
강의 주소 : 연남대 최규상 교수님 컴퓨터 구조 강의 (2015년)
Chapter 5. Large and Fast : Exploiting Memory Hierarchy
5.1 Introduction
1) Principle of Locality(지역성의 원칙)
- 프로그램은 특정 시간에 메모리의 아주 적은 부분에 접근한다.
- Temporal locality : 최근 access한 항목은 다시 access할 확률이 높다.
- Space locality : 최근 access한 항목 근처의 것들은 다시 access할 확률이 높다.
Taking Advantage of Locality
- Memory hierarchy : 자주 사용하는 데이터를 고속의 임시 저장소로(CPU와 가깝게)
- disk에 모든 것을 store
- 최근 access한 항목들을 disk에서 작은 DRAM 메모리로 복사 -> 메인 메모리(고속)
- 좀 더 최근의 항목들은 DRAM에서 더 작은 SRAM 메모리로 복사 -> CPU와 통합된 캐시 메모리(초고속)
2) Memory Hierarchy Levels
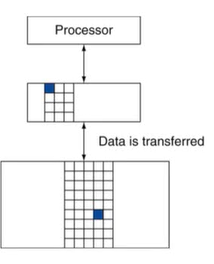
- 위에서부터 Processor/Cache/Memory
- block/line : 복사의 단위(Maybe 여러 word)
- 만약 원하는 데이터가 상층부에 존재한다면?
->Hit: 상층부에서 access 성공
-> Hit ratio = hits/accesses - 만약 원하는 데이터가 없다면?
->Miss: 하층부에서 block 복사로 시간 소요(miss penalty)
-> Miss ratio = misses/accesses = 1 - hit ratio
-> 상층부로 복사한 후, 상층부에서 데이터 access
3) Characteristics of the Memory Hierarchy
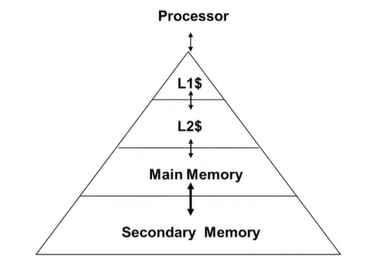
- access time : 프로세서와 가까울수록 upper level, access time이 더 빠르고 용량이 작다.
- Inclusive(포함) 특성
- L1의 일부분(L1는 Cache, Cache를 간단히 표현할 때 $ 사용)
- L2$는 메인메모리의 일부분
- 메인메모리는 2차메모리의 일부분
4) DRAM Technology
- capacitor의 충전으로 데이터가 저장된다.
- 전하에 access하기 위해 단일 트랜지스터가 사용된다.
- 주기적으로 데이터를 다시 써줘야 한다.
- SRAM은 한 번 써두면 recharge할 필요가 없으나, DRAM은 필요
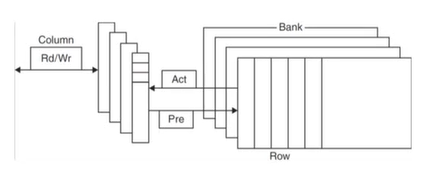
Advanced DRAM Organization
- DRAM의 bit들은 직사각형 배열(2차원 배열)로 되어있다.
