2-10 영화 줄거리를 이용해서 장르 분류 해보기 (1) - 기초 개념
1) 머신러닝 원리 맛보기
인공지능: 숫자. 숫자를 토대로 연산해서 숫자를 예측하는 과정
ex) 공부시간*a+b = 성적
공부시간에서 성적을 예측하는 인공지능을 만든다는 것 = 이 방정식에서 a와 b 값 알아내는 것.
'학습' : 수많은 데이터를 주고 데이터가 저 식에 가장 적합하도록, 일치하도록 a와 b값을 구하는 것
- 기계가 처음에는 a와 b 값을 무작위로 설정함. 데이터가 들어오는 것에 따라서 주어진 데이터를 토대로 a와 b를 계속 수정해 나감.
- a 값을 가중치라 표현하기도 함.
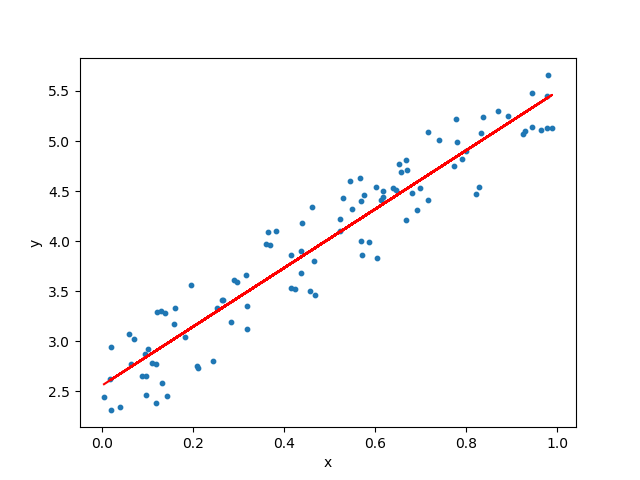
- a,b 값을 어떻게 정하느냐에 따라 직선 달라짐.
- a,b 값을 알아낸다는 것은 데이터와 가장 일치하는 듯한 직선을 하나 긋는 행위.
- 그러나 이 모든 데이터를 정확하게 설명하는 직선을 그리는 것은 불가능.
- 경향성을 띄는 선을 그려야 새로운 데이터가 들어왔을때 예측가능
- 어느정도 오차가 발생할수 있음을 받아들여야 함.
머신러닝의 과정은 a,b값을 예측하면서 최대한 줄여나가는 과정.
최적화 : 오차를 적게 만들수 있도록 수정 (미분, 편미분 하는데 파이썬이 해줌)
이런식으로 기계는 a, b 값을 처음에는 무작위로 설정했다가, 엄청난 속도로 연산을 하고 주어진 데이터를 기반으로 오차를 비교하면서 최적의 a, b 값을 찾아나갑니다. 이러한 과정을 '최적화' 라고 말을 합니다.
최적화의 세부적인 원리는 선형대수와 관련한 지식이 있어야만 이해를 할 수 있습니다. 그런데 우리가 직접 최적화를 할 필요는 없습니다. 최적화와 관련한 알고리즘이 이미 다 구현이 되어있기 때문이죠!
2) 줄거리만 보고 장르를 예측할 수 있을까?
예시)
이번에는 머신러닝 (Machine Learning) 에 대해서 본격적으로 공부를 시작할건데, 어렵지 않습니다. 그냥 인간이 학습하는 과정과 똑같다고 생각해보시면 쉽습니다.
수많은 영화의 줄거리와 장르를 어떤 사람에게 알려주고, 영화 D 에 대한 줄거리를 보고 예측하라고 하면, 그 사람은 학습한 장르 중 하나를 말해낼 수 있을 겁니다! 실제 장르와 일치하지 않더라도, 예측은 할 수 있겠죠?
이러한 분류들을 AI 알고리즘을 통해 수행한다고 하면 일반적으로 이런 과정

벡터화를 시킨 줄거리를 토대로 기계한테 해당 줄거리는 어떤 특정한 장르에 해당한다고 지속적으로 학습을 시키는 것입니다. 그렇게 학습시킨 결과를 모델 (Model) 이라고 합니다.
여기서 중요한 점은, 기계는 사람과 다르게 글자를 바로 이해하지 못합니다. 그래서 기계도 글로 되어있는 입력을 받을 수 있도록 벡터화 (Vectorization) 의 과정을 거치는 것입니다.
벡터화 (Vectorization) 는 그저 단어를 숫자로 치환하는 것이라고 생각하면 쉽습니다. 벡터가 정확히 무엇인지 꼭 이해하실 필요는 없습니다.
벡터 ; 어떤 공간 상의 위치. 점 하나하나가 백터
https://projector.tensorflow.org/
이와 같이 오늘 공부할 내용을 텍스트 분류 (Text Classification) 라고 합니다.
💡 무엇을 할수 있는가 ?
우리가 평소에 쉽게 접할 수 있는 텍스트 분류의 영역으로는 예를 들어 '스팸 메일 자동 분류', '사용자의 리뷰로부터 긍정, 부정을 판단하는 감성 분류', '포탈 사이트가 언론사의 뉴스들을 문화, 정치 등 자동으로 분류하여 보여주는 뉴스 카테고리 분류' 등이 있습니다.
텍스트 분류에도 여러 종류가 있는데 대표적으로
- 클래스가 2개인 경우를
이진 분류 (Binary Classification)이라고 하고, - 클래스 3개 이상인 경우를
다중 클래스 분류 (Multiclass Classification)이라고 합니다.
예를 들어 이진 분류에는 메일이 스팸인지 아닌지를 결정하는 스팸 메일 분류기가 대표적인 예일 것입니다.
오늘 우리가 하게 될 텍스트 분류는 다중 클래스 분류(Multiclass Classification)에 속합니다.
2-11 영화 줄거리를 이용해서 장르 분류 해보기 (2) - 데이터
👨🏫 데이터 불러와서 어떻게 되어있는지 탐색하자.
네이버 영화 줄거리 데이터를 크롤링을 해놨긴 하지만 그 데이터의 양이 예측 모델을 만들기 위해서는 좀 부족하다. 예측모델의 경우 많은 데이터가 있어야만 좀 정확한 모델을 구축할 수 있다. 특히, 영화 장르 경우, 너무 많은 장르가 있어서 장르별로 어떤 영화가 있는지 최대한 많이 기계한테 알려줘야 새로운 줄거리를 받았을떄 이 장르에 해당한다 라고 정확하게 답할수 있다.
