[논문리뷰] EEG emotion Recognition using Attention-based Convolutional transformer neural network
paper-review
ABSTRACT
EEG 신호를 이용한 감정 인식에서 성능을 향상시키기 위해 공간적, 스펙트럼적, 시간적 정보를 효과적으로 결합하는 방법, ACTNN(Attention-based Convolutional Tranformer Neural Network)이라는 새로운 신경망 구조를 제안한다.
1. Introduce
- ACTNN이라는 새로운 어텐션 기반 트랜스포머 신경망 제안
- CNN의 로컬 인식과 트랜스포머의 글로벌 인식의 장점을 효과적으로 사용
- 일반적인 주의 매커니즘 레이아웃으로 높은 계산 복잡성을 극복하고 연산량을 절약
2. Materials and methods
2.1 Dataset
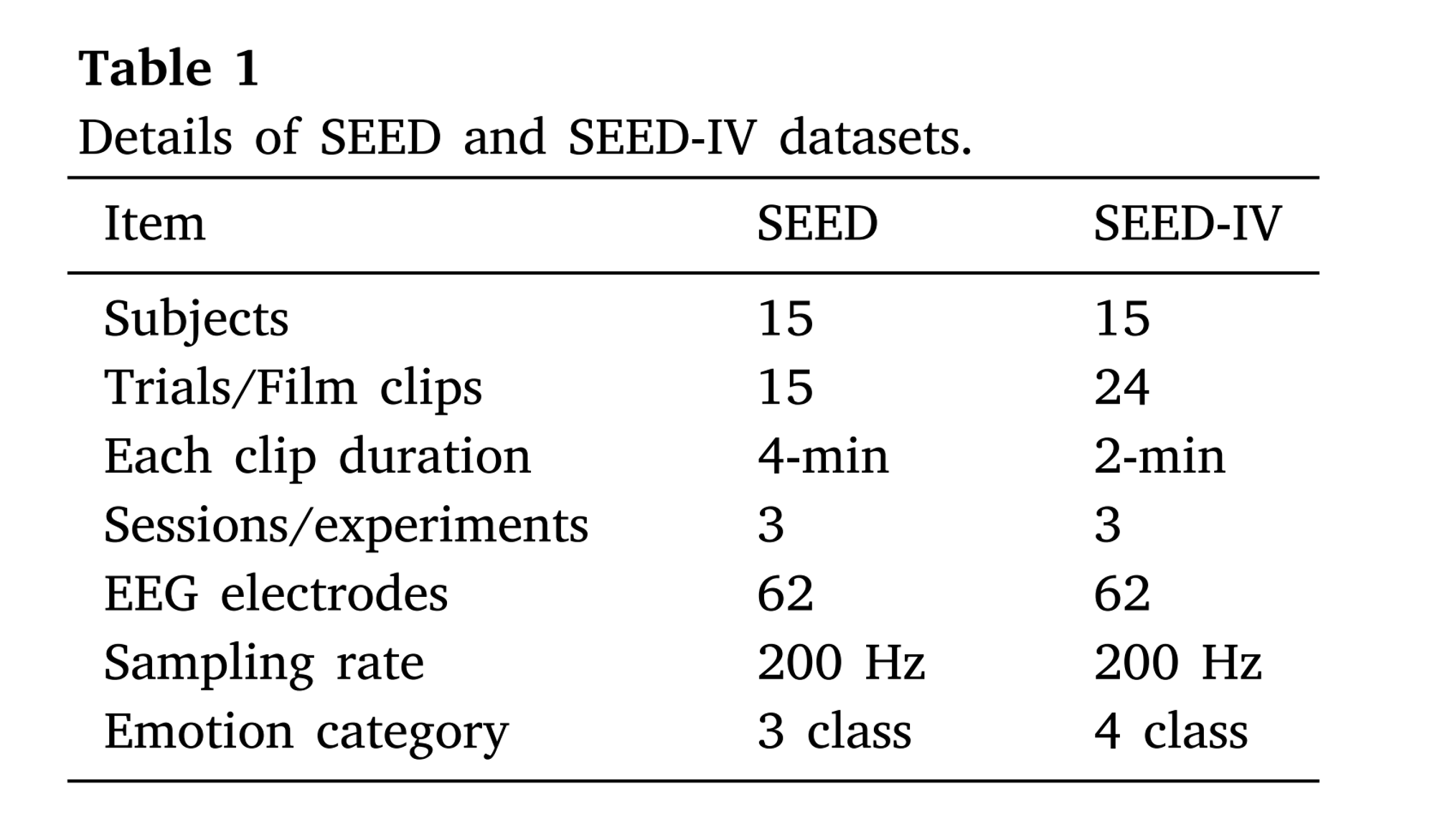
SEED dataset [31, 38]은 감정 모델이 있는 공공 EEG 감정 데이터으로 각 피험자는 3번의 실험을 진행했다. 각 실험에서 피험자는 4분짜리 15개의 영화 클립을 시청했다.
SEED 4 데이터셋은 EEG 신호와 시선 이동 신호까지 함께 들어 있는 공공 데이터셋으로 하나의 실험당 2분 짜리 24개의 영화 클립을 15명의 피험자가 시청했다. 62개의 전극을 가지고 있었고 SEED4의 경우 중립, 슬픔, 두려움, 행복 4가지 감정이 있다.
2.2 The proposed model
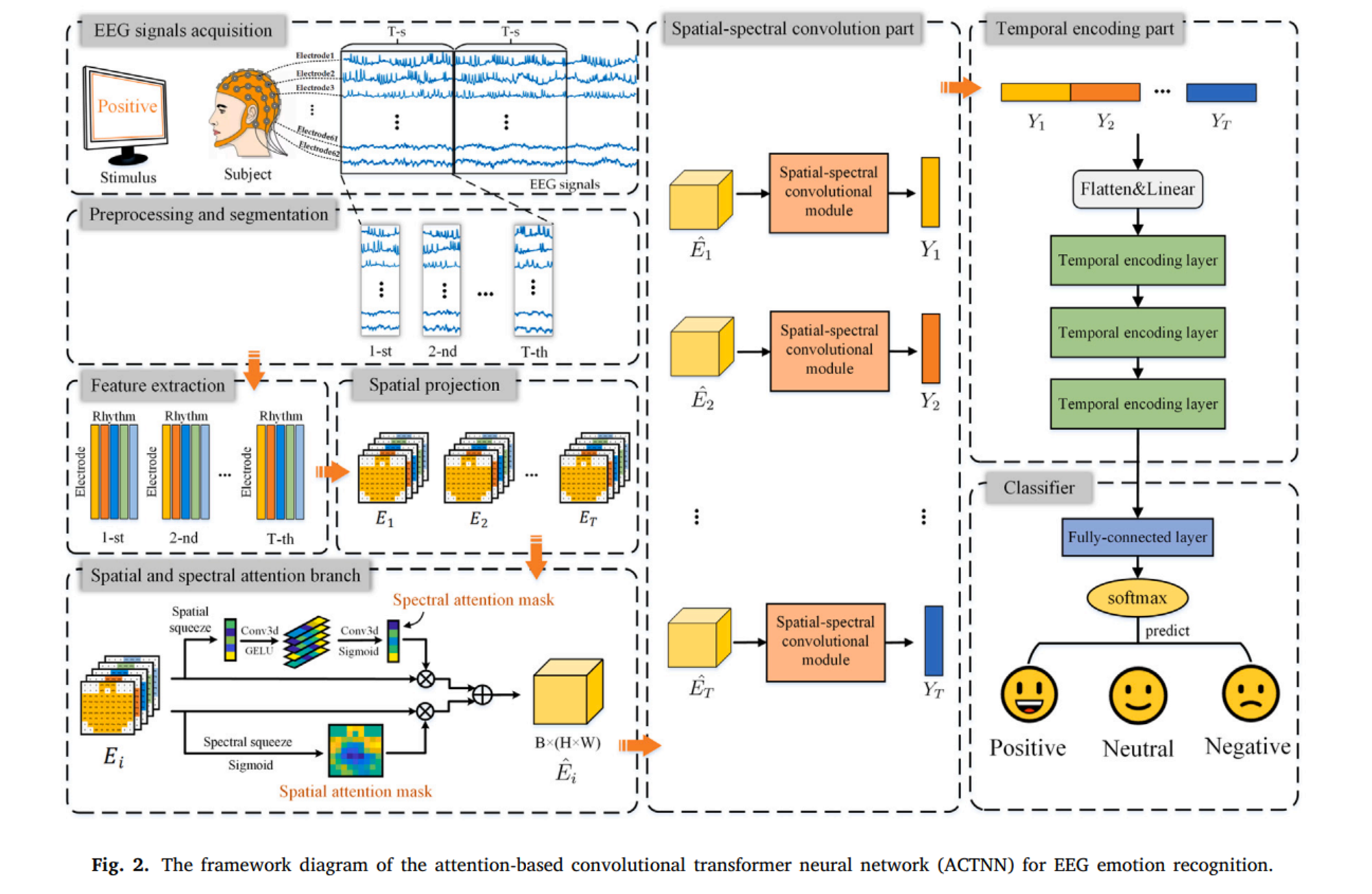
- 전처리 : EEG 신호를 1초의 작은 조각으로 슬라이싱하고 각 조각에 대해 5개의 주파수 대역에 대해 DE 특징을 추출
- 공간적 정보 추가 : EEG 전극의 위치를 2D 행렬로 투영함. 이때 전극의 위치는 DE 특징 값으로, 나머지는 0으로 채움.
