 이름']
다시 말해 데이터프레임에서 beer_servings의 값이 158보다 큰 경우로 필터링하여 데이터프레임을 뽑아내는 코드는 아래의 두 가지 방법이 있습니다.
drink_df[drink_df.beer_servings > 158]
= drink_df[drink_df['beer_servings'] > 158]
# 지면의 한계로 상위 20개만 출력
drink_df[drink_df['beer_servings'] > 158].head(20)
그렇다면 조건을 걸되, 특정 열 몇 개만 출력하고 싶다면 어떨까요?
앞서 특정 열들만을 뽑아서 출력하는 방법을 아래와 같이 소개했었습니다.
데이터프레임의 이름[['특정 열의 이름1, '특정 열의 이름2']]
이를 응용하여
beer_servings의 값이 10 이하이면서country,beer_servings의 두 개의 열만을 뽑아내는 방법은 다음과 같습니다.
ex)drink_df[drink_df.beer_servings <= 10] [['country','beer_servings']]
우선, drink_df[drink_df.beer_servings <= 10]로 조건에 맞는 데이터프레임을 뽑아낸 뒤에 이 데이터프레임에 [['country','beer_servings']]를 붙여서 2개의 열만을 뽑아내는 것이죠.
# 지면의 한계로 20개만 출력
drink_df[drink_df.beer_servings <= 10][['country','beer_servings']].head(20)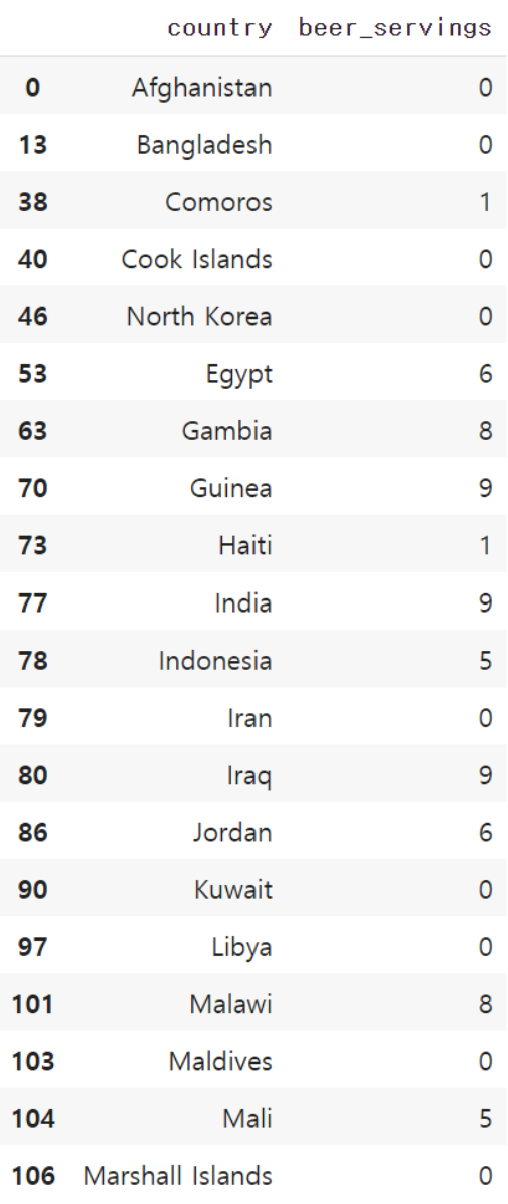
이번에는 조건으로 필터링하여 시리즈(Series)를 얻어낸 뒤에 평균(mean)을 얻어보겠습니다.
drink_df[drink_df.continent=='EU'].beer_servings.mean()
>>>>>>>>>>>>>결과>>>>>>>>>>>>>>>
193.77777777777777
위 코드는 continent의 값이 'EU'인 경우로 데이터프레임을 뽑아내지만, 그 중 beer_servings라는 하나의 열만을 뽑아내므로 (앞서 열을 하나만 뽑을 경우 데이터프레임이 아니라 시리즈가 된다고 언급한 바 있습니다.) 시리즈로 변환되며, 시리즈에 대해서 mean()을 사용하여 평균값을 뽑아내게 됩니다. 결과적으로 continent의 값이 EU인 beer_servings 열의 평균값(mean)을 구하게 되는 것이죠.
