2-6 영화 줄거리를 이용해서 장르 분류해보기 (2) - 머신러닝, 번외
어떻게 하는 건지? 머신러닝의 내재적인 원리가 무엇인지
!!
3가지
- 모든데이터는 (텍스트 데이터는) 벡터화를 진행해 줘야 한다.
이제 본격적인 예측 모델 구축을 위해서, 각종 머신 러닝 알고리즘들을 사용해봅시다.
예측 모델에 필요한 모듈 임포트
from sklearn.naive_bayes import MultinomialNB # 다항분포 나이브 베이즈 모델
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score # 정확도 계산
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer우선 훈련용 줄거리 데이터 (x_train) 에 대해서 DTM을 만듭니다
dtmvector = CountVectorizer()
x_train_dtm = dtmvector.fit_transform(x_train)DTM으로부터 TF-IDF 행렬을 만듭니다.
tfidf_transformer = TfidfTransformer()
tfidfv = tfidf_transformer.fit_transform(x_train_dtm)마찬가지로 테스트용 줄거리 데이터 (x_test) 에 대해서 DTM, TF-IDF 를 만들어줍니다.
x_test_dtm = dtmvector.transform(x_test) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환이제 이를 각종 머신 러닝 알고리즘의 입력 및 평가에 사용할 예정입니다.
25) 나이브 베이즈 분류기
나이브 베이즈 분루기 란?
P(A)가 A가 일어날 확률,
P(B)가 B가 일어날 확률,
P(B|A)가 A가 일어나고나서 B가 일어날 확률,
P(A|B)가 B가 일어나고나서 A가 일어날 확률이라고 해봅시다.
이때 P(B|A)를 쉽게 구할 수 있는 상황이라면, 아래와 같은 식을 통해 P(A|B)를 구할 수 있습니다.
아래 식을 '베이즈 정리' 라고 합니다
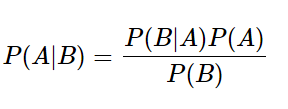
ex)

위 데이터로부터 치킨집에서 손님이 주문을 할 때 맥주를 주문할 지 안 할지를 예측하는
공식은 베이즈 정리에 따르면 다음과 같습니다.
아래의 식에서 '주문'은 맥주 주문을 의미합니다.
- P(주문|저녁) = P(저녁|주문) P(주문) / P(저녁) = 3/4 4/10 * 10/5 = 0.6
ex)
이러한 공식을 이용한다면, '모험을 떠난다' 라는 줄거리가 '액션' 이라는 장르에 해당할 확률은
- P(액션|모험을 떠난다) = P(모험을 떠난다|액션) * P(액션) / P(모험을 떠난다)
전체 줄거리와 전체 장르 데이터는 주었으니,
- P(액션) = 액션 장르에 해당하는 영화 개수 / 모든 영화 개수
- P(모험을 떠난다) = 모험을 떠난다라는 줄거리를 포함한 영화 개수 / 모든 영화 개수
- P(모험을 떠난다|액션) = 액션 장르 중에 모험을 떠난다를 포함한 영화 개수 / 액션 장르에 해당하는 영화 개수
는 당연히 주어진 데이터만으로 구할 수 있을 것입니다.
이를 토대로 공식에 대입하면, '모험을 떠난다' 라는 줄거리가 '액션' 이라는 장르에 해당할 확률을 구할 수 있습니다!
나이브 베이즈 분류기는 사이킷런의 MultinomialNB()를 통해 사용할 수 있습니다.
사이킷런이 제공하는 머신러닝 모델들은 공통적으로 fit()이라는 함수를 제공하고 있는데요.
훈련 데이터와 해당 훈련 데이터에 대한 레이블을 인자로 사용하면 모델이 학습을 하게 됩니다.
mod = MultinomialNB()
mod.fit(tfidfv, y_train)테스트 데이터에 대해서 정확도를 측정하기 위해서는 훈련 데이터와 동일한 전처리를 거쳐야 합니다. 다시 말해 테스트 데이터에 대해서도 TF-IDF 행렬로 변환해주고,
predict()란 함수로 예측값을 얻어서 정확도를 측정합니다.
predicted = mod.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교정확도: 0.442675276752767544.2%의 정확도를 얻습니다. 사실 그렇게 좋은 성능은 아닙니다.
뒤에서 다른 모델들을 통해서 더 좋은 성능을 얻기 위해서 노력해봅시다.