- 하나의 row에 전체적으로 access하고, 그 안에서 column access
- Burst mode : row가 같고 column만 다른 경우 row를 바꿀 필요가 없어 빠른 access가 가능
- Double Data Rate(DDR) : rising, falling clock edge마다 데이터 전송(<-> Single Data Rate : 둘 중 하나로만 데이터 전송)
- Quad Data Rate(QDR), DDR2 : 기존의 DDR 칩에 input, output을 하나씩 추가해 bandwith를 2배로 증가
DRAM Performance Factors
row buffer: row 단위로 데이터를 access할 때 row별로 buffer를 사용하기 때문에 병렬적으로 여러 word를 읽거나 쓸 수 있게 해준다.synchronous DRAM: DRAM이 clock에 동기화되어 동작 -> 각각의 주소를 보내지 않고도 연속된 주소에는 burst하게 access할 수 있게 해준다. = bandwith 향상DRAM banking: 여러 DRAM에 동시에 access할 수 있게 해준다. = bandwith 향상
DRAM : Main Memory Supporting Caches
DRAM을 메인 메모리로 사용
- 고정된 사이즈
- fixed-width clocked bus에 연결되어 있음(bus clock은 CPU clock보다 느림)
Increasing Memory Bandwith(메모리 대역폭 늘리기)
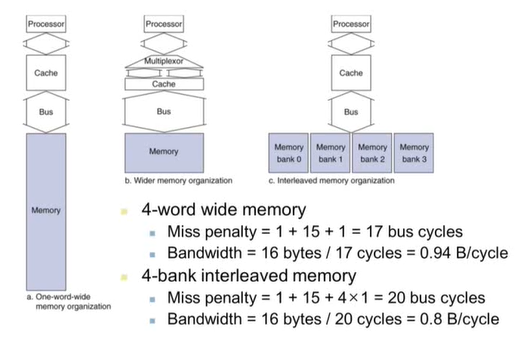
a : 1-word wide DRAM
b : 4-word wide memory
-> 긴 word를 다루기 때문에 메모리에도 긴 word 단위로 접근
-> 데이터 교환도 긴 word 단위로 이루어짐
c : 4-bank interleaved memory
-> 실제 주로 사용하는 방식
-> bank : I/O가 독립적으로 이루어질 수 있는 단위
-> 메모리 접근은 여러 bank로 동시에 접근, 데이터 교환은 차례로 수행
성능은 b가 가장 좋지만 많은 HW 자원이 사용되므로 c형태를 주로 사용한다.
c는 HW 자원을 a와 비슷하게 사용하며, 성능은 b와 비슷하게 향상된다.
5.2 Memory Technologies
Chapter 5에서 다룰 내용 : Memory(Chapter 4 : processor)
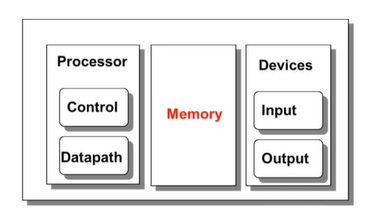
메모리는 크게 3가지로 나뉘어짐
- Cache
- Main Memory -> Chapter 5
- Secondary Memory(Disk, Storage) -> Chapter 6
1) Memory Technology
메모리는 크게 ROM과 RAM이 있다.
- ROM : Read Only Memory로 비휘발성 메모리
- Static RAM(SRAM)
- Dynamic RAM(DRAM)
- RAM : Random Access Memory로 휘발성 메모리
- Magnetic disk(HDD)
2) Processor-Memory Performance Gap
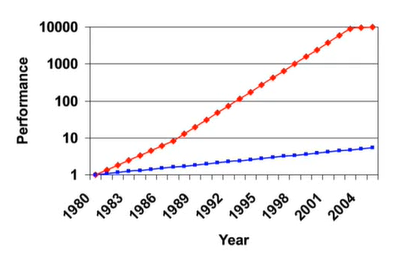
프로세서의 성능은 아주 빠르게 발전했지만 메모리는 느리기 때문에 Performance Gap이 생긴다. -> 프로세서와 메모리의 성능차이는 50%/year만큼 증가하고 있다.
The Memory Wall
프로세서 vs DRAM(메모리)의 속도 차이가 계속 커지고 있다.
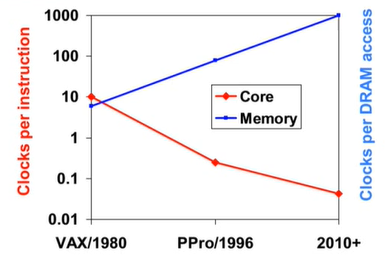
-> 메모리 성능 향상의 제한으로 프로세서의 성능 향상에도 제한이 생긴다. 메모리 체계 설계를 잘하는 것이, 컴퓨터의 전체 성능 향상에 점점 더 중요해지고 있다.
