🔆 본 논문은 AI 모델에서 윤리적 행동을 가능하게 하기 위한 필요성을 설명하며, 현재 윤리적 원칙을 정의하거나 학습하는 방법론이 각각 제한점을 가지고 있다는 것을 지적한다.
이에 상징적 판단 에이전트와 학습 에이전트를 결합한 새로운 하이브리드 접근 방식을 제안하며, 이를 통해 AI 에이전트가 다중 에이전트 환경에서 윤리적 행동을 학습하고 적용할 수 있게 한다.
1. Introduction(소개)
Moor는 “로봇이 점점 자율성을 가지게 되면서 우리는 이들에게 더 많은 윤리적 능력을 부여해야 한다”라고 말한다.
더욱이 윤리적 임팩트 에이전트 개념을 도입하여, 인간 사회에 통합될 때 AI 에이전트가 미칠 윤리적 영향을 고려하는 중요성을 언급한다.
🔆
윤리적 임팩트 에이전트란?
그 행동이 인간이 삶에 영향을 미칠 때 윤리적 관점에서 평가될 수 있는 AI 시스템을 의미한다. 이러한 에이전트는 특정 윤리적 규칙을 준수하여 행동하거나 인간의 가치를 기반으로 행동을 선택할 수 있다.
ex. 환자의 안전과 자율성을 존중하며 치료 결정을 내리는 의료 로봇, 사고를 피하기 위한 선택을 내릴 때 윤리적 기준을 고려하는 자율 주행 자동차.
그러나 기존 접근법에는 한계가 있다.
Top-down 방식의 경우 전문가의 지식을 바탕으로 윤리 규칙을 명시적으로 정의하지만 새로운 상황에 적용하는 능력이 제한적이며 Bottom-Up의 방식은 데이터를 통해 윤리적 행동을 학습하지만 결과물의 해석 가능성이 낮다는 단점이 있다.
이러한 연구의 문제를 극복하기 위해 상징적 판단 에이전트와 학습 에이전트를 결합한 하이브리드 접근법을 제안한다. 해당 접근법은 규칙 기반의 상징적 에이전트를 이용해 학습 에이전트의 행동을 평가하고, 학습 에이전트가 동적으로 윤리적인 행동을 학습하도록 돕는다.
2. 배경지식
윤리와 AI(Ethics and AI)
기계 윤리는 ‘기계가 인간 사용자 및 다른 기계와 상호작용하는 방식’에 중점을 두며, 윤리적 원칙에 의해 가이드되는 기계를 만드는 것을 목표로 한다.
기존에는 소개에서 말했듯 세 가지 정도의 접근법이 있는데, 윤리 규칙을 먼저 정의하고 이에 맞춰 윤리적 행동을 보장하는 Top-down방식, 데이터를 통해 윤리적 행동을 학습하는 Bottom-up 방식, 마지막으로 이 두 방식을 결합한 Hybrid 방식이다.
Multi-Agent Hybrid Neuro-Symbolic AI for Ethics
- 하이브리드 접근법 : 상징적 추론과 학습 기반 접근법의 장점을 결함
- 판단 에이전트와 학습 에이전트를 분리하여, 독립적으로 발전하면서 서로의 장점을 극대화할 수 있도록 설계한다.
심볼릭 판단
심볼릭 판단은 상징적인 평가(ex.도덕적, 비도덕적, 중립적)를 학습 에이전트가 사용할 수 있는 숫자 보상 값으로 변환하여 판단을 내리는 방식이다. 주로 윤리적 행동이나 의사결정 과정에서 사용된다.
3. 제안모델
3.1 추상적 구조(Abstract Architecture)
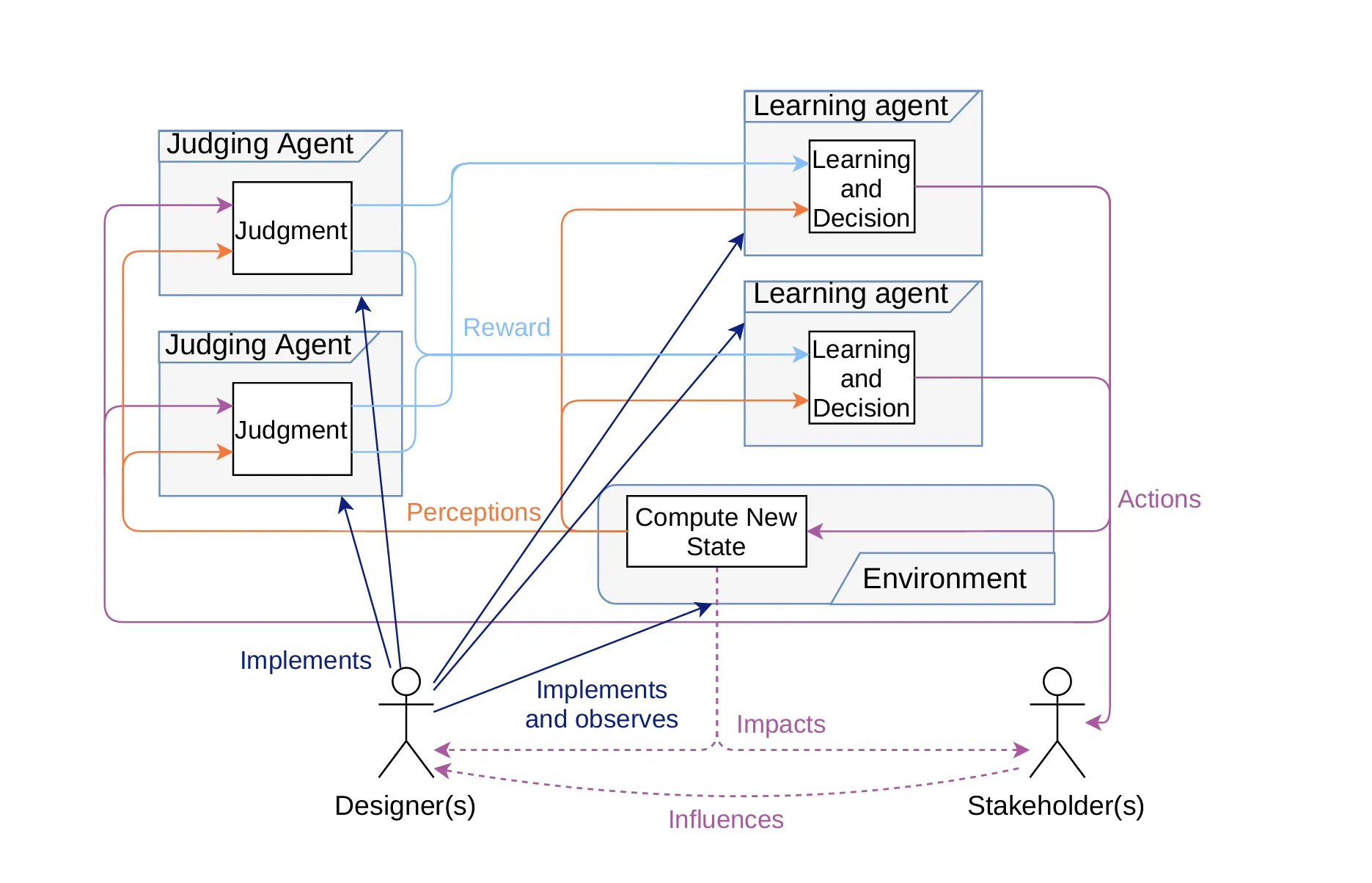
Figure1 : Abstract architecture of our approach, with human designers implementing rules to judge learners. Learner’s actions modify a shared environment, which impacts humans
해당 구조는 크게 5가지로 나눌 수 있다.
