🔆 LLM-based multi-agent system이 어떻게 구성되는지 설명하는 survey 논문이다. 강화학습 기반 multi-agent를 배우며 ehtical한 ai를 만들기 위해 multi-agent가 꼭 필요하다고 생각해 읽게 되었다.
- 주 : 내용 정말 김...
1 Intruduce
- 자율 지능 시스템의 신뢰성과 지능성을 향상시키는 것은 오랫동안 매우 유망한 연구 분야로 여겨져 왔음
- 역사적으로, RL 기반 지능 시스템이 이 분야를 지배해 왔으며, 이 시스템의 에이전트는 일반적으로 환경과의 제약 상호 작용을 통해 간단하고 잘 정의된 행동이나 작업을 수행하도록 할당
- LLM 기반 에이전트는 복잡한 환경과 상호작용하고, 다양한 응용 분야에서 복잡한 작업을 해결하는 데 큰 진전을 이룸
- 본 논문에서는 LLM 기반 다중 에이전트 시스템 분야의 기존 연구를 위한 전체적이면서도 세부적인 인지 프레임워크를 수립
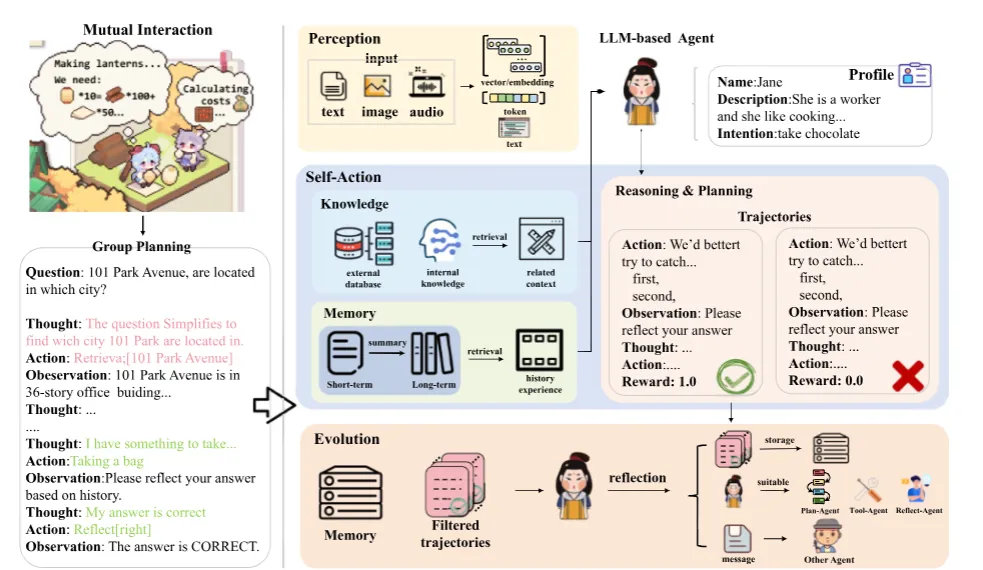
2 Background
2.1 Single Agent
- 단일 에이전트 시스템은 독립적으로 환경을 인식하고 결정을 내릴 수 있는 단일 LLM 기반 지능 에이전트로 구성됨
- 단일 에이전트 시스템의 핵심은 에이전트의 개별 특성, 인식 능력 및 자가 행동 능력에 있음
- 핵심은 개별 특성, 인식 능력, 자가 행동능력
- 개별 특성 : 그 행동 패턴과 환경 내 역할을 정의하는 고유한 특성과 능력을 갖추고 있음
- 인식 능력 : 감각 시스템을 통해 외부 세계를 이해하고 해석하는 방식
- 자가 행동 : 에이전트가 자신의 인식 및 내부 상태에 따라 결정을 내리고 행동을 실행할 수 있는 능력
- 집중성과 효율성이 좋고 중앙 집중식 처리로 여러 에이전트 간의 자원 할당 필요성이 줄어들어 전체 효율성 향상되며 설계 및 유지 관리가 명확. 또한 복잡한 통신 및 조정 매커니즘이 필요하지 않아 시스템 복잡성이 줄어들고 문제 해결 및 성능 최적화 과정이 단순화됨
2.2 Multi agents
- 단일 에이전트 시스템은 확장된 협력이나 집단 지성이 필요한 복잡한 문제를 다룰 때 제한이 있음
- MAS의 핵심은 분산된 의사 결정 및 문제 해결 기능
- 각 에이전트가 자율성을 지니며 독립적으로 환경을 인식하고 결정을 내릴 수 있음
- 협력, 경쟁 및 계층적 조직과 같은 실제 협력 패턴을 시뮬레이션해서 상호작용이 가능함.
- 강화 학습을 통해 이루어짐
- MAS의 구조 : 에이전트 수준과 시스템 수준의 특성으로 나누어짐.
각 프로그램들은 세 부분으로 나눌 수 있다. 통신 패러다임, 통신 구조, 그리고 통신 내용.
- 통신 패러다임 : 상호 작용 스타일을 나타냄
- 통신 구조 : 탈중앙화, 중앙화, 계층화 또는 중첩의 네 가지 유형으로 분류되어 다양한 작업 요구와 환경 조건에 정으함
최근 몇 년 동안 LLM의 급속한 발전으로 인해 LLM 기반 다중 에이전트 시스템(MAS)이 나타나기 시작했다. 이러한 시스템에서 에이전트는 자연어 이해 및 생성에 대한 LLM의 강력한 기능을 활용해 더 복잡하고 유연한 상호작용을 가능하게 한다.
3 LLM-based multi-agent work
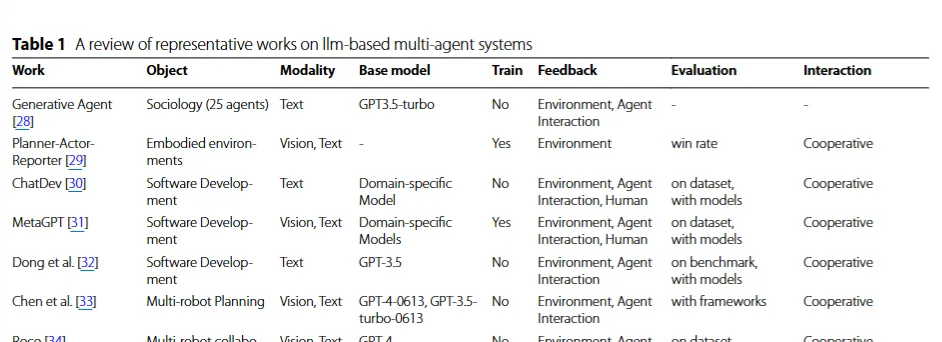
해당 표는 다양한 관점에서 현재의 작업에 대한 자세한 분석으로, 에이전트의 이름(Work), 목표(Object), 사용된 데이터 유형(Modality), 훈련 여부(Train), 에이전트 상호작용 피드백 형태(Feedback)으로 이루어져 있다.
해당 부분에서는 총 5가지의 모듈을 논의하고자 한다.
- Profile Module : 작업 목표에 따라 특정 특성을 가진 LLM 기반 에이전트 초기 생성
- Perception Module : 현재의 상호작용 환경을 이해하기 위한 필수 정보 캡쳐
- Self-action Module : 메모리에 저장된 역사적 지식과 경험을 통합하고 외부 지식 및 인식된 정보를 보완해 추론, 계획 및 일반화 능력을 사용해 의사결정을 내리고 계획을 생성
- Mutual Interaction Module : 에이전트 간의 통신 및 협력
- Evolution Module : 환경 상호작용 중 자기 반성을 통해 에이전트의 인지 및 작업 처리 능력을 증강
3.1 Agent Profile
LLM 기반 다중 에이전트 시스템은 일반적으로 복잡한 작업 실행이나 복잡한 시나리오를 가정하여 수행한다. 그렇게 에이전트 프로파일을 잘 작성해야 각 에이전트가 지정된 기능에 맞게 잘 수행하기 때문이다. (ex. 학교에서 적합한 맥락은 교사, 학생 및 교장)
Profile Context
에이전트 프로파일에 Text로 정보를 담는 것을 의미한다!
에이전트의 기본 본질적인 특성으로 작용하는 프로파일은 일반적으로 이름, 나이, 성별 및 직업과 같은 기본 정보를 포함하는데 추가적으로 현재 감정, 성격, 인생 목표와 같은 심리적 속성도 포함되어 독특한 성격을 반영한다. + 더욱이 에이전트가 참여할 수 없는 행동을 명시하기 위해 제한정보가 포함될 수 있다.
Generation Strategy
에이전트를 프로파일링하기 위해 선택된 정보는 주로 특정 응용 시나리오에 의해 결정되며, 이는 프로파일 생성의 경로를 안내한다. 다음과 같은 세 가지 전략이 있다.
