
강의 주소 : 연남대 최규상 교수님 컴퓨터 구조 강의 (2015년)
Chapter 6. Storage and Other I/O Topics
6.1 Introduction
I/O 장치 분류 방법
- 동작 : Input, Output, Storage
- 파트너(누구와 동작)
- data rage : bytes/sec, transfer/sec
I/O bus connections
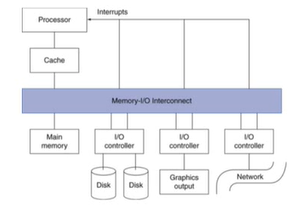
I/O System Characteristics
- 안전성, 신뢰성이 중요하다. -> 오류 없이
- 성능은 Latency(응답시간)와 Throughput(처리량)으로 나뉘어진다.
- desktop & embeded systems : response time과 diversity of devices에 초점
- servers : throughput과 expendability of devices에 초점
6.2 Dependability, Reliability and Availability
1) Dependability
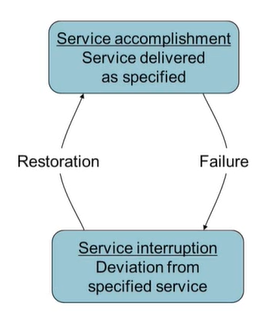
Dependability Measures
- Reliability : MTTF(Mean Time To Failure) -> 평균적으로 오류가 언제마다 한 번씩 발생하는지
- Service interruption : MTTR(Mean Time To Repair) -> 수리에 걸리는 시간
- MTBF(Mean Time Between Failures) = MTTF + MTTR -> 오류들 사이의 평균 시간
-> 서비스가 제대로 수행될 확률 : Availability = MTTF / (MTTF + MTTR)
-> Availability를 향상시키려면?
- MTTF를 증가시킨다 : fault avoidance, fault tolerance, fault forecase
- MTTR을 감소시킨다 : 진단과 수리를 위한 향상된 도구와 프로세서 사용
6.3 Disk Storage
비휘발성, rotating magnetic storage
1) Disk Sectors and Access
- 각 sector에는 기록된 내용
- sector ID
- data
- Error Correctiong Code
- synchronization fields와 gaps
- 특정 sector에 access하는데 다음의 과정이 소요된다.
- queing delay : 만약 다른 access가 보류중이라면 대기열에 들어가 기다린다.
- seek : head를 원하는 track 위로 움직인다.
- rotational latency : track 중에 sector가 head 위치에 오도록 한다.
- data transfer : 데이터를 쓰거나 읽는다.
- controller overhead : 읽은 데이터를 메모리 버스나 I/O 버스에 전달한다.
2) Disk Performance Issues
- 제조사는 평균 seek time을 명시해야 한다.
- smart disk controller는 disk에 physical sector를 할당시킨다.
- disk driver들은 cache를 갖고있다.
6.4 Flash Storage
비휘발성의 semiconductor(반도체) storage로 disk 보다 100 ~ 1000배 빠르다. 더 작고 더 저전력에, 외부충격에 더 강하다.
1) Flash Types
- NOR flash : bit cell이 마치 NOR gate와 유사하다.
- NAND flash : bit cell이 마치 NAND gate와 유사하다.
-> flash bit은 수만 번의 access를 거친 후 기능이 상실된다.
-> direct RAM이나 disk의 완전 대체로는 적합하지 않다.
6.5 Connecting Processors, Memory, and I/O Devices
1) Interconnecting Components
- CPU, memory, I/O controllers는 서로 연결이 필요하다.
- Bus : 요소끼리 공유하는 소통 채널
- data 및 data transfer의 synchronication을 위한 선들의 병렬 집합
- 병목현상이 생기기 쉽다.
- 물리적 인자들에 의해 성능이 제한된다. -> wire의 길이, connection의 수 등
- 최근에는 high-speed serial connections 지원
Bus Types
- 메모리 bus : 짧고 초고속
- I/O bus : 길고 multiple connection 허용, bridge를 통해 메모리 bus와 연결됨
Bus Signals and Synchronization
- data lines : address, data 운송
- control lines : data type을 나타내거나 transaction 동기화
- synchronous bus : bus clock에 맞춰 동작
- asynchronous bus : handshaking 방식으로 request/acknowledge control lines 사용
6.6 Interfacing I/O Devices to the Processor, Memory, and Operating System
1) I/O Register Mapping
- memory mapped I/O
- I/O instructions
2) I/O Data Transfer
- polling과 intterupt-driven I/O : CPU가 개입해야 한다. CPU가 data를 메모리와 I/O data register에 전달한다.