- 판단 에이전트(Judge Agent)
- 학습 에이전트(Learning Agent)
- 환경(Environment)
- 디자이너(Designer)
- 이해 관계자(Stakeholder)
학습 에이전트는 환경에서 행동(Actions)을 수행하며 환경 상태를 변화시킨다. 이 변화된 상태는 판단 에이전트와 이해 관계자에게 영향을 미친다.
판단 에이전트는 학습 에이전트의 행동(Actions)과 환경 상태를 인지(Perceptions)하여 윤리적 판단(Judgement)을 수행하는데, 이 결과는 숫자 보상(Reward)값으로 변환되어 학습 에이전트에 전달된다.
디자이너는 판단 에이전트의 윤리적 규칙을 설계(Implement)하고, 학습 에이전트의 행동 결과를 모니터링(Implements and observes)한다. 만약 필요하다면 윤리적 규칙을 수정하여 시스템의 윤리적 기준을 업데이트한다.
학습 에이전트가 환경에서 수행한 행동은 이해관계자에게 영향을 미치며(ex. 에너지 소비, 자원 분배 등) 이해관계자는 간접적으로 학습 에이전트의 행동과 시스템의 윤리적 기준의 영향을 받는다.
🔆 구조의 특징
1. 학습 에이전트와 판단 에이전트가 분리되어 독립적 설계가 가능하다는 것
2. 디자이너가 시스템의 윤리적 기준을 제어하고 이해관계자의 영향을 고려하는 등 사람 중심 설계가 가능하다는 것
3. 여러 판단 에이전트를 통해 다양한 윤리적 관점에서 학습 에이전트의 행동을 평가한다는 것
3.2 수학적 모델(Formal Model)
마르코프 게임으로 모델링
확장된 마르코프 의사결정 과정(MDP)를 사용함
확장된?
학습 에이전트는 환경 상태와 자신의 행동이 판단 에이전트에 의해 평가된 피드백(=보상)을 바탕으로 최적의 행동을 학습한다.
- 상태 집합(𝑆): 에이전트가 경험할 수 있는 모든 가능한 상태를 정의.
- 행동 집합(𝐴): 에이전트가 수행할 수 있는 모든 가능한 행동.
- 에이전트 집합(P)(MDP에서 이 부분이 추가됨) : 실제로 환경에 영향을 미치는 에이전트의 집합으로, 에이전트는 자신의 행동집합(A) 중에서 행동을 선택하고 이를 통해 환경에 영향을 미친다.
- 학습 에이전트의 집합에 해당하는 것!
- 다중 에이전트 환경에서는 각 에이전트가 환경에 독립적으로 또는 협력적으로 영향을 미칠 수 있음
- 전이확률함수()
-
MDP에서는 MRP와는 달리 에이전트(a)가 선택한 액션에 따라서 다음 상태가 달라지므로 현재 상태가 이며 에이전트가 액션 를 선택했을 때 다음 상태가 가 될 확률을 정의해야 한다.
-
주의해야 할 점은, 상태 S에서 액션 a를 선택했을 때 도달하게 되는 상태는 반드시 같지 않다는(결정론적이지 않다는) 점이다. 매번 다른 상태에 도착할 수 있으므로, 액션 실행 후 도달하는 상태 에 대한 확률 분포가 있고 그게 바로 전이확률행렬 P이다.
-
- 보상함수() : 어떤 액션을 선택하느냐에 따라 받는 보상이 달라진다.
-
확률적으로 매번 바뀔 수 있으므로 기댓값을 이용해 표기한다.
-
- 감쇠 인자
- 는 0에서 1 사이의 숫자로 강화 학습에서 미래에 얻을 보상에 비해 당장 얻는 보상을 ‘얼마나 더 중요하게’ 여길 것인지를 나타내는 파라미터
- = 0 : 즉각적인 보상만을 고려
- = 1 : 미래 보상을 현재와 동일하게 중요시 여김
- 미래에 얻을 보상의 값에 가 여러 번 곱해지며, 그 값을 작게 만드는 역할을 함
- 강화 학습은 엄밀히 말해 보상이 아니라 리턴을 최대화 하도록 학습하는 것이다!
- 리턴 : 시점 t부터 미래에 받을 감쇠될 보상의 합
- 사람은 기본적으로 눈앞의 보상을 더 선호하기에 에이전트를 학습하는데 있어 감마의 개념을 도입한다. 더욱이 미래의 가치에는 ‘불확실성’이 있기 때문에 이를 반영하고자 감쇠를 해준다.