네이버 줄거리 데이터를 이용할수 없고 이미 누군가가 거의 10만개 가까이 크롤링 해놓은 IMDb 줄거리 데이터를 이용해서 같이 진행해 볼 것이다.
3) IMDB 줄거리 데이터 탐색하기
▶ [코드스니펫] 캐글 IMDb 장르 분류 데이터
IMDb 에 있는 줄거리랑 장르 데이터를 크롤링 해온 것이다. 캐글사용자가 올려놓은 것. 출처.
우리가 사용할 파일은 train_data.txt , test_data_solution.txt 파일 입니다.
- 왜 두개인가? 여기서 이해하셔야 될 것이
훈련 데이터와테스트 데이터의 차이입니다. 둘은 학습한 모델의평가를 위해서 구분됩니다.
👨🏫 두개 다 똑같은 영화 정보들이 들어가 있다.영화 제목, 장르, 줄거리 그런데, 차이점은 평가할 때 차이가 난다.
훈련 데이터경우 줄거리랑 장르 두개 다 기계한테 알려줌. 이 줄거리의 경우 이런 장르에 해당하는구나 라고 수많은 데이터를 보면서 학습함.test 데이터는 학습 안하고 줄거리만 주고 장르를 맞춰보라고 한다.
-> 실제 이 줄거리의 장르가 무엇인지 모른체로 기계는 줄거리를 받아들이게 되고, 이것을 토대로 훈련데이터로 학습한 결과에 의하면 이 줄거리 A는 이 장르에 해당한다고 대답해주는 것이다. 그렇게 했을때 실제 A의 장르랑 일치하면 정확도가 상승하고, 그렇지 않으면 정확도 하락.
예측모델의 경우, 많은 데이터가 있어야 정확하게 예측 가능.
훈련 데이터는 우리가 예측하고자 하는 값까지도 일단 다 알려주면서 학습을 시키기 위한 데이터. 기계에게 일정한 내용을 학습시키기 위한 데이터.
줄거리와 장르를 알려줌. 관계를 학습.테스트 데이터는 이 데이터로는 기계가 더 학습을 하지 않음. 그냥 줄거리만 주고 시험용으로 장르를 예측해보라고 주기 위한 데이터.
맞추면->정확도가 상승하고
이런식으로 평가를 한다.
훈련 데이터는 기계 속으로 답이 한번식 거쳐 갔으니깐, 아예 기계가 답을 한번도 보지못한 테스트 데이터 를 만들어서 더 정확한 평가지표를 만들기 위해 두 데이터를 구분함.
- 다운받고 colab에 업로드. 버튼누르거나 드레그해서 업로드. 노란색 다 채워질때 까지 기다리기.

해당 텍스트 파일은 아래처럼 생겼는데, ::: 을 이용해서 번호 / 영화 제목 / 장르 / 줄거리 가 구분이 되어있습니다. 이를 이용하면 쉽게 파일을 불러올 수 있습니다.

👨🏫 끝에 names라고 해서 명시해 놨는데, 그냥 불러오게 되면 이런식으로 열마다 라벨값. 해당 열이 무엇해당하는지 똑바로 안불러와지니깐 명시를 꼭 해줘야 이 부분이 무엇인지. 데이터 프레임 자체에 명시할수 있다.
import pandas as pd
# sep=":::" 을 이용해서, 열 구분을 ::: 로 해서 불러오라고 말해준다.
train = pd.read_table('train_data.txt', sep=":::", names=['Index', 'Title', 'Genre', 'Content'])
test = pd.read_table('test_data_solution.txt', sep=":::", names=['Index', 'Title', 'Genre', 'Content'])1) 잘 불러와졌는지, head() 함수를 이용해서 확인.
train.head(3) #위에 있는 3줄 출력 >>>>>>>>>>실행

2) 불러왔으면, infor() : 총 몇 개의 데이터로 이루어져있는지를 알아봅시다.
train.info() test.info() >>>>>>>>>>>>>>>>실행 >>>>>>>>>>>>>>>>>>> <class 'pandas.core.frame.DataFrame'> RangeIndex: 54214 entries, 0 to 54213 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Index 54214 non-null int64 1 Title 54214 non-null object 2 Genre 54214 non-null object 3 Content 54214 non-null object dtypes: int64(1), object(3) memory usage: 1.7+ MB <class 'pandas.core.frame.DataFrame'> RangeIndex: 54200 entries, 0 to 54199 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Index 54200 non-null int64 1 Title 54200 non-null object 2 Genre 54200 non-null object 3 Content 54200 non-null object dtypes: int64(1), object(3) memory usage: 1.7+ MB
훈련 데이터는 54214 개,테스트 데이터는 54200 개 총 약 11만개 정도 영화가 존재
3) .unique() 함수 활용
Q. 어떤 장르가 있는가?
train['Genre'].unique()A. 총 27개 장르
array([' drama ', ' thriller ', ' adult ', ' documentary ', ' comedy ', ' crime ', ' reality-tv ', ' horror ', ' sport ', ' animation ', ' action ', ' fantasy ', ' short ', ' sci-fi ', ' music ', ' adventure ', ' talk-show ', ' western ', ' family ', ' mystery ', ' history ', ' news ', ' biography ', ' romance ', ' game-show ', ' musical ', ' war '], dtype=object)
앞으로는 이 장르를 클레스라고 표현할 것임. 그러니깐 어떤 영화가 1번 클래스에 해당한다 2번 클래스에 해당한다 할것인데, 클래스 라고 하면 장르를 말하는 거라는 것 알기. 분류를 하고자 하니 분류되는 그 분류 값을 클래스라고도 한다.
4) 데이터 전처리
👨🏫 줄거리라는 데이터로 장르를 예측할려고 하는 것이니깐, 줄거리가 어떻게 보면 x값 독립변수. 줄거리로 장르가 결정된다 생각하니깐 줄거리에 영향받는 장르가 y값 종속변수
줄거리로 장르가 결정된다.
줄거리가
독립변수 (X)이고, 장르가종속변수 (Y)가 됨.
1) 장르와 줄거리가 한 행에 같이 포함되 있어서 나눠줄 것이다.
y_train = train['Genre'] # 훈련 데이터의 장르 부분을 y_train 이라는 이름으로 저장
x_train = train['Content'] # 훈련 데이터의 줄거리 부분을 x_train 이라는 이름으로 저장
y_test = test['Genre'] # 테스트 데이터의 장르 부분을 y_test 이라는 이름으로 저장
x_test = test['Content'] # 테스트 데이터의 장르 부분을 x_test 이라는 이름으로 저장2) 가장 최상위 3개의 열만 한번 출력.
ex1)
y_train.head(3)
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
0 drama
1 thriller
2 adult
Name: 2, dtype: object
------------------------------------------------------------------
ex2)
x_train.head(3)
>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>
0 Listening in to a conversation between his do....
1 A brother and sister with a past incestuous r.......
2 As the bus empties the students for their fie.........
Name: Content, dtype: object- 기계는 단어를 바로 받아들이지 못함.
