5-3 탐색적 데이터 분석 (2) - 데이터 집계
👨🏫 본격적인 시작. 고객 데이터를 보면서 토대로 어떤 가설들을 세울수 있을지 생각해보고, 그 다음 이용량 데이터를 좀 보면서 이용량을 토대로 어떤 정보를 알아 낼 수 있는지 생각해보자.
2) 데이터 집계 - 가설 발견
👨🏫 customer_join 이라는 데이터프레임이 만들어졌는데 이것을 보면서 한번 어떤 가설을 세울수 있는지 생각해보자.
우선grouby를 써서 고객들이 좀 어떤 클래스를 많이 듣는지를 한번 보자.
-> 클레스별 고객의 명수를 출력하면 된다.count()를 쓰기.
데이터 가공을 완료했으니 고객 데이터에 대해서 탐색해봅시다.
우선 고객들이 어떤 클래스를 많이 듣는지 확인해봅시다.
customer_join.groupby("class_name")["customer_id"].count()
>>>>>>>>>>>>>>>실행 >>>>>>>>>>>>>>>>>>>>>>>
class_name
0_종일 2045
1_주간 1019
2_야간 1128
Name: customer_id, dtype: int64종일 클래스를 가장 많이 듣고
이 수치는 전체 수치의 거의 절반에 달합니다. 주간 야간은 숫자가 크게 차이나지는 않습니다.
👨🏫 이번에는 캠패인 위주로 groupby 해봄
- 이번에는 고객들이 어떤 행사에 많이 속해있는지 확인해봅시다.
customer_join.groupby("campaign_name")["customer_id"].count()
>>>>>>>>>>>>실행 >>>>>>>>>>>>>>>
campaign_name
0_입회비반액할인 650
1_입회비무료 492
2_일반 3050
Name: customer_id, dtype: int64일반이 압도적으로 많고, 그 후에는 입회비 반액, 입회비 무료 순입니다.
👨🏫 아무래도 이벤트에 가입안하고 평소에 가입한 사람이 많을수 있겠죠. 총합을 따져봤을때.
- 고객들의 성별은 어떨까요?
customer_join.groupby("gender")["customer_id"].count()
>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>>>>
gender
F 1983
M 2209
Name: customer_id, dtype: int64
남성 회원이 조금 많습니다. 큰 차이는 없다.
👨🏫
여기서 여러분들이 뭔가 더 생각해 낼 수 있겠죠. 만약에 성별로 남성 회원들은 어떤 클래스에 많이 속해 있을까? 가 궁금할수도 있고, 종일클레스에 속한 사람들은 어떤 캠페인에 많이 가입되있을까? 라는게 궁금할수 있는데 파이차트 등을 그려보면서 비교를 시각화 해서 눈으로 확인가능. 그런식으로 생각하는 가설들을 나름대로 분석을 진행해 볼수 있다.
그 가설에 대해서는 진행안하고 좀 있다가 다양한 가설에 대해서 진행해보겠다.
그렇다면 현재 가입된 회원과 탈퇴한 회원의 수를 비교해봅시다.
customer_join.groupby("is_deleted")["customer_id"].count()
>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>
is_deleted
0 2842
1 1350
Name: customer_id, dtype: int64이쯤 탐색하다보면 여러분들 스스로 어떤 가설들이 생각날 수 있습니다. 행사에 대한 성별 간 선호도라던가, 올 해 가입한 인원들은 어떤 특징들을 갖고있었나 등. 이쯤 얻은 가설들은 집계를 통해서도 얻는 것도 중요하지만, 현장의 목소리.
즉, 이 데이터의 경우에는 회원들의 목소리를 직접 청취해보시는 게 좋습니다. 그렇게 되면 더 좋은 가설이나 인사이트들을 얻을 수 있는 경우가 많기 때문입니다.
3) 데이터 집계 - 통계량 파악
👨🏫일단은 이용량 데이터로 어떤 것을 파악해 볼수 있는지 인사이트를 얻어보는 과정을 진행해보자.
- uselog 여기에 이용량 데이터를 불러 왔었는데, 날짜있고 어떤고객이 어떤날에 이용했는지 나열되어 있다.
- log_id 부분은 의미를 가지고 있다기 보다는 해당이용. 그 자체에 대한 어떤 코드 값.이라고 생각하면 됨. 언제 누가 이용했느냐에 따라서 이용할때마다 log_id가 바뀜. 데이터별로 고유한 값이다.
이제 이용 이력 데이터(uselog)로 알 수 있는 것을 생각해 봅시다.