- 는 0에서 1 사이의 숫자로 강화 학습에서 미래에 얻을 보상에 비해 당장 얻는 보상을 ‘얼마나 더 중요하게’ 여길 것인지를 나타내는 파라미터
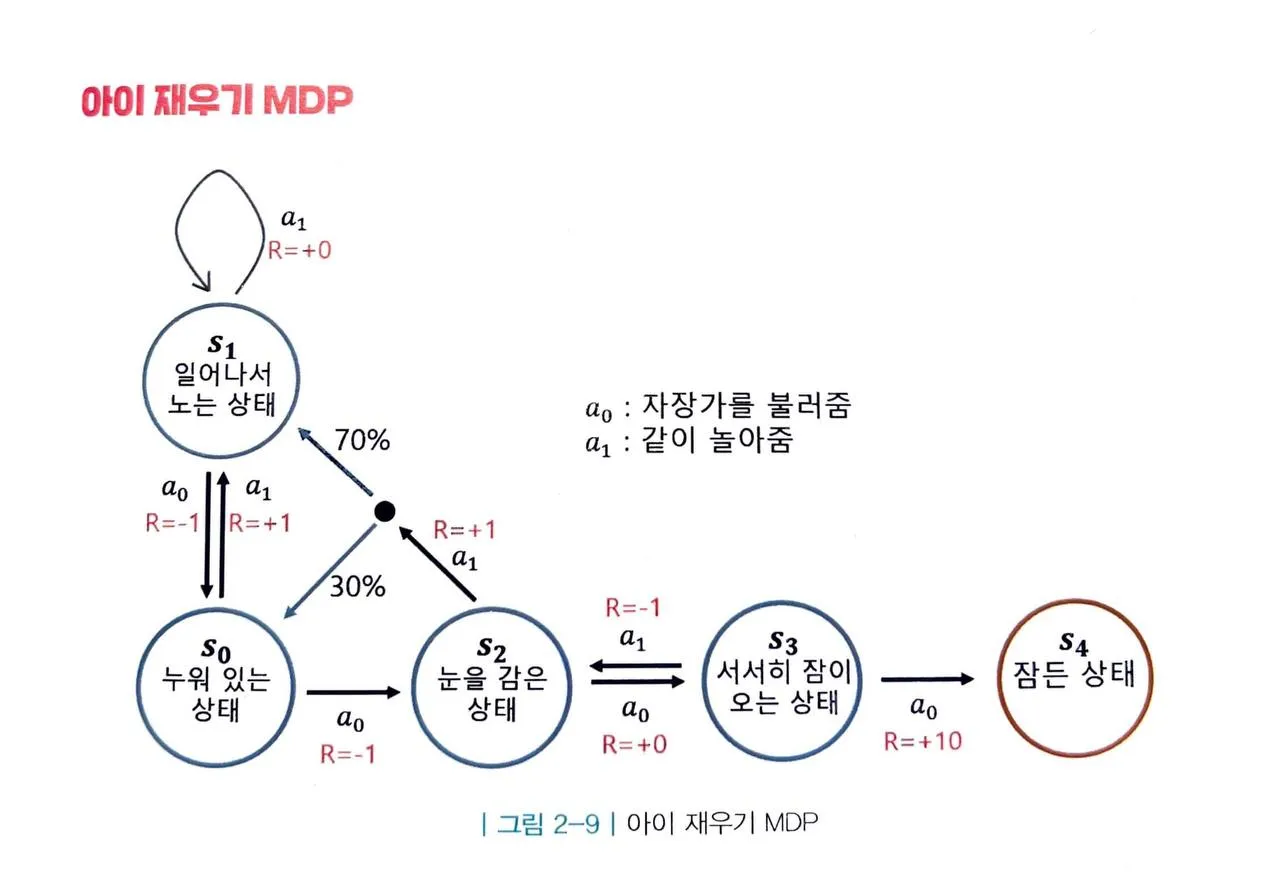
출처 : https://velog.io/@hkun_ho/RL-Markov-Decision-Process
해당 예시를 살펴보면, 어머니가 선택할 수 있는 액션은 자장가를 불러주는 액션 a0와 같이 놀아주는 액션 a1이 있다. 눈여겨 볼 부분은 S2에서 같이 놀아주는 a1 을 선택하면 상태에 따라 S1이 될 수도 있고 S0가 될 수도 있다는 점이다.
여기서 보상(R)을 보면 결국 보상의 합을 최대화하기 위해서는 a0만을 해야한다는 것을 알 수 있다. 이렇게 MDP는 간단한 경우 최적의 전략을 찾기 쉽지만, 실제 세계에서 마주하는 MDP는 상태의 개수(S), 액션의 개수(A)가 훨씬 많고 전이확률행렬(P)도 다양하기 때문에 쉽지만은 않다.
학습과 판단 에이전트의 역할
- 학습 에이전트
- 강화 학습(RL)을 사용하여 보상 신호를 기반으로 행동 전략을 학습하였다.
- 각 학습 에이전트는 자신만의 행동 전략(Policy)를 최적화하여 보상을 극대화한다.
- 판단 에이전트
-
학습 에이전트의 행동을 평가하고, 피드백을 숫자 보상 값으로 변환하여 제공한다.
-
각 판단 에이전트는 특정 윤리적 가치(ex. 정의, 포용성)에 대해 독립적으로 평가를 수행한다.
-
3.3 학습 에이전트(Learning Agents)
학습 에이전트는 다중 에이전트 환경에서 행동을 수행하며, 강화 학습을 통해 최적의 행동 전략(Policy)을 학습한다. 논문에서는 Q-DSOM 알고리즘을 사용하였으며 이는 결정 과정(Decision process)와 학습 과정(Learning process)로 나뉜다.