벡터화(숫자화)해야함. - 두개의 관계를 예측하는데 사용할 것이라 관계를 반영한
벡터화필요. - 장르는 예측의 결과라
벡터화까지는 필요없고, 숫자로 치환.
👨🏫 주의점: 줄거리들은 벡터화를 다음시간에 진행해줄 것인데 그 전에 설명한게 기계는 이 단어를 바로 받아들이지 못한다. Listening in to a conversation between his do.... 이것은 벡터, 그러니깐 숫자로 변형을 해줄 껀데, 장르들은 어떻게 해야하는가. 장르도 단어라서 기계가 바로 받아들일 수 없다. 그래서 이 부분에 대해 숫자로 바꾸는 작업을 해줘야 한다.
-
그런데 주의점은
Listening in to a conversation between his do....이런 것들은 우리가 예측하는데 사용할 데이터이기 때문에, 벡터화를 진행시켜 줘야 한다. 이것들 간의 관계가 에측하는데 사용이 될 것이라서. 벡터화를 진행해주는 것이다. 관계를 반영한 벡터화를. -
그런데 이
장르값들은 사실 그냥 드라마가 아니라 1이라고 하던 스릴러를 2라고 하던 예측하는데 상관없다. 장르라는건 예측의 결과일 뿐이니깐 이것을 벡터화 할 필요없고 숫자로 치환만 하면 된다.
▶장르별 고유 숫자(딕셔너리)
mapping = {' drama ':1, ' thriller ':2, ' adult ':3, ' documentary ':4, ' comedy ':5,
' crime ':6, ' reality-tv ':7, ' horror ':8, ' sport ':9, ' animation ':10,
' action ':11, ' fantasy ':12, ' short ':13, ' sci-fi ':14, ' music ':15,
' adventure ':16, ' talk-show ':17, ' western ':18, ' family ':19, ' mystery ':20,
' history ':21, ' news ':22, ' biography ':23, ' romance ':24, ' game-show ':25,
' musical ':26, ' war ':27}
y_train = y_train.replace(mapping)
y_test = y_test.replace(mapping)27개의 장르를 다 숫자로 대응시키고. .replace 함수를 사용하면 전부 교체된다.
훈련데이터의 장르에 대해서도 변형 시켜줄것이고 테스트 데이터의 장르에 대해서도 이렇게 변형 시켜 줄 것이다.
3) 실행 뒤, 이제 다시 y_train 을 출력.
y_train.head(3)0 1
1 2
2 3
Name: 2, dtype: int64기본적인 전처리는 마쳤고, 기본적으로 데이터 분포에 대해서 확인해봤고 그 다음시간에는 영화 줄거리를 이용해서 장르를 분류하는데 있어서 가장 중요한 벡터화를 같이 진행해보도록 하겠습니다.
2-12 영화 줄거리를 이용해서 장르 분류 해보기 (3) - 벡터화
👨🏫 벡터화를 어떻게 하면 만들수 있는지, 어떻게 진행할수 있는지 설명하겠다. 벡터화 하는 과정에는 굉장히 다양한 방법들이 있는데, DTM 방식.벡터란 어려운 개념이 아닌 숫자들의 나열이라고 생각해도 상관없다.
벡터화의 가장 기본적인 방법.
벡터화란 숫자들의 나열
ex)
[7, 3, 2, 5, 4, 1]
[7, 3, 2, 1, 2, 3]
[1, 2, 5, 1, 2, 5]
이렇게 리스트를 만들었었는데 이게 이제 벡터이다. 벡터를 활용하면 다양한 것들을 구현할 수 있는데 그것에 대해서는 나중에 점차 설명드리도록 하겠다.
5) DTM(Document-Term Matrix)
✔ 문서 단어 행렬(Document-Term Matrix, DTM)이란?
- 문서를 행으로 하고,
- 각 문서에서 등장하는 각 단어들의 등장 횟수를 행렬로 표현한 것을 말함.
👨🏫 벡터 만드는 방식 : 문서에 어떤 단어가 몇 번 등장했는지에 따라서 벡터를 만든다.
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
이를 문서 단어 행렬로 표현
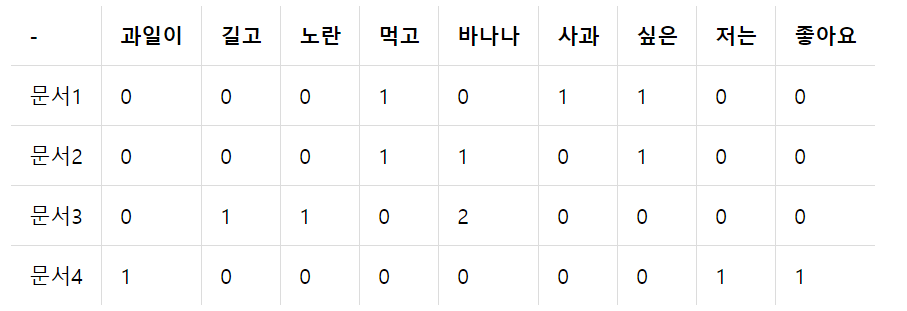
👨🏫이렇게 표 형태로 문서들이 나열되어 있는데, 여기서 문서 1의 벡터를 이 한줄이 구성하고, 문서2는 두번째 .... 쭉 한행한행이 각 문서별 벡터가 된다. 벡터라는 것이 어렵지 않죠. 그냥 문서별로 단어가 몇개등장했는지 벡터를 만들수 있다.
💡
DTM경우,유사도를 구할 수 있다.
✔ 한계점: the, you, a 등 단어별 중요도가 전혀 반영 안됨. 단어별로 가중치가 없다.