-
맥락화된 생성 방법(Contextulized Generation Mothod)복잡한 시나리오를 분석하고 이를 여러 개의 하위 작업으로 나누는 과정을 통해 각 에이전트에게 구체적인 임무를 부여한다. 그리고 이들 간의 협력이 시스템의 효율성을 높이는데 중요한 역할을 한다.
ex. 기업 환경에서는 의사 결정, 배포, 실행 및 피드백을 포함하는 작업의 작업 흐름은 관리자, 비서, 일반 직원 및 컨설턴트의 네 명의 에이전트 협업을 필요
실제로 이 방법은 이전에 주로 사용되었는데, 소프트웨어 회사에서 각 에이전트의 정체성을 정의하기 위해 자연어로 된 설명을 활용하며, 여기에는 그들의 직업과 에이전트 간의 관계가 포함돼 시드 메모리로 작용한다.
ex. MetaGPT(효율적인 인간 작업 흐름을 LLM 기반의 다중 에이전트 협력에 통합한 혁신적인 메타 프로그래밍 프레임워크)
- 장점 : 1) 맥락화된 생성 방법은 복잡한 과제의 맥락에 따라 에이전트 프로필의 유형과 내용을 유연하게 결정 2) 작업 요구 사항과의 최적 맞춤형을 보장
- 단점 : 새로운 시나리오에 대해 에이전트 프로필을 재생성해야 하기 때문에 일회성이고 노동 집약적임
-
사전 정의된 방법(Pre-defined Method)대규모 언어 모델(LLM)을 광범위하게 활용하여 여러 에이전트를 정의하고, 이를 통해 에이전트 풀을 형성한다. 그리고 특정 시나리오에 직면했을 때, 적합한 에이전트가 해당 풀에서 선택되어 관련 하위 작업을 수행한다.
프로필 생성 규칙을 명확히 설정해야 하고, 에이전트의 상태 정보는 복구 혹은 후속 작업을 위해 업데이트 한다.
ex. SpeechAgents : 에이전트를 위한 초기 시드 프로필 생성
-
학습 기반 방법(Learning-based Method)몇몇 에이전트를 초기에 넓은 범위로 정의한다. 특정 시나리오가 발생하면 사전 정의된 에이전트가 하위 작업을 수행하고, 새로운 에이전트가 이후에 생성되어 새로운 작업을 처리하며 새 상황에 적응한다. 새로운 에이전트 생성에는 LLM이 활용되며 이전 에이전트 프로필과 에이전프 프로필 규칙을 결합해 자동으로 에이전트를 생성한다.
ex. RecAgent : 초기 프로필 구성 후 ChatGPT를 통해 추가 에이전트 프로필을 생성
- 해당 방식은 이전 접근 방식의 장점을 통합해 유연성을 증가
3.2 Perception
정보는 인지 모듈을 통해 중간 표현으로 변환되고, 이후 에이전트의 자율적 의사결정 결과와 행동 반응을 결정하게 된다.
LLM 기반 에이전트가 다중 모달 정보를 인식하는 출처가 무엇인지, 그리고 LLM 기반 에이저트가 다중 모달 인식 능력을 부여받는 방법론에 대해 설명하고 있다.
Message source
특정 시나리오 몰입한 LLM 기반 에이전트는 상호작용 중에 메시지를 인식, 처리, 생성하며 이는 협력에 중요한 역할을 한다.
전체 환경 메시지(Entire Environment Message)- 에이전트 주변 환경에 대한 기본 정보(장면의 위치, 레이아웃, 가구, 장면 전환), 시간 민감한 정보, 분위기나 감정적으로 미세한 정보와 같은 감정적 정보를 전달
- 초기에는 사용자가 정의하지만 이후에는 에이전트 자신이나 추가 LLM에 의해 자동 생성 가능
- 에이전트의 행동 변화 등으로 이어지며 상호작용에 영향을 미침
상호작용 메시지(Interaction Message)- 에이전트 간 상호작용 중 교환되는 정보로, 작업 요구 사항이나 시뮬레이션된 시나리오에 따라 유연하게 결정
- 일반적으로 상호작용하는 에이전트에 의해 자율 생성, 경우에 따라 특정 에이전트를 향한 제어 신호로서 LLM이 생성하기도 한다.
- 에이전트 간 기본적인 커뮤니케이션과 상호작용의 매개체이며, 그들의 의사결정 및 행동 반응에 영향을 미친다.
자기 반영 메시지(Self-Reflection Message)- 자신의 역사적 메시지, 다른 에이전트와의 상호 작용에서 생성된 메시지, 포괄적인 환경 배경 정보를 혼합하여 포함한다.
- 에이전트가 자기 반성 후 업데이트 신호를 생성하도록 안내하는 지표 역할을 함
Message Type
LLM 기반 에이전트는 텍스트, 시각, 청력을 포함한 다중 모달 인식 능력을 어떻게 얻었을까?
-
텍스트 메시지텍스트 커뮤니케이션은 인간이 세계와 상호작용하는 주요 방법이다. 더욱이 LLM이 텍스트 기반 입력 및 출력을 선호하므로 LLM 기반 에이전트도 상호작용 및 정보 전파의 주요 매체로 텍스트 메시지를 활용한다.
- 무엇이 포함되어 있나? 환경 설명, 다른 대리인으로부터의 텍스트 출력, 대리인의 자체 텍스트 데이터와 같은 원시 정보, 시각 모델을 통해 이미지에서 추출된 캡션 정보와 같은 다른 양식에서 유도된 변화한 데이터
일부 연구는 텍스트 내의 암묵적인 의미와 감정적 내용을 분석하고 이해하는 데 초점을 맞추고 있음.
- 무엇이 포함되어 있나? 환경 설명, 다른 대리인으로부터의 텍스트 출력, 대리인의 자체 텍스트 데이터와 같은 원시 정보, 시각 모델을 통해 이미지에서 추출된 캡션 정보와 같은 다른 양식에서 유도된 변화한 데이터
-
시각 메시지
텍스트 메시지는 시각 정보가 줄 수 있는 미세한 특성을 포착하고 전달하는데 한계가 있다.
ex. 개체의 세부 속성, 대리인 간의 미세한 공간 관계, 복잡한 기상 조건 등
- 이전 연구는 시각 언어 모델(VLMs)을 어댑터로 사용하여 시간적 특징을 추출하고 이를 LLM 지식 기반에 통합하거나 함께 작동하도록 해 시각 정보를 추가로 처리할 필요 없도록 했음 →
But! 시각 인식을 전달하는 정확성과 세부 사항을 사용된 특정 VLM에 크게 의존함! 그 과정에서 종종 많음 암시적 시각 정보를 잃게 됨
- GAN 아키텍처를 활용해 생성기 잠재 공간 내에서 시각 정보를 시각 벡터로 인코딩 →
But! 해석 가능성이 결여된 잠재 벡터를 초래해 관련성을 직접 이해하기 어렵게 만듦
- ViT(Vision Transformer), VQVQE(벡터 양자화 변형 자동 인코더)와 같은 접근법들은 이미지를 고정 크기 패치로 나누고, 이를 고차원 벡터 공간으로 매핑하여 트랜스포머 인코더에 입력하는 방식으로 처리 → 이미지의 전역적 및 지역적 특성을 정교하게 표현해, 시각 콘텐츠 인식 good → 시각 인코더를 LLM 내의 추가 모듈로 통합해 이미지와 텍스트의 엔드 투 앤드 처리를 달성하거나 LLM에 사전 변환된 시각 토큰을 제공하는 어댑터로 사용 → 세분화와 정확성 향상 →
But! 계산 자원에 상당한 요구를 부과하며 소규모 샘플 작업에서의 최적 성능을 보이지 않음
비디오 인식의 경우, 이미지와 비교했을 때 시간 차원의 연속성과 변동성에 더 큰 비중을 두고 있음 → 이미지 인식 능력을 활용해 비디오 콘텐츠를 이해할 수 있다!
- 이전 연구는 시각 언어 모델(VLMs)을 어댑터로 사용하여 시간적 특징을 추출하고 이를 LLM 지식 기반에 통합하거나 함께 작동하도록 해 시각 정보를 추가로 처리할 필요 없도록 했음 →
-
청각 메시지
고유한 시간-주파수 특성 덕분에 오디오 메시지는 텍스트나 시각이 복제할 수 없는 지각 정보를 전달한다. LLM 기반 에이전트가 시각 정보를 인식하는 것처럼 오디오 정보에 대한 인식은 세 가지 유형으로 분류가 가능하다.
- (WavJourney, AudioLM) 오디오를 이산 토큰으로 변환하고(ex. 소리의 스펙트로그램을 분석해 특정 음 파형을 디지털 방식으로 표현하는 것) 이를 LLM 지식 기반에 통합하는 오디오 인코더 사용 →
But! 오디오의 시간적 연속성을 간과한다. 오디오 신호는 본래 연속적으로 변하는 파형을 가지고 있으나 이산 토큰으로 변환하게 되면 데이터의 샘플링과 비트레이스 등에 의해 변형되어 세부적인 정보가 손실 될 수 있다.
- 확산 모델의 잠재 공간 내에서 오디오 정보를 잠재 벡터로 인코딩 → 계산 효율성을 높이지만
But! 추출된 저차원 오디오 특징이 지나치게 단순할 수 있음
- 오디오 정보를 임베딩으로 표현 일반적으로 다른 유형의 데이터와 통합하기 위해 사용되는데, 완결 연결 계층, 멀티헤드 크로스 어텐션, Q-포머 등을 이용해 특징을 추출한다. → 세밀한 오디오 특징을 포착, 인코더를 고정해 훈련 시간과 컴퓨팅 비용 절약
- 오디오 정보의 인식을 시각 정보의 인코딩으로 변환 오디오 스펙트로그램을 평면 이미지로 시각화하는 것인데, 예를 들어 AST(Audio Spectrogram Transformer)는 오디오 스펙트로그램 이미지를 처리하기 위해 Transformer 아키텍처를 사용해 스펙트로그램을 패치로 분할함으로써 오디오 정보를 효과적으로 인코딩함
- (WavJourney, AudioLM) 오디오를 이산 토큰으로 변환하고(ex. 소리의 스펙트로그램을 분석해 특정 음 파형을 디지털 방식으로 표현하는 것) 이를 LLM 지식 기반에 통합하는 오디오 인코더 사용 →
3.3 Self-Action
사회적 맥락에서 인간은 자율적인 개체로서 지각된 정보를 처리하여 기억을 생성하고, 인지 인식을 구축하며, 개인적인 생각을 발전시키고, 행동을 수행한다.