결정 과정
학습 에이전트가 현재 상태에서 어떤 행동을 수행할지 선택하는 단계
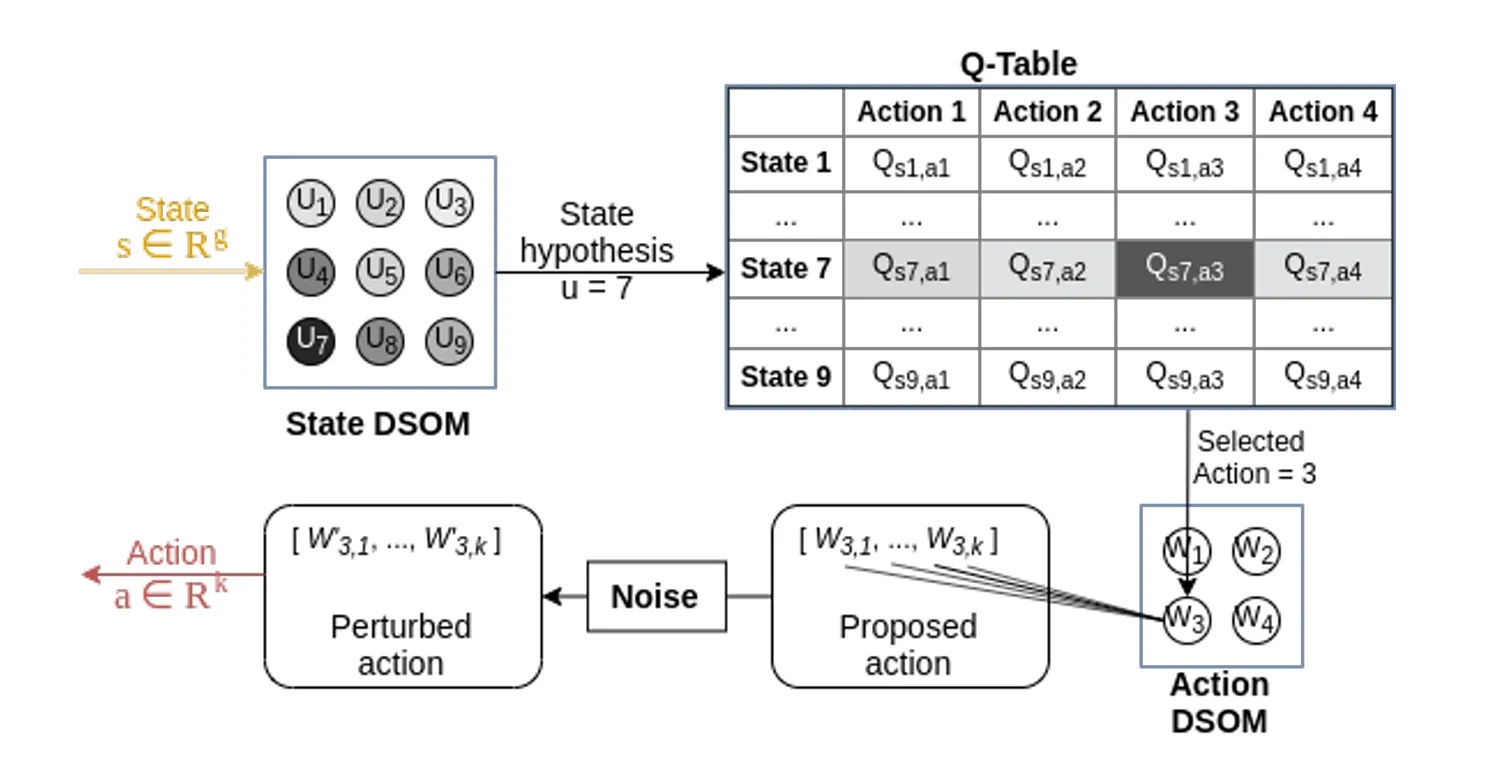
Figure2 : An example of a decision process
-
결정 에이전트는 상태 s를 입력값으로 받고, 이를 가장 가까운 클러스터 로 매핑한다.
- State DSOM(Dynamic Self-Organizing Map) : 상태 공간을 클러스터링 한 것
- Fig2에서는 s가 클러스터 과 가장 유사하다고 판단
-
매핑된 클러스터 은 State hypothesis로 사용되어 Q-Table로 넘어간다.
-
DSOM에서 결정된 상태 u=7에 대해 Q 테이블의 해당 행(State 7)을 참조하고 여러 행동에 의한 Q값을 비교하여 가장 높은 값을 선택한다.
- Q-Table : 상태와 행동 쌍에 대한 품질(Quality) 값을 저장
- Fig2에서는 Action3의 Q값이 가장 큼
-
선택된 행동은 행동 DSOM의 클러스터 로 매핑되며 이는 선택된 행동 벡터 를 나타낸다.
- 행동 DSOM(Action DSOM)은 에이전트가 환경에서 수행할 수 있는 모든 가능한 행동을 정의하는 공간으로 유사한 행동들끼리 그룹화한 것
- Fig2에서 Action3()는 클러스터 으로 배핑되는데, 이는 해당 클러스터의 대표 행동 벡터이자 행동 벡터가 실제로 수행될 행동으로 사용된다.
- 클러스터링의 이유 : 행동 공간이 매우 크거나 연속적일 경우 모든 행동을 직접 계산하기 어렵기 때문
-
선택된 행동 벡터에 랜덤 노이즈를 추가해 탐색을 촉진한다. 이로 인해 학습 에이전트는 최적의 행동만 반복하지 않고, 새로운 행동을 시도하며 더 나은 전략을 탐구한다.
-
최종적으로 계산된 행동 벡터는 환경에 적용되어 상태 s를 변화시킨다.
-
학습 에이전트는 이 행동의 결과로 보상을 받고, 이 보상을 사용해 Q-Table과 DSOM의 가중치를 업데이트한다.
🔆DSOM
고차원 데이터를 효율적으로 처리하고, 변화하는 환경에 적용할 수 있는 도구
학습 과정
결정 과정에서 선택한 행동의 결과를 바탕으로 에이전트의 전략(Policy)를 개선하는 단계
- 에이전트는 행동 수행 후, 환경으로부터 새로운 상태 와 보상 를 받는다.
- 새로운 보상 가 이전에 기억된 상태의 Q값(행동-상태 품질)보다 좋다면, 에이전트는 해당 행동이 좋은 행동이라고 판단하고 그 행동의 클러스터를 업데이트 한다.
- Action-DSOM에서 클러스터의 중심은 수행된 행동의 방향으로 조금 이동하는데, 이는 클러스터 중심이 노이즈가 추가된 행동 쪽으로 더 가까워졌다는 걸 의미
- 시행착오 기반으로 행동 클러스터 조절
- Bellman 방정식을 이용해 상태-행동 쌍의 Q-값을 업데이트한다.
- 마지막으로 State-DSOM에서 상태 클러스터가 업데이트되어 환경 상태를 더 잘 반영하게 된다.
🔆정리
행동의 결과를 보고 ‘좋은 행동이었다’고 판단하면 클러스터 업데이트를 통해 그 행동과 유사한 행동을 더 많이 선택할 가능성을 높이고 Bellman 방정식을 이용해 행동의 Q값을 수정한다. 동시에 환경 상태를 나타내는 State DSOM도 업데이트한다.
3.4 판단 에이전트(Judging Agents)
판단 에이전트는 학습 에이전트가 환경에서 수행한 행동에 대한 윤리적인 평가를 제공해 더 나은 행동을 학습할 수 있도록 피드백을 생성한다.