~~나중에 할 것 ~~
ex)나이브 베이즈 분류기가 임의의 영화에 대해서 장르를 정확히 예측하는지 테스트를 해보겠습니다. 네번째 영화(인덱스 상으로는 3)의 줄거리를 출력하면 다음과 같습니다.
x_test[3]"His father has died, he hasn't spoken with his brother for about 10 years and has a serious cancer. Diego is a talented film director with difficulty to deal with his sickness, which is making him lose his friends and family. His best friend and doctor Ricardo gives him the news that he needs a bone marrow transplantation, otherwise he'll die. He gets married to a beautiful woman, Livia, just before going to Seattle to get treatment. There, he undergoes numerous medical procedures. During treatment, he meets an Hindu boy, with whom he plays and whom he tells amazing stories. Odds are against him and when stakes are the highest, Diego gets a visit from a very uncommon man."이 영화의 장르는 무엇이었을까요?
y_test[3]->
1matplot 을 이용한 시각화는 다음 주차에 공부할 예정입니다. 대략적으로 아래와 같은 코드를 통해서 시각화를 할 수 있다는 것만 눈에 익혀두세요!
import matplotlib.pyplot as plt
plt.subplot(211)
plt.rcParams["figure.figsize"] = (10,10)
plt.bar(mod.classes_, mod.predict_proba(tfidfv_test[3])[0])
plt.xlim(-1, 21)
plt.xticks(mod.classes_)
plt.xlabel("Genre")
plt.ylabel("Probability")
plt.show()->
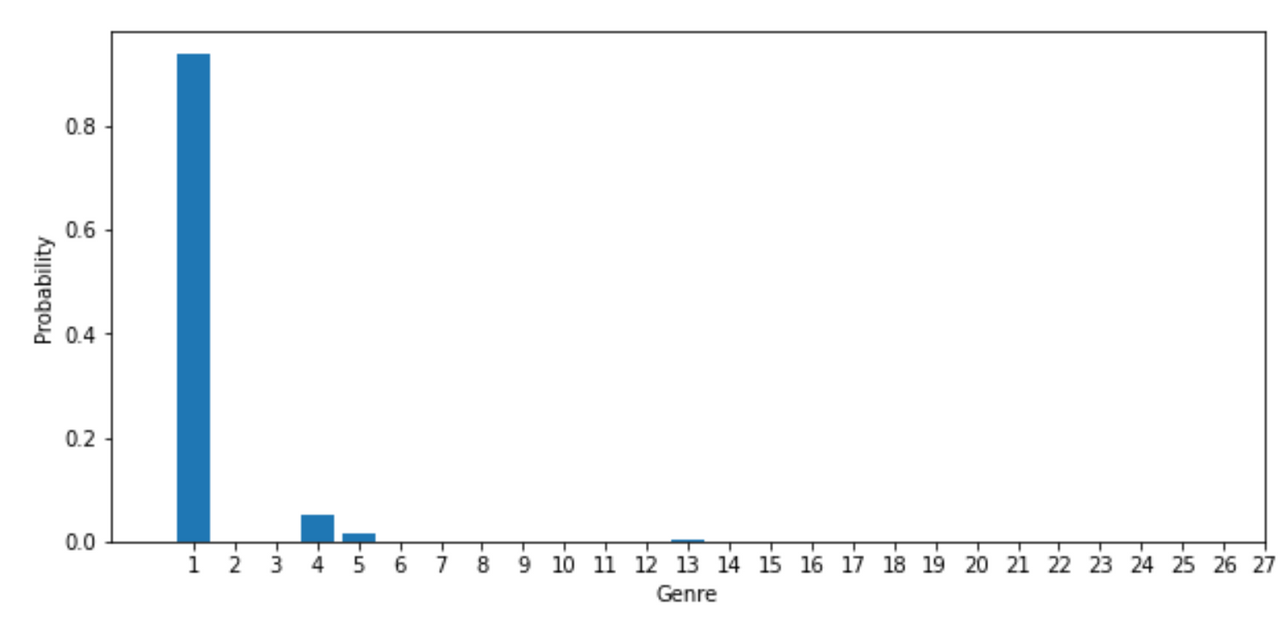
번외로, predict() 함수를 사용해보면 최종 예측한 장르인 1만 출력하는 것을 확인할 수 있습니다.