이와 유사하게 에이전트의 자기 행동은 그들이 자율적으로 결정을 내리고 상호작용 환경에서 생존과 진화를 위해 필요한 행동을 수행하는 독립적인 개체로 기능하는 중요한 매커니즘이다.
개별 에이전트가 자율적으로 학습하고 추론하는 방식?
지각된 정보 수신 → 기억을 호출해 관련 역사적 경험 추출 (+) 외부 지식 기반에서 추가 지식 보완 → 정보의 융합은 맥락으로 작용해 에이전트가 추론, 계획 및 일반화, 궁극적으로 의사 결정 → 에이전트는 실제 세계 상호작용을 달성하기 위해 해당하는 행동 수행 (+) 기억을 자가 업데이트하고 진화
Memory
기억검색(Retrieval), 기억저장(Storage), 그리고 기억 반영(Reflection)으로 나눠진다.
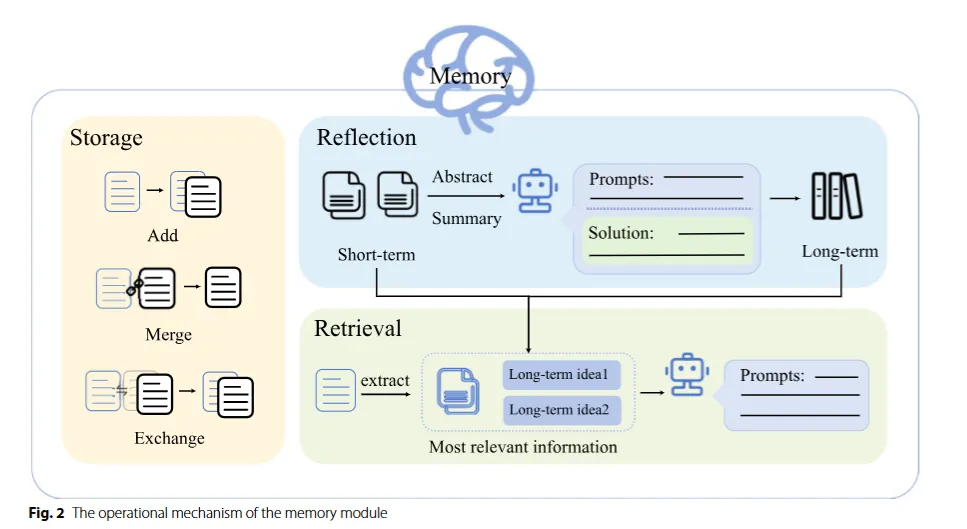
Memory Retrieval
- 메모리 검색의 목표 : 에이전트의 메모리에서 현재 상황과 관련된 귀중한 정보를 추출하여 의사 결정을 더욱 정확하게 만드는 것(ex. 환경 인식, 과거 상호작용 기록, 경험적 데이터 밋 외부 지식)
- 단기 메모리와 관련된 경우 : 검색 모듈이 일반적으로 전체 정보 콘텐츠 추출
- 장기 메모리와 관련된 경우 : 필터링 메커니즘을 사용해 가장 관련성 높은 메모리만을 분별하고 제시
- Retrieval Mothod
- 자동화된 검색 : 에이전트의 유연성과 동적 적응성을 유지하기 위해 기억이 자동으로 검색
- 평가 기준 : 최신성, 관련성, 중요성
- 각 기억에 대해 가중 점수를 계산하고 점수가 높은 기억이 우선적으로 사용됨
- Retrieval Extentsion
- LLM 기반 에이전트를 중앙 제어 인터페이스로 활용하여 사용자가 대화 기록을 보고 수정할 수 있음 → LLM 기반 에이전트의 메모리 시스템에 대한 직관적이고 유연한 제어를 목표
Memory Storage
- 메모리 저장의 목적은 상호작용 동안 에이전트가 인식한 정보와 학습한 경험을 기록하는 것
- 자연어 텍스트를 메모리에 작성하는 것, 메모리 내에서 적절한 저장 위치를 선택하고 정보 교체를 관리하는 작업 → 체계적인 저장 → 관련성 높은 데이터에 접근할 수 있도록 함
- Storage Format
- 일반적으로 자연어 (+) 시각 및 오디오 데이터와 같은 다중 모달 정보도 포함
- 저장 형식은 수행할 작업의 성격과 데이터의 속성에 따라 달라지는데, 각기 다른 모달리티와 작업 요구 사항에 맞춰 저장 형식을 조절함으로서 효과적으로 활용 가능
- 메모리 항목과 역사적 대화를 나타내기 위해 임베딩 벡터 채택 ex. 문장을 삼중 구성으로 번역, 메모리를 독립적인 데이터 객체로 인식
- Storage Method
- 메모리 수정 : 새로운 정보와 기존 메모리 간의 유사성을 고려해, 적절한 통합 방법을 결정.( 추가, 병합, 대체(
- 메모리 교환 : 메모리 저장이 일반적으로 제한적이므로 에이전트에 유익한 정보를 유지하기 위해 효과적인 정보 교환 전략을 설계
- 전략적 정보 교환 메커니즘 : RET-LLM은 고정 크기 메모리에서 가장 오래된 항목을 덮어쓰는 선입선출(FIFO) 전략을 사용하고 ChatDB는 관련 없는 정보를 삭제함
Memory Reflection
- 에이전트가 인식한 정보와 역사적 상호작용에서 학습한 경험을 바탕으로 자기 개선에 참여하는 과정이다. 기존 지식을 요약, 정제, 반영하는 인간의 관행을 모방하여, 에이전트가 새로운 환경과 작업에 적응할 수 있도록 개선하는 것을 목표로 함
- 반영 과정은 일반적으로 자동으로 발생하여 다중 에이전트 환경에서는 중앙 LLM 기반 에이전트가 개별 에이전트의 메모리 반영을 통제한다. 중앙 에이전트가 특정 제어 신호를 보내서 에이전트 네트워크 간의 일관성과 조정을 보장.
- survey
- Generative Agent : 메모리 반영 中 에이전트가 메모리에 저장된 과거 경험을 넓고 더 추상적인 통찰로 요약할 수 있음
- ExpeL 프레임워크 : 작업 실행 중에 에이전트가 올바른 경로의 경험으로부터 학습하고 잘못된 경로에서 교훈을 도출함.
- GITM : 새로운 작업을 할 때 하위 목표를 성공적으로 달성한 에이전트의 행동이 목록에 저장됨
Knowledge Utilization
지식 활용은 메모리 정보를 제외한 외부 지식을 LLM 기반 계획에 통합하는 데 초점을 맞췄다. RAG 및 실시간 웹 스크레핑 같은 기술은 이러한 모델이 내부 능력과 외부 정보를 결함해 계획 및 의사 결정 과정을 개선하는 데 도움을 준다.
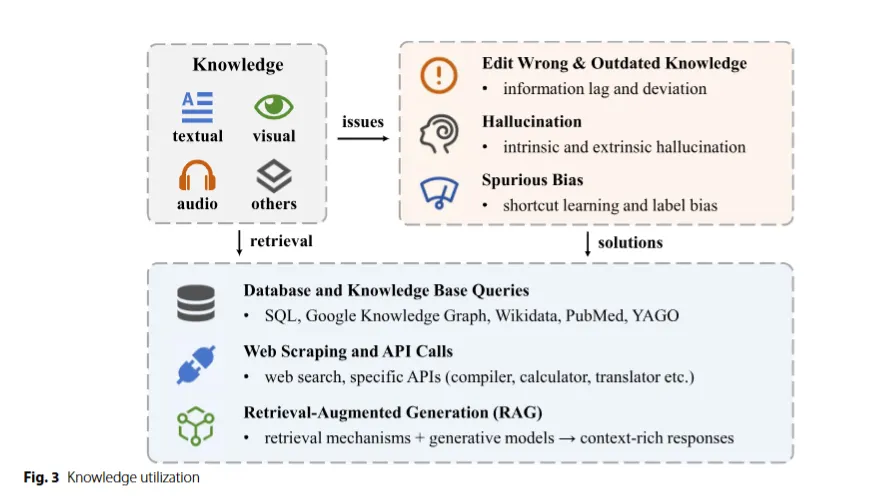
Fig3을 보자면 텍스트, 비주얼, 오디오, 기타의 지식을 활용할 때 잘못된 정보 수정, 환각 현상, 편향 등의 문제가 발생할 수 있고 이를 해겨랗기 위해 데이터베이스 및 지식 기반 쿼리를 이용하거나 웹 스크레핑 및 API 호출을 진행하거나 RAG를 이용할 수 있다.