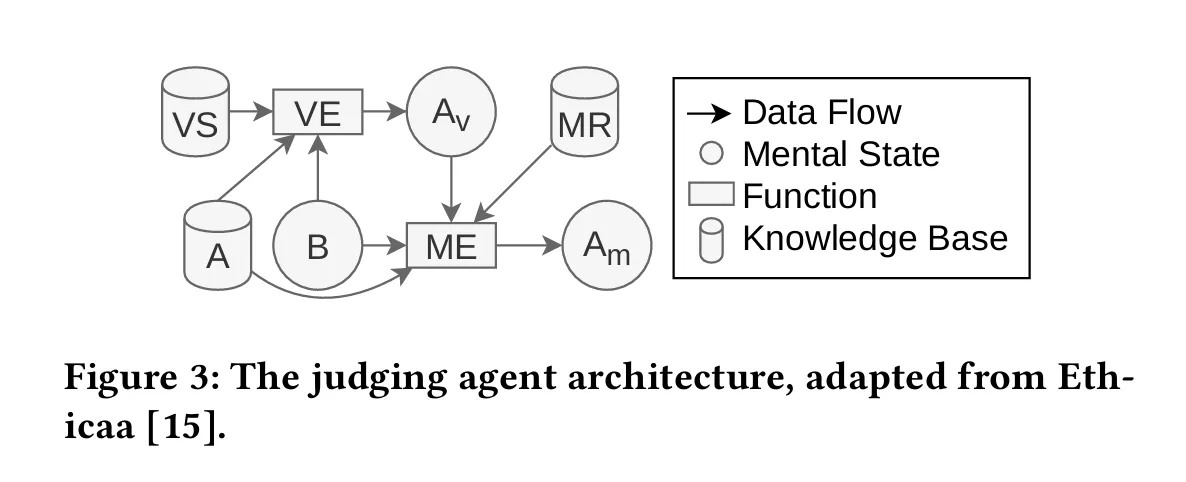
사진 설명
- VS (Value System) : 가치 시스템을 나타내며 판단 기준이나 윤리적 규칙 포함
- VE (Value Evaluator) : VS의 데이터를 사용해서 입력이나 상황 평가
- (Attitude toward Value) : VE에서 평가된 정보를 기반으로 에이전트가 어떤 가치를 선호하는지 나타냄
- MR(Moral Reasoning) : 도덕적 추론이나 관련 규칙, 정보 저장
- A (Action) : 에이전트가 수행할 수 있는 행동이나 옵션에 관한 데이터 보관
- B(Belief) : 에이전트의 신념이나 세계관
- ME(Moral Evaluator) : A와 B에서 제공된 데이터를 기반으로 도덕적 판단 수행
- (Moral Attitude) : 도덕적 판단을 기반으로 한 에이전트의 태도 형성
- 관찰 : 판단 에이전트는 학습 에이전트의 행동과 그로 인해 변화한 환경 상태를 관찰
- 윤리적 규칙 기반 평가
- 사전에 정의된 ‘윤리적 규칙’을 사용해 학습 에이전트의 행동을 평가
- 각 윤리적 규칙은 특정 기준에 따라 도덕적(Moral), 비도덕적(Immoral), 중립적(Neutral)인지 판단
- 숫자 보상 변환 : 판단 결과를 숫자 보상 값으로 변환해 학습 에이전트에 전달한다.
- "도덕적" → 높은 보상 (예: 1)
- "중립적" → 중간 보상 (예: 0.5)
- "비도덕적" → 낮은 보상 (예: 0)
- 다중 판단 에이전트의 결합
- 판단 결과는 평균, 가중 평균, 또는 특정 규칙 우선순위에 따라 결합
3.5 학습을 위한 판단(Judgment for Learning)
판단 에이전트가 생성한 피드백(윤리적 판단 결과)는 학습 에이전트가 행동 전략을 학습하는데 사용되며 숫자 보상 값은 강화 학습 알고리즘을 업데이트하는데 사용된다.
- 판단 결과 수신
- 예를 들어 에이전트가 에너지를 효율적으로 분해하면 도덕적 평가를 받고, 높은 보상을 수신
- Bellman 방정식 기반 업데이트
- 학습 에이전트의 행동 전략 개선
판단 에이전트 vs 학습을 위한 판단
| 판단 에이전트 | 학습을 위한 판단 | |
|---|---|---|
| 주요 역할 | 학습 에이전트의 행동을 평가 | 평가 결과를 학습 에이전트의 학습에 활용 |
| 결과물 | 윤리적 판단(숫자 보상으로 변환) | Q-값 업데이트 및 행동 전략 개선 |
| 사용 알고리즘 | 윤리적 규칙 기반 판단 | 강화 학습 알고리즘 (Bellman 방정식) |
| 결과의 반영 대상 | 학습 에이전트의 행동 품질 평가 | 학습 에이전트의 행동 전략 및 정책(policy |
학습 에이전트의 ‘학습 과정’은 미래 보상을 최대화하는 행동 전략을 학습하는 것으로 스스로 행동의 효율성을 평가하는 것
판단 에이전트는 윤리적 기준이나 외부 규칙에 따라 학습 에이전트의 행동을 평가하는 것
비유해보자면, 학습 에이전트는 목표 지점에 빨리 도달하려는 운전자이고, 판단 에이전트는 교통 경찰처럼 교통 규칙을 평가하고 벌금 또는 보상을 제공하는 역할. 운전자(학습 에이전트)가 목표를 달성하려면 경찰(판단 에이전트)의 기준을 따르면서도 효율적으로 운전을 해야 함!
4. 실험
실험은 스마트 그리드라는 가상 시뮬레이션 환경에서 수행된다.
- 스마트 그리드 : 전력 생산이 분산된 소규모 네트워크로, 전력 소비자와 생산자가 모두 역할을 수행하는 Prosumers로 구성됨
실험의 목표는 “학습 에이전트가 윤리적 규칙을 학습하고, 이 규칙에 따라 에너지 소비 및 분배를 최적화할 수 있는 평가”하는 것이다. 윤리적 딜레마를 다루는 시뮬레이션에서 에이전트의 행동을 분석한다.
4.1 윤리적 규칙과 가치의 중요성
논문에서는 시민의 관점에서 학습 에이전트가 준수해야 하는 4가지 윤리적 규칙을 제안한다.
MR1- 안정적인 전력 공급 (Security of Supply)- 에이전트가 자신의 편안함(comfort)을 개선할 수 있는 행동은
도덕적이다. - ex. 필요한 에너지를 제 때 소비함
- 에이전트가 자신의 편안함(comfort)을 개선할 수 있는 행동은
MR2- 경제적 부담 감소 (Affordability)- 예산을 초과하는 소비를 유발하는 행동은
비도덕적이다. - ex. 예산을 초과하는 비용을 지불하고 에너지를 구매.
