1) 로직과 수치 정보의 결합
drink_df에서 total_litres_of_pure_alchohol의 값이 최대값인 경우의 country 열을 출력해봅시다. 이를 구현하기 위해서 고려해야할 것은 총 두 가지입니다.
- 특정 열의 최대값을 구하는 방법이 무엇이었는지
- 특정 열만을 출력하는 방법이 무엇이었는지
drink_df[drink_df.total_litres_of_pure_alcohol ==
drink_df.total_litres_of_pure_alcohol.max()]['country']
>>>>>>>>>>>>>>>출력>>>>>>>>>>>>
15 Belarus
Name: country, dtype: object우선 drink_df.total_litres_of_pure_alcohol.max()를 통해서 total_litres_of_pure_alcohol열의 최댓값을 구하고, 이를 로직에 적용하여 출력할 수 있습니다.
이번에는 drink_df에서 wine_servings의 값이 300보다 크거나, beer_servings의 값이 300보다 크거나, spirit_servings의 값이 300보다 큰 경우의 country열의 데이터를 모두 카운트하였을 때의 숫자를 출력해봅시다. 이를 구현하기 위해서 고려해야할 것은 총 두 가지입니다.
- 다수의 조건을 '또는'으로 한 번에 사용하는 방법이 무엇이었는지 생각해봅시다.
- 숫자를 '카운트' 하는 방법이 무엇이었는지 생각해봅시다.
drink_df[(drink_df.wine_servings > 300) |
(drink_df.beer_servings > 300) |
