
강의 주소 : 연남대 최규상 교수님 컴퓨터 구조 강의 (2015년)
Chapter 4. The Processor
4.1 Introduction
1) Introduction
CPU 성능 요소
- 명령어 수 : ISA에 의해 결정
- CPI & Cycle Time : CPU HW에 의해 결정
MIPS 구현방식 2가지
- simplified version
- 실제 MIPS 프로세서와 비슷한 pipelined version
실제 MIPS의 모든 명령어를 사용하지 않고 일부 사용
일부의 명령어가 MIPS 명령어의 대부분을 커버
- 메모리 참조 : lw, sw
- 산술 & 논리 : add, sub, and, or, slt
- 제어 이동 : beq, j
2) Instruction Execution
- 프로그램에 메모리가 로드되면 명령어들은 instruction memory에 순서대로 주소를 가지며 위치한다.
- PC(프로그램 카운터)
- 현재 실행하는 명령어의 메모리 주소를 가진다. -> 정확히는 다음 번 명령어의 메모리 주소
- target address 또는 PC + 4 값이 저장된다.
- fetch instruction : PC에 담긴 주소로 instruction memory에서 instruction을 읽어온다.
- 레지스터 번호 <-> 레지스터 뭉치
- read register : 명령어에서 레지스터 번호를 통해 레지스터에 접근해 값을 읽어오는 것
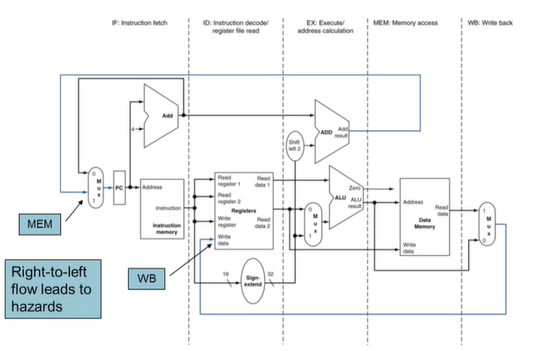
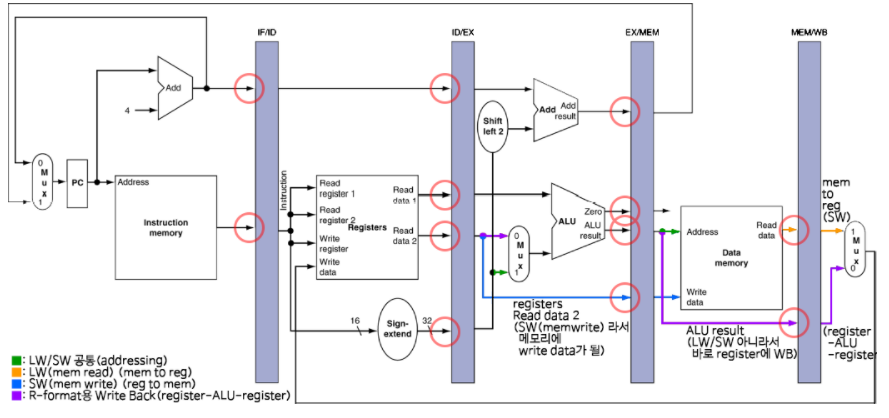
3) CPU Overview
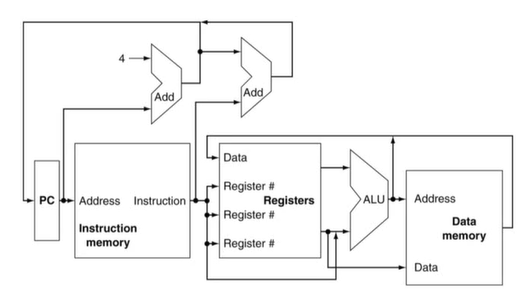
-> 실제로는 여러 선이 함께 만날 수 없다. 원래는 Multiplexer(MUX)를 사용해 그 중 하나의 신호를 선택한다.
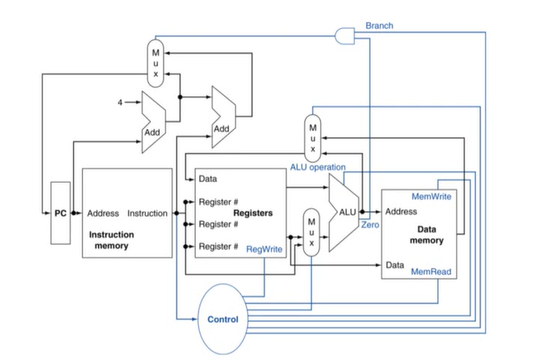
-> Control : 각각의 HW 모듈이 어떻게 동작하는지 제어해주는 컨트롤을 만들어 주는 회로로 명령어를 읽어 해당하는 제어 신호를 만들어낸다.