LLM 기반 에이전트를 위한 지식(Knowledge for LLM-based Agents)
LLM 기반 에이전트가 텍스트, 시각, 오디오 및 기타 도메인 특화 지식을 활용하는 방법
-
텍스트 지식
- LLM의 근본으로 방대한 텍스트 자료로 훈련됨
- 자연어 이해, 텍스트 생성, 번역 등과 같은 작업이 중요함
- 사전 훈련된 LLM은 최소한의 추가 맥락으로 텍스트 생성, 요약, 번역, 계획 수립 작업 수행 가능
-
시각적 지식
- 다중 모달 데이터 이해 및 추론을 촉진하기 위해 텍스트 정보와 통합됨
- 시각적 지식 survey
- PaLM-E는 시각적 데이터와 상태 추정을 포함한 연속 입력을 LLM에 통합하여 구현된 추론 및 의사 결정을 가능하게 하며, 다중 모달 처리 프레임워크를 통해 작업 간 전이 학습 기능을 보여줌
- LLaVA : CLIP 시각 인코더를 언어 모델과 통합하고 시각적으로 지시하는 세부 조정을 적용해 복잡한 작업에서 시각적 및 텍스트 정보를 공동으로 추론 가능
-
오디오 지식
- 음성을 처리할 때 LLM 에이전트는 연결 모듈을 통해 음성 입력을 이산화하고 이를 텍스트와 공유된 벡터 공간에 임베딩
- 오디오 지식 survey
- SpeechGPT : HuBERT 인코더에 의해 생성된 음성 토큰은 LLaMA 어휘로 임베딩되어 LLM이 음성 입력을 처리할 수 있게 함
- AudioPaLM : 종단 간 오디오 LLM은 음성 및 기타 오디오 신호를 동시에 처리해 보다 넓은 청각 요구 사항을 충족함. (LLM + 기초 오디오 모델)
-
기타 지식
LLM은 종종 텍스트, 시각, 오디오를 넘어 특정한 도메인의 전문 지식을 활용할 필요가 있음
- 기타 지식 survey
- 의료 분야 LLM : PubMed와 같은 DB에서 의료 정보 검색 가능
- 기타 지식 survey
지식 검색(Knowledge Retrieval)
LLM이 정확하고 맥락에 맞는 관련 응답을 제공하기 위한 중요한 과정으로 이전 섹션에서 보관한 지식들을 사용하는 법을 설명한다.
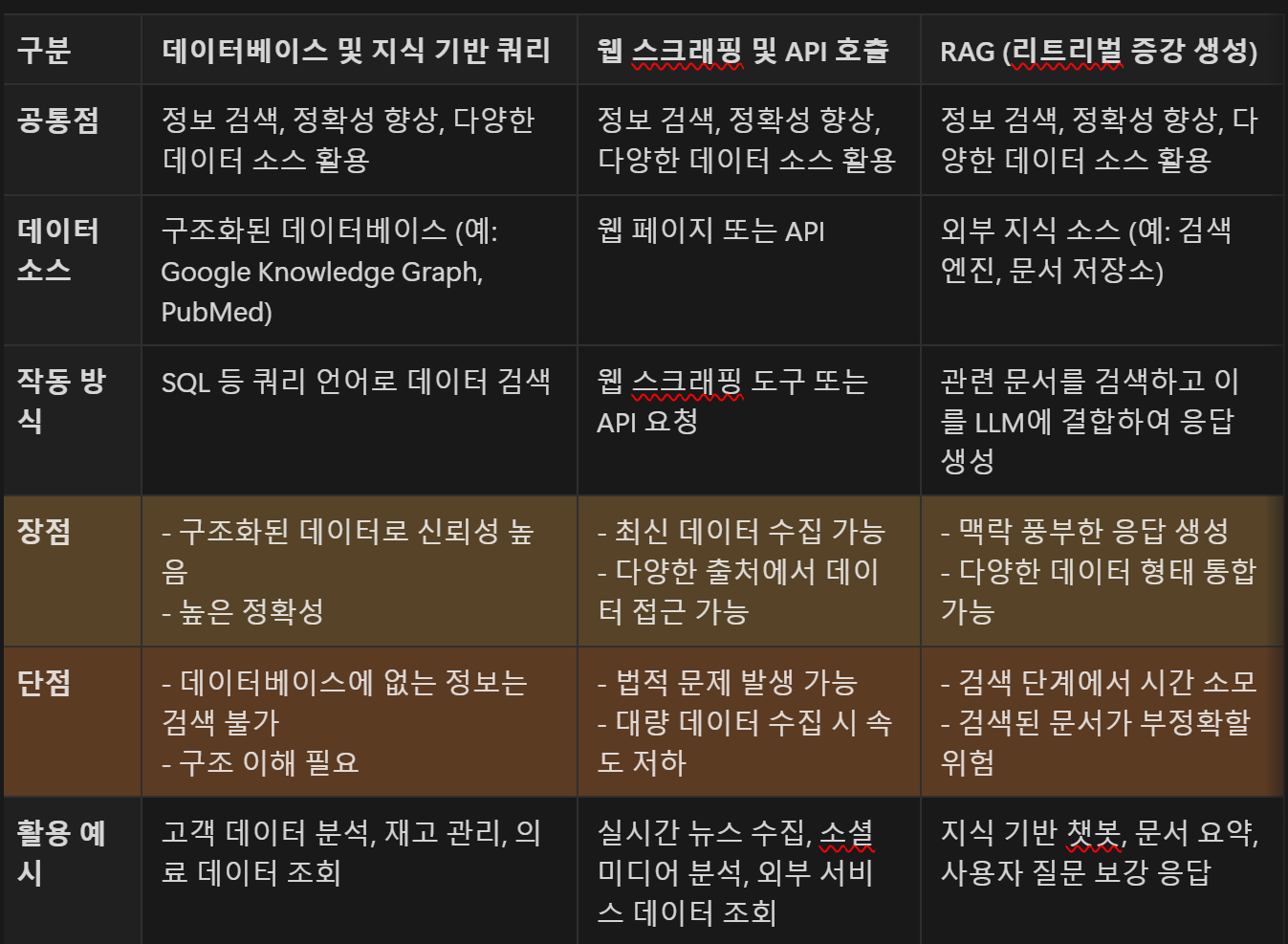
- 데이터베이스 및 지식 기반 쿼리
- DB와 같은 저장소에서 구조화된 데이터에 접근하는 것을 포함
- 데이터 베이스 및 지식 기반 쿼리 survey
- ChatDB 시스템 : SQL 쿼리를 사용해 관련 데이터를 논리적으로 가져옴
- SQL-PALM : LLM 기반으로 하는 Text-to-SQL 모델을 사용해 쿼리 정확도와 DB 상호작용을 크게 향상
- KnowledGPT : LLM이 ‘Program of Thoughts’ 프롬프트를 통해 외부 지식 저장소에서 지식을 접근, 검색할 수 있음
- 웹 스크래핑 및 API 호출
- LLM 기반 에이전트가 인터넷에서 실시간 정보를 수집할 수 있게 함.
- 뉴스 요약이나 시장 분석 같이 최신 데이터가 필요한 작업에 유용함
- 웹 스크래핑 및 API 호출 survey
- Talm : 명령 API 위한 데이터셋을 생성하고 LLM을 미세 조정해 도구와 검색기를 효과적으로 사용
- Gorila : API 호출 작성을 위한 GPT-4의 성능을 초월하는 미세 조정 LLM. API 호출에 대한 정밀한 입력 매개변수를 생성하고 환각 완화
- 검색 증강 생성(RAG)
- 검색 매커니즘과 생성 모델을 결합해 맥락이 풍부한 응답 생성
- 개방형 질문 응답 및 대화형 에이전트에 효과적임
- 반복 검색, 재귀 검색, 적응 검색이라는 세 가지 검색 개선 프로세스를 포함함
지식 검색의 세 방법 비교하기
추출 문제(Extraction Issues)
LLM의 개발 및 적용 과정에서 다양한 추출 문제에 직면하게 되며, 이는 모델의 정확성, 적용 가능성 및 편향에 직접적인 영향을 미친다.
잘못되거나 오래된 지식 수정- 에이전트의 지식 추출에서 주요 도전 과제 중 하나는 ‘정보의 적시성과 정확성’을 보장하는 것
- 직접적인 방법은 새로운 데이터 정기적 업데이트 →
But! 미세 조정의 비용 높음. 점진적 훈련은 모델이 사전 훈련 동안 학습한 광범위한 지식을 잃는 치명적인 망각으로 이어질 수 있음 → 기존 LLM에 새로운 지식을 통합해 최신 정보 유지하는 효율적인 방법이 필요
- 외부 지식 출처 활용 → But! 깊은 지식 업데이트 처리에 한계
- 연구와 개발이 필요!
환각 현상(Hallucination)- 훈련 데이터에서 모델의 과도한 일반화나 불완전하거나 오해를 일으킬 수 있는 정보의 잘못된 해석으로 인해 발생
- 내재적 환각 : 입력 논리를 모순하는 텍스트 생성
- 외재적 환각 : 기존 정보로 확인이 불가능한 텍스트 생성
- 환각 현상 해결 survey
- 외부 지식 기반과 사실 확인 시스템을 통합해 정확성 검증
- 모델의 투명성과 해석 가능성을 높여 출력을 신뢰할 수 있게 함 → 미세 조정 포함
- TruthfulAQ : 모델이 인간의 잘못된 진술을 모방하는지 여부 감지
- 디코딩 전략 : 텍스트 생성을 하는 동안, 언어 모델이 출력 토큰을 선택하는 방식을 최적화해 다양성과 사실 정확성의 균형 맞추기
잘못된 편향(Spurious Bias)- 단축 학습(shortcut larning) : 모델이 강건한 기능을 학습하기보다는 훈련 데이터 내의 우연적이고 비일반화한 가능한 단서에 의존해서 생기는 문제 ex. 훈련 샘플의 순서에 따라 선호도 개발, 답변 위치에 따라 판단 변화 → 데이터 평향 제거, 적대적 훈련, 해석적 정규화, 신뢰 정규화를 통해 완화
- 레이블 편향(Label bias) : 훈련 데이터 세트 내 클래스 불균형에서 발생 → 데이터 세트 재조정, 고급 샘플링 기법, 새로운 평가 메트릭 개발
- 단축 학습(shortcut larning) : 모델이 강건한 기능을 학습하기보다는 훈련 데이터 내의 우연적이고 비일반화한 가능한 단서에 의존해서 생기는 문제 ex. 훈련 샘플의 순서에 따라 선호도 개발, 답변 위치에 따라 판단 변화 → 데이터 평향 제거, 적대적 훈련, 해석적 정규화, 신뢰 정규화를 통해 완화
Agent’s ability utilization
에이전트는 인식된 정보를 분석하고 합성하며 창의적인 사고에 참여할 수 있다.