이용 이력 데이터는 고객 데이터와는 달리, 시간적인 요소를 분석할 수 있습니다.
예를 들어, 한 달 이용 횟수의 변화와 회원이 스포츠 센터를 정기적으로 이용하는지, 비정기적으로 이용하는지와 같은 것을 알 수 있습니다.
이번에는 월 이용 횟수의 평균값, 중앙값, 최댓값, 최솟값과 정기적 이용 여부를 작성해서 고객 데이터에 추가하겠습니다. 최종적으로 고객마다 월 이용 횟수를 집계한 데이터를 작성해 봅시다.
우선 usedate 열의 데이터 타입을 datetime으로 변환합니다. 그 후 201804와 같은 형식으로 변환한 '연월'이라는 열을 추가합니다.
👨🏫 월별로 어떤 특정 사용자가 몇번이나 이 센터를 이용했는지 확인해보겠다.
- 월별로 한번 묶어 줘야함. 지금은 일별로 데이터가 되어있어서, 월별로 열을 하나 더 만들어 줘야 한다.
- 일단 한번 uselog.info() 보면 usedata가 저번 주차에서도 봤듯이 날짜 시간 이런거는 datatime이라는 자료형이 있는데 이거는 object 로 불러와져 있다. 그래서 이것을 datatime 으로 불러오는 형식이 여러가지 있었는데 이번에는 apply를 써서 바꾸겠다. 바꿔줘야 거기서 날짜, 연도 같은 것들을 쉽게 추출할 수 있다.
.apply(pd.to_datetime)- 바꾸고 연월이라는 열을 하나 만들겠다. 연월 까지만 가지고 오면 되니깐
.dt.strftime("%Y%m")이렇게 해서 딱 그부분만 특정하게 추출해서 가져올수 있다. 지금은 %y가 년이고 %m 이니깐 두개를 붙여놓겠다. 그럼 년월. 딱 숫자가 추출되서 연월이라고 저장됨.
# usedate열을 데이터프레임 타입으로 변환
uselog["usedate"] = uselog["usedate"].apply(pd.to_datetime)
#201804와 같은 데이터의 형식으로 변환
uselog["연월"] = uselog["usedate"].dt.strftime("%Y%m")
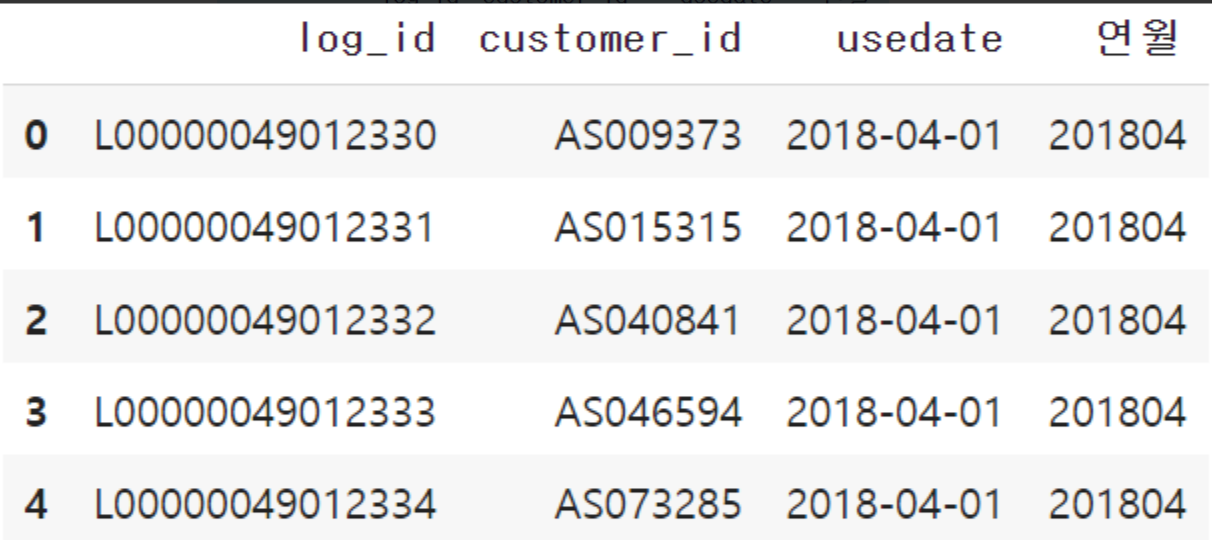
uselog.head()
>>>>>>>>>>>>
👨🏫 이제는 연월별 고객별 이용량. groupby 쓰면 되겠죠. 그리고 월별이용량은 uselog_months라는 이름으로 변수 저장해서.
as_index=False연월부분을 인덱스로 만들지 않고 연월이라는 새로운 열로 계속 유지하겠다는 뜻이다. 원래 이게 없으면 연월부분이 0,1,2,3 이부분처럼 여기에 연월 데이터가 들어가는건데 데이터가져올때 번거로울수 있어. 그래서 연월도 이렇게 하나의 열로 만들어라 라고 말하는 것이다.- count 하면 이용량이 나오는 것.