- 공간적, 스펙트럼적 어텐션을 통해 주요 데이터 추출 : 중요한 뇌 영역과 주파수 대역을 강조하고 공간적, 스펙트럼적 어텐션 가중치를 계산
- Local 패턴 추출 : 연속적인 3개의 Conv layer로 구성되어 있는 conv 모듈로 공간 및 스펙트럼 패턴 추출
- Global 시간적 특징 추출 : 3개의 MHA로 구성되어 있으며 각 시간 슬라이스 별 시간적 패턴을 파악
- Classification : Fully-connected layer와 softmax layer로 감정 상태를 분류함
Preprocessing and feature extraction
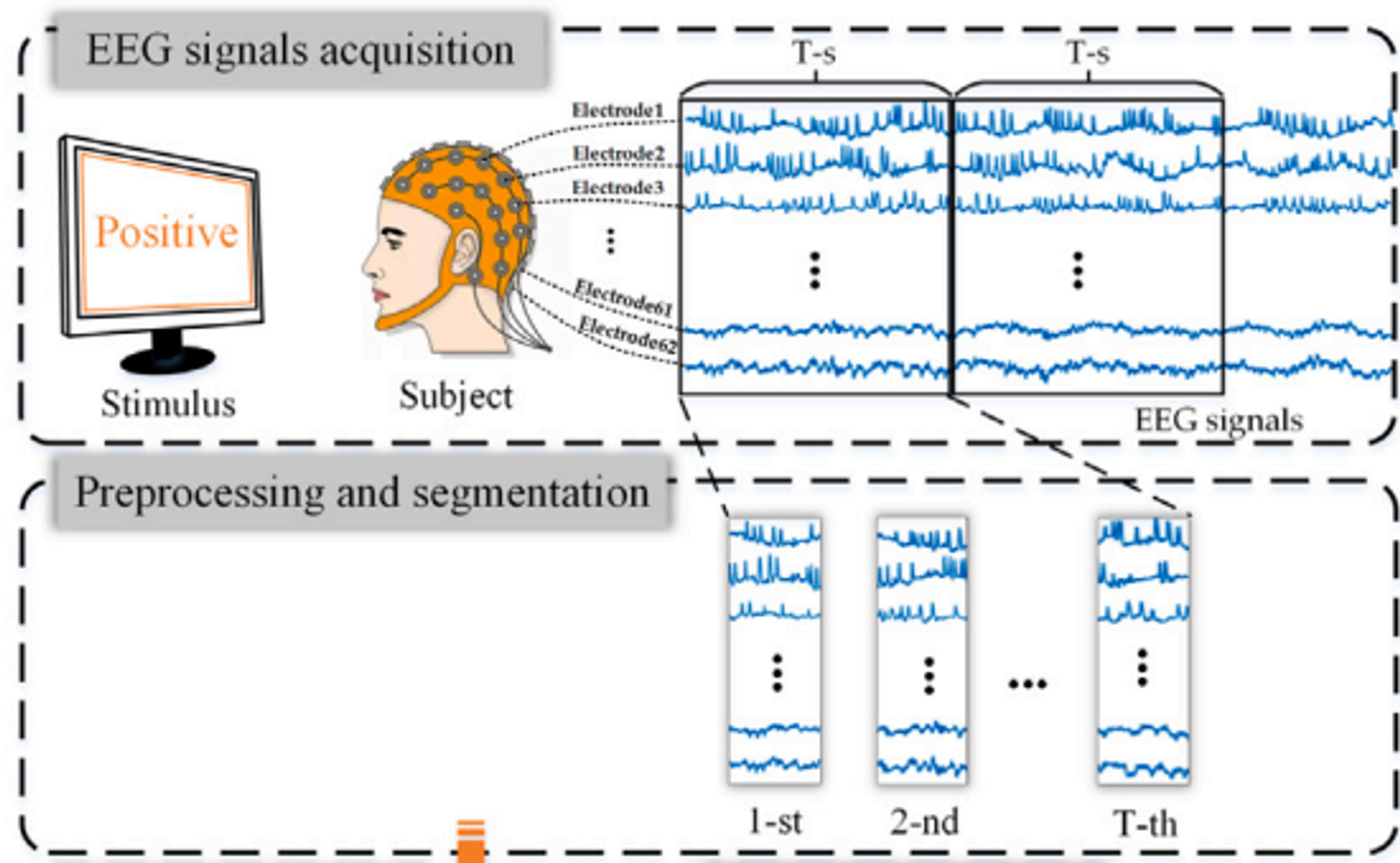
전체 데이터를 1초 길이의 T개 조각으로 슬라이싱한다. 각 segment에 대해 DE(Differential entropy) 특징을 추출한다.
Spatial Projection
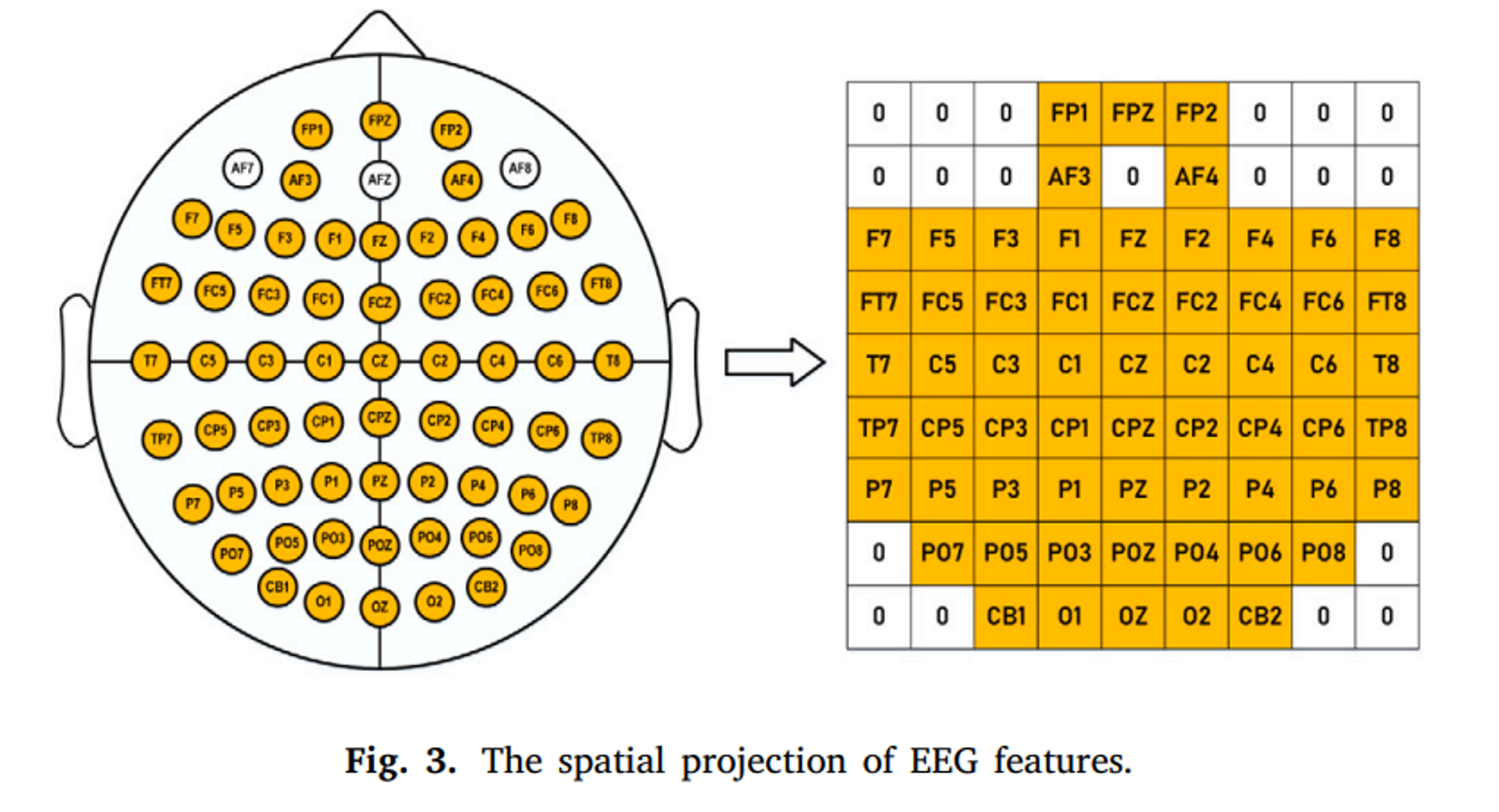
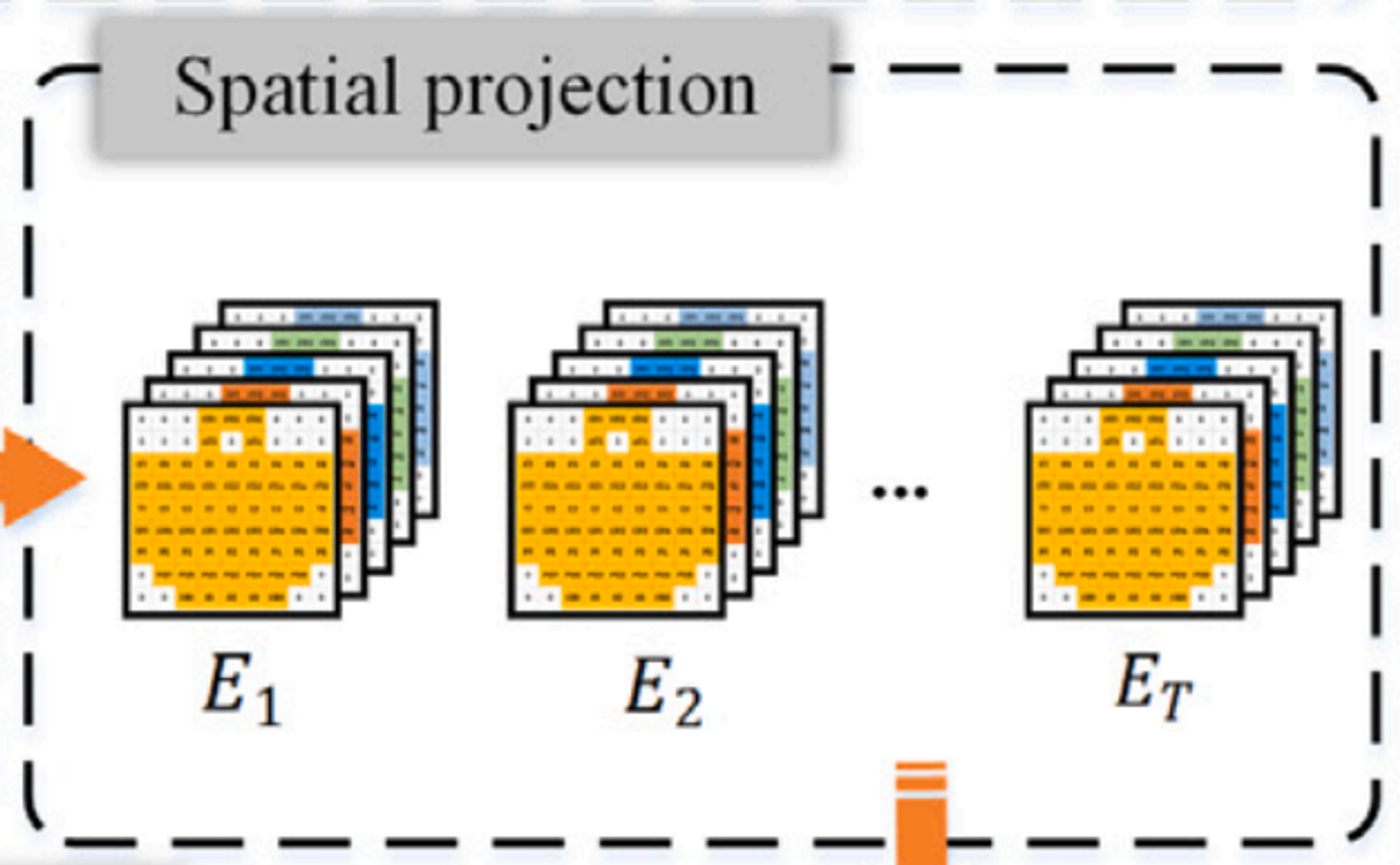
EEG 전극의 위치와 상대적인 관계성을 보존하기 위해 2D 행렬로 projection 한다. 각각 전극의 EEG 특성들은 2D 행렬에 매핑되고, frequenvy band에 의해 3D 구조물로 조직된다.(???)
