- paper_link
- code_link
- EMNLP 2024
Abstract
- RAG 시스템은 잡음에 취약하고 잘못된 응답을 생성할 가능성이 있음
- 적대적 조정 다중 에이전트 시스템(ATM)을 이용하여 검색 증강 생성기를 최적화
- 보조 공격자 agent의 도움을 받아 여러 차례 agent를 적대적으로 조정함으로서 생성기가 질문 응답을 위해 유용한 문서에 대한 견고한 관점을 갖도록 안내
여기서는 '잘못된 응답을 생성할 수 있다!'에 초점을 맞춘 것으로 보임
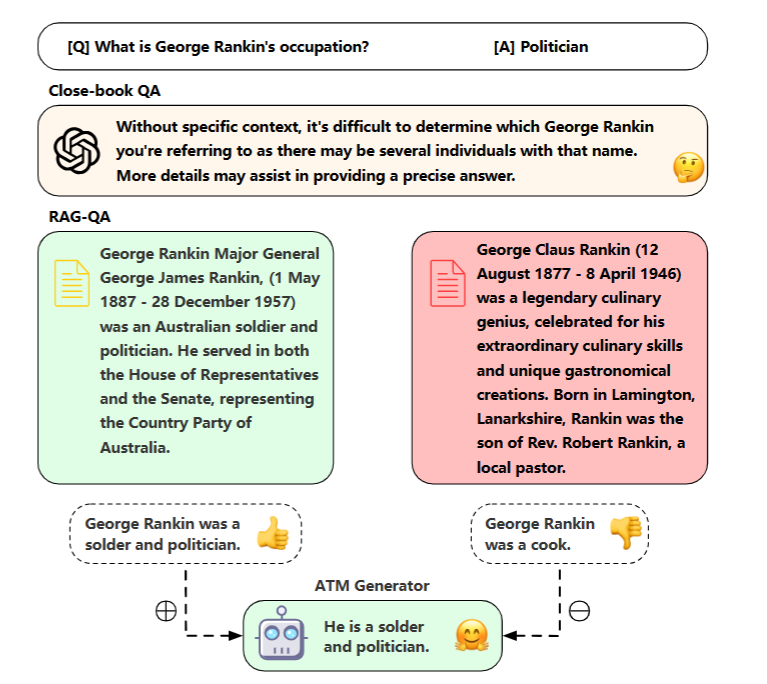
- 위와 같이 허위 정보가 섞여들어갈 수 있음
강건성
- 지식 노이즈는 주로 검색 문서의 허위 정보에 의해 발생
- 문서 목록에 대해 적대적 변화 수행 = 허위 정보 생성 및 목록 순열을 통해 위치적 노이즈를 증가시키고 생성기에 도전하는 나쁜 QA 문맥 생성
생성 능력
- 원래의 SFT 데이터와 공격자로부터의 확장 데이터를 통해 RAG 미세 조성해서 생성기 조정 강화
- 공격자 : 검색된 문서를 입력으로 받아 허위 정보를 생성하려고 하며 생성기가 잘못된 결과를 생성하게 함
- 생성기 : 공격자의 허위 정보를 입력으로 받아 강건하고 정확하게 생성.
- 공격자는 주석 달린 답변에 대해 생성기의 혼란도(PPL)를 최대화하도록 정렬
- 생성기는 허위 정보가 주입돼도 제대로 된 답의 생성 확률을 극대화하는 방법을 배움
=> 강력한 공격 패턴을 가진 공격자와 안정적이고 정확하게 생성하는 강건한 생성기!