💡
Q. 해결방법?
A. TF-IDF
6) TF-IDF (Term Frequency-Inverse Document Frequency)
목적 : 좀 더 명확한 유사도 계산
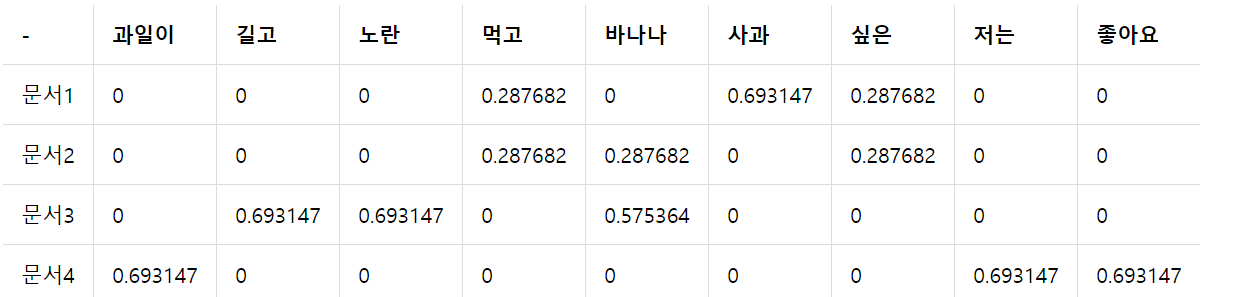
👨🏫 단어별 중요도를 계산해서 단어별 중요도를 DTM에 곱해서 이런 식으로 행렬을 구할 수 있다.
ex) 먹고 경우, DTM이 1 되어있고, TF-IDF경우 0.287682 로 1보다는 낮은 수로 표현된 것을 확인 가능.
몇몇 단어에 높은 가중치가 주어진 이유는 이 문서에만 등장하는 단어이기 때문이다. 전체 문서를 봤을떄 사과 같은거 보면 딱 1번만 등장함. 여러번 등장하는 단어보다 훨씬 높은 값이 부여된 것이다. 이것을 이용하면 조금 더 정확한 어떤 문서간의 유사도 검사를 할 수 있다.
지금 하는 것은 머신러닝 어떤 분류중에 분류라는 파트를 공부하고 있다. 다른 부분은 다음주차에 할 것이다.
7) DTM, TF-IDF 만들기
1) Q. DTM, TF-IDF는 어떻게 만드냐?
A. 사이킷 런 (scikit-learn) 은 머신러닝을 위한 각종 기능을 제공하는 모듈
기본적으로 머신러닝의 큰 분류로는 회귀, 분류가 존재하는데, 이러한 머신러닝을 구현하기 위한 함수를 제공하고 있습니다. 지금 우리는 분류를 공부하고 있고, 4주차에서는 회귀, 5주차에서는 군집화를 공부할 예정입니다.
- 사이킷런을 이용하면,
DTM과TF-IDF를 쉽게 만들 수 있습니다. - 사이킷런의
CountVectorizer를 사용하면DTM을 만들 수 있고, TfidfTransformer를 사용하면TF-IDF행렬을 만들 수 있습니다.
✔ 행렬이나 벡터나 사실상 같은 말
둘 다 각각 객체를 만든 후에 fit_transform() 이라는 함수를 사용하여 실행합니다.
▶ [코드스니펫] DTM, TF-IDF 벡터 생성
2) DTM 벡터 생성
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformercorpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer() # DTM 벡터화를 위한 선언 뒤, 객체 생성
x_train_dtm = vector.fit_transform(corpus) # 해당 문서들을 벡터화 진행
print(x_train_dtm.toarray()) # 벡터가 어떻게 생겼는지 확인
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
[[0 1 0 1 0 1 0 1 1] #문서1번의 벡터
[0 0 1 0 0 0 0 1 0] #문서2번의 벡터
[1 0 0 0 1 0 1 0 0]] #문서3번의 벡터👨🏫 코드 설명)
- 패키지 불렀고, 예시문서 corpus를 벡터로 변화하는 과정.
DTM을 만들겠다고 선언뒤 (CountVectorizer()) , 진행을 위한 객체 생성(vector).vector이것을 이용해서,fit_transform()함수를 작성하고, () 안에 전체 문서를 명시(corpus).- 이 전체 문서를
DTM으로 바꿔서x_train_dtm이라는 변수에 저장을 하게 된다.
3) TF-IDF 벡터 생성
이렇게 얻은DTM으로부터 TfidfTransformer()를 사용하여
TF-IDF 행렬을 추가적으로 학습할 수 있습니다.
```python
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformercorpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer() # DTM 벡터화를 위한 선언 뒤, 객체 생성
x_train_dtm = vector.fit_transform(corpus) # 해당 문서들을 벡터화 진행
print(x_train_dtm.toarray()) # 벡터가 어떻게 생겼는지 확인
----------------------------------------------
tfidf_transformer = TfidfTransformer()
# tfidf 벡터화를 위한 객체 생성
tfidfv = tfidf_transformer.fit_transform(x_train_dtm)
# x_train_dtm에 대해서 벡터화 진행
print(tfidfv.toarray()) # 벡터가 어떻게 생겼는지 확인
>>>>>>>>>>>>>>>>>>>>>> 실행>>>>>>>>>>>>>>>>>>
[[0 1 0 1 0 1 0 1 1] #문서1번의 벡터
[0 0 1 0 0 0 0 1 0] #문서2번의 벡터
[1 0 0 0 1 0 1 0 0]] #문서3번의 벡터
[[0. 0.46735098 0. 0.46735098 0. 0.46735098 0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0 0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0.0.57735027 0. 0. ]]단어별 중요도를 반영한 벡터가 완성됨. 이것을 이용해서 예측작업을 시작해 볼 것이다.
👨🏫 코드 설명)
TfidfTransformer()이렇게 해서tfidf_transformer라고 객체 선언 뒤,.fit_transform()해서x_train_dtmDTM 넣으면 TF-IDF 행렬을 구할 수 있다.
👨🏫
4) DTM에서 TF-IDF 벡터 생성하는 이유
노션 참조
TF-IDF를 만드는 방식은 어쨌든 파이썬에서 해주기 때문에 정확한 계산 공식을 외울 필요는 없으나, TF-IDF는 어떤 약자인데, TF라는 말은 특정 단어에서 등장 횟수를 뜻하는데. 특정 문서에서의 특정 단어가 등장하는 횟수란? 봤던 경험인데 DTM이다. 사실상 DTM의 각각의 값들이 TF가 되는 것이다. 그래서 TF-IDF 경우, TF에다가 IDF 값을 곱해서 생성할 수 있다. TF는 이미 DTM에 있으니깐 이용해서 구하는 것이다.
IDF 는 DF의 역수인데,
DF 경우, 특정 단어가 등장한 문서의 개수를 말함. 빈도가 아닌. 그러니깐 문서들에서 몇번 등장했는지가 아닌 그냥 그 단어가 포함된 문서가 몇개인지를 df 라 하고 복잡한 방식으로 역순을 취하면 IDF 가 되는 것이다.