- 예산을 초과하는 소비를 유발하는 행동은
MR3- 포괄성 및 공정성 (Inclusiveness)- 모든 에이전트 간 편안함(comfort)의 형평성을 개선하는 행동은
도덕적이다. - ex. 에너지를 적절히 분배하여 특정 에이전트가 과도한 불편을 겪지 않도록 함.
- 모든 에이전트 간 편안함(comfort)의 형평성을 개선하는 행동은
MR4- 환경 지속 가능성 (Environmental Sustainability)- 국가 전력망과의 에너지 거래를 최소화하는 행동은
도덕적이다. - ex. 개인 저장소나 지역 그리드를 우선 활용하여 전력망 의존을 줄임
- 국가 전력망과의 에너지 거래를 최소화하는 행동은
4.2 Simulator Description
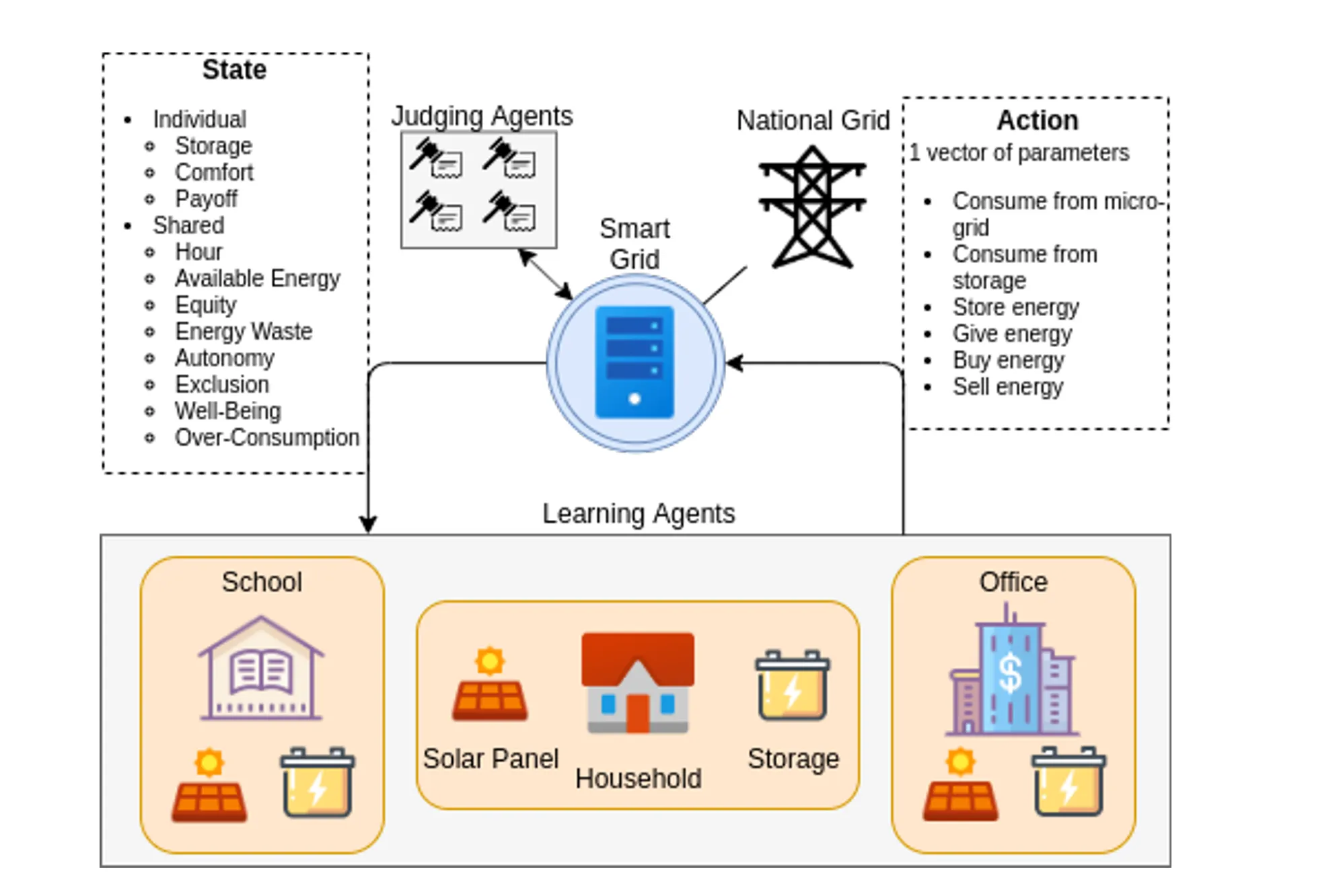
- 학습 에이전트는 스마트 그리드의 참여자(프로슈머)이며 이들은 에너지를 소비하거나 저장하거나 필요에 따라 거래를 수행한다.
- 가정, 사무실, 학교라는 환경에서 학습 에이전트는 6개의 매개변수로 행동을 수행한다.
- 매개변수
- : 마이크로 그리드에서 소비한 에너지
- : 개인 저장소에서 소비한 에너지
- : 개인 저장소에서 마이크로 그리드로 제공한 에너지
- : 개인 저장소로 저장한 에너지
- : 국가 전력망에서 구매한 에너지
- : 국가 전력망에 판매한 에너지
- 매개변수
- 판단 에이전트는 학습 에이전트의 행동이 앞서 말한 윤리적 규칙을 얼마나 잘 준수했는지 평가하고 보상을 숫자값으로 변환하여 전달한다.
5. 결과
해당 논문은 가장 관련성이 높은 Default과 Incremental 시나리오에 초점을 맞췄으며 단일 윤리적 규칙이 에이전트의 행동에 미치는 영향을 확인하기 위해 Mono-Values 시나리오도 사용하였다.