전극이 위치한 곳에는 특징으로 채워지고 위치하지 않은 곳은 0으로 채워진다.
2D Matrix의 모양은 HXW(H=W=9)이다.
Spatial Attention Branch
감정에 큰 영향을 미치는 뇌 영역과 주파수를 찾아내기 위해 Spatial Attention branch를 이용함
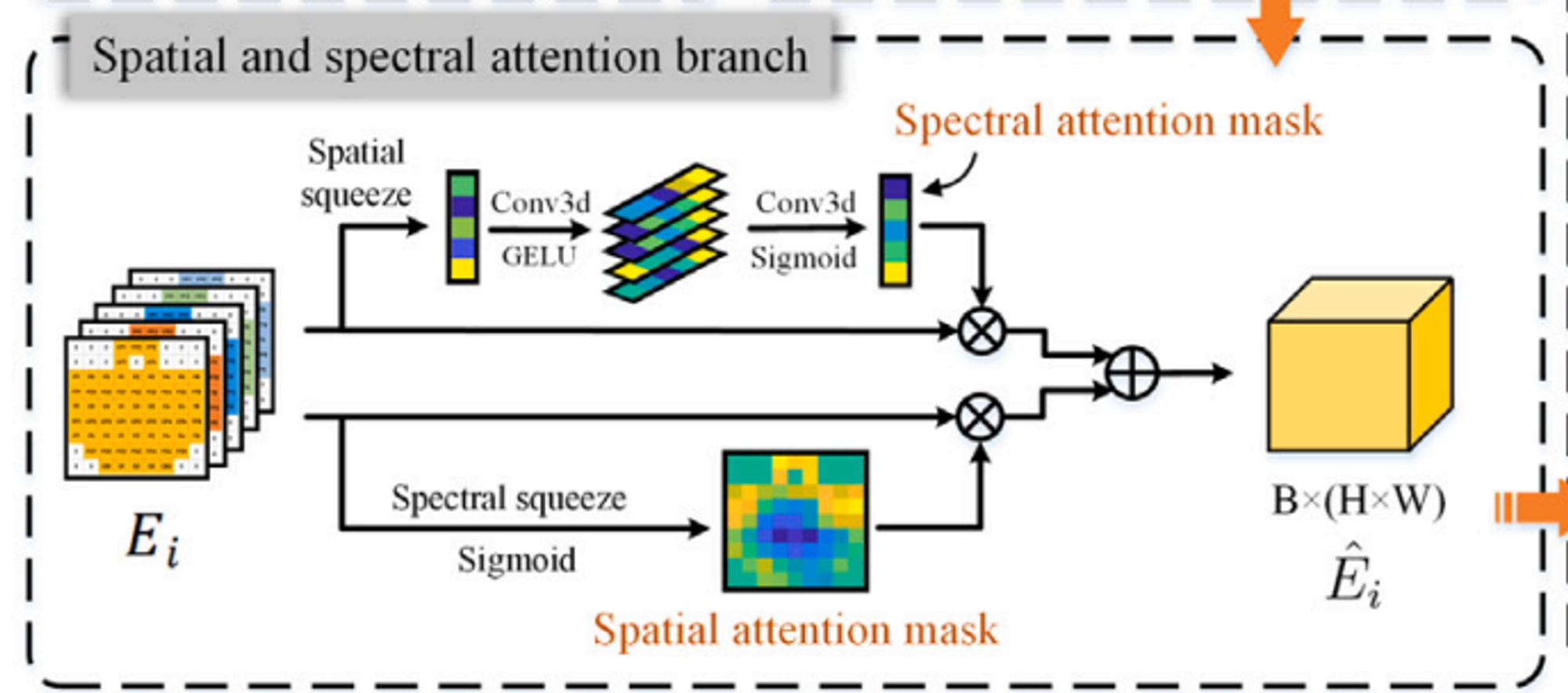
Spatial attention branch
감정 활동에 관여하는 뇌 영역을 포착하기 위해 스펙트럼 압축(spectral squeeze)과 spatial excitation을 사용함
각 시간 조각의 3차원 구조 E_i는 [e1,1,e1,2…..eH,W]로 표현된다. 3D 합성곱(convolution)을 사용하여 구현하고 커널 크기는 BX1X1이며 출력 크기는 1이다.
시그모이드 함수를 이용하여 정규화하고, 이를 3차원 구조에 적용해 을 얻는다.
Spectral Attention branch
감정 활동에 관여하는 주파수 밴드를 포착하기 위해 사용한다. 더 높은 주파수에는 높은 Attention 가중치를 부여하며 활성화 함수는 GELU(Gaussian error linear unit)이다.
𝐸_{𝑖,𝑠𝑝𝑒𝑐𝑡𝑟𝑎𝑙} = [𝜎( ̂𝑧1)𝑒1, 𝜎( ̂𝑧2)𝑒2, …, 𝜎( ̂𝑧𝐵)𝑒𝐵]
최종적으로 뇌 영역의 요도에 따른 Attention score와 주파수의 중요도에 따른 Attention score를 합산하여 score를 적용한 행렬이 나온다.
Spatial-spectral convolution module
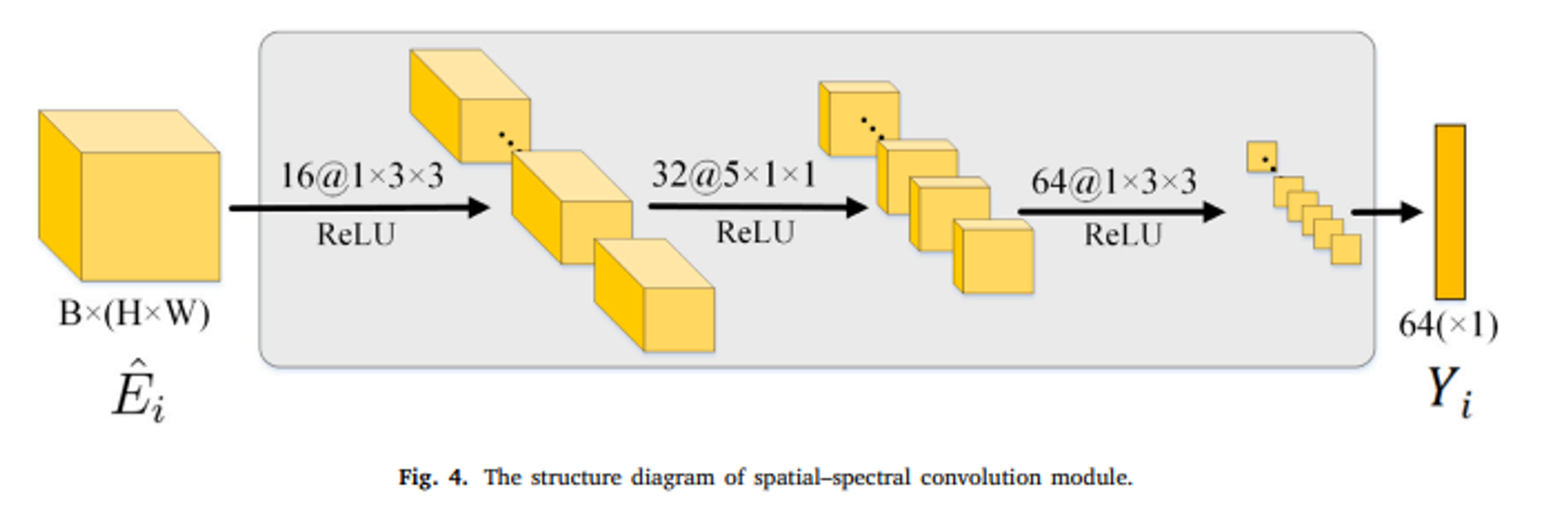
Local 특징을 포착하기 위해 conv를 수행한다.각 conv 모듈은 연속적인 conv layer로 구성되어 있으며 각 layer
Transformer-based temporal encoding part
3개의 시간적 인코딩 레이어로 구성되어 있으며 각각은 multi-head self-attention(MHSA)과 feed-forward network(FFN) 모듈로 이루어져 있다.