👨🏫
5) fit_transform() vs transform()
👨🏫본격적으로 예측을 진행할 것이다. 다음시간에 여기서
fit_transform()도 쓰고,transform()이란 함수도 쓰기 시작할 것인데 여기에 대해 설명하고 마치겠다.
아래에서 모델을 구축하면서, test 데이터에 대해서는 그냥 transform 이라는 함수를 쓸 텐데, 그 차이에 대해서 설명드리겠습니다.
fit_transform()은 생성한 객체 (vector, tfidf_transformer) 에다가 해당 문서 혹은 단어들의 벡터값을 저장하면서 벡터화를 진행하는 함수입니다.
저장된 벡터값을 얼마든지 가져올수 있다. test 데이터의 경우에는 다르다, 우리가 이전 시간에 훈련데이터, test데이터 차이에 대해서 설명했는데, test 데이터를 이용해서 학습해서는 안된다. 학습을 하는건, 그러니깐 벡터값을 저장하는건 훈련 데이터에 대해서만 해야하는 것이지, test데이터는 이미 만들어져있는 벡터값을 보고 그냥 그것에 따라서 벡터화로 변환만 해주면 된다.
transform()은 훈련 데이터를 통해서 만들어진 벡터값을 보고, 그것에 따라 벡터화를 진행하는 함수입니다. 만약 훈련 데이터를 토대로 'a' 라는 단어에 대해서 벡터값을 [0 1 0] 이라고 생성해놓았다면, test 데이터에서 등장한 'a' 에 대해서도 [0 1 0] 이라고 벡터화를 진행하는 것입니다.
그냥 transform()쓰게 되면, 더이상 벡터값을 저장하는, 그러니깐 학습의 과정을 진행하지 않는다. 그런데 훈련데이터 경우 어쨌든 지금있는 데이터로 학습을 진행해야 그러니깐, 벡터값을 저장하면서 진행해야 하기 때문에 fit_transform() 써서 벡터화를 진행하는 것이고. test 경우 학습을 진행하면 안되기 때문에 학습진행 안하고 이미 저장된 벡터값을 보고 그냥 치환만 하는 그런 역활을 하는 transform()를 test 데이터에 사용한다.
transform 이라는 함수는 fit_transform()랑 조금 다르다. 이제 모델을 구축하면서 테스트 데이터에 대해서는 transform()이라는 함수를 쓰고, 이 훈련 데이터에 대해서는 fit_transform()이란 함수를 쓸것 이다. 이 차이를 완벽히 이해 어려워도 느낌 알자.
그냥 test data는 학습을 진행하지 않기 때문에 fit_ 이라는 말은 빼고 그냥 transform이라는 함수를 쓴다. 라고 이해하고 넘어가도 된다.
본격적으로 예측을 진행해보도록 합시다.
👨🏫
지난 시간까지
- 어떻게 벡터화를 진행할 수 있는지, 그리고
- 그 벡터화의 원리에 대해서 공부했습니다.
👨🏫 이번 시간에는
- 그 벡터화 진행된 데이터, 그러니깐 줄거리 데이터를 벡터화를 진행시켜보고,
- 그 벡터화된 데이터를 이용해서 장르를 예측해 보는 그 모델을 같이 학습시키고, 구축해보는 그런 실습을 진행하겠습니다.
- 그런데 우선은 어떤 머신러닝 모델을 사용할수 있는지, 그러니깐 그 줄거리를 토대로 장르르 예측하는 그 행위를 어떻게 하는 건지,
- 이 머신러닝 모델들이 가진 그 내재적인 원리들이 무엇인지 먼저 강의 자료를 보면서 설명 드리겠습니다.
2-13 영화 줄거리를 이용해서 장르 분류 해보기 (4) - 머신러닝
8) 나이브 베이즈 분류기
(1) ▶[코드스니펫] 예측 모델에 필요한 모듈 임포트
from sklearn.naive_bayes import MultinomialNB
# 다항분포 나이브 베이즈 모델
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score # 정확도 계산
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer👨🏫 아래 두개 코드는 저번 시간에 배웠던 그 코드들. 벡터화를 진행할때
CountVectorizer는DTM을 만드는 함수TfidfTransformer는TF-IDF벡터를 만드는 함수- 총 3가지. 위에 세줄 import 코드는 오늘 사용할 머신러닝 모델들을 불러오는 코드이다. 3가지 머신러닝 모델에 대해 공부할 것.
우선은 머신러닝 모델에 넣으려면, 모든 데이터는 벡터화를 해야한다. (텍스트 데이터는 컴이 바로 알아들을수 없기 때문에)
저번시간에는 예시데이터에 대해서만 벡터화를 진행했었는데 이번에는
(2) 줄거리 데이터를 벡터화 하기
👨🏫 과정은 지난시간에 배웠던 코드와 완전히 똑같다.
① 우선 훈련용 줄거리 데이터 (x_train) 에 대해서 DTM을 만듭니다.
dtmvector = CountVectorizer()
x_train_dtm = dtmvector.fit_transform(x_train)👨🏫 코드 설명)
CountVectorizer()함수를 이용해서dtmvector; DTM을 만드는 그런 객체를 우선 생성한다. 그뒤에dtmvector.fit_transform이라는 벡터화 진행하는 함수를 실행하게 된다.
-
객체를 생성한다는 것; 함수를 쓰기위해서 준비작업을 하는 것이라고 생각하자. 우리가 그냥
CountVectorizer() 함수만으로는 바로 벡터화를 진행할 수 없게 사이킷런에서 설계해놓음. 그래서 이전에 클레스 배울때, 클래스 안에 함수를 만들면 우선은 클레스를 이용해서 어떤 객체라는 걸 만들고 그 객체안에 있는 함수를 이용할수 있게 된다고 설명 드렸었죠. 똑같음.dtmvector = CountVectorizer()객체를 생성한다는 것은 어떤 함수를 우리한테 필요한.fit_transform()를 실행하기 위한 준비작업을 하는 것이다. 라고 이해하기.
fit_transform(x_train)의 ()안에 벡터화를 진행하고자 하는 데이터를 명시하면 벡터화가 진행되었었다.
② DTM으로부터 TF-IDF 행렬을 만듭니다.
tfidf_transformer = TfidfTransformer()
tfidfv = tfidf_transformer.fit_transform(x_train_dtm)마찬가지로 테스트용 줄거리 데이터 (x_test) 에 대해서 DTM, TF-IDF 를 만들어줍니다.
x_test_dtm = dtmvector.transform(x_test) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환이제 이를 각종 머신 러닝 알고리즘의 입력 및 평가에 사용할 예정입니다.