5.3 The Basics of Caches
1) Cache Memory
Cache : 메모리 계층에서 CPU와 가장 근접하게 위치
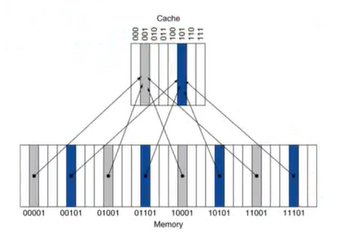
Caching : A Simple Example
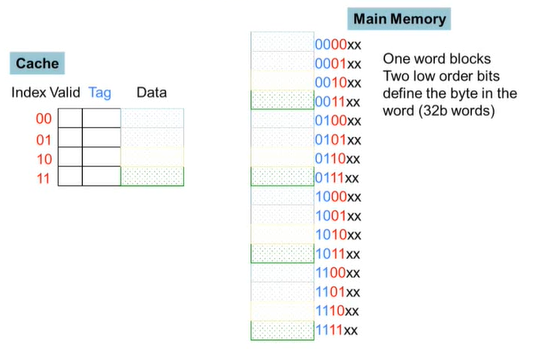
- 메인메모리 : 16개의 word blocks
- 메인메모리의 하위 2-bits는 word 안에서의 byte를 정의하는데 사용한다. -> 상관 X
- 중간의 2-bits는 캐시의 인덱스에 쓰인다. -> 캐시의 어느 line에 매핑되는지
- 상위 2-bits는 캐시의 태그에 쓰인다.
- 캐시는 메인 메모리와 어떻게 매핑이 이루어지는가?
- 메인메모리는 16 blocks, 캐시는 4 lines
- 메인 메모리의 4 block -> 캐시의 1 line으로 매핑
- 캐시의 tag와 메인메모리 주소의 상위 2-bits를 비교해 캐시에 메모리 block이 있는지 알 수 있다.
- 메인메모리의 주소들을 캐시의 bock들의 수로 나머지 연산을 한 것이 캐시의 index가 된다.
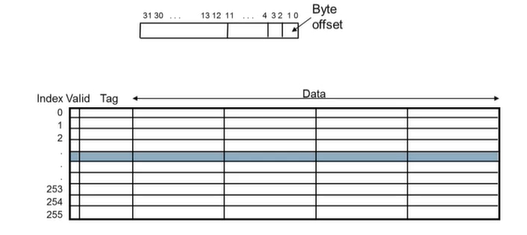
2) Direct Mapped Cache
Cache의 한 line이 한 block만 가진다.
Tags and Valid Bits
- 캐시의 위치에 매핑된 데이터가 메모리의 어느 특정 block과 일치하는지 어떻게 알 수 있는가?
- 블록 주소를 데이터처럼 저장한다.
- 오직 상위 비트들만 필요하다. -> Tag
- 만약 캐시에 데이터가 없다면?
- valid bit이 1이면 존재, 0이면 없는 것
- 처음에는 0으로 시작
3) Multiword Block Direct Mapped Cache
캐시의 블록에 여러 word가 저장
-> temporal locality와 spatial locality 활용
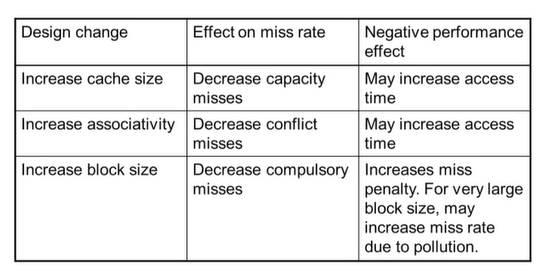
Block Size Considerations
- 블록이 클수록 miss rate 감소 -> spatial locality : 한번에 많이 저장하기 때문
- but 캐시의 크기는 고정적
- 블록의 크기가 커지면 -> 캐시의 line 수는 줄어든다.
- line이 줄어들면 하나의 line이 매핑할 메모리가 늘어나고 경쟁이 잦아진다. -> miss rate 증가
- 블록이 클수록 캐시의 line에 read/write가 자주 발생하며 오염된다. -> overhead다 더 커질 수도 있다.
- 블록이 클수록 miss penalty가 커진다.
- miss가 발생했을 때, miss마다 한 번에 더 많은 block을 읽어와야 한다.
- miss rate를 감소시키려다 전체 성능 저하가 발생할 수 있다.
- Early restart and critical-word-first 방법 할용 : refresh하려는 word 중 target word만 우선 보내서 먼저 시작
4) Cache Misses
캐시가 적중했을 때, CPU는 정상 동작
캐시가 적중 실패 시,
- CPU pipeline에 stall을 발생시킨다.