(drink_df.spirit_servings > 300)].country.count()
>>>>>>>>>>>>>출력>>>>>>>>>>>>>>>>>
18
2) 정렬하기
데이터를 특정 기준으로 정렬해서 볼 수도 있습니다.
정렬해서 보는 방법은 다음과 같습니다.
데이터프레임의 이름.sort_values('정렬 기준이 되는 열의 이름')
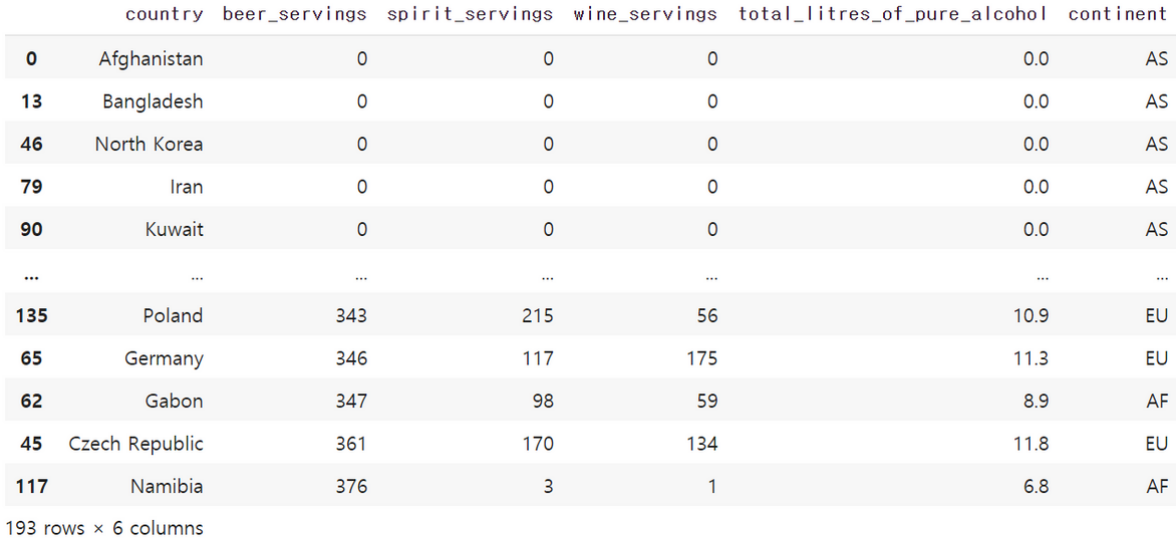
# beer_servings을 기준으로 정렬
drink_df.sort_values('beer_servings')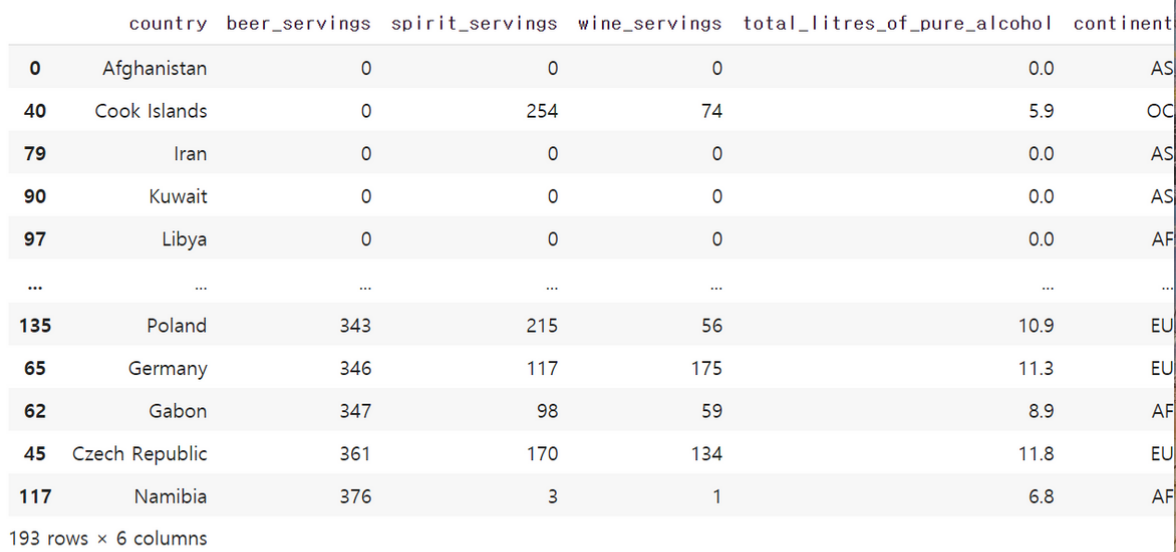
beer_servings의 열을 보면 오름차순을 기준으로 정렬된 것을 확인할 수 있습니다.
기본적으로는 오름차순으로 정렬되지만, 만약 내림차순으로 정렬하고 싶다면
데이터프레임의 이름.sort_values('정렬 기준이 되는 열의 이름', ascending=False)
sort_values의 인자로 ascending=False를 추가해주면 됩니다.
# 내림차순으로 정렬
drink_df.sort_values('beer_servings', ascending=False)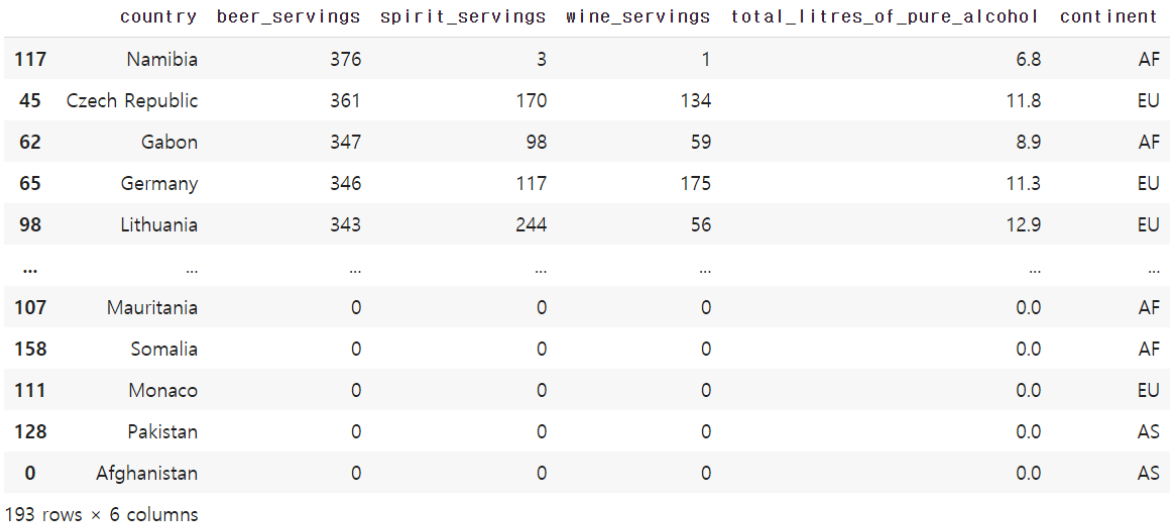
정렬의 기준은 하나의 열이 아니라 다수의 열일 수 있습니다. 열의 이름들을 원소로하는 리스트를 sort_values의 입력으로 사용하면 해당 열들을 기준으로 정렬을 수행합니다.
# 2개의 열을 기준으로 정렬
drink_df.sort_values(['beer_servings', 'wine_servings'])