나이브 베이즈 분류기
그 중 처음으로 사용할 모델은 나이브 베이즈 분류기입니다.
나이브 베이즈 분류기를 간단하게 설명해보겠습니다.
- P(A)가 A가 일어날 확률,
- P(B)가 B가 일어날 확률,
- P(B|A)가 A가 일어나고나서 B가 일어날 확률,
- P(A|B)가 B가 일어나고나서 A가 일어날 확률이라고 해봅시다.
이때 P(B|A)를 쉽게 구할 수 있는 상황이라면, 아래와 같은 식을 통해 P(A|B)를 구할 수 있습니다. 아래 식을 '베이즈 정리' 라고 합니다.
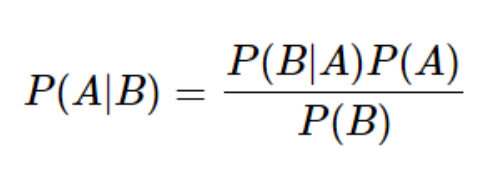
나이브 베이즈 분류기는 이러한 베이즈 정리를 이용하여 텍스트 분류를 수행합니다. 예를 들어서 나이브 베이즈 분류기를 통해서 다음의 예시를 풀어본다고 해봅시다.
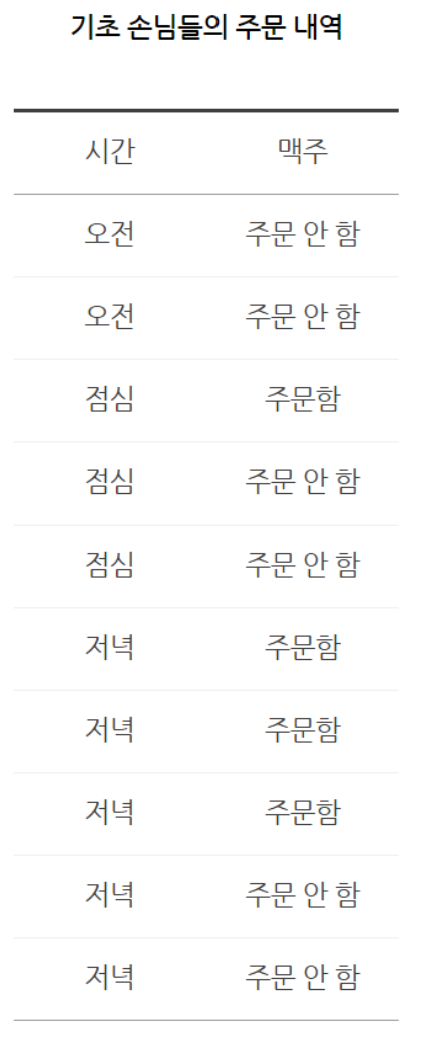
위 데이터로부터 치킨집에서 손님이 주문을 할 때 맥주를 주문할 지 안 할지를 예측하는 공식은 베이즈 정리에 따르면 다음과 같습니다.
아래의 식에서 '주문'은 맥주 주문을 의미합니다.
- P(주문|저녁) = P(저녁|주문) P(주문) / P(저녁) = 3/4 4/10 * 10/5 = 0.6
저녁에 치킨을 주문할 확률은 60%므로 치킨을 주문할 것으로 예측할 수 있습니다. 이러한 공식을 이용한다면, '모험을 떠난다' 라는 줄거리가 '액션' 이라는 장르에 해당할 확률은
- P(액션|모험을 떠난다) = P(모험을 떠난다|액션) * P(액션) / P(모험을 떠난다)
이런 공식으로 구할 수 있을 것입니다!
전체 줄거리와 전체 장르 데이터는 주었으니,
- P(액션) = 액션 장르에 해당하는 영화 개수 / 모든 영화 개수
- P(모험을 떠난다) = 모험을 떠난다라는 줄거리를 포함한 영화 개수 / 모든 영화 개수
- P(모험을 떠난다|액션) = 액션 장르 중에 모험을 떠난다를 포함한 영화 개수 / 액션 장르에 해당하는 영화 개수
는 당연히 주어진 데이터만으로 구할 수 있을 것입니다.
이를 토대로 공식에 대입하면, '모험을 떠난다' 라는 줄거리가 '액션' 이라는 장르에 해당할 확률을 구할 수 있습니다!
나이브 베이즈 분류기는 사이킷런의MultinomialNB()를 통해 사용할 수 있습니다.
사이킷런이 제공하는 머신러닝 모델들은 공통적으로fit()이라는 함수를 제공하고 있는데요.
훈련 데이터와 해당 훈련 데이터에 대한 레이블을 인자로 사용하면 모델이 학습을 하게 됩니다.
mod = MultinomialNB()
mod.fit(tfidfv, y_train)테스트 데이터에 대해서 정확도를 측정하기 위해서는 훈련 데이터와 동일한 전처리를 거쳐야 합니다. 다시 말해 테스트 데이터에 대해서도 TF-IDF 행렬로 변환해주고,
predict()란 함수로 예측값을 얻어서 정확도를 측정합니다.
predicted = mod.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted))#예측값과 실제값 비교
>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.
정확도: 0.4426752767527675
44.2%의 정확도를 얻습니다. 사실 그렇게 좋은 성능은 아닙니다.
뒤에서 다른 모델들을 통해서 더 좋은 성능을 얻기 위해서 노력해봅시다.
나이브 베이즈 분류기가 임의의 영화에 대해서 장르를 정확히 예측하는지 테스트를 해보겠습니다. 네번째 영화(인덱스 상으로는 3)의 줄거리를 출력하면 다음과 같습니다.
x_test[3]
>>>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>
"His father has died, he hasn't spoken with his brother for about 10 years and has a serious cancer. Diego is a talented film director with difficulty to deal with his sickness, which is making him lose his friends and family. His best friend and doctor Ricardo gives him the news that he needs a bone marrow transplantation, otherwise he'll die. He gets married to a beautiful woman, Livia, just before going to Seattle to get treatment. There, he undergoes numerous medical procedures. During treatment, he meets an Hindu boy, with whom he plays and whom he tells amazing stories. Odds are against him and when stakes are the highest, Diego gets a visit from a very uncommon man."이 영화의 장르는 무엇이었을까요?
y_test[3]
>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>
11 이라는 숫자는 drama 장르에 해당합니다. (위에서 전처리할 때 그렇게 함께 정했었습니다!)
과연 모델은 제대로 예측하고 있는지 그리고 어느정도의 확신을 가지고 판단하는지 모델이 결정한 확률을 그래프로 시각화해봅시다.