4.2 Logic Design Conventions
1) Logic Design Basics
- 정보는 binary(0, 1)로 인코딩된다.
- 저전력 : 0, 고전력 : 1
- One wire per bit : 하나의 비트 표현마다 한 개의 선 필요
- Multi-bit data encoded on multi-wire buses
로직은 다음과 같이 2가지로 나누어진다.
- combinational element(조합 요소)
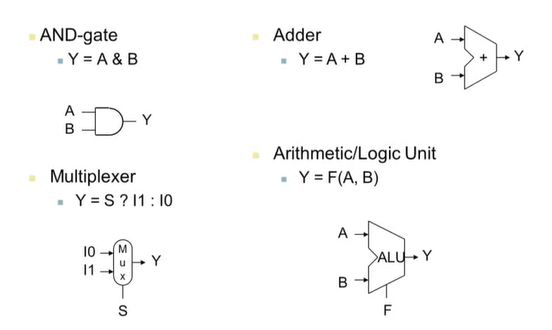
-> 데이터에 동작
-> input에 의해 output이 결정됨
- state(sequential) element
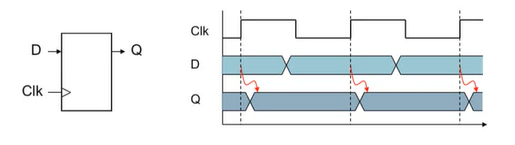
-> 정보를 저장하는데 사용
-> clock signal을 사용해 저장된 값이 언제 업데이트 되는지 결정
-> 현재값, input, clock 타이밍에 의해 output이 결정됨
2) Clocking Methodology

- Combinational logic은 clock cycle동안 데이터를 변형한다.
- state elemnt로부터 input이 되고 output은 또 state element가 된다.
- 가장 지연이 긴 시간이 clock period를 결정한다.
4.3 Building a Datapath
1) Building a Datapath
Datapath란?
- 데이터가 흐르는 경로
- CPU에서 프로세스 데이터와 주소들의 요소가 전달되는 길 : 레지스터, ALU, MUX, 메모리 등의 모듈들이 연결되는 통로
Instruction Fetch
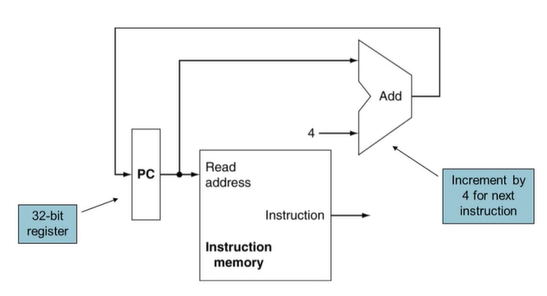
- instruction memory로부터 instruction을 읽어온다.
- PC의 값이 instructio memory에 input으로 들어가면 해당 instruction이 output으로 나온다.
- 동시에 현재 PC 값에 4를 더한 후 PC에 저장한다.