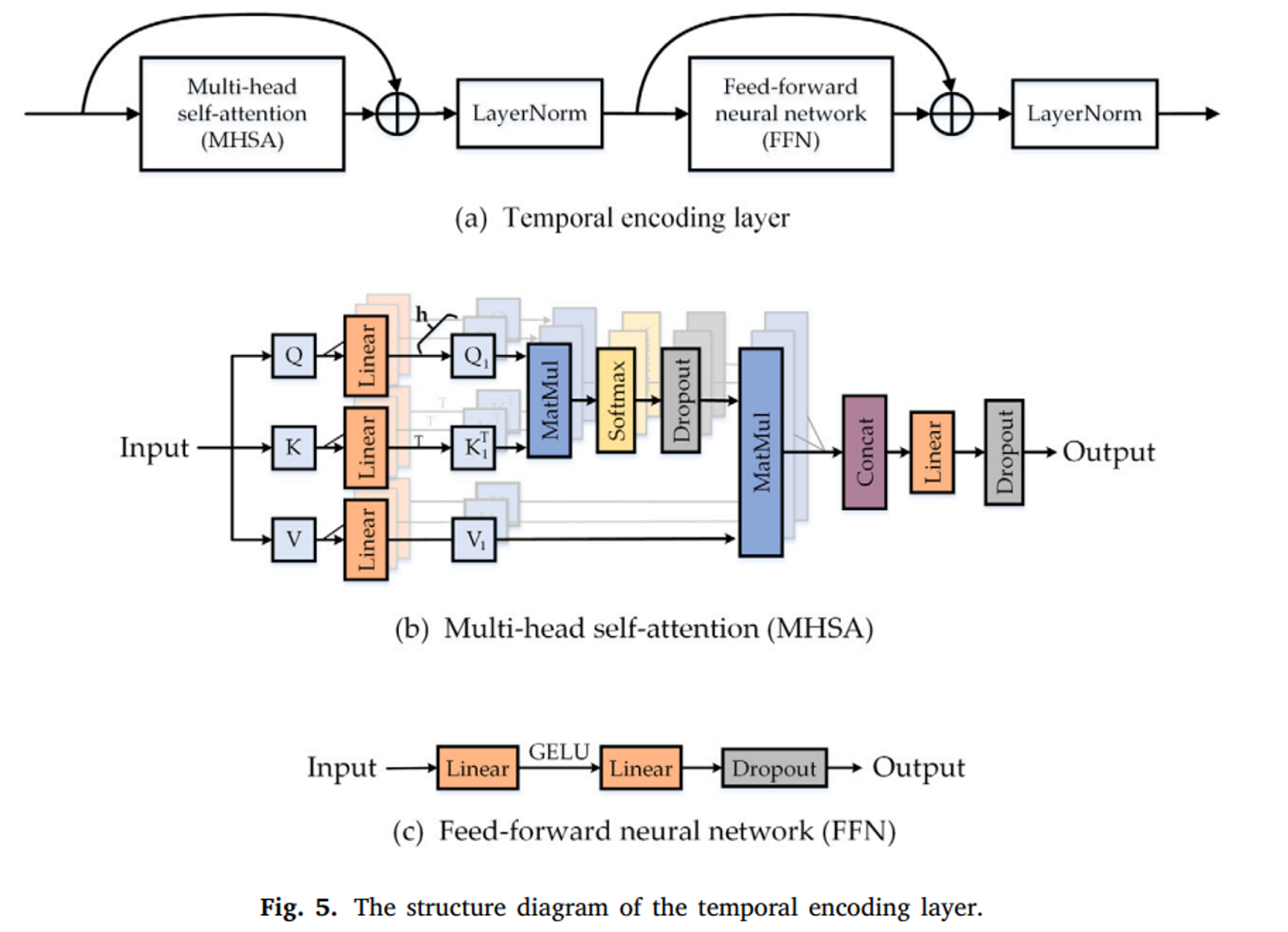
MHSA에서 모델에서는 6개의 attention head를 사용하며 이전 단계의 출력 Y를 이용해 Q, K, V를 생성한다. 각 헤드의 출력을 연결해 최종 출력을 얻으면 이에 잔차 연결과 레이어 정규화를 적용한다.
FFN의 경우 두 개의 선형 매핑 레이어로 구성되는데, 잔차 연결과 레이어 정규화를 적용한 후 출력 Y’를 시간적 인코딩 레이어에 전달한다.
Classifier
최종분류기는 완전 연결 레이어와 소프트맥스 레이어로 구성된다. 최종 출력을 사용해 감정 레이블을 예측한다.
3. Experiment and Results
SEED dataset은 1692개로 이루어져 있고 SEED4 dataset은 세션별로 각각 1711, 1677, 1655개로 이루어져 있다

3.1 Experiment setup
NVIDIA RTX 1080Ti GPU를 사용하여 모델을 테스트하였으며 pytorch로 구현한 코드는 github에 나와있다.
3.2 Model implementation
spatial-spectral convolution module은 3개의 convolution layer를 포함하고, 각각의 커널 크기는 1X3X3, 5X1X1, 1X3X3, 출력은 각각 16, 32, 64이다.
MHSA의 head 개수는 6개이고 여기에 LayerNorm과 GELU activate 기능이 적용되었고 단순 분류기(classifier)sms fully-connected layer와 softmax 계층으로 구성되었다.
3.3 Statistical Analysis of DE Features
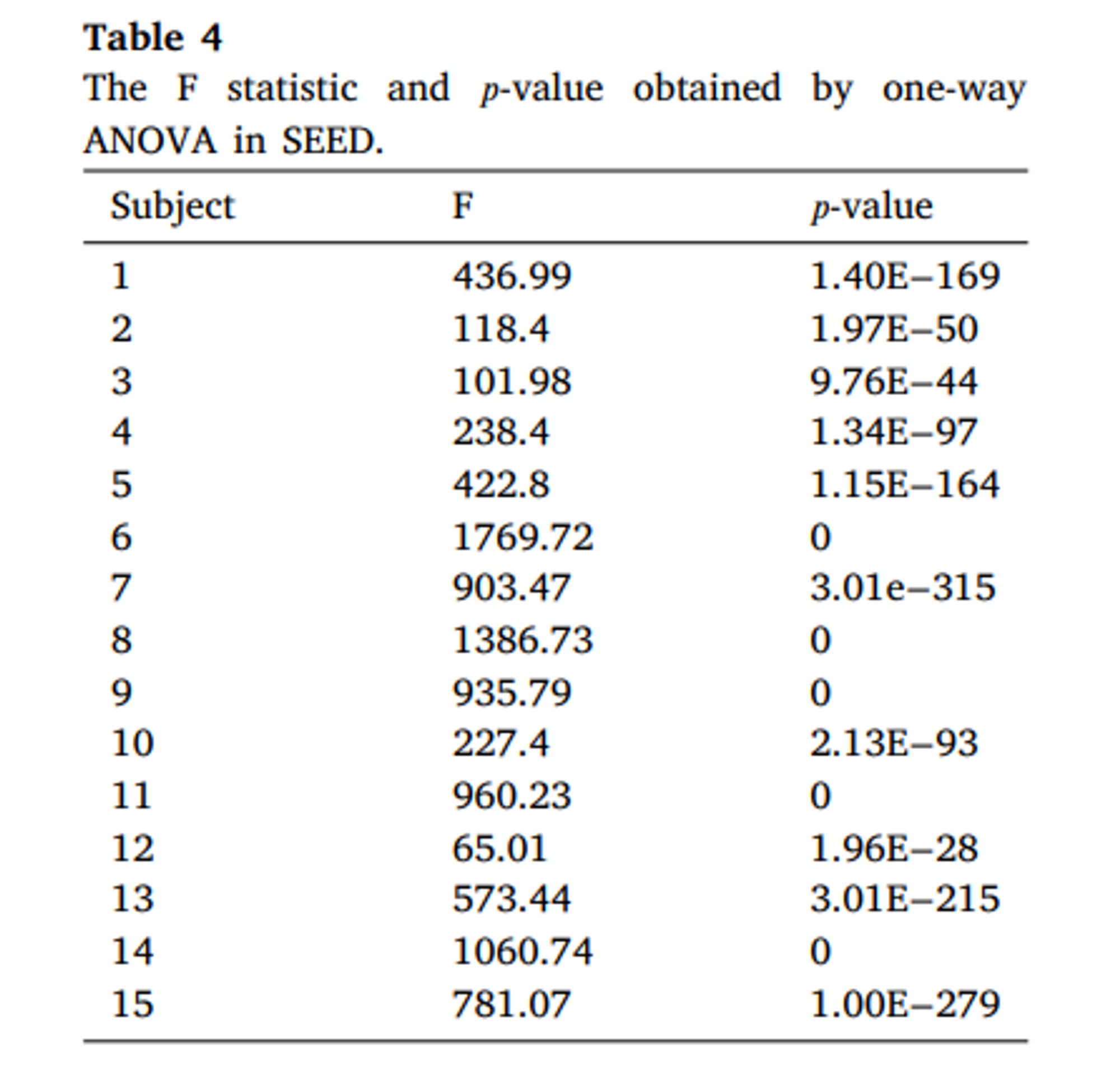
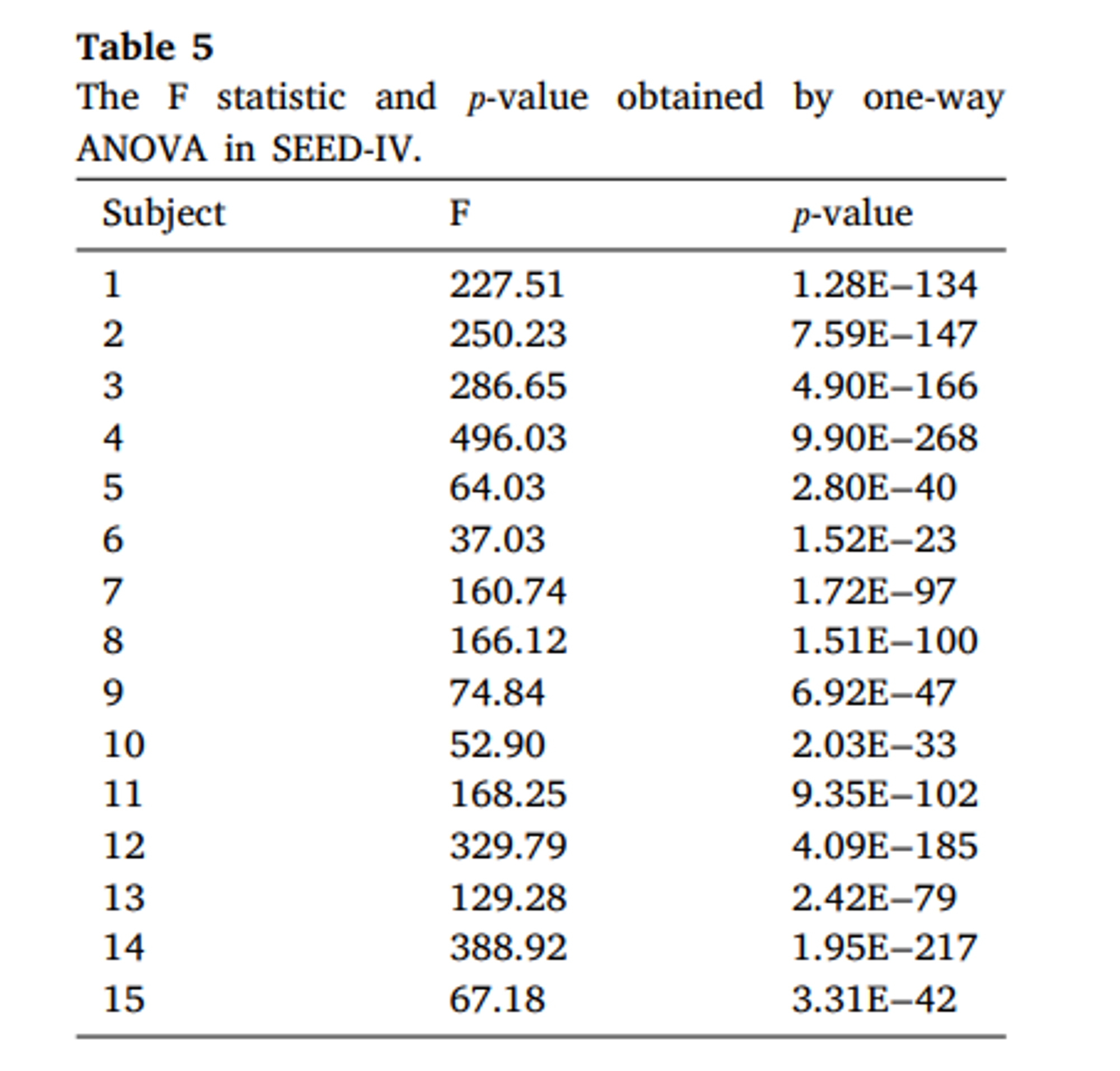
ANOVA 분석을 사용하여 99% 신뢰도에서 서로 다른 감정에서 DE 특징의 유사도를 조사했다. 종속변수는 EEG 신호에서 추출한 DE 특징의 평균 정규화값, 독립변수는 감정 상태이다.