우리는 에이전트의 능력을 세 가지로 분류하는데 1) 추론은 과거 경험과 현재 지식을 기반으로 논리적 추론을 실시하고, 보편적인 패러다임을 추출한다. 2) 계획은 새로운 시나리오에 고차원 일반 규칙을 적용해 구체적이고 실행 가능한 계획을 수립하는 것이고 3) 일반화는 기존 경험을 적용해 새로운 상황과 문제를 해결하고자 하는 과정이다.
추론과 계획(Reasoning and Planning)- 역사적 경험, 공통 지식, 현재 상태 정보를 활용하여 논리적 분석을 수행하고, 이로부터 더욱 깊은 통찰을 도출하는 체계적인 과정 →
fundamental human capabilities! - 작업이 진행되며 에이전트는 자기 성찰을 진행하기도 함
- 연역적, 귀납적, 유추적 추론 포함
- 역사적 경험, 공통 지식, 현재 상태 정보를 활용하여 논리적 분석을 수행하고, 이로부터 더욱 깊은 통찰을 도출하는 체계적인 과정 →
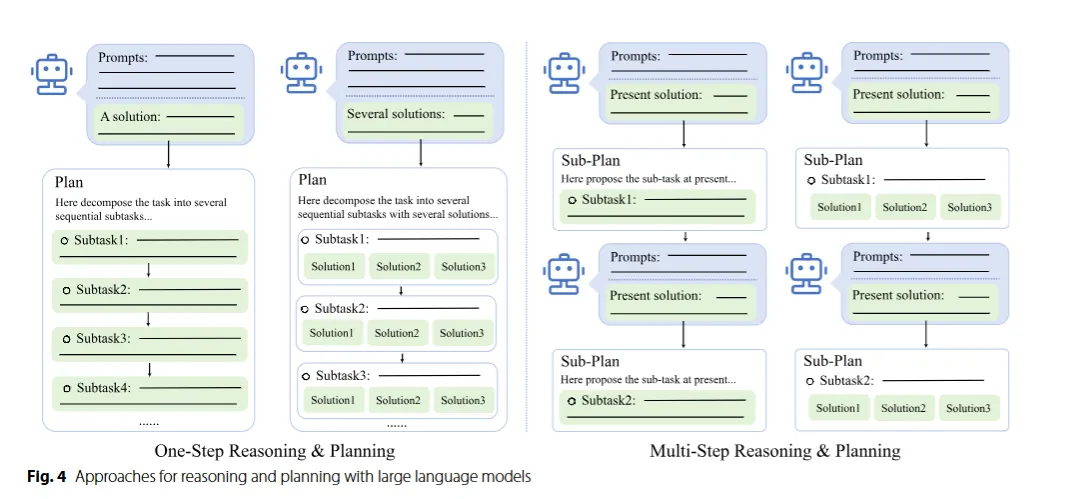
-
One-step Reasoning(Fig4 왼) : 단일 해결책을 제공하고 간단한 작업 처리. 즉각적인 해결책!
- Self-consistency CoT : CoT를 사용해 여러 추론 경로 생성
- Tree of Thought : 문제를 트리 구조로 분해
- Algorithm of Thought : 알고리즘 예제를 프롬프트에 통합해 LLM 추론 강화
- RecMind : 계획 과정에서 버려진 이력을 활용해 새로운 추론 단계 도출하는 자기 영감 메커니즘
- Graph of Thought : ToT의 트리 형태의 추론 구조를 그래프 구조로 확장
- RAP : 다양한 계획의 이점을 시뮬레이션하기 위해 세계 모델 구축하고 여러 반복을 집계하여 최종 계획을 생성
- Re-Prompting 접근법 : 각 단계가 계획을 진행하기 전에 필요한 전제 조건을 충족하는지 확인하고 못하면 전제 조건 오류 메시지가 생성돼 LLM이 계획을 수정
- ReWOO : 에이전트가 계획 및 외부 관찰을 독립적으로 생성하는 패러다임 도입 -
Multi-step Reasoning(오) : 여러 하위 작업을 제안, 여러 해결책을 탐색. 복잡한 문제! 여러 추론 사이클을 위해 LLM을 반복적으로 호출해야 하며, 각 사이클은 현재 맥락을 바탕으로 하나 또는 여러 점진적 단계를 생성하면서 전체 목표와 일관성을 유지해야 한다. 계획 과정을 명확한 단계로 분해해 성능을 향상시키는 것을 목표로 한다.
- SwiftSage : 행동 복제와 LLM의 장점을 결함한 프레임워크
- DECKARD(2023) : 꿈꾸는 단계에서 LLM을 활용해 작업을 하위 목표로 분해하고 깨어 있는 단계에서 각 하위 목표에 대한 모듈형 전략을 배우고, 에이전트 경험을 바탕으로 가정을 검증 또는 수정
일반화(Generalization)- LLM 에이전트의 일반화 능력은 역동적이고 예측 불가능한 환경에서의 효과성에 매우 중요함
- 강건성! ⇒ 다양한 입력 변형에 적응할 수 있는가?
- 현상 학습(In-Context Learning, ICL) : 현재 작업의 예를 입력 프롬프트 내에 제공하는 것으로, 모델이 이러한 예를 사용해 작업 요구 사항을 추론하고 적절한 응답을 생성할 수 있게 함 매개 변수 업데이트가 필요하지 않아 계산적으로 효율적이고 구현이 용이
- 제로샷 학습(Zero-shot Learning) : 모델이 특정 작업 예제나 미세 조정 없이 수행하며 전적으로 사전 학습된 지식에 의존함. 모델의 고유한 일반화 능력을 강조하고 추가 학습이 없어도 되지만 복잡하거나 전문화된 작업의 경우 제한될 수 있음
Action
에이전트의 유무형적 행동 결과를 나타내며 변화를 일으키고 상호작용에 영향을 미친다. 이는 프로필, 메모리 및 상호작용맥 락(에이전트 간, 에이전트와 환경 간, 에이전트와 인간 간의 상호작용 포함)의 조합에 의해 결정된다.
행동 생성(Action Creation)
말 그대로 행동이 생성되는 과정과 단께로 에이전트의 내부 상태와 외부 자극에 따라 특정 행동을 형성하는데 이르는 의사 결정 프레임워크, 알고리즘 및 절차가 포함됨
-
One-Step Decision
- 에이전트는 메모리에서 최근의 중요한 정보를 추출해 즉각적인 의사결정을 내림
- 필요한 경우 외부 지식 기반에 접근해 정보 보완
- 현재 작업 요구 사항과 메모리 회상 및 외부 지식의 조합으로 도출된 프롬프트에 따라 계획을 수립하고 행동을 실행
- One-step Decision survey
- 생성형 에이전트 : 지속적인 메모리 스트림을 유지하여 최근의 적절한 정보로 행동을 이끌어냄
- GITM : 에이전트가 메모리를 쿼리하여 성공적인 경험을 식별하고 과거 작업에서의 효과적인 행동을 복제
-
Pre-defined Decision
- LLM 기반 에이전트의 모든 행동은 엄격하게 사전 정의된 계획을 따르며 이 계획은 에이전트에 의해 자율적으로 생성되거나 사용자가 미리 정의할 수 있음
- Pre-defined Decision survey
- DEPS : 특정 작업에 대한 행동 계획을 시작하고 실행 도중 계획 실패의 징후가 나타나지 않는 한 계속 진행
-
Dynamic Creation
- 사전 정의된 계획의 안정성과 동적 환경에 대한 적응력을 결합
- 처음에 포괄적인 목표 계획으로 구성되고, 상호작용 동안 에이전트는 이 목표를 따르며 즉각적인 결정을 내릴 수 있는 유연성을 가짐
- Dynamic Creation survey
- GITM : 에이전트가 작업을 여러 하위 목표로 분해하여 고수준 계획을 만듦
행동 적용(Action Application)
행동의 맥락은 특정 적용 시나리오에 따라 동적으로 변화한다. 그리고 이들의 행동 결과는 현재 작업의 실현 및 다중 에이전트 시스템 전반의 진행에 직접적으로 영향을 미친다.
에이전트가 직면하는 다양한 상호작용 시나리오에 따라 세 가지로 분리할 수 있다.
- Task-Driven
- 특정 하위 작업을 수행하여, 이를 통해 더 큰 목표 작업을 완수하는 것을 목표
- Task-Driven survey
- DEPS : 복잡한 작업을 관리 가능한 하위 목표로 나누어 해결할 수 있는 마인크래프트 에이전트 개발
- GITM, Voyager
- TaskMarix.AI : 수백만 개의 API와 LLM을 통합해 작업 수행 지원
- Communication Interaction
- 에이전트 간의 상호작용은 특정 주제에 대한 논의와 아이디어 교환을 중심으로 함
- Communication Interaction survey
- ChatDev 의 에이전트들은 소프트웨어 개발 작업을 공동으로 수행하기 위해 상호작용
- Inner Monoloque : 에이전트가 인간과 대화하며 피드백에 따라 행동 전략 수정
- Environment Exploration
- 에이전트들이 협력하여 변화하는 환경에 적응하고 탐험하는 과정
- 이를 통해 에이전트는 의사 결정 과정을 강화하고 작업 수행의 효율성과 정확성을 향상
- Environment Exploration survey
- Voyager : 작업 완료 중 미지의 기술을 탐험하며, 환경 피드백을 통해 기술 실행을 지속적으로 개선
3.4 Mutual-Interaction
에이전트 간의 정보 교환과 행동 조정을 포함하며, 이는 다중 에이전트 시스템 내에서 집단 지능을 향상시키는 데 매우 중요하다.