연월과 고객 ID별로 groupby을 이용해서 이용 횟수를 집계합니다.
이제 연월에 따른 고객들의 이용 횟수가 기록됩니다.
이 값은 log_id와 usedate 두 개의 열에 기록이 되었습니다.
# 고객별 연월 이용 횟수를 카운트
uselog_months = uselog.groupby(["연월","customer_id"], as_index=False).count()
uselog_months.head()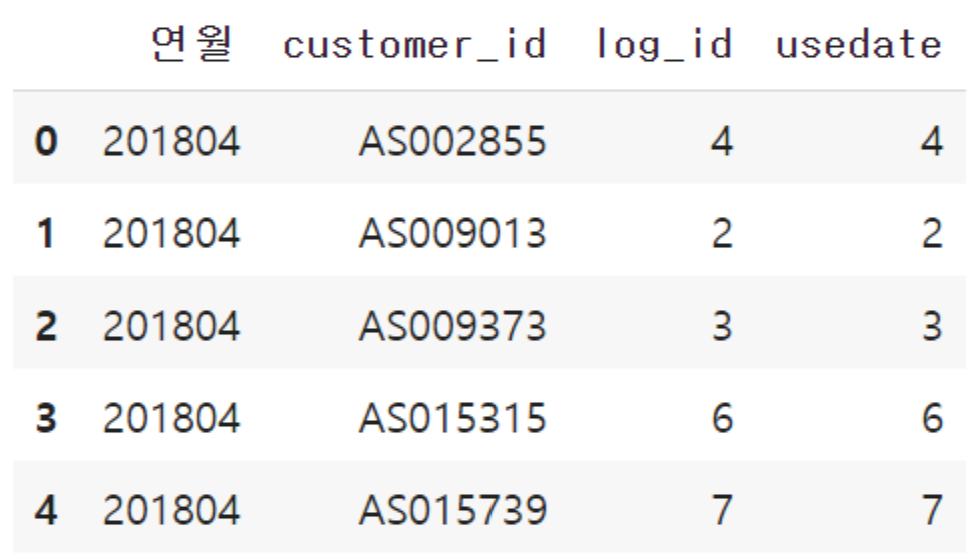
👨🏫 이렇게 딱 봤을때 log_id 개수랑 usedata개수가 들어가 있다. 근데 사실 둘중에 뭐를 남기던 상관없이 둘다 이용량에 해당하는 것은 마찬가지. usedata는 삭제하고 log_id는 카운트로 바꿔주겠다.
- rename 함수를 쓰면 열 이름을 바꿀수 있다. count (이용량)이름으로 바꿔주고
- inplace=True 이렇게 해야 이 데이터 프레임에서 반영되는 것. 없으면 새 변수에 저장되게 상황만 만드렁 주는 것.
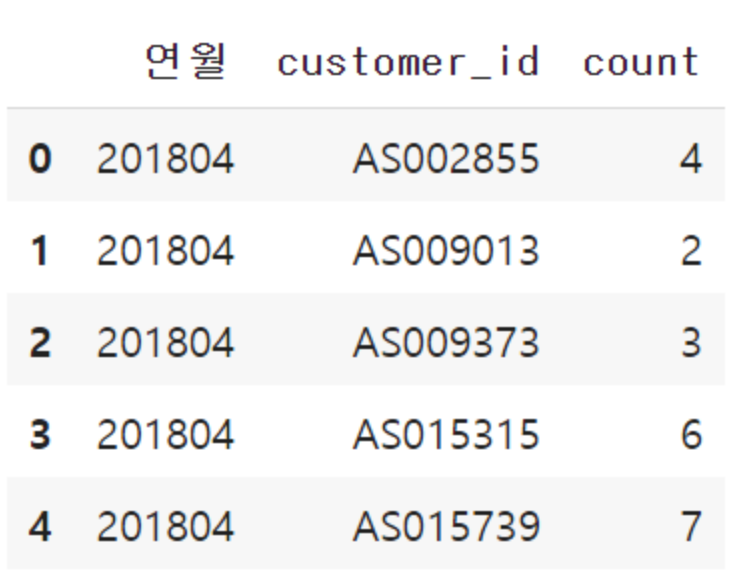
집계는 log_id를 카운트하면 되므로 필요 없는 usedate열 삭제합니다. 또한, log_id 열을 count라는 이름으로 변경합니다.