SEED와 SEED4 모두 피험자의 p 값이 0.01미만으로 나타나므로 추출된 DE 특징은 서로 다른 감정 하에서 유의한 차이가 있음을 알 수 있다.
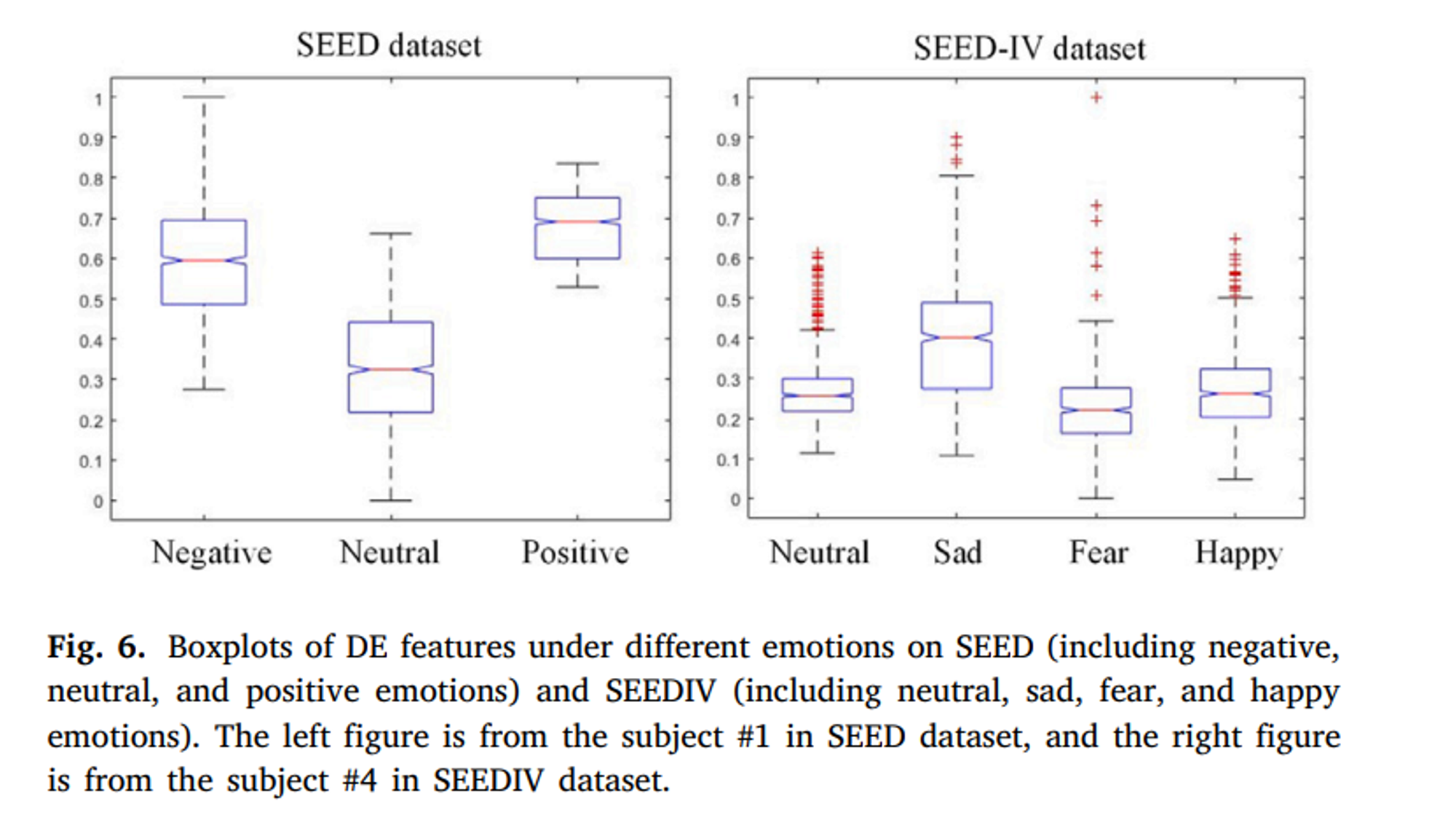
다른 감정의 평균 DE Feature 값이 서로 다른 분포를 보여준다.
3.4 Results and Analysis
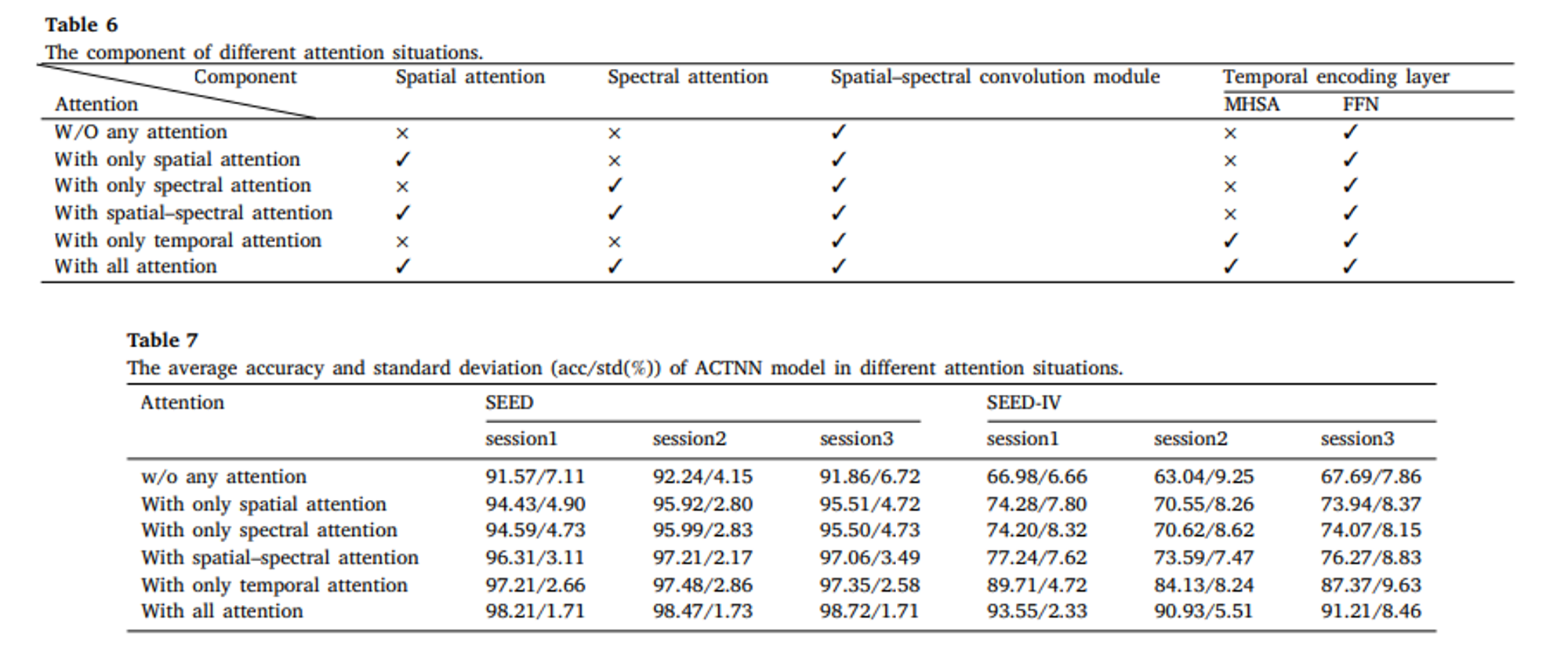
Table 6는 각각의 attention 상황의 구성요소이다. Table 7은 각각 다른 어탠션 매커니즘 하에서 얻어지는 평균 정확도와 표준 편차다.