세 가지 기본 구성 요소로 분해될 수 있다.
- 메시지 전달
- 상호작용 구조
- 상호작용 시나리오
상호작용 구조 vs 상호작용 장면
상호 구조는 에이전트 간의 정보 교환이 어떻게 이루어지는가를 나누어, 에이전트의 역할과 책임을 설명한 것이다.
상호작용 시나리오는 에이전트들이 어떤 상황에서, 어떤 행동을 통해 상호작용하고 협력하는지를 나눈 것이다. 그러니까 상호작용 구조가 실제로 어떻게 활용되는지를 보여주는 것.
Message Delivery
메시지 전달은 에이전트 간의 커뮤니케이션 및 협업을 가능하게 하는 필수 요소로, 에이전트 간의 정보 교환을 포함한다.
EXPLORING LARGE LANGUAGE MODEL BASED INTELLIGENT AGENTS: DEFINITIONS, METHODS, AND PROSPECTS
Interaction structure
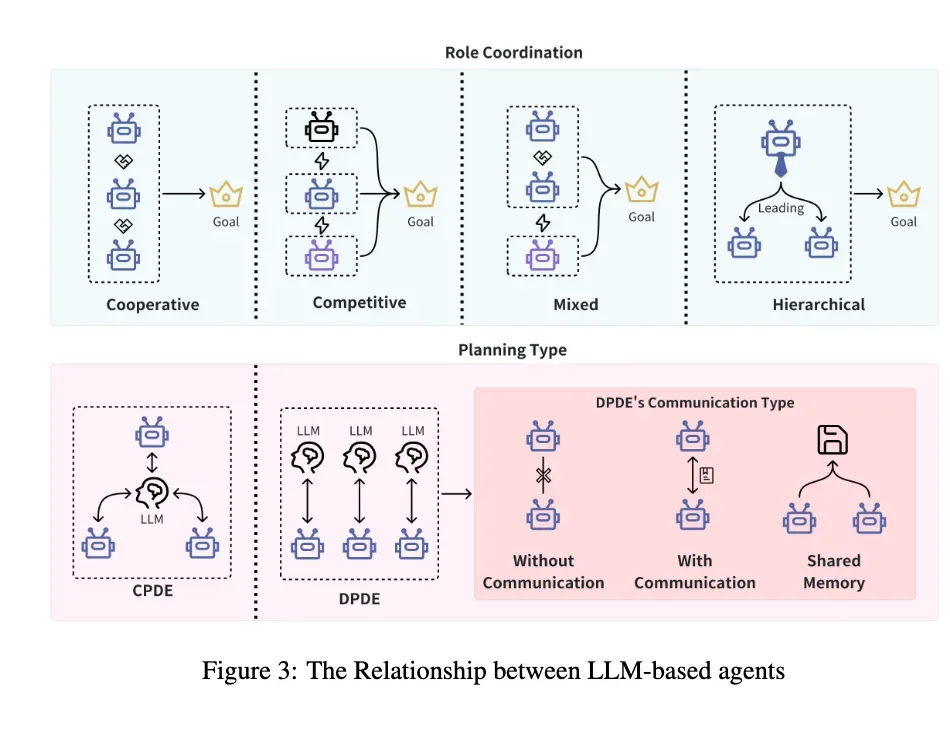
상호작용 구조는 일반적으로 메시지의 내용에 따라 조작되고 배열되어 에이전트에게 서로 다른 역할과 책임을 부여한다. 크게 계층적, 분산형, 중앙집중형, 공유 메모리로 분류할 수 있다.
계층적(Hierarchy)
- 서로 다른 수준의 에이전트는 다른 역할을 맡고 상위 에이전트와 하위 에이전트 간에 명확한 구분
- 상위 에이전트는 일반적으로 감독 역할을 수행하여 결정, 지시 등을 수행
- 전통적인 조직 구조를 모방해 권한 및 책임 경계를 명확히 하여 효율성을 높임
- ex. DyLAN : LLM 에이전트가 복잡한 작업을 위해 다중 턴 동적 상호작용을 할 수 있도록 하는 동적 계층 에이전트 아키텍처를 구성
분산형(Decentralized)
- 에이전트가 중앙 권한에 의존하지 않고 서로 직접 통신하는 peer-to-peer 네트워크 내에서 운영
- 에이전트 간의 평등을 촉진하여 보다 유연하고 동적인 상호작용을 가능하게 하며, 개별 LLMs에 대한 계산 부담을 줄여 시스템의 견고성을 향상
But! 대규모 시스템에 적용될 경우 조정 및 통신 오버헤드가 상당
중앙집중형(Centralized)
- 중앙 에이전트(혹은 그룹)이 시스템을 조정하고 모든 에이전트 간의 상호작용을 관리
- 제어 및 조정을 중앙화하여 의사 결정 과정을 단순화하고 잠재적인 충돌을 피하며 전체 시스템 효율성을 향상
But! 시스템이 중앙 에이전트에 의존하기 때문에 단일 실패 지점 및 통신 지연에 취약하여 환경 변화에 신속하게 대응하기 어려움- ex. ACORM : 단일 LLM 중심 계획자로 사용해 중앙 집중식 아키텍쳐 도입
공유 메모리(Shared Message Pool)
- LLM 에이전트 간의 정보 교환 메커니즘으로, 에이전트가 공유 메시지 풀을 통해 정보를 게시하고 구독하는 방식
- 단순화된 통신 프로세스, 정보 전송의 복잡성 감소, 통합 메시지 관리 접근 방식
But! 여러 에이전트가 공유 메시지 풀에 동시 접근할 경우 경합 및 동기화 문제가 발생- ex. MetaGPT : 각 에이전트가 필요한 정보를 동적으로 관찰하고 추출할 수 있도록 공유 메시지 풀을 유지
Interaction scene
LLM 기반 MAS의 상호작용 시나리오의 ‘주요 범주’는 커뮤니케이션, 작업 실행 및 환경 탐색이다.
- 커뮤니케이션 시나리오 : 가장 기본적인 상호작용으로 에이전트는 정보를 교환하여 조정하고 결정을 내림
- 작업 실행 시나리오 : 에이전트가 미리 정의된 작업 할당에 따라 특정 작업을 수행하는 방식에 중점을 두며, 역할 놀이 게임, 분산 작업 할당 등이 포함
- 환경 탐색 : 에이전트가 인식 및 학습 메커니즘을 이용하여 알려지지 않은 환경에서 지속적으로 적응하고 행동을 최적화해야 하는 상황
그럼 MAS의 상호작용은 어떤 형태로 나타날 수 있을까?
협동적(Cooperative)
- 공동의 목표를 달성하기 위해 협력
- 기본 프로세스 : 목표 설정, 작업 분해, 정보 공유, 협업 의사 결정 및 실행 피드백
- 에이전트는 의사소통과 협상을 통해 정보를 공유하고 합의에 도달하기 위해 공동으로 결정
- 비순서 협력 : 고정된 역할 없이 자연스럽게 협력하고 피드백 제공(ex. ChatLLM)
- 순서 협력 : 에이전트가 할당된 역할과 전문성을 기반으로 특정 작업을 수행(ex.METAGPT)
적대적(Adversarial) 상호작용
- 에이전트들이 경쟁 관계에 있으며, 각 에이전트는 자신의 이익 극대화를 추구
- 기본 프로세스 : 목표 설정, 전략 수립, 상호작용 게임 및 결과 평가
- 에이전트는 최대 이익을 추구하기 위해 상호작용을 통해 전략을 실행 → 이후 게임 결과를 평가하고 미래의 경쟁에 대비해 전략 조정
- ex. ChatEval : 인간 평가자의 집단 지혜와 인지적 협업을 시뮬레이션 MAD : 다중 에이전트 토론을 통해 LLM의 자기 반성에서 발생하는 “사고 붕괴” 문제를 해결함
혼합(Mixed)
- 협력적 상호작용과 적대적 상호작용의 특징을 결합하여 에이전트가 협력과 경쟁 간의 균형을 찾음
- 병렬(Parrallel)
- 에이전트가 서로 간섭하지 않고 독립적으로 별도의 작업에 협력하며 일부 정보를 공유
- 위계(Hierarchical)
- 자식 노드 에이전트는 특정 작업을 실행하고 실행에 대한 피드백을 제공
- 부모 노드 에이전트는 피드백을 바탕으로 글로벌 전략을 조정하여 전체 작업 실행을 최적화
3.5 Evolution
인간이 환경 및 타인과의 상호작용을 통해 인지 능력을 지속적으로 개선하고 지식을 습득하는 것처럼, 에이전트의 진화는 자신의 결정 및 행동에 대한 지속적인 반성을 포함하여 동적으로 자신의 지식과 경험을 업데이트하는 것
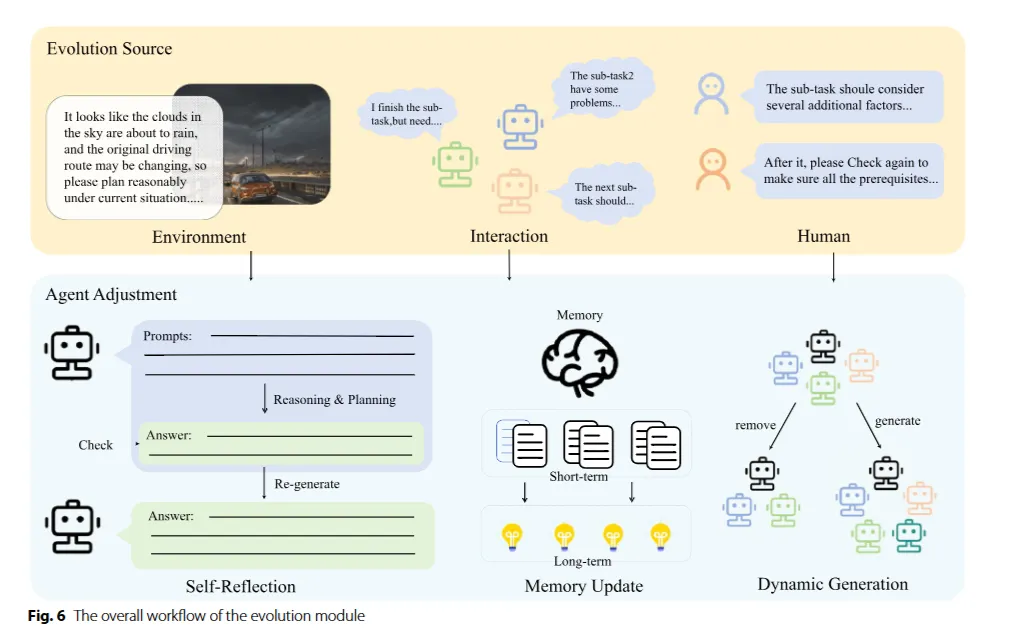
주변 환경에서 인식된 정보, 다른 에이전트와 교환된 정보, 또는 인간에 의해 전달된 정보에서 기인한 외부 피드백을 통해 이루어진다.