- Default 시나리오 : 모든 판단 에이전트가 한 번에 활성화된 상태의 시나리오
- Incremental 시나리오 : 판단 에이전트를 하나씩 추가하면서 학습 에이전트가 새로운 규칙에 적용하는 능력을 테스트하는 시나리오
- Mono-values 시나리오 : 한 번에 하나의 판단 에이전트만 적용하는 시나리오
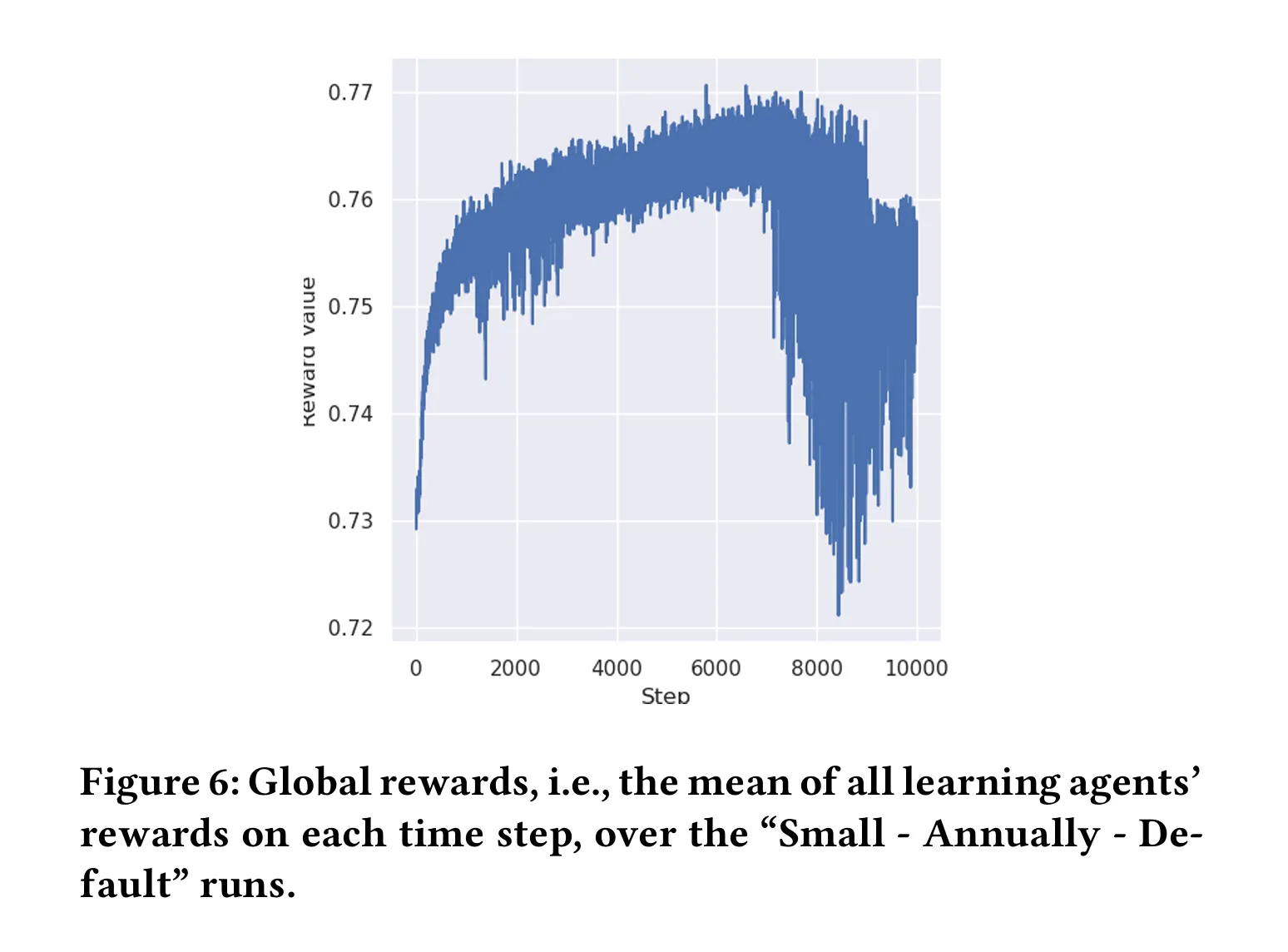
Fig은 Default 시나리오다. 여기서 시간이 지남에 따라 학습 에이전트가 규칙을 점진적으로 학습하면서 보상 값이 높아짐을 알 수 있다. 그러나 후반부에는 보상이 급격히 하락하는데, 규칙 수가 많아지면서 복잡해져 학습 에이전트가 이를 완전히 이해하고 적용하기 어려웠던 것으로 보인다.
즉, 제안된 모델은 윤리적 행동을 학습하는 데 효과적이지만 특정 규칙 혹은 복잡한 규칙은 개선이 필요하다.
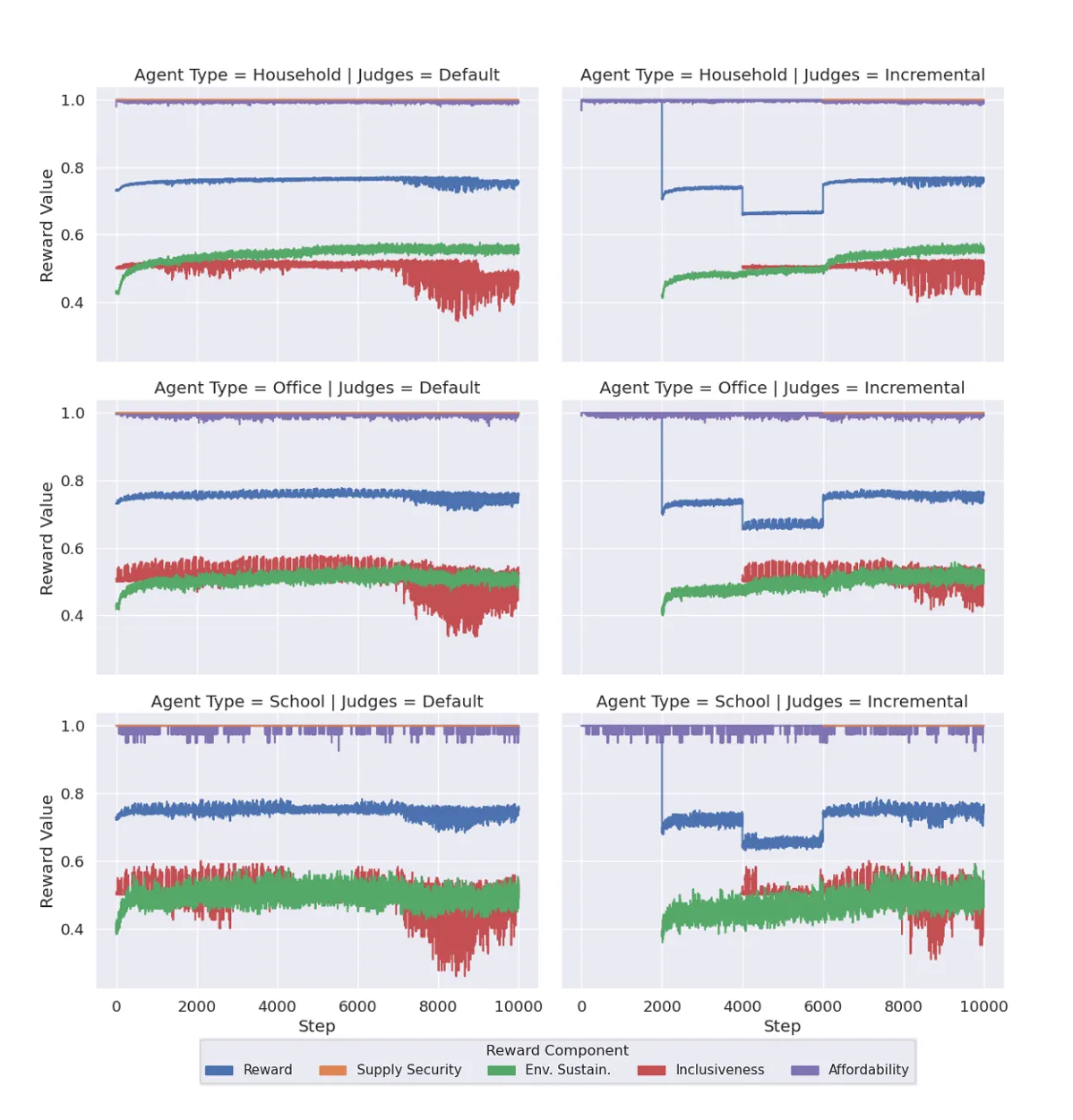
전반적으로 초반 보상 값은 높으나 후반부에 떨어지는 모습을 보인다.