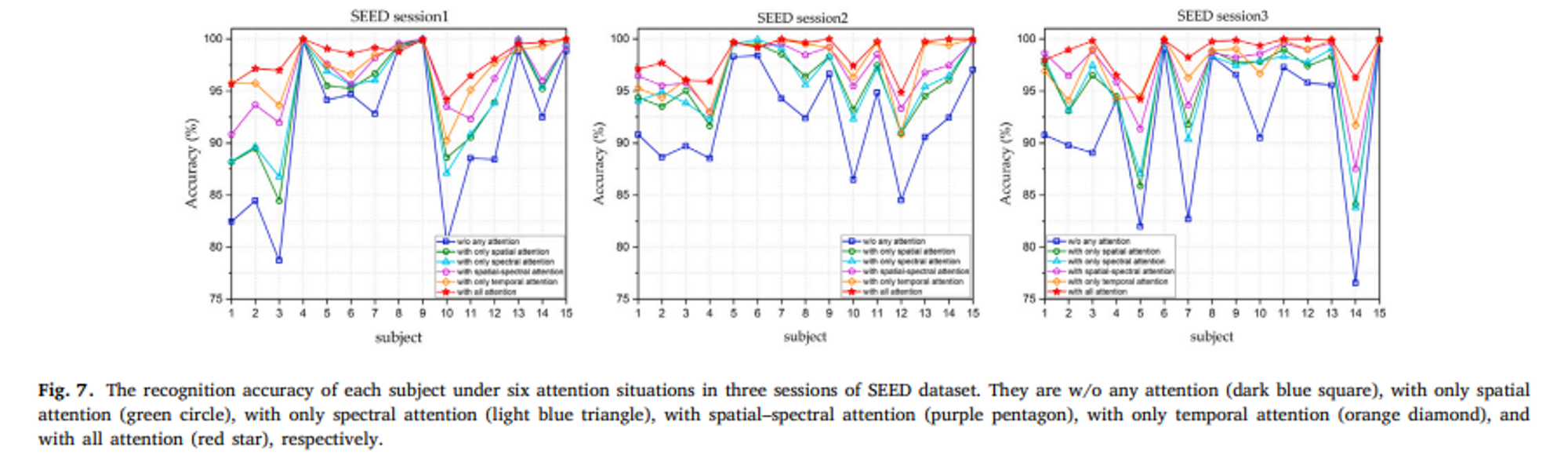
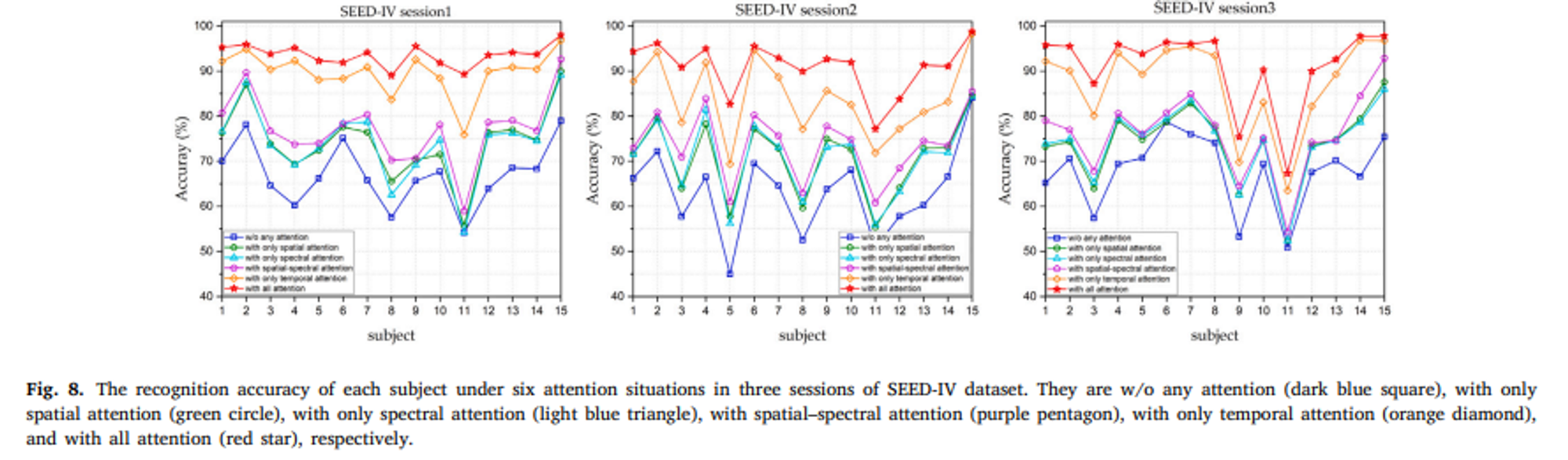
어떠한 Attention도 사용하지 않았을 경우 남색 그래프와 같이 정확도가 가장 낮았다.
전체적으로 spatial-spectral attention보다 temporal attention만을 적용했을 때 우수한 성능을 달성했다.
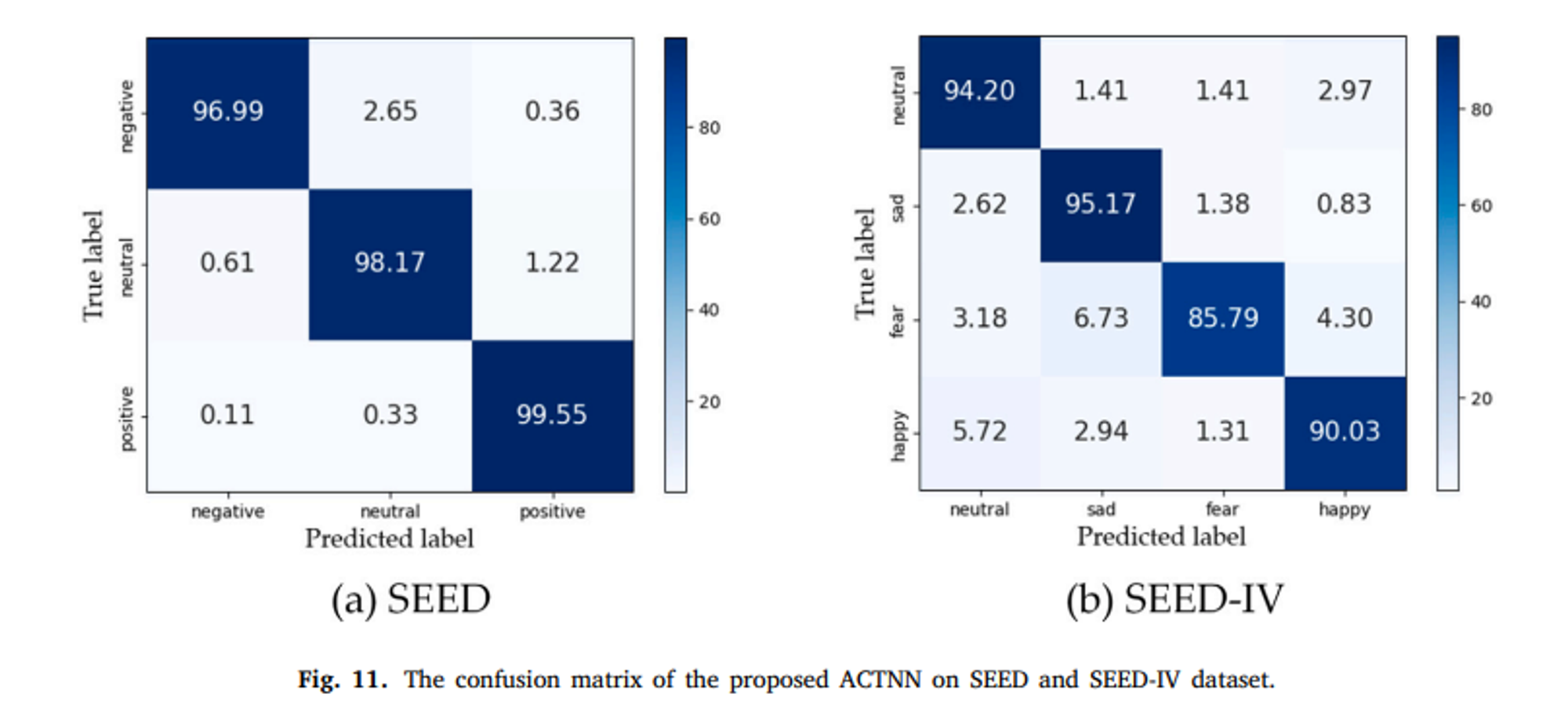
SEED와 SEED4 데이터 세트에서 ACTNN이 얻은 혼란 행렬은 다음과 같다. SEED의 경우 ACTNN이 긍정적인 감정에 대해 가장 좋은 분류를 달성할 수 있으며 중립적인 감정이 그 뒤를 이은다.
3.5 Comparative analysis betseen raw EEG signals and DE features
추출된 DE 특징이 ACTNN에 사용될 경우 간정 인식 수행 능력이 좋아진다는 것이 증명됐다. 따라서 Raw EEG 신호를 넣었을 때를 알아보고자 한다.