- Direct Memory Access(DMA) : OS가 메모리의 시작주소를 알려주면 CPU의 개입 없이 I/O controller가 메모리간에 자율적으로 교환
DMA/Cache Interaction
- DMA는 CPU가 개입하지 않아 메모리에 있는 데이터만 읽는다. 하지만 최근의 값은 캐시에 있을 확률이 높다.
- DMA가 캐시된 메모리 블록에 write를 하면 캐시의 데이터는 원본과 달라진다.
- 캐시의 통일성을 보장하려면?
- DMA가 사용하려는 블록에 대해 캐시가 해당 블록을 비우도록 한다.
- DMA가 write하면 캐시가 stale(원본과 달라짐)하지 않도록
- DMA가 read하면 캐시가 write-back해서 올바른 정보를 읽도록
DMA/VM Interaction
- OS는 메모리의 virtual address를 사용한다. 하지만 DMA는 physical memory를 사용한다.
- DMA가 virtual adress를 사용하려면?
- controller가 translation 작업을 해야한다.
6.7 I/O Performance Measures : Examples from Disk and File Systems
1) Measuring I/O Performances
- I/O Performance는 다음에 의존한다.
- HW : CPU, memory, controllers, buses
- SW : OS, database management system, application
- workload : request rates, patterns
- I/O 시스템 설계는 응답시간과 처리량 사이의 trade-off를 할 수 있다.
6.9 Parallelism and I/O : Redundant Arrays of Inexpensive Disks
1) RAID
- Redundant Array of Inexpensive Disks
- 여러개의 작은 디스크를 그룹으로 사용
- parallelism이 성능을 향상시켜 준다.
RAID 0
- no redundancy
- 성능은 향상된다. -> 한번에 여러 장에서 읽을 수 있기 때문
- but 데이터에 오류가 발생하면 복원할 수 없다.
RAID 1
- mirroring
- N + N의 디스크로 데이터 보관, 복제
- data disk와 mirror disk 모두에 data write
- 성능은 1개의 디스크와 그대로지만 데이터에 오류가 발생하면 mirror로부터 read할 수 있다.
RAID 2
- Error Correcting Code
- N + E의 디스크로 N개의 디스크에 data를 bit단위로 쪼개어 나눠 저장
- E개의 디스크에 ECC 생성
- 너무 복잡해 실제로는 잘 쓰이지 않는다.
RAID 3
- Bit Interleaved Parity
- N + 1의 디스크
- N개의 디스크에 data를 byte 단위로 쪼개어 디스크들에 번갈아가는 순서로 저장
- 1개의 디스크에 parity 저장 : 원본을 비교해 만든 정보
- read access : 모든 디스크로부터 read
- write access : 모든 디스크에 access
- 오류 발생 시 parity를 사용해 복원할 수 있다.
- 많이 쓰이지 않는다.
RAID 4
- Block Interleaved Parity
- N + 1의 디스크
- N개의 디스크에 data를 block 단위로 쪼개어 디스크들에 번갈아가는 순서로 저장
- 1개의 디스크에 parity 저장
- read access : required block을 갖고 있는 디스크에서만 read
- write access : 수정될 block을 갖고 있는 디스크 하나와 parity 디스크만 read, 새로운 parity를 계산하고 해당 data 디스크와 parity 디스크를 업데이트
- 오류 발생 시 parity를 사용해 복원할 수 있다.
- 많이 쓰이지 않는다.
RAID 5
- N + 1의 디스크
- RAID 4와 비슷하지만 parity block이 전 디스크에 걸쳐 분산되어 있다.
- parity disk에 집중되는 병목 현상을 방지해준다. -> 성능 향상
- 주로 사용하는 방식이다.
RAID 6
- P + Q Redundancy
- N + 2의 디스크
- RAID 5와 비슷하지만 두배의 parity
- more redundancy : fault tolerance가 향상됨 -> 여러 오류가 발생해도 복원 가능
2) RAID Summary
- RAID는 performance와 availability를 향상시킨다.
- disk failure가 independent하다고 가정한 것이다. -> 전체가 파손되면 소용 없다.

Software Engineer