이번에는 beer_servings 열의 평균값을 조건에 넣어보겠습니다.
drink_df[drink_df.beer_servings > drink_df.beer_servings.mean()]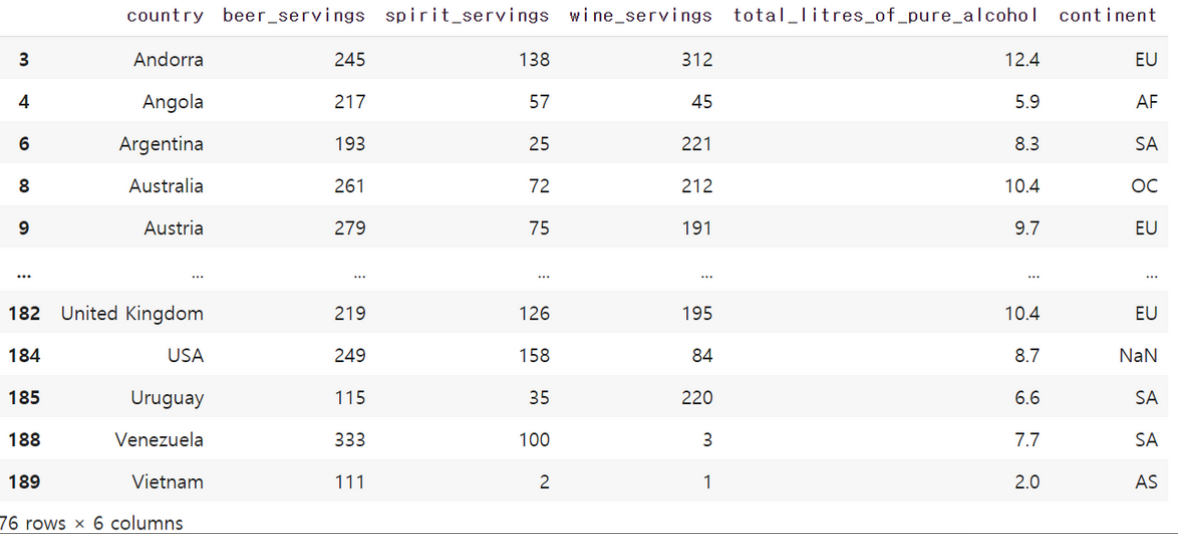
해당 열에 null 값(결측값)이 존재하는지 유무에 대한 True와 False의 시리즈(Series)로 얻어내는 방법은 해당 열의 isnull()을 하면 알 수 있습니다. isnull()은 해당 행에 Null 값이 들어있는 경우만 True를 리턴하고, 아니라면 False를 리턴합니다.
drink_df.continent.isnull()
>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>
0 False
1 False
2 False
3 False
4 False
...
188 False
189 False
190 False
191 False
192 False
Name: continent, Length: 193, dtype: bool이를 이용하면 데이터프레임에서 특정 열에 Null 값이 위치한 경우만 뽑을 수 있습니다.
drink_df[drink_df.continent.isnull()]
continent의 값에 NaN 값(결측값을 의미)인 경우만 출력되는 것을 확인할 수 있습니다. 즉, 이 데이터들은 다른 열에는 값이 다 존재하지만 continent의 열에는 실질적으로 값이 존재하지 않는다고 해석할 수 있습니다.
2) AND, OR, NOT 연산자 사용하기
AND나 OR 또는 NOT과 같은 연산자를 사용하여 여러 개의 조건을 동시에 사용하거나, 조건문 자체를 반대로 해석하도록 할 수도 있습니다.

데이터프레임의 AND, OR, NOT은 각각 &, |, ~에 해당됩니다.
- & : AND
- | : OR
- ~ : NOT
다시 말해 다음과 같이 사용할 수 있습니다.