# 카운트한 값을 count열이라 명명
uselog_months.rename(columns={"log_id":"count"}, inplace=True)
# usedate열을 삭제
del uselog_months["usedate"]
# 최종 결과 데이터프레임을 상위 5개의 행을 출력
uselog_months.head()
👨🏫 이제는 수치 정보를 파악해 보자. 그러니깐 고객에 따라서 연월별 평균 이용량은 어떻게 되는가. 어떤 고객이 제일 많이 이용한 그 달에 이용량은 또 어떻게 되는지 분석해 보면 좋곘죠.
- 이런것들은 customer이라는 이름으로 데이터 프레임을 만들것이고,
- month.groupby() 함. 그니깐 이 고객별 이용량의 평균. 혹은 최댓값. 이런것을 출력하고자 하는 것이라. -> 고객별 이용량. 거기서 뭐 평균구하고 싶으면 agg
- agg 수치정보 여러게 출력하는 것 사용.
- median은 중간값. 전체 데이터를 쭉 일렬로 나열했을떄 딱 중간에 있는 값. 상위 50%지점 같은. Q2 같은 동일한 개념이다.
- 일단은 이렇게 4개를 한번 출력해보기.
- .reset_index(drop=False) 이렇게 해주면 인덱스 값들이 번호 형태로 남아있고 customer_id는 열로써 다시 열에 복귀하게 됨.
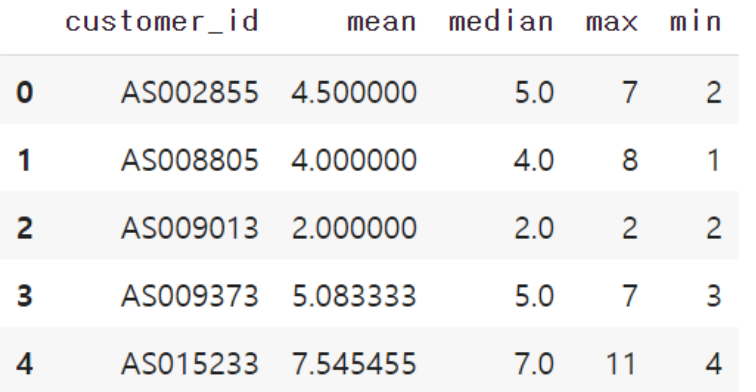
최종적으로 고객에 따라서 연월에 몇 번 이용했는지를 기록한 데이터가 완성되었습니다.
가령, 고객 AS002855는 2018년 4월에 4번 이용했음을 알 수 있습니다. 이제, 고객별로 평균값, 중앙값, 최솟값을 집계해 봅시다.
uselog_customer = uselog_months.groupby("customer_id")["count"].agg(["mean", "median", "max", "min" ])
uselog_customer = uselog_customer.reset_index(drop=False)
uselog_customer.head()
>>>>>
👨🏫 여기까지 진행했고 다음시간에는 이 이용자가 정기적으로 이용하는 사람인지 비정기적 이용하는 사람인지 나누기 위해 열을 하나 더 만들어 줄 것이다. 1,0으로 하는 열을 하나 만들것이다. 이런 1,0으로 특정한 요소의 존재여부를 표시하는 것을 플래그라고 한다. 다음주의 주제가 플래그 작성하는 것이 주제.
1행에서 groupby로 평균값, 중앙값, 최댓값, 최솟값을 집계합니다. 2행에서는 groupby의 영향으로 customer_id가 index에 들어 있기 때문에 이것을 칼럼으로 변경합니다. 고객 AS002855는 평균값 4.5, 중앙값 5, 최댓값 7, 최솟값 2인 것을 알 수 있습니다. 이렇게 고객별 월 이용 횟수 집계가 끝났습니다. 다음은 정기적/비정기적 스포츠 센터 이용 여부를 1/0 으로 작성합니다.
정기적으로 이용한다면 1, 비정기적으로 이용한다면 0 이라고 하는 것입니다. 이렇게 1/0 으로 특정한 요소의 존재 여부를 표시하는 것을 **플래그**라고 합니다.