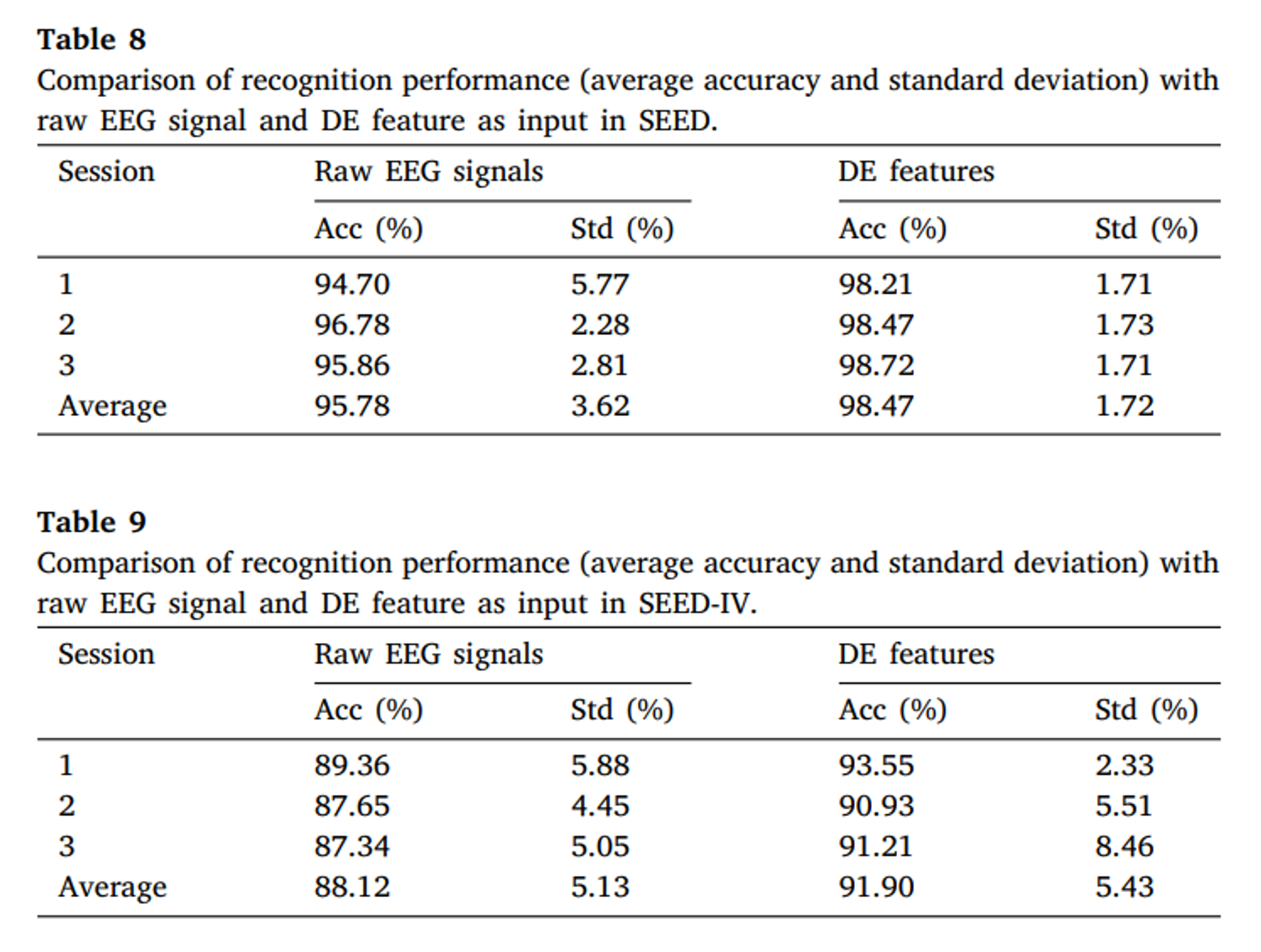
SEED 데이터에서 Raw EEG 신호를 넣었을 떄 정확도는 95.78이었는데 이는 DE 특징을 넣었을 때보다 2.69% 더 적다. 유사하게, SEED4 데이터에서는 88.12으로, 3.78% 적다.
이를 통해 DE Features가 복잡한 범위를 더 잘 받아들이고 더 효과적인 감정 정보를 얻는다는 것을 알 수 있다.
3.6 Analysis of spatial and spectral attention mask
Spatial and spectral attention maks를 시각화하였다. Attention Mask는 학습 후 중요 전극 또는 주파수 대역에 동적으로 할당되는 데이터 기반 Attention 가중치 세트다.
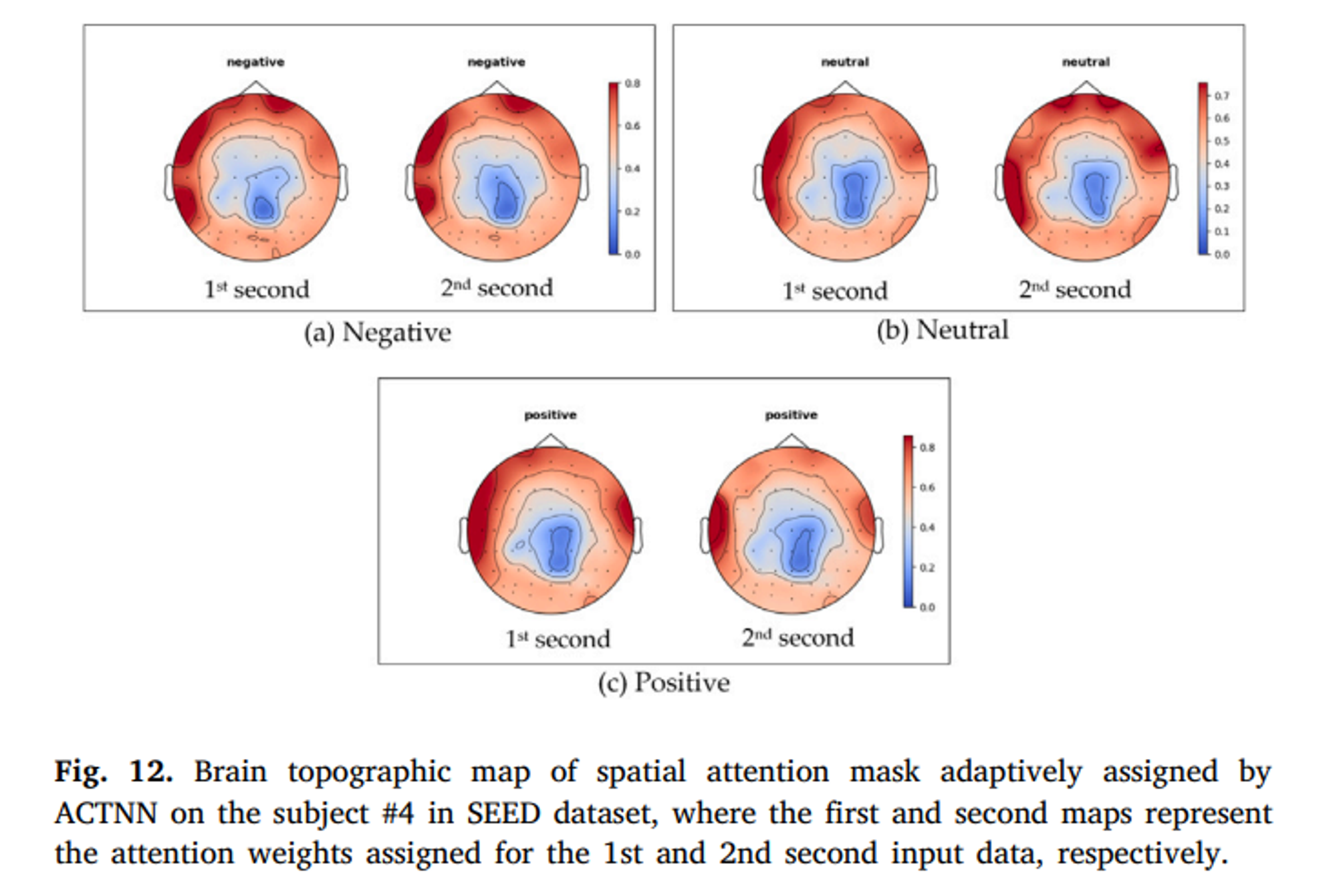
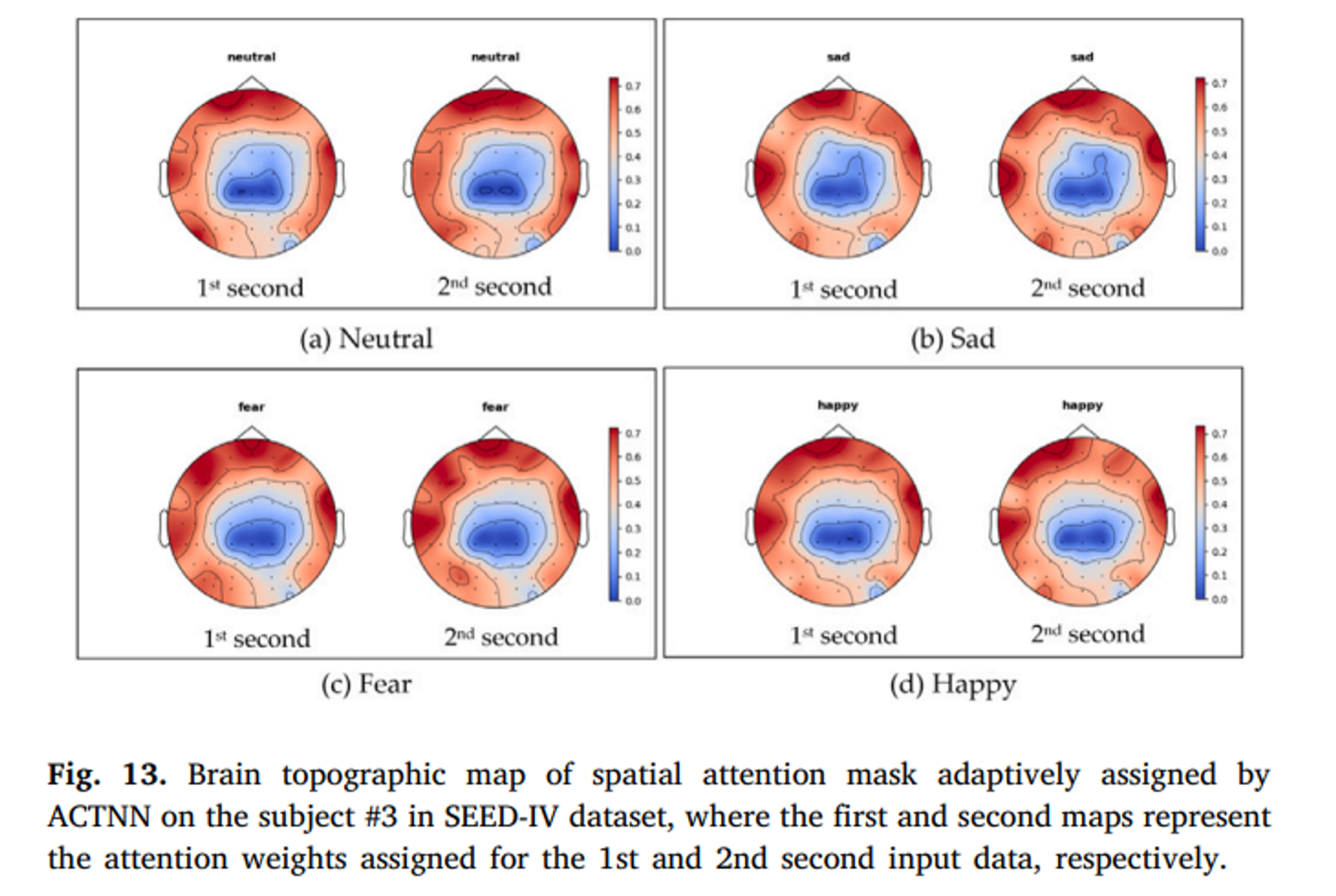
빨간색일 수록 더 가중치가 높으며 모든 감정의 Attention 가중치가 주로 전전두엽과 측두엽에 분포되어 있음을 알 수 있다.