Evolution source
Environment Feedback
- 일반적으로 에이전트가 외부 환경과 상호작용하는 동안 내리는 결정과 행동의 결과로 인해 환경에서 변화하는 정보
- 따라서 보상 신호 역할을 하여 행동의 결과를 알린다.
Agents Interaction
- 특정 에이전트의 결정이나 행동에 대한 다른 에이전트로부터의 평가 또는 상태 업데이트와 에이전트 간의 맥락적 통신
- 작업의 계츠아적 실행과 에이전트 커뮤니케이션에서 뚜렷하게 나타냄
- 이를 통해 협력 능력을 향상시키고 복잡하고 동적인 시나리오에서 전체 시스템 성능 개선
Human Feedback
- 에이전트가 더 나은 결정과 행동을 하도록 유도하는 신호로, 에이전트의 인지 능력을 향상
- 인간의 가치와 선호에 맞게 조정되며, 환각과 같은 문제를 완화
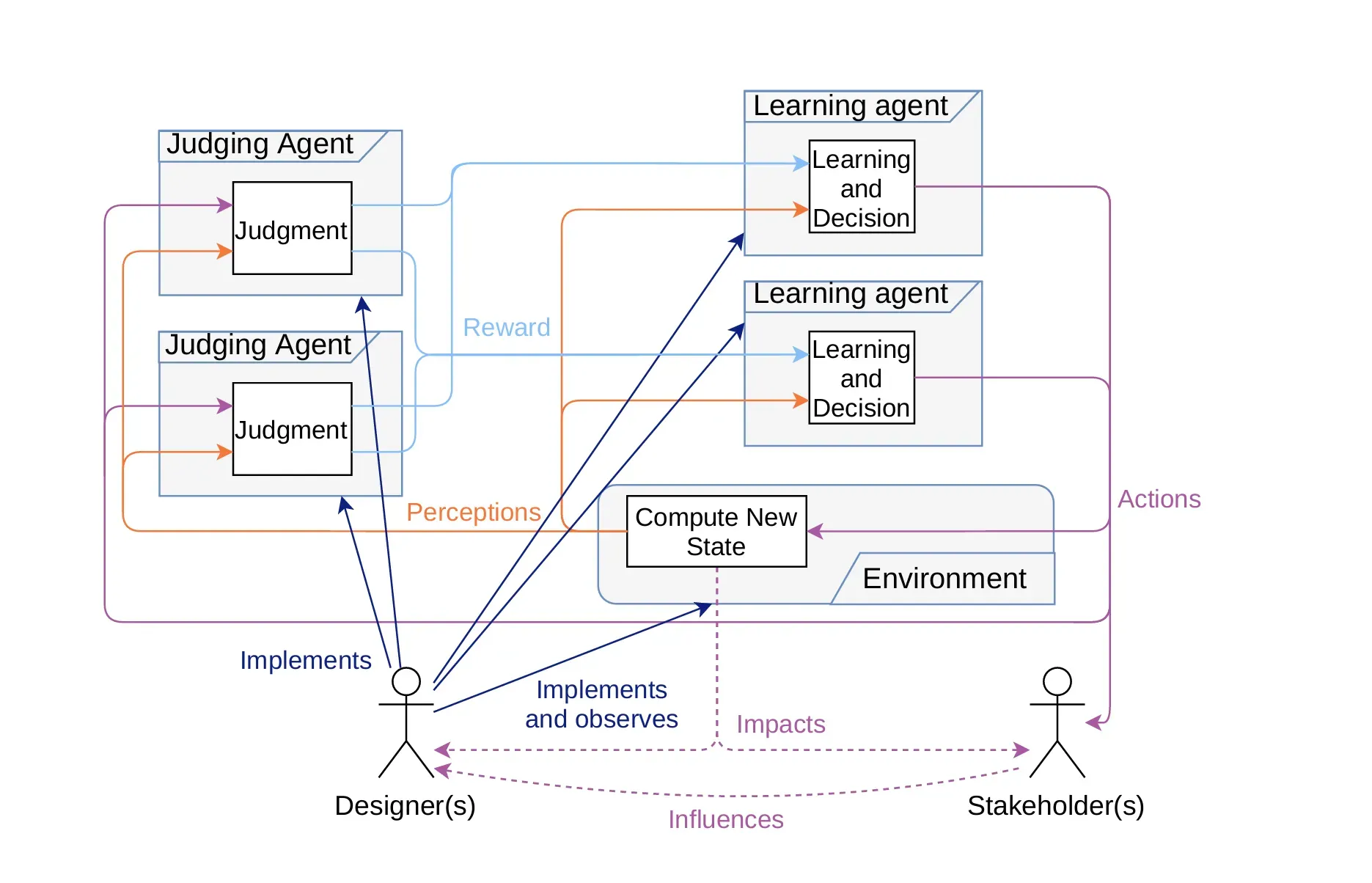
Evolution methods
지능형 시스템을 개발하는데 필수적이며 시스템이 자율적으로 전략과 행동을 정제해 더 나은 성능을 달성할 수 있도록 한다. 진화 방법은 다음과 같다.
Fine-Tuning
- 전 모델 미세 조정
- 재이용
- 추가 매개변수 미세 조정
- 어댑터, 저차원 적응(LoRA), 프리픽스 튜닝, 프롬프트 튜닝
Feedback Learning
- 피드백 정보를 맥락으로 활용하여 에이전트가 가중치 업데이트 없이 반복적으로 정책 생성을 강화할 수 있도록 하는 접근 방식
- ex. Instruct-GPT(2022) : 모델의 출력에 대한 인간 주석자의 평가를 수집하여 학습
Prompt Engineering
- 잘 설계된 프롬프트와 피드백을 맥락적 신호로 활용
- ex. Retroformer : 에이전트가 과거 실패를 반영하고, 이러한 반성을 프롬프트에 통합하여 향후 행동을 안내 ex. AutoPrompt : 프롬프트의 생성 및 최적화를 자동화함으로써 특정 작업에서 언어 모델의 성능을 상당히 향상 ex. 프리픽스 튜닝(2021) : 모델 가중치를 변경하지 않고 프롬프트를 최적화함으로써 모델의 성능을 상당히 향상
Reinforcement Learning
- 에이전트가 환경과의 상호작용을 통해 최적의 전략을 학습
- 각 행동은 해당하는 피드백(보상 또는 처벌 등)을 생성하고, 에이전트는 이 피드백을 바탕으로 지속적으로 전략을 조정하여 누적 보상을 극대화
- 핵심은 시행착오와 최적화!
- ex. ICPI(2022) : 전문가 시연이나 그래디언트 업데이트 없이 정책 반복을 수행하기 위해 대규모 언어 모델을 사용하여 맥락에서 학습하고 시행착오 상호작용을 통해 전략을 개선 ex. GLAM(2023) : 온라인 강화 학습을 사용
Agents Adjustment
- 진화 메커니즘의 핵심 측면은 에이전트의 기존 지식과 경험을 지속적으로 업데이트하고, 결정과 행동을 정제하는 것
Memory Update
새로 습득한 지식과 경험은 메모리 또는 외부 DB에 저장!
Self-Reflection
지속적인 상호작용을 통해 에이전트는 지식 기반을 평가하고 향상!
Dynamic Generation
환경의 복잡성을 감안할 때, 시스템은 작업 특화 에이전트를 생성하거나 제거하여 즉각적으로 규모를 조정할 수 있음.
→ 자유롭게 조정하고 생성한다!