모델이 어느정도의 확신을 가지는지 출력하려면 predict_proba()를 통해 알 수 있습니다.
predict()이 최종 예측한 클래스만을 리턴한다면,
predict_proba()는 각 클래스 별 몇 %의 확신을 가졌었는지를 리턴합니다.
▶[코드스니펫] 그래프 출력 코드
💡 matplot 을 이용한 시각화는 다음 주차에 공부할 예정입니다. 대략적으로 아래와 같은 코드를 통해서 시각화를 할 수 있다는 것만 눈에 익혀두세요!
import matplotlib.pyplot as plt
plt.subplot(211)
plt.rcParams["figure.figsize"] = (10,10)
plt.bar(mod.classes_, mod.predict_proba(tfidfv_test[3])[0])
plt.xlim(-1, 21)
plt.xticks(mod.classes_)
plt.xlabel("Genre")
plt.ylabel("Probability")
plt.show()위 코드를 실행하면 아래와 같은 그래프가 출력됩니다.
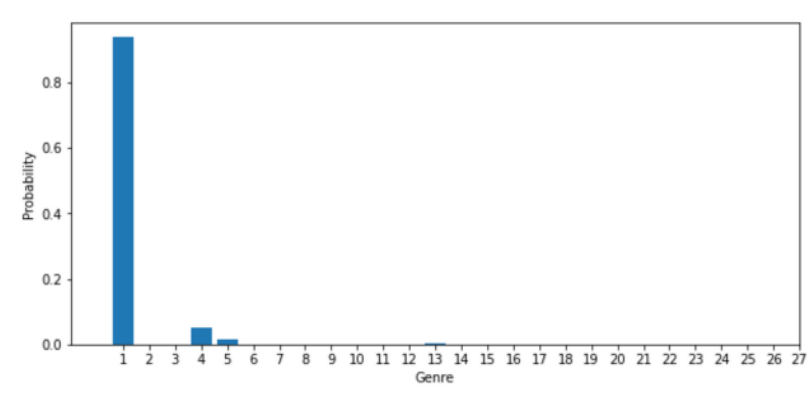
우리가 학습시킨 예측 모델은 1번 장르를 약 90%의 확률로 확신하는데, 약 5%의 확률로 4번 장르라고 판단합니다. 90%의 확률로 확신하므로 모델이 예측한 장르는 1번입니다.
실제 해당 영화의 장르였던 drama 와, 우리가 학습시킨 모델이 예측한 장르가 drama 로 일치하고 있습니다!줄거리만으로 기계가 장르를 예측해낸 것입니다!
번외로, predict() 함수를 사용해보면 최종 예측한 장르인 1만 출력하는 것을 확인할 수 있습니다.
mod.predict(tfidfv_test[3])
>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>
array([1])
9) Logistic Regression
로지스틱 회귀는 소프트맥스(softmax) 함수를 사용한 다중 클래스 분류 알고리즘을 지원합니다. 다중 클래스 분류를 위한 로지스틱 회귀를 소프트맥스 회귀(Softmax Regression)라고도 합니다.
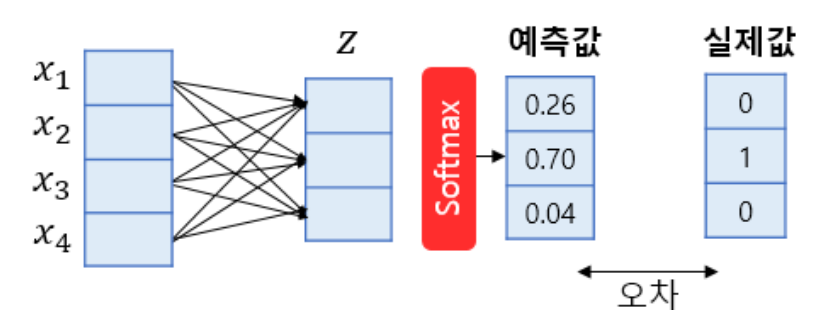
소프트맥스 함수는 클래스가 N개일 때, 각 클래스가 정답일 확률을 표현하도록 하는 함수입니다. 예를 들어 위의 그림은 3개의 클래스를 가지는 경우의 소프트맥스 회귀의 동작 과정을 보여주고 있습니다.
💡 위 그림에서 화살표 각각은 이후에 선형 회귀에서 배울 가중치(weight)에 해당합니다. 이 값들은 처음에는 랜덤값이지만, 학습이 진행되면서 모델이 정답을 잘 맞출 수 있는 값으로 변하게 됩니다.
표현이 어려운데, 조금만 더 쉽게 설명해보겠습니다! 만약 '액션', 'SF', '로맨스' 라는 장르만 존재한다고 가정해봅시다. 그러면 모델은 입력으로 어떤 영화의 줄거리가 들어왔을 때, 3가지 장르 중 하나로 분류해야 합니다.
여기서 소프트맥스 함수는 '액션', 'SF', '로맨스' 라는 각각의 장르에 해당할 확률을 학습한 가중치를 토대로 계산을 합니다. 즉, 소프트맥스 함수를 거치고 나면 결과값은 ['액션에 해당할 확률', 'SF에 해당할 확률', '로맨스에 해당할 확률'] 이렇게 3가지 값이 나오게 됩니다.
그러면 그 3가지 값 중에 가장 높은 값을 가진 것이 예측 결과로 나오게 되는 것입니다.
우리가 진행하고 있는 실습에서는 장르가 총 27개였기 때문에, 소프트맥스 함수는 각각의 장르에 해당할 확률27개를 모두 계산합니다.
사이킷런에서 소프트맥스 회귀는 LogisticRegression()을 통해서 구현할 수 있습니다.
lr = LogisticRegression(C=10000, penalty='l2') #c와 penalty의 의미는 4주차에서 배울 예정입니다!
lr.fit(tfidfv, y_train)
predicted = lr.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교
>>>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.
정확도: 0.586826568265682710) 선형 Support Vector Machine
서포트 벡터 머신(이하 SVM)은 결정 경계(Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델이다. 그래서 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 됩니다.