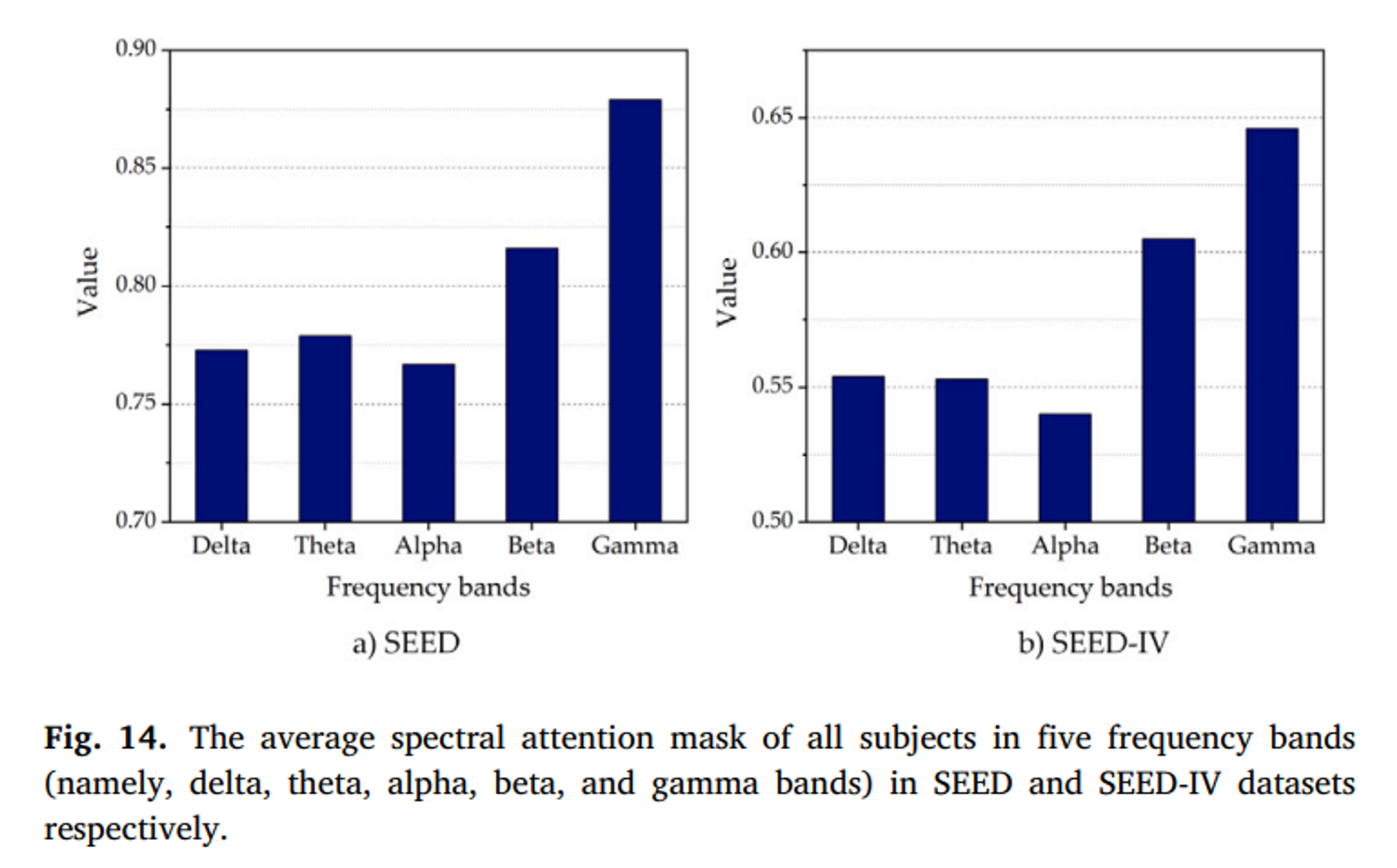
모델은 감마 대역에 최대 어텐션 가중치를 할당했다. 감마(Gamma) 대역의 뇌파가 사람의 감정과 더 관련이 있을 수 있음을 나타내며, 이는 기존 연구와 일치한다. 이에 감마 대역의 기능은 재보정 후 지속적으로 향상되었으며 이는 전반적인 인식 성능 향상으로 이어졌다.
🍦 대역에 대한 부분을 우리가 조정하는 방법? 감마 대역의 기능 재조정 방법
감마 대역은 일반적으로 30-100Hz의 주파수를 나타낸다.
1. 주파수 필터링 : 감마 대역 신호를 강조하거나 더 강하게 학습하도록 유도
2. 감마 대역 신호를 별도로 추출하여 특징으로 강화하기
⇒ SEED data 확인…
3.7 Method Comparison
원래 의료 이미지 분할에 사용되었던 새로운 공간적, 스펙트럼적 어텐션 매커니즘을 더 가볍고 효과적으로 사용하였다는 점에 의의가 있다.
해당 방법은 SST-EmotionNet, 3DCNN&PST, 4D-aNN에도 설계되었으나 여러 convolution block에 어탠션 메터니즘을 내장하는 것이 아니라 convolution 모듈 입력 부분에만 적용함으로서 연산량을 줄였다.
4. Discussion
- ACTNN의 더 나은 뇌파 감정 인식 성능은 CNN 기반과 트랜스포머 기반 모듈의 조합에 기인한다.
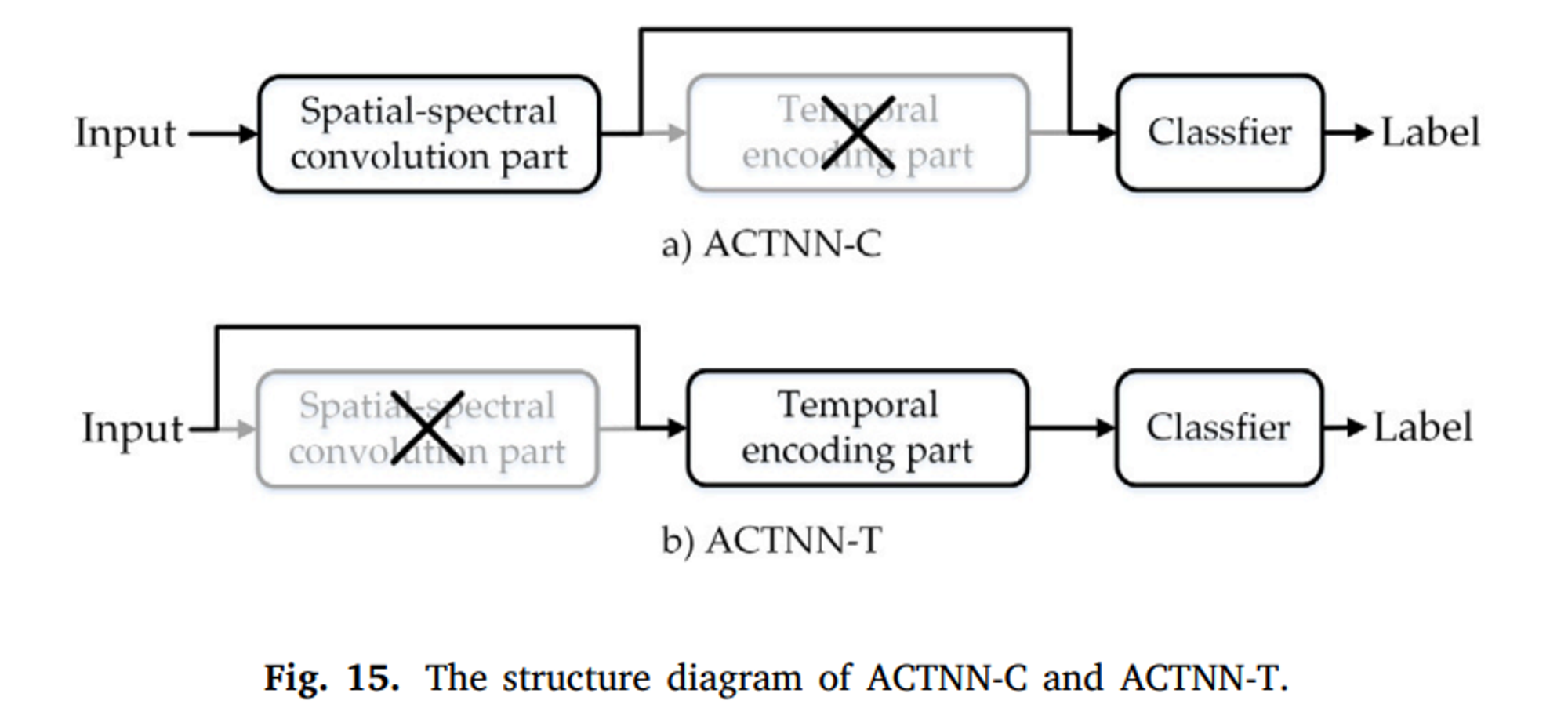