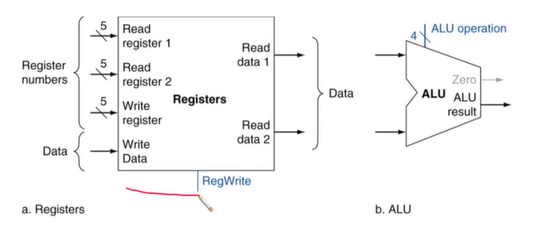
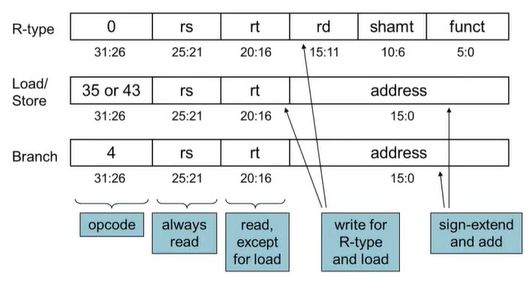
R-Format Insturction
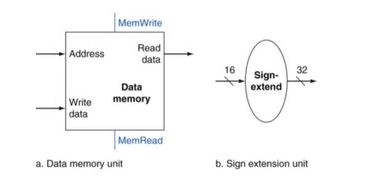
Load/Store Instruction
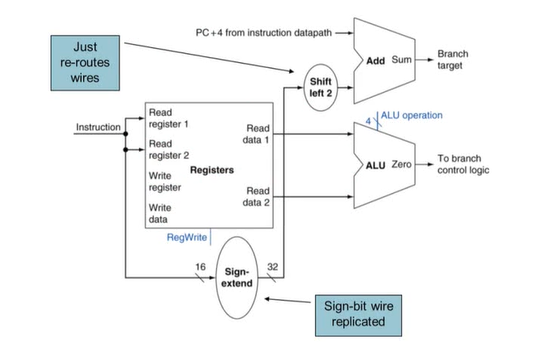
Branch Instruction
2) Composing the Elements
- 각 요소들을 통합해 한 clock cycle에 동작할 수 있도록 한다.
- 한 clock cycle에 하나의 instruction만 실행한다.
- 각 datapath 요소는 한 번에 하나의 기능만을 수행할 수 있다.
- 따라서 data memory, instruction을 분리해야 한다. 그렇지 않을 경우, 하나의 명령어가 동시에 접근하려고 한다.
- data source가 교차하는 곳에서는 MUX를 사용해 다른 instruction에 다른 경로로 대응할 수 있도록 한다.
R-Type & Load & Store Datapath 통합
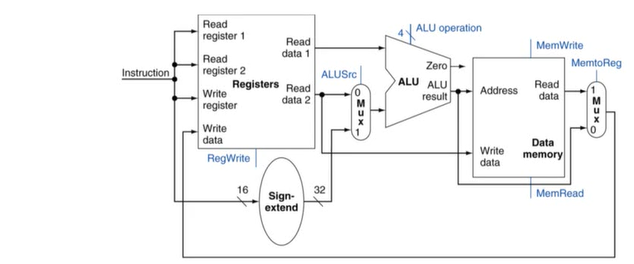
Full Datapath
Single-cycle로 돌아가는 간소화 버전의 MIPS 구현 회로
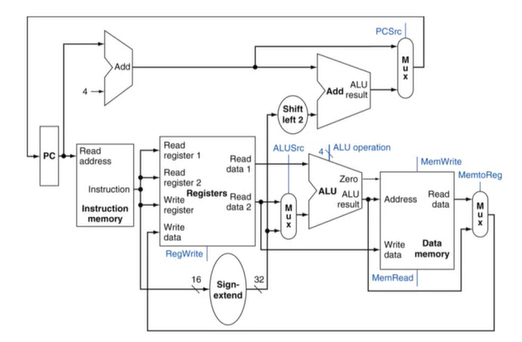
4.4 A Simple Implementation Scheme(MIPS의 simplified version)
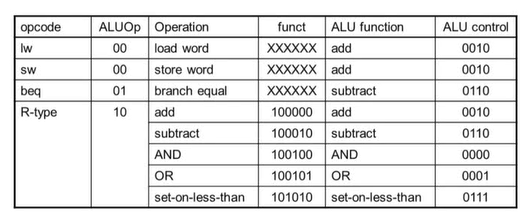
1) ALU Control
ALU 사용
- Load & Store : F = add
- Branch : F = substract
- R-type : F depends on funct field
ALU Control
opcode로부터 2-bit 부분을 가져와 ALUOp로 도출한다. -> Combinational logic을 사용해 ALU control을 만들어낸다.
The Main Control Unit
Control 신호는 instruction으로부터 얻어진다.
2) Performance Issues
- 회로에서 가장 지연시간이 긴 부분이 전체 클럭 주기를 결정한다.
- MIPS에서 치명적인 경로 : load instruction(memory -> register file -> ALU -> data memory -> register file)
- 다른 instruction에 다른 주기로 실행할 수 없다.
- 모든 instruction은 한 clock cycle에 실행되어야 하며 모두 같은 clock cycle time이어야 한다.
- 설계 원칙에 위배된다 : making the common case fast
- 가장 느린 부분에 맞춰지기 때문
- 따라서, pipelining을 통해 성능을 향상시켜야 한다.