- 메모리의 다음 계층에서 해당 block을 fetch해온다.
- Instruction cache miss 시, 다시 instruction fetch가 되도록
- Data cache miss 시, data access 완료
5) Write-Through & Write-Back
Write-Through
- data-write이 발생하면 메모리가 아닌 캐시의 블록을 바로 업데이트 할 수는 있지만 그러면 메모리와 캐시의 일관성이 없어진다.
- write-through policy : 캐시와 함께 메모리도 업데이트
- 하지만, write가 더 오래걸릴 수 있다.
- 해결책으로
write buffer: 캐시에 작은 buffer를 하나 두고 메모리에 쓸 데이터를 메모리에 쓰지 않고 buffer에 쓴 후 메모리에 작성- CPU는 계속 진행
- 메모리에 write가 될 때까지 기다리지 않아도 된다.
- write buffer가 이미 가득 차있을 때에만 stall 발생
Write-Back
- data-write가 발생하면 메모리가 아닌 캐시의 블록만 바로 업데이트
- 메인메모리와 캐시의 데이터가 다른지, 같은지 관리 필요
dirty bit을 활용
- dirty block이 replace될 때, 캐시의 데이터가 유효값인데 해당 line에 교체 등의 이유로 캐시에서 빠져나가야 할 때 메모리에 write it back
- write buffer를 활용해 메모리에 쓰는 것을 CPU가 기다리지 않도록
Write Allocation
write miss가 발생한다면?
- Write-Through의 대안
- allocate on miss : miss한 데이터를 가지고 온 후 업데이트(fetch the block)
- write around : 블록을 fetch하지 않음 -> 캐시는 write하지 않고 메모리만 직접 업데이트
- Write-Back의 대안 : 주로 fetch the block
5.4 Measuring and Improving Cache Performance
1) Measuring Cache Performance
CPU time 요소
- program execution cycles : cache hit time 포함
- memory stall cycles : 주로 cache miss로부터 발생
간결화 가정
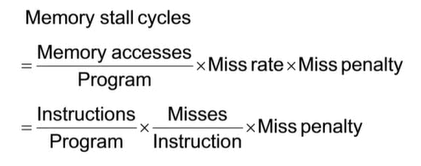
Average Access Time
hit time는 성능에 아주 중요한 요소이다.
AMAT(Average Memory Access Time) = hit time + miss rate * miss penalty
2) Performance Summary
- CPU 성능이 향상되면?
- miss penalty가 점점 더 중요하게 여겨진다.
- CPU가 빨라지면 총 시간 중에 메모리에서 소요되는 시간이 실제 실행 시간을 더 많이 차지하게 된다. -> 프로세서에서 소요되는 시간이 줄어들어서
-
base CPI를 줄이면?
메모리 stall에 소요되는 시간의 비중이 더 커진다. -
clock rate를 높이면?
메모리 stall에 걸리는 CPU cycle이 더 많아진다.
-> 시스템 성능을 평가할 때, cache의 영향을 무시할 수 없다.
3) Associative Caches
지금까지 본 캐시와는 다른 종류의 캐시 -> 캐시의 set(line)에 여러 block이 들어간다. 이 캐시의 line은 block 단위가 아닌 set 단위
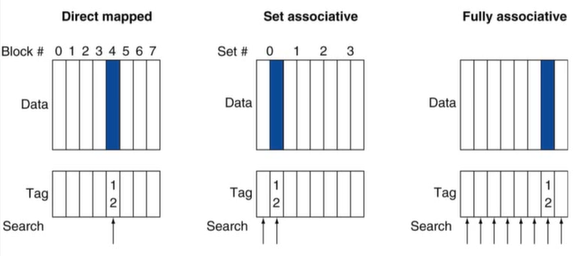
fully associative
- 특정 block이 캐시의 어는 entry에나 들어갈 수 있다.
- 모든 캐시 entry를 한번에 검색해야 한다.
- entry마다 comparator가 필요하다. -> 비싸짐
n-way set associative
- 하나의 set(line과 같은 의미)은 n개의 entry로 구성되어 있다.
- block number가 어떤 set에 매핑되는지 결정한다.