mod.predict(tfidfv_test[3])array([1])-> 나중에 듣기
베이즈 정리라는 공식을 이용해서 해결
Logistic Regression
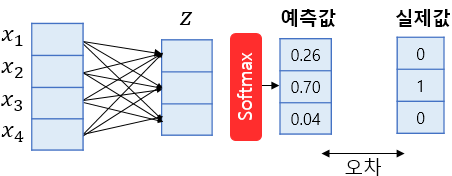
로지스틱 회귀는 소프트맥스(softmax) 함수를 이용해서 어떤 데이터가 각각의 클레스에 해당할 확률을 출력해주는 것
ex)3개의 영화 장르가 있다고 가정 Z, 각각 장르에 해당할 확률 구함 x, 그중에서 가장 높은것 결과값. 실제값과 계속 비교하면서 계속 오차를 줄여나감.(최적화-횟수를 제한하기도 함)
특이한 점 : 소프트맥스 회귀는 예측값 합이 '1'이 나오도록 보정하기도 함.
사이킷런에서 소프트맥스 회귀는 LogisticRegression()을 통해서 구현할 수 있습니다.
lr = LogisticRegression(C=10000, penalty='l2') #c와 penalty의 의미는 4주차에서 배울 예정입니다!
lr.fit(tfidfv, y_train)predicted = lr.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교->
정확도: 0.5868265682656827이전 모델보다 높은 58%의 정확도를 얻었습니다.
선형 Support Vector Machine
서포트 벡터 머신(이하 SVM)은 좀 더 간단. 결정 경계(Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델이다. 그래서 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 됩니다.
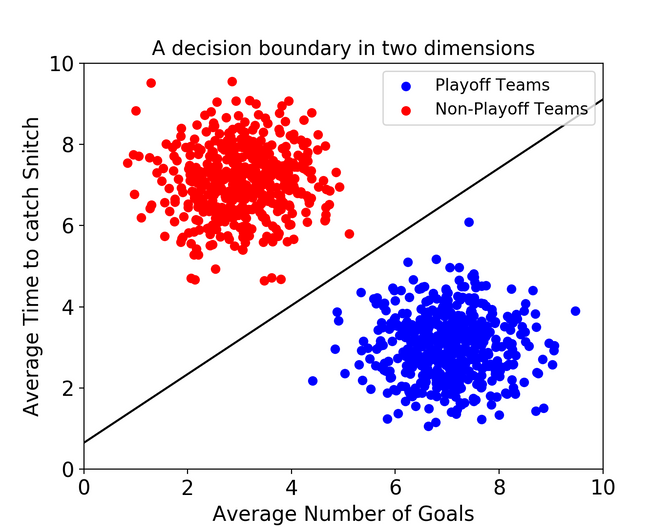
선을 그엇을때 제일 분류가 잘 되었는지 판단하며 분류해 나감.
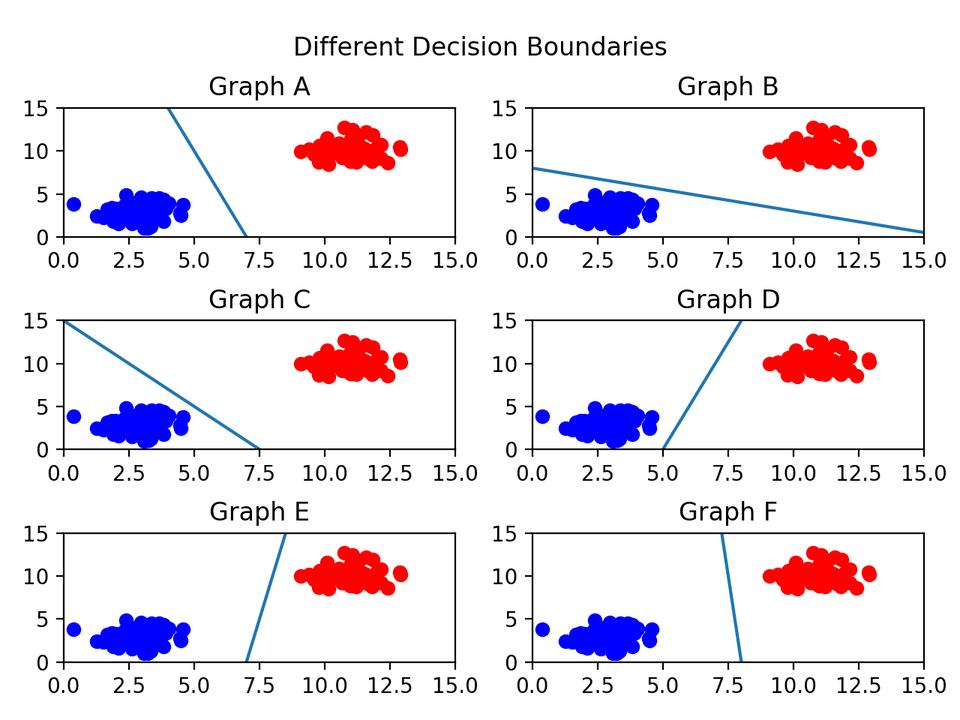
lsvc = LinearSVC(C=1000, penalty='l2', max_iter=500)#오차 제한 500번
lsvc.fit(tfidfv, y_train) #패널티는 나중에 학습할 예정이다.predicted = lsvc.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교->
정확도: 0.520867158671586752%라는 정확도를 얻었습니다.