4.5 An Overview of Pipelining(MIPS의 pipelined version)
1) Pipelining Analogy
병렬처리로 성능 향상
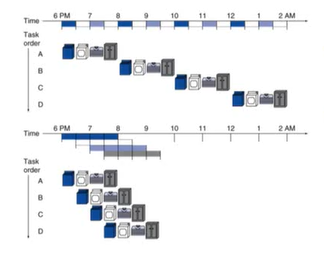
2) MIPS Pipeline
5개의 stage로 이루어져 있다.
- IF : 메모리부터 Instruction Fetch -> 메모리로부터 명령어 로드
- ID : Instructon Decode & register read
- EX : EXcute operation / calculate address
- MEM : access MEMory operand -> 메모리에 접근
- WB : Write result Back to register -> 레지스터에 결과를 다시 기록
3) Pipeline Performance
pipeline화된 데이터 경로와 single-cycle의 데이터 경로를 비교하면 다음과 같다.

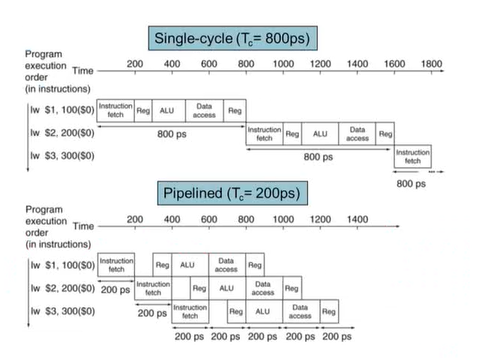
-> single-cycle은 총 소요시간인 800ps, pipelined에서는 가장 소요시간이 긴 200ps
4) Pipeline Speedup
- 만약 모든 stage들이 비슷한 처리시간을 갖는다면 'stage 수'배의 성능향상 효과를 기대할 수 있다.
- 모든 stage가 균등하지 않다면 속도향상의 효과는 더 적을 것이다. -> 가장 느린 stage에 맞춰지기 때문
- 속도향상은 throughput을 늘려서 얻은 결과이다. ->병렬식으로 동시에 여러 instruction을 실행시킴으로써
- 지연시간(각 instruction 하나를 실행하는데 걸리는 시간) 자체는 줄어들지 않는다.
5) Pipelining & ISA Design
- MIPS ISA는 pipelining에 적합한 구조이다.
- 모든 instruction : 32-bit로 한 cycle 안에 fetch하고 decode하기 쉽다.
- 적은 종류의 규격화된 instruction format
- 한 번에 decode하고 레지스터를 read할 수 있다.
- Load/Store addressing
- 주소 계산은 3번째 stage에서, 메모리 접근은 4번째 stage에서 이루어진다. 즉, stage별로 다른 작업을 수행할 수 있다.
- memory operand의 정렬
- memory access는 한 cycle 안에 이루어진다.
6) Hazards
다음 사이클에서 다음 instruction이 실행되는 것을 막아버리는 상황이 발생할 수 있다. = 매 cycle마다 instruction을 실행해야 하는데, 그렇지 못하는 경우
Structure Hazard(구조적 위험)
- instruction을 수행하기 위해 필요한 HW 자원이 사용중인 경우
- 단일 메모리를 사용하는 MIPS pipeline에서
- Load/Store 명령은 데이터 접근을 위해 메모리에 접근한다.
- instruction fetch도 instruction을 가져오기 위해 메모리에 접근한다.
- 서로 동시에 진행될 수 없으므로 한 쪽은 대기를 해야 하고 해당 cycle을 지연시킨다.
- 따라서 pipeline화된 datapath는 instruction memory와 data memory가 분리되어야 한다. 혹은, instruction과 data cache 분리
- 대부분의 Structure Hazard는 resource 부족으로 인해 발생하며, resource를 추가하면 해결되는 경우가 많다.
Data Hazard(데이터 위험)
- instruction을 수행하기 위해 필요한 데이터가 있는데 다른 instruction이 데이터를 read/write하고 있는 경우
Control Hazard(제어 위험)
- 어떤 instruction을 수행하기 ㅜ이해 다른 instruction 결과에 의존하는 경우, 제어 행동을 결정하는 것이 이전 instruction에 의존하는 경우
7) Pipeline Summary
- pipelining은 instruction의 throughput을 늘림으로써 성능을 향상시키는 방법이다.
- 한 명령어의 실행 속도가 아닌, 동시에 여러 명령을 가능하게 하는 양을 늘린 것이다.
- 병렬적으로 여러 명령을 실행한다.
- 각 instruction은 같은 지연시간을 갖는다.
- hazard에 주의해야 한다.
- instruction set의 설계방식은 pipeline 구현의 복잡도에 영향을 미친다. -> ISA가 간단할수록 pipeline 구현도 쉬워진다.
4.6 Pipelined Datapath and Control
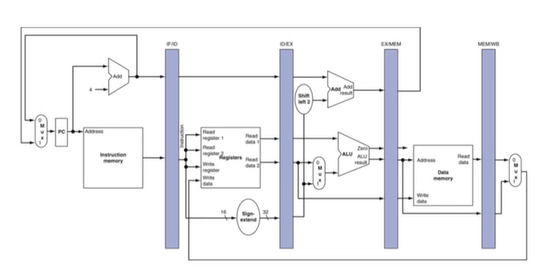
1) MIPS Pipelined Datapath
pipeline registers
각 stage 사이에 레지스터들이 필요하다. -> 이전 cycle에서 만들어진 정보를 가지고 있어야 하기 때문
2) Pipeline Operation
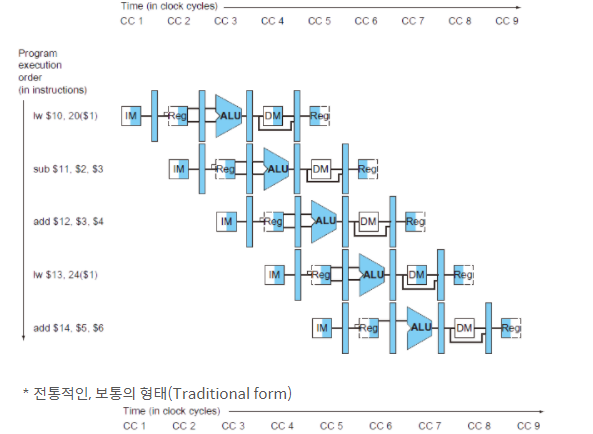
pipeline process를 이해하기 위해서는 cycle-by-cycle로 어떤 명령어가 수행되는지 이해해야 한다. cycle-by-cycle 흐름을 표현하는 방법에는 2가지가 있다.
single-clock-cycle
특정 cycle의 pipeline 현재 상태를 보여준다.
multi-clock-cycle
시간과 명령어에 따른 resource(HW 자원)을 보여준다.
3) Pipelined Control
control signal은 instruction으로부터 파생된다.
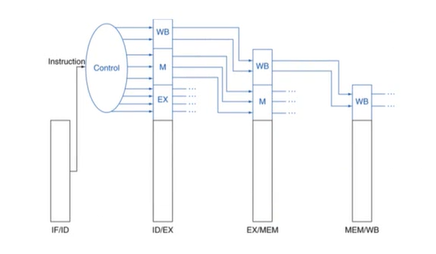
- 각 stage에 control들이 전달되기 위해 pipeline register에 함께 전달되어 보존되어야 한다.
- single-control과는 달리, ID에서 해석되어 생성된 제어신호들이 각stage에 쓰이기 위해 보존되어야 하기 때문
- pipeline이 single-cycle보다 훨씬 복잡해진다.
4.7 Data Hazards : Forwarding vs Stalling
4.8 Control Hazards
4.9 Exceptions
1) Exceptions and Interrupts
- Exception(예외) : CPU 내부에서 발생
- undefined opcode, overflow, syscall 등
- Interrupt(중단) : 외부 I/O Controller로부터 발생
- Trap(= SW Interrupt) : syscall을 구현하는데 사용 -> 명령어가 interrupt를 발생시키는 것
-> 위의 문제들을 다루기 위해서는 어느 정도의 성능 저하가 발생한다.
2) Handling Exceptions
기본 처리 방식
- MIPS에서 exception은 System Control Coprocessor(CP0)에 의해 관리된다.
- 문제가 생긴 instruction의 PC를 저장한다.
- MIPS에서는) Exception Program Counter
- 문제의 종류를 저장한다.
- MIPS에서는) Cause Register에 저장
- handler(주소 : 8000 00180)로 jump
조금 더 발전된 방식
- Vectored Interrupts : 원인에 따라 다른 handler의 주소가 정해져있다.
- 앞의 방식의 경우, 무조건 8000 00180으로 jump
- 문제가 발생한 instruction은 다음 중 하나로 진행된다.
- 해당 handler에서 처리(드뭄)
- real hadler로 jump하여 처리
2) Handler Actions
- 원인을 읽고 관련된 handler로 넘겨준다. = handler로 jump
- 필요한 동작 결정
- 해당 명령어의 재시작이 가능하다면?
- 적절한 동작으로 처리
- EPC를 이용해 원래의 PC로 돌아갈 수 있도록
- 그렇지 않다면?
- 프로그램 중단(terminate)
- Report error using EPC 등
3) Exception Properties
- 재실행 가능한 명령어에 대한 exception
- pipeline은 명령어를 비운다.
- handler가 처리 후, 원래의 instruction으로 돌아간다.
- EPC에 저장된 PC 값 활용
- EPC에는 PC + 4의 값이 저장되어 있기 때문에 다시 PC 값을 저장할 때는 4를 빼준 후 저장
4) Multiple Exceptions
- pipeline은 여러 명령어를 동시에 수행하므로 여러 exception이 한 번에 발생할 수 있다.
- 간단한 접근법 : earlier exception부터 처리
- 복잡한 pipeline에서는
- 한 사이클마다 여러 명령어 실행
- 명령어의 결과 순서가 실행 순서와 같지 않다.
- 위와 같을 경우 precise exception(어떤 명령어를 먼저 처리할지 규정되어 있는 것)을 처리하기가 어렵다.
Imprecise Exception
- pipeline 동작을 멈추고 현재 상태를 저장한다.
- handler가 동작하도록 한다. -> 어느 instruction이 exception을 일으켰는지 파악하고 어떤 것을 처리할지, 어떤 것을 flush할지 결정
- HW는 간결화하되 handler SW는 더욱 정교하게 -> SW적으로 해결
- 명령어를 다중 수행할 수 있는 out-of-order pipeline인 복잡한 최신 CPU에서는 사용할 수 없다. -> HW가 간단하지 않기 때문
4.10 Paralleslim via Instructions
1) Instruction-Level Parallelism(ILP)
pipelining : 여러 명령어들을 병렬적(parallel)으로 수행
ILP를 향상시키기 위한 방법
- Deeper pipeline : 여러 stage로 더 깊게
- stage마다 적은 일을 하면 clock cycle은 짧아진다.
- 한 stage에 같은 clock cycle이므로 stage를 세분화하여 한 stage가 적은 일을 하면 속도는 더 빨라진다.
- 한 명령어가 거칠 stage의 총 수는 많아지지만, 병렬적으로 처리
- Multiple issue
- pipeline stage를 복제 -> multiple pipelines
- clock cycle마다 여러 명령어들을 동시에 시작
- 최근에는 CPI < 1이므로 대신 IPC(Instructions Per Cycle)를 사용
2) Multiple Issue
Static multiple issue
- 컴파일러가어떤 명령어가 어느 cycle에서 실행될지 이미 결정이 되어 있는 것
- 컴파일러가 명령어들을 묶어줌 = issue slots
- 컴파일러가 hazards를 감지하고 회피시켜 줌
Dynamic multiple issue
- CPU가 instruction stream을 테스트해보고 각 cyce에 issue할 명령어들을 고름
- 컴파일러가 명령어 순서를 재배치함으로 도와줄 수는 있음
- runtime 동안 CPU는 고급 기술로 hazard 해결
3) Speculation(추측)
- 어떤 instruction을 할 것인지 예상하는 것
- 가능한 빨리 operation 시작
- 예측이 맞으면 operation을 그대로 진행, 틀리면 roll-back하고 올바른 작업 수행
- static과 dynamic multiple issue에서 공통적으로 사용하는 형태
Compiler & HW에서의 Speculation
- Compiler는 instruction들의 순서를 재배치할 수 있다.
- HW는 실행할 instruction들을 예측할 수 있다.
-> 실제로 수행되어야 하는게 맞는지 알기 전까지 buffer가 instruction들을 수행해 결과를 가지고 있는다. 추측이 맞으면 해당 명령어를 그대로 사용하고, 틀리면 buffer flush
Speculation & Exceptions
만약 추측으로 미리 실행한 명령어에서 exception이 발생한다면?
- Static speculation : ISA의 도움을 받아 exception 처리를 늦춘다.
- Dynamic speculation : 명령이 끝날 때까지 exception들을 buffer 해둔다.