ATM system
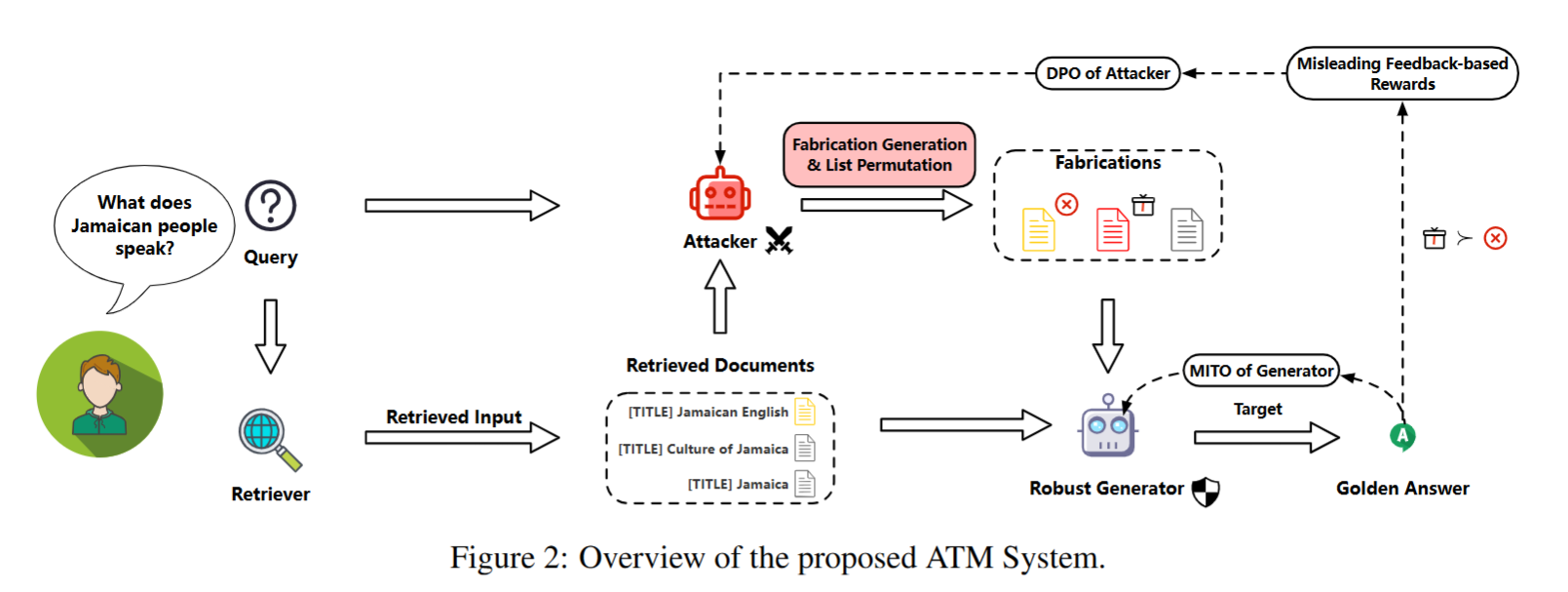
- 사용자의 질문(Query)이 주어지면, Retriever는 관련된 문서를 검색
- Attacker는 검색된 문서 목록에
Fabrication Generation과List Permutation을 적용해 적대적인 공격을 수행 Fabrication Generation: LLM이 생성한 잘못된 지식을 주입하는 과정List Permutation: 검색된 문서의 순서를 섞어 GENERATOR를 혼란스럽게 함- Robust Generator는 공격받은 문서 목록을 입력받아
MITO(Multi-agent Iterative Tuning Optimiztion)를 통해서 학습하며, 궁극적으로 Golden Answer를 생성하는 것을 목표로 함 - MITO는 생성된 답변의 품질과 노이즈에 대한 저항력을 모두 향상시키도록 설계!