해당 그래프의 특징은 다음과 같다.
- 포괄성(Inclusiveness)의 가치는 학습하기 더 어려우며 후반부에 크게 감소하는 모습을 보임
- Default와 Incremental을 비교했을 때 후자가 포괄성에 대한 부정적인 영향을 완화하는 것으로 보임
- 학교 에이전트는 행동 범위와 환경이 미치는 영향이 커서 보상의 변동폭이 큰 반면, 가정과 사무실 에이전트는 더 예측 가능한 방식으로 학습함
- 스마트 그리드 내에서 가정보다 학교 에이전트가 더 많은 에너지를 사용함
- 행동 범위가 넓다는 것은 의사 결정의 복잡성과 중요성이 크다는 것
6. 논의
해당 논문은 다중 에이전트 시스템에서 학습 에이전트에게 보상으로 제공되는 상징적 판단을 사용하여 ‘윤리적 행동’을 학습하는 새로운 방법을 제안한 것으로 시뮬레이션된 스마트 그리드 환경의 에너지 분배 문제에 적용하여 평가했다.
개선할 여지는 많으나 제안된 접근법이 효과적으로 작동할 수 있음을 증명하는 초기 단계의 연구로서 가치가 있다고 할 수 있다.
해당 접근법의 기여는 다음과 같다.
- 윤리적 행동 학습 방법 제안
- 도덕적 가치를 포함하고 인간 관점에서 윤리적이라고 간주되는 행동 학습 설계
- 심볼릭 판단을 보상으로 사용해 보상 유도
- 적응성 강조
- 현재 사회에서 일반적으로 받아들여지는 윤리는 시간에 따라 변할 수 있음에 주목
- 본 논문에서는 Incremental(점진적 추가) 실험 시나리오를 통해 규칙이 추가될 떄 에이전트의 적응능력을 보여준다.
- 기존 보상 설계 방식과는 달리, 새로운 데이터셋을 생성하거나 에이전트 재학습이 필요 없음
- 연속적 행동
- 많은 연구가 텍스트북 딜레마(ex. 트롤리 문제)나 제한된 현실적 상황(ex. 노인 돌봄 로봇, 군사용 로봇)과 같이 이산적(discrete) 행동만 다룸.
- 본 연구는 연속적(continuous) 행동을 요구하는 더 복잡한 환경(스마트 그리드)에서 실험을 수행.
문제에 따른 개선점 제안
-
판단 에이전트가 학습 에이전트에 대한 광범위한 데이터를 요구해 개인 정보를 침해할 수 있음
→ 데이터를 제한하여 개인 정보 침해를 최소화
→ 판단 에이전트가 에이전트를 식별할 수 없도록 데이터를 익명화
-
논문에서 사용한 도덕 규칙은 단순해서 수치 함수로도 대체가 가능함
→ 판단 에이전트와 도덕 규칙을 확장
-
심볼릭 판단을 숫자로 매핑하고 평균 내어 보상을 생성하는 방식은 다루기 쉽지만 복잡한 상황에서 한계를 가질 수 있음
-
규칙 간의 우선순위 문제
- 모든 윤리적 규칙이 항상 동일한 중요도를 가지는 것이 아님
- ex. 병원 같은 중요 건물이 에너지 부족 상태에 처할 경우, 환경 보호 규칙을 일시적으로 무시하고 국가 전력망에서 에너지 구입하는 것이 더 윤리적일 수 있음
- 현재는 규칙을 단순히 숫자로 변환함으로 특수 상황에서의 규칙 우선순위 판단이 어려움
→ 협상 매커니즘 도입 : 판단 에이전트들이 ‘이 상황에서 어떤 규칙이 더 중요한가?’를 논의해 결론 내리는 시스템 추가
7. What we can do?
- Multi-agent를 도입해 행동 에이전트의 행동을 최적화 + 윤리화하는 것을 목표 (해당 논문을 베이스로 시작)
- 협상 매커니즘 도입 부분을 진행해봐도 좋지 않을까 싶습니다! → 후속 논문을 찾아봤는데 아직 없는 것으로 보임.
- 관련 자료
- [Blog|EIPA] Negotiating Smarter : How AI might Change the Game(2024)
🐋 생각모음
- 윤리적인 AI를 위해서는 강화학습이 필수적이라는 생각이 들었다. 그런데 AI는 결국 '이익을 위한 윤리'만을 학습할 수밖에 없는 것일까? '윤리적인 행동'을 하면 보상이 크게 주어지는 상황에서 AI는 이익을 최대화하기 위해 우리가 원하는 방향을 따라갈 수밖에 없다. 윤리 AI에서 윤리와 AI는 어떤 관계를 가지고 있는지 생각해봐야할 것 같다.
- 더욱이 디자이너가 계속해서 판단 에이전트와 학습 에이전트를 수정하는데, 이 과정에서 '보편적 윤리'라는 것은 대체 무엇일까?