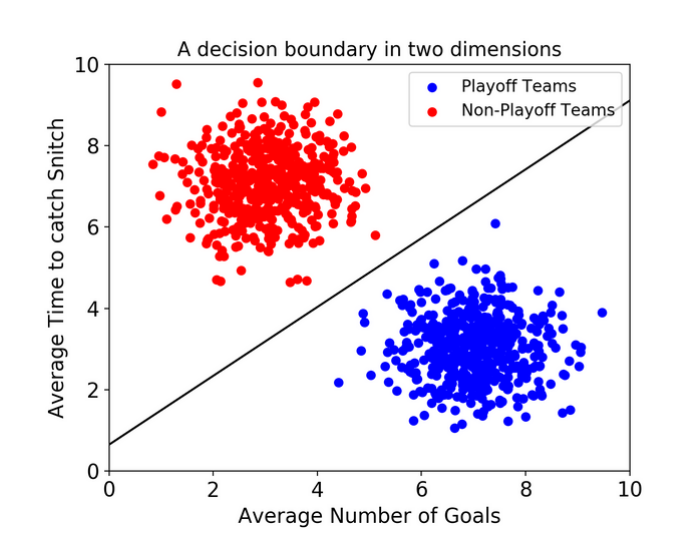
예를 들어 위 그림은 서포트 벡터 머신이 두 가지의 카테고리를 분류하기 위해서 결정 경계. 즉, 선을 그은 것을 말합니다. 이제 새로운 데이터가 들어오면 해당 결정 경계를 기준으로 어떤 클래스인지를 예측하게 됩니다.
잘 만들어진 서포트 벡터 머신이라는 것은 저러한 결정 경계를 얼마나 잘 그리나를 의미하는데, 결정 경계라는 것도 얼마나 모델이 학습이 잘 되었는지에 따라 천차만별이기 때문입니다
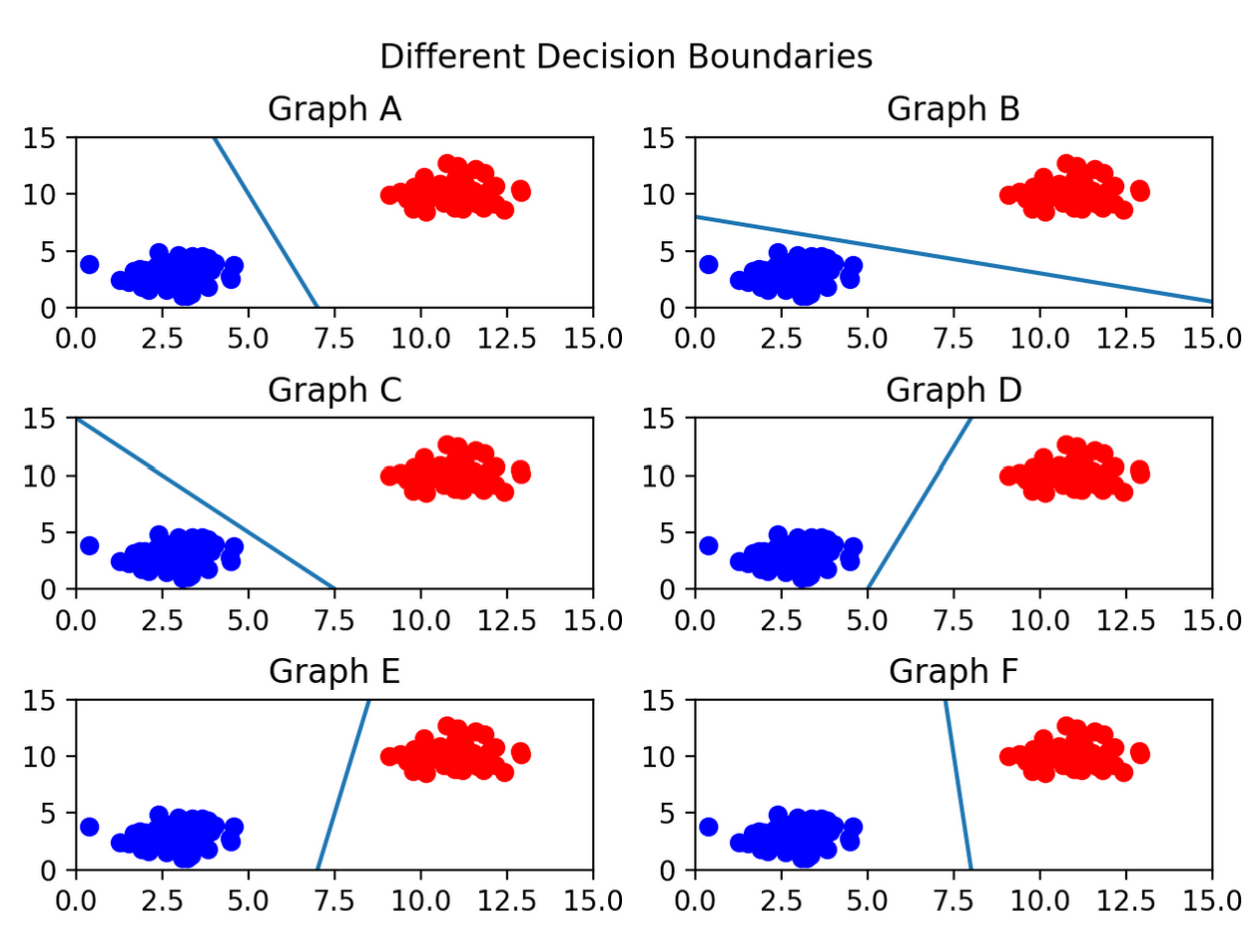
예를 들어 그림 C를 보면 선이 파란색 부류와 너무 가까워서 아슬아슬해보입니다. 만약, 실제로 파란색 카테고리에 속하는 데이터가 입력되더라도, 빨간색 클래스로 잘못 분류될 가능성이 있는 것이죠. 반면, 그림 F의 선은 두 클래스 모두와 적절한 거리를 두고 분류선이 그려져 있어 C보다 훨씬 분류를 잘할 것으로 보입니다. SVM이 학습이 잘 되었다는 것은 F와 같은 경우를 말하는 것이지요.
서포트 벡터 머신(LinearSVC)를 통해서 모델을 학습하고, 성능을 측정해봅시다.
lsvc = LinearSVC(C=1000, penalty='l2', max_iter=500)
lsvc.fit(tfidfv, y_train)
predicted = lsvc.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교
>>>>>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
정확도: 0.520867158671586752%라는 정확도를 얻었습니다.
💡 다양한 머신러닝 모델을 사용해보면서, 어떤 모델이 가장 정확도가 높은지를 비교해보는 것도 데이터 분석가로서 중요한 자세입니다.
💡 여기서 더 높은 정확도를 얻고 싶으시다면, 자연어처리 (NLP) 를 더 깊게 공부하셔야 합니다. 벡터 임베딩의 다양한 기법을 시도해보고, 딥러닝까지 적용해본다면 이것보다 훨씬 더 높은 정확도를 만들어내실 수 있을 것입니다.