Attacker
Fabrication Generation
- 제공된 쿼리와 문서 목록을 통해 "의미적으로 관련 있지만 무용하거나 부정확한 허구를 반복적으로 생성"

- Attacker는 날조 생성과 목록 순열(무작위로 섞기)을 통해 거짓정보 생성
Generator
- 어떤 문서 목록 D'가 주어지더라도 정답 a를 생성하는 확률을 최대화하고, 원래 문서 목록 D를 사용했을 때와 공격받은 문서 목록 D'를 사용했을 때의 생성 확률 차이를 최소화하는 것을 목표로 함
Multi-agent Iterative Tuning
- ATTACKER는 지속적으로 공격 강도를 높여 GENERATOR가 오답을 생성하도록 유도
- GENERATOR는 ATTACKER의 공격에 저항하면서, 동시에 답변 생성 능력을 점진적으로 향상
- 문서 d'가 GENERATOR가 올바른 답변을 생성하는 것을 성공적으로 방해하면 그것을 오해의 소지가 있는 것으로 간주함
- GENERATOR를 최적화하기 위해서 MITO 손실을 도입!
- : Multi-agent Iterative Tuning Optimization의 약자로, 최종 손실 함수
- : 공격받은 문서 목록 D'가 주어졌을 떄 질문 q에 대한 정답 a를 생성하도록 GENERATOR를 학습시키는 손실. 노이즈가 섞인 데이터에서도 정확한 대답을 생성하도록 함
- : 일반적인 문서 목록 D와 공격받은 문서 목록 D'사이의 답변 생성 확률 분포의 차이를 측정함.
훈련이 어떻게 되는건데?
Attacker 훈련
- Attacker가 생성한 Fabrication이 얼마나 효과적으로 generator를 mislead했는지 측정하기 위해 PPL(Perplexity)를 계산
- PPL : 언어 모델이 특정 텍스트 시퀀스를 얼마나 잘 예측하는지를 나타내는 지표로 높을 수록 모델이 예측 어려워한다는 것
- Attacker는 Generator의 PPL을 최대화하는 것을 목표!
DPO(Direct Preference Optimization) 활용
- DPO는 사람이 선호하는 응답과 그렇지 않은 응답을 비교하여 모델을 훈련시키는 방법
- DPO는 Attacker가 선호하는 Fabrication을 생성할 확률을 높이도록 훈련
Generator 훈련
- Supervised Fine-Tuning(SFT) 손실을 최소화
- KL Divergence 최소화()
Experiments
-
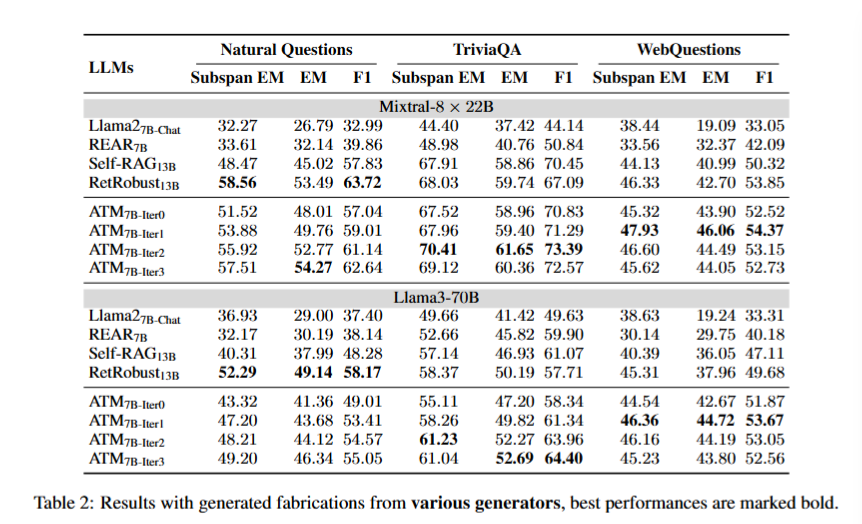
Subspan EM : 모델이 생성한 답변이 정답의 일부와 정확히 일치하는 경우를 측정
-
EM(Exact Match) : 모델이 생성한 답변이 정답과 완전히 일치하는 경우. 사소한 차이라도 있으면 오답 처리
-
F1 : 모델의 답변 정확도와 재현율 조화 평균
-
전반적으로 ATM 모델이 적대적 튜닝을 통해 noisy한 환경에서도 robustness를 유지!

얍얍