다양한 머신러닝 모델을 사용해보면서, 어떤 모델이 가장 정확도가 높은지를 비교해보는 것도 데이터 분석가로서 중요한 자세입니다.
여기서 더 높은 정확도를 얻고 싶으시다면, 자연어처리 (NLP) 를 더 깊게 공부하셔야 합니다. 벡터 임베딩의 다양한 기법을 시도해보고, 딥러닝까지 적용해본다면 이것보다 훨씬 더 높은 정확도를 만들어내실 수 있을 것입니다.
예측해보기
학습시킨 모델을 통해서, 우리가 임의로 만든 줄거리에 대해서 모델이 해당 줄거리를 어떤 장르로 분류하는 지를 확인할 수 있습니다.
가장 정확도가 높았던 로지스틱 회귀를 이용해서 진행하겠습니다.
내가 만든 줄거리 장르 예측해보기
x_test_dtm = dtmvector.transform(['(내가 만든 줄거리)']) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환
predicted = lr.predict(tfidfv_test) #테스트 데이터에 대한 예측
print(predicted)저는 어벤져스의 명대사 중 하나인 'i love you 3000' 을 입력값으로 넣어보겠습니다.
x_test_dtm = dtmvector.transform(['i love you 3000']) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환
predicted = lr.predict(tfidfv_test) #테스트 데이터에 대한 예측
print(predicted)그 결과값으로 24가 나오는 것을 확인할 수 있습니다.
[24]24는 romance 장르에 해당하는 번호입니다. 즉, i love you 3000 이라는 줄거리만 보고 로맨스 장르의 영화일 것이라고 모델이 추측해낸 것입니다!
여러분들이 원하는 줄거리를 짜서 한번 넣어보시면, 예측의 정확도를 수치가 아닌 눈으로 확인하실 수 있을 겁니다. 다른 줄거리도 한번 넣어보세요!
불용어 제거
불용어 제거에 대해서 위에서 공부했으니, 모델 구축하는 과정에서 한번 활용해봅시다!
어떤 식으로 불용어를 제거하는지에 따라서, 정확도가 올라가기도 내려가기도 합니다. 불용어를 적절하게 제거해서, 정확도를 최대한 올리는 것이 자연어처리에서는 중요한 과제이기도 합니다.
위에서는 불용어를 제거하는 과정에서 리스트 컴프리헨션이라는 복잡한 코드를 작성했었는데, 사이킷런에서는 그렇게 할 필요없이 몇가지 옵션을 명시하는 것만으로 자동으로 불용어가 제거됩니다!
불용어 제거한 후, 예측진행해보기
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
# dtm, tfidf 벡터 생성을 위한 객체 생성
dtmvector = CountVectorizer(stop_words="english") # 영어 스탑워드를 제거해달라는 뜻!
tfidf_transformer = TfidfTransformer()
# x_train에 대해서 dtm, tfidf 벡터 생성
x_train_dtm = dtmvector.fit_transform(x_train)
tfidfv = tfidf_transformer.fit_transform(x_train_dtm)
# 나이브 베이즈 분류기로 학습 진행
mod = MultinomialNB()
mod.fit(tfidfv, y_train)
# x_test에 대해서 dtm, tfidf 벡터 생성
x_test_dtm = dtmvector.transform(x_test) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환
predicted = mod.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교결과를 보면 불용어를 제거하기 전보다 0.2% 가량 정확도가 올라간 것을 확인할 수 있습니다.
정확도: 0.44474169741697417