- 해당 set의 캐시 entry를 한번에 검색해야 한다.
- n개의 comparator가 필요하다. -> fully 보다는 비용 감소
Set Associative Cache Organization
set associate cache의 내부 구조(4-way set associative cache)
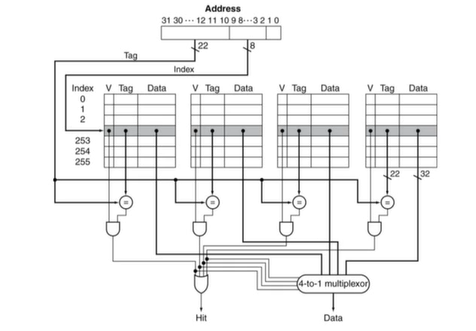
4) Replacement Policy
cache miss가 발생했을 때, set 안에서 어떤 block을 교체할 것인가?
- direct mapped : 무조건 교체(선택권 X)
- set associative : non-valid(valid bit이 0) entry가 있다면 이것을 replace, 모두 valid인 경우 LRU 알고리즘 사용 -> 고르는 것이 까다로움
- random : high associativity에서는 LRU와 유사한 성능
5) Multilevel Caches
지금까지는 한 계층의 캐시 메모리 모델을 봤지만, 최신 CPU는 여러 레벨로 이루어져 있다.
- Primary cache(L1) : CPU와 붙어있음 -> 작지만 빠르다.
- Level-2 cache : primary 캐시 miss 발생 시 접근 -> L1보다 조금 더 크고 조금 더 느리지만 메인메모리보다는 빠르다.
- 메인메모리에는 L2 캐시에서 miss가 발생했을 때 접근한다.
- 최근의 고성능 시스템은 L3캐시를 갖기도 한다.
Multilevel Cache Considerations
- Primary cache : hit time을 줄이는 것에 초점
- L2 cache : miss rate를 줄여 메인메모리에 access하는 것을 줄이는 것에 초점(hit time은 전체 성능에 큰 영향을 주지 않음)
-> 멀티레벨 캐시의 L1 cache는 일반적으로 single cache보다 작다.
-> L1 블록 크기는 L2 블록 크기보다 작다.
6) Interactions with Advanced CPUs
- out-of-order(instruction을 순서 상관없이 실행하는) CPU는 cache miss가 발생하는 동안도 instruction을 실행할 수 있다.
- 보류된 store 동작은 load/store unit에 머무른다.
- miss한 것에 의존적인 instruction은 reservation station에서 대기한다. 비의존적인(miss와 관련 없는) instruction은 계속 실행한다.
- miss의 효과는 프로그램의 data flow에 의존적이다. -> 분석이 힘들다.
5.7 Virtual Memory
1) Virtual Memory
- 메인메모리를 secondary memory의 캐시로 사용 -> CPU와 OS가 공동으로 관리
- 프로그램들은 메인메모리를 공유한다. -> 각각의 프로그램들은 개인적인 virtual address space를 가지고 자주 사용하는 코드와 데이터를 여기에 올려놓고 사용한다.
- CPU와 OS는 virtual address를 physical address로 변환해주어야 한다.
- VM 입장에서 block을 page라고 부른다.
- VM에서 miss가 발생하면 이를 page fault라고 부른다.
2) Address Translation
프로그램이 사용하는 주소 : virtual address
실제 메인메모리 주소 : physical address
-> 각 virtual address는 translation을 통해 physical address와 매핑된다.
Virtual Addressing with a Cache
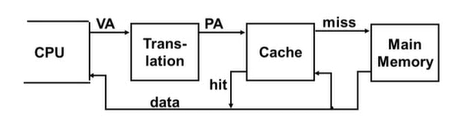
- CPU(프로그램)가 사용하는 주소 : virtual address
- Cache가 사용하는 주소 : physical address
- Translation : VA를 PA로 바꾸어주어야 한다.
- VA -> PA 하는 과정에서, extra memory access가 필요하다.
- translation 정보고 메인메모리에 존재하기 때문에 메인메모리에 access 해야한다. 하지만 메인메모리의 access time은 cache에 비해 많이 느리다. -> overhead 발생
- HW는 이 문제를
Translation Lookaside Buffer(TLB)를 사용해 해결한다.- 메인메모리의 page table을 탐색하지 않도록 최근 사용한 주소 매핑 정보를 보관하는 작은 cache
3) Page Fault Penalty
- page fault가 일어나면 해당 page를 disk로부터 읽어와야 한다.
- 수백만 clock cycle이 소요된다.
- OS code에 의해 처리된다.
4) Page Tables
- page table은 translation 정보를 갖고있다.
- page가 메인메모리에 있다면 Page Table Entry(PTE)가 실제 physical page number를 갖고 있다.
- page가 메인메모리에 없다면 PTE는 disk에 있는 swap space를 가리키게 된다.
5) Mapping Pages to Storage
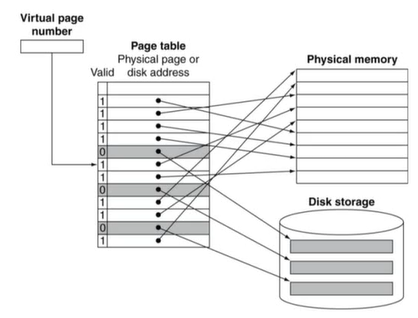
-> 어떤 page들은 메모리에, 어떤 page들은 storage에 매핑된다.
6) Replacement & Writes
- page fault rate을 줄이기 위해 LRU 알고리즘을 사용한다.
- disk에 쓰는 것은 수백만 cycle이 소요된다.
- disk access는 block 단위로 이루어진다.
- write-through 방식을 사용할 수 없어 write-back 방식 사용
- page의 업데이트 여부를 확인하기 위해 PTE에 dirty bit을 두고 표시한다.
7) Memory Protection
- 다른 작업은 각각 고유의 virtual address space를 사용한다.
- HW는 OS Protection을 위해 HW적인 지원을 한다.
- privileged supervisor mode
- privileged instructions
- page table과 기타 state 정보는 오직 supervisor mode에서만 접근 가능하다.
- system call exception
5.8 A Common Framework for Memory Hierarchy
1) The Memory Hierarchy
- 공통적인 원칙들이 메모리 계층의 전 단계에 적용된다.
- block placement
- block 찾기
- miss 발생 시 replacement
- write policy
2) Block placement
associativity에 관련이 있다. -> Higher associativity reduces miss rate
- Direct mapped : set은 1 way -> 한가지 선택지
- n-way set associative : set에 n개의 way -> n개의 선택지
- Fully associative : 하나의 set, 한 set에 모든 block이 들어가 있다. -> 캐시의 block 수 = 선택지 수
3) Finding a block
- HW caches : 비용을 줄이기 위해 비교 횟수를 줄임
- virtual memory : miss rate을 줄이기 위해 full lookup table이 full associativity를 가능하도록 해줌
4) Replacement
-
HW caches : miss 발생 시 교체할 entry를 선택하는 방법
- LRU
- Random
-
virtual memory : HW 도움으로 LRU와 비슷한 기법 사용 -> clock replacement algorithm
5) Write Policy
- HW caches
- write-through
- 상층부, 하층부를 함께 업데이트
- replacement를 간단히 만들어주지만 write buffer 필요
- write-back
- 먼저 상층부만 업데이트
- 업데이트된 block이 교체될 때 하층부도 마저 업데이트
- 더 많은 state 정보를 가지고 있어야 함
- virtual memory : disk write latency로 wirte-back만 가능
6) Sources of Misses
compulsory miss: block에 첫 access를 할 때 발생하는 misscapacity miss: 유한한 캐시 사이즈 때문에 발생하는 miss -> upper level이 lower level보다 작기 때문conflict miss- non-fully associative cache에서 발생
- set 안에서의 경쟁 때문에 발생
7) Cache Design Trade-offs
5.15 Fallacies and Pitfalls
- byte vs word addressing
- memory system을 고려하지 않고 코드 작성 -> poor locality
- shared L2 or L3 캐시를 사용하는 멀티프로세서 환경에서 core 수가 많아지면 associativity도 늘려야 한다.
- out-of-order 프로세서의 성능을 평가할 때 AMAT를 사용하면 AMAT 측정은 non-blocked access의 영향을 무시한다. -> simulation을 통해 성능을 평가해야 한다.