A조건 & B조건: A조건과 B조건 모두 만족하는 경우A조건 | B조건: A조건 또는 B조건 둘 중 하나를 만족하는 경우~A조건: A조건을 만족하는 경우의 반대. 즉, A조건을 만족하지 않는 경우.
물론 실제로는 조건이 2개 이상일 수도 있고, 이들을 섞어서 사용하는 것도 가능하므로 위 케이스보다 다양하게 사용할 수 있습니다. 여기서는 가장 기본적인 위의 세 가지 경우에 대해서만 다뤄보겠습니다.
우선 NOT을 사용한 경우를 봅시다.
# NOT 조건
drink_df[~(drink_df.continent=='EU')]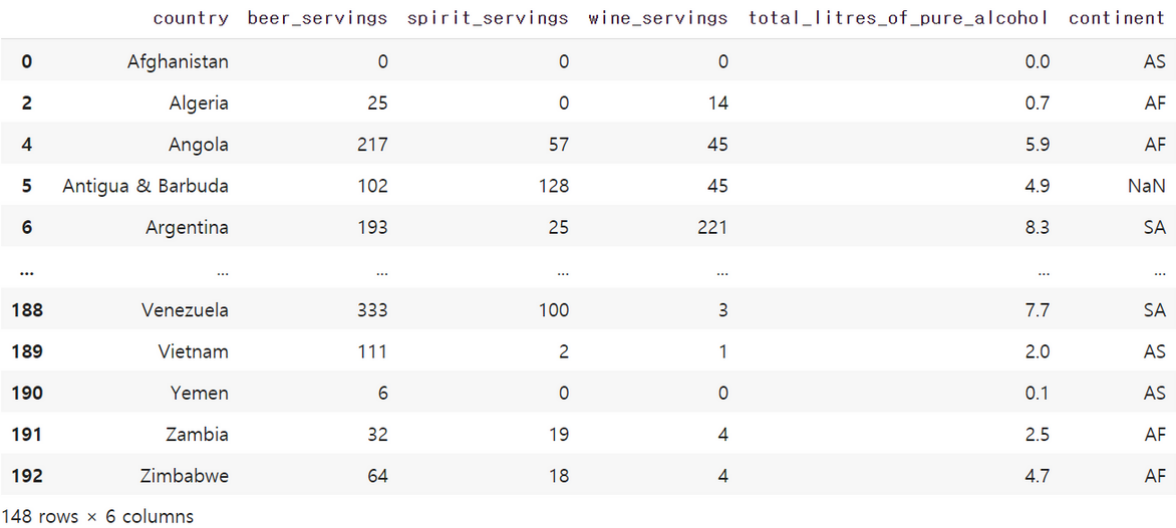
위 코드는 continent의 값이 'EU'가 아닌 경우만을 필터링하는 코드입니다.
이번에는 두 개의 조건 모두가 참인 경우만을 필터링하는 AND를 사용해봅시다.
# AND 조건
drink_df[(drink_df.continent=='EU') & (drink_df.wine_servings > 300)]
위 코드는 continent의 값이 'EU'이면서 wine_servings의 값이 300보다 큰 경우만을 필터링합니다. 두 개의 조건을 만족하는 행은 193개의 행 중 단 3개뿐입니다.
하지만 두 가지 조건을 모두 만족하는 것이 아니라 단, 한 개만 만족하더라도 데이터를 뽑으려고 한다면 AND를 단지 OR로 바꿔주기만 하면 됩니다. 두 개의 조건은 같지만 AND를 단순히 OR로 바꾼 경우에는 데이터가 몇 개나 뽑히는지 확인해봅시다.
len(입력)을 사용하면 입력의 길이를 계산하여 알려줍니다. 데이터프레임의 이름을 입력으로 할 경우에는 데이터프레임의 행의 길이를 출력합니다.
# OR 조건
len(drink_df[(drink_df.continent=='EU') | (drink_df.wine_servings > 300)])
>>>>>>>>>>>>>>>>>결과>>>>>>>>>>>>>>
45AND 조건을 사용하였을 경우에는 행이 3개밖에 없었지만, 이번에는 45개로 훨씬 많습니다.