4 Application
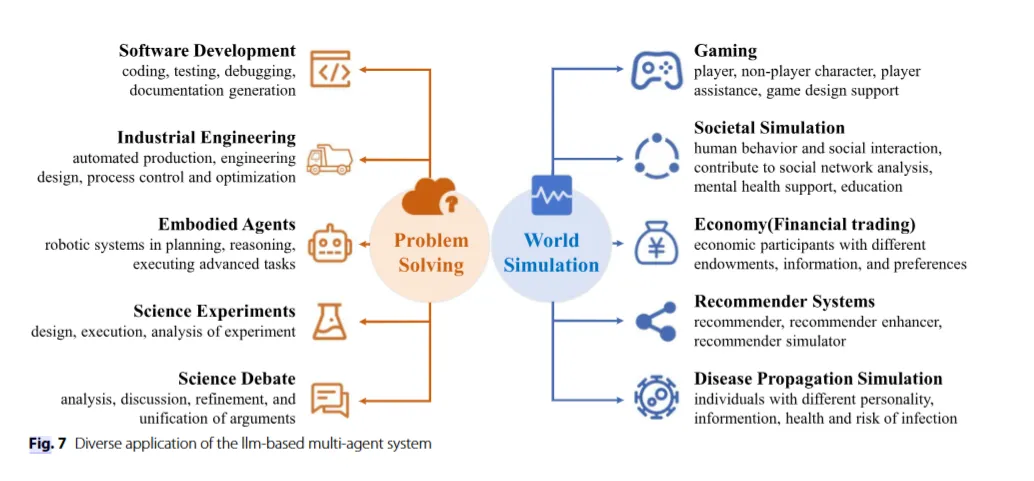
4.1 Problem Solving
다양한 도메인에서 자연어 이해 및 기타 응용의 고급 기능을 활용하여 문제 해결을 혁신하고 있음
→ 해당 부분은 소프트웨어, 산업공학, 구체화된 에이전트, 과학 실험, 과학 토론 에 다양한 방식으로 영향을 미침
- 소프트웨어 개발 : 코딩, 테스트, 디버깅 및 문서 생성의 자동화
- 산업공학 : 자동화된 생산, 공학 설계, 프로세스 제어 및 최적화와 같은 다양한 영역
- 구체화된 에이전트 : LLM 생성의 고수준 계획을 활용해 환경 상태 및 가치 함수와 결합해 로봇을 위한 실행 가능 계획을 생성하는 등 로봇 시스템의 지능적이고 개인화된 미래에 대한 새로운 가능성을 제시함
- 과학 실험 : LLM의 과학 분야 통합은 화학 실험을 자율적으로 수행할 수 있는 지능형 에이전트의 생성에 기여함
4.2 World Simulation
LLM 에이전트는 일관되고 의미론적으로 풍부한 텍스트를 이해하고 생성할 수 있어 인간 행동과 상호작용을 시뮬레이션할 수 있음 → AI가 인간을 모방할 수 있을까? (trust를 중심으로)
→ 게임, 사회적 시뮬레이션, 경제(금융 거래), 추천 시스템, 질병 전파 시뮬레이션 등에 사용할 수 있음
- 관련 연구
- S3: Social-network Simulation System with Large Language Model-Empowered Agents(2023) : 감정, 태도 및 상호작용 행동에 대한 정보를 포함하는 프롬프트 엔지니어링 및 파인튜닝 기술을 사용하여 LLM 기반의 다중 에이전트 시스템을 생성하여 개별 및 그룹 수준의 시뮬레이션을 지원
- Large Language Model based Multi-Agents: A Survey of Progress and Challenges(2024) : 인기 있는 LLM 기반 대화형 에이전트인 Replika에 기반하여 2917개의 사용자 코멘트에 대한 질적 분석을 수행하여 이들이 주문형 비판단적 지원을 촉진하고 사용자 신뢰를 향상시키며 자기 발견을 도움
- GPT in Game Theory Experiments(2023) : 죄수의 딜레마에서 GPT의 전략적 의사 결정을 조사하여 GPT가 인간과 유사한 반응을 보이며 공정성 우려나 이기심과 같은 특성에 의해 영향을 받을 수 있음을 입증
- Epidemic Modeling with Generative Agents(2023) : ChatGPT를 사용해 자가 격리와 같은 행동을 모방하는 생성 에이전트를 개발하여 전염병 곡선을 더 현실적으로 평탄화하는 데 기여
- Generative Agent-Based Modeling: Unveiling Social System Dynamics through Coupling Mechanistic Models with Generative Artificial Intelligence(2023) : 사회적 사건에 대한 반응으로 태도와 감정이 변하는 인간과 유사한 행동을 보이는 LLM 기반 에이전트가 있는 시뮬레이션 환경을 생성
5 Discussion
5.1 Open Problem
LLM의 본질적인 제약
- 블랙 박스 효과 및 의사결정 정확성 평가
- 의사결정 과정이 불투명하기 때문에 고위험 응용프로그램에서 그들의 결정의 정확성과 신뢰성을 평가하는 데 중요한 도전과제임.
- 모델 결정 설명 방법(2023, link2), 추론 과정 생성을 안내하는 방법, 모델의 내재적 추론 능력을 드러내는 방법(2023) 등을 사용함
- 할루시네이션, 환각 현상
- 외부 지식 기반을 통합해 정확성 높이기, 모델 투명성을 높여 의사 결정 과정 이해하도록 촉진하기, 출력을 검증하기 위한 사실 확인 시스템 개발하기(2025), 모델 성능을 평가하고 개선하기 위해 환각 탐지 작업을 설계하기
- 편향(편향 관련 survey 논문)
- 훈련 데이터셋 재조정, 편향 완화 알고리즘 적용, 모델 출력 정기적으로 감사하기
악용
- 대규모 허위 정보 생성(2023, 2023)사이버 공격, 다른 부적절한 행동 등에 의해 악의적으로 이용될 수 있음
- Academic integrity and artificial intelligence : is GhatGPT hype, hero or heresy?(2023)
- 지침 처리 및 악성 탐지, 적대적 훈련과 프롬프팅을 통해 에이전트의 견고성을 높여 악의적 입력에 견딜 수 있도록 함(2023)
- AI 윤리 및 정책 수립은 에이전트 시스템의 개발 및 배치를 안내하여 윤리적이고 법적 틀 내에서 운영되도록 하여 오용의 위험을 줄임.
- From ethical AI frameworks to tools : a review of approaches(2023)
- #ethic tool!
- From ethical AI frameworks to tools : a review of approaches(2023)
Scaling up the multi-agent System
- 시스템 성능과 현실성을 향상하기 위해 다중 에이전트 시스템의 확장이 필요하지만 계산 자원, 통신 효율성 및 시스템 조정과 관련된 도전 과제를 수반한다.
- 이를 해결하기 위해 정적 조정 및 동적 스케일링 방법, 통신 및 조정 메커니즘 최적화, 시스템 아키텍처 및 설계의 혁신 등이 방법으로 제시되고 있음
5.2 Future Direction
AI 에이전트에서의 집단 지능
- 집단 지능은 다양한 관점을 통합하고 협업과 경쟁을 통해 의사 결정을 이루어 내부 능력을 초과하는 집단의 지혜를 형성
- 효과적인 조정 메커니즘이 필요하며, 이를 통해 집단사고와 인지 편향을 피하면서 협력이 촉진
- 분산 학습 알고리즘의 도입은 에이전트가 독립적으로 학습하고 팀과 통찰을 공유할 수 있도록 지원하여 집단 지능을 발전시킬 수 있음
서비스로서의 LLM 기반 에이전트 시스템
- LLM 다중 에이전트 시스템을 클라우드 플랫폼을 통해 서비스로 제공함으로써 기술 장벽을 낮추고 서비스의 신뢰성과 효율성을 향상
- 사용자들은 복잡한 인프라를 구축할 필요 없이 고급 에이전트 서비스를 사용
But! 에이전트의 의사 결정 과정은 투명하고 해석 가능해야 하며, 시스템의 안정성과 응답 속도를 보장하는 것이 중요
응용 프로그램의 확대
- LLM 기반 다중 에이전트 시스템(MAS)은 의료, 교통 관리 및 환경 모니터링과 같은 다양한 분야에서 혁신을 가져올 것
- 이 시스템은 복잡한 데이터 스트림을 보다 정확하게 이해하고 변화하는 환경에 신속하게 대응할 수 있도록 향상될 것입니다.
But! 데이터 융합, 실시간 처리 및 의사 결정과 관련된 도전과제가 여전히 남아 있으며, 이들을 해결하기 위한 연구와 혁신이 필요합니다.
6 Conclusion
본 논문에서는 LLM 기반 다중 에이전트 시스템에 대한 종합적인 개요를 제공하고, 이 분야의 현재 연구를 포괄적으로 검토했다.
현재 연구가 이상적이고 신뢰할 수 있으며 자율적인 시스템 응용에 도달하는 데 다소 거리가 있음에도 불구하고, 연구자들은 LLM 기반 에이전트가 중요한 전진을 나타낸다고 믿는다고 함~~
🔆 survey 논문이라 그런지 굉장히 길었고 방대한 양을 다루는 듯 했다.
LLM based Multi-agent의 전반적인 개요를 알았으나, 내가 바라는 연구 주제가 무엇인지 명확히는 모르겠다. 강화학습 기반 multi-agent를 통해 ethical한 ai를 만들어내는 논문을 읽고 해당 survey를 읽어봤는데… 그렇다면 나는 이 기본적인 구조를 이용해 어떤 ehical 한 ai를 만들어낼 수 있을까?
개인적으로 마지막 application 부분에 ‘From ethical AI frameworks to tools : a review of approaches(2023)’을 읽어보면 어떨까 싶다. 나는 결국 ethical한 AI를 만들기 위해서 무엇이 필요한지를 알고 싶은 거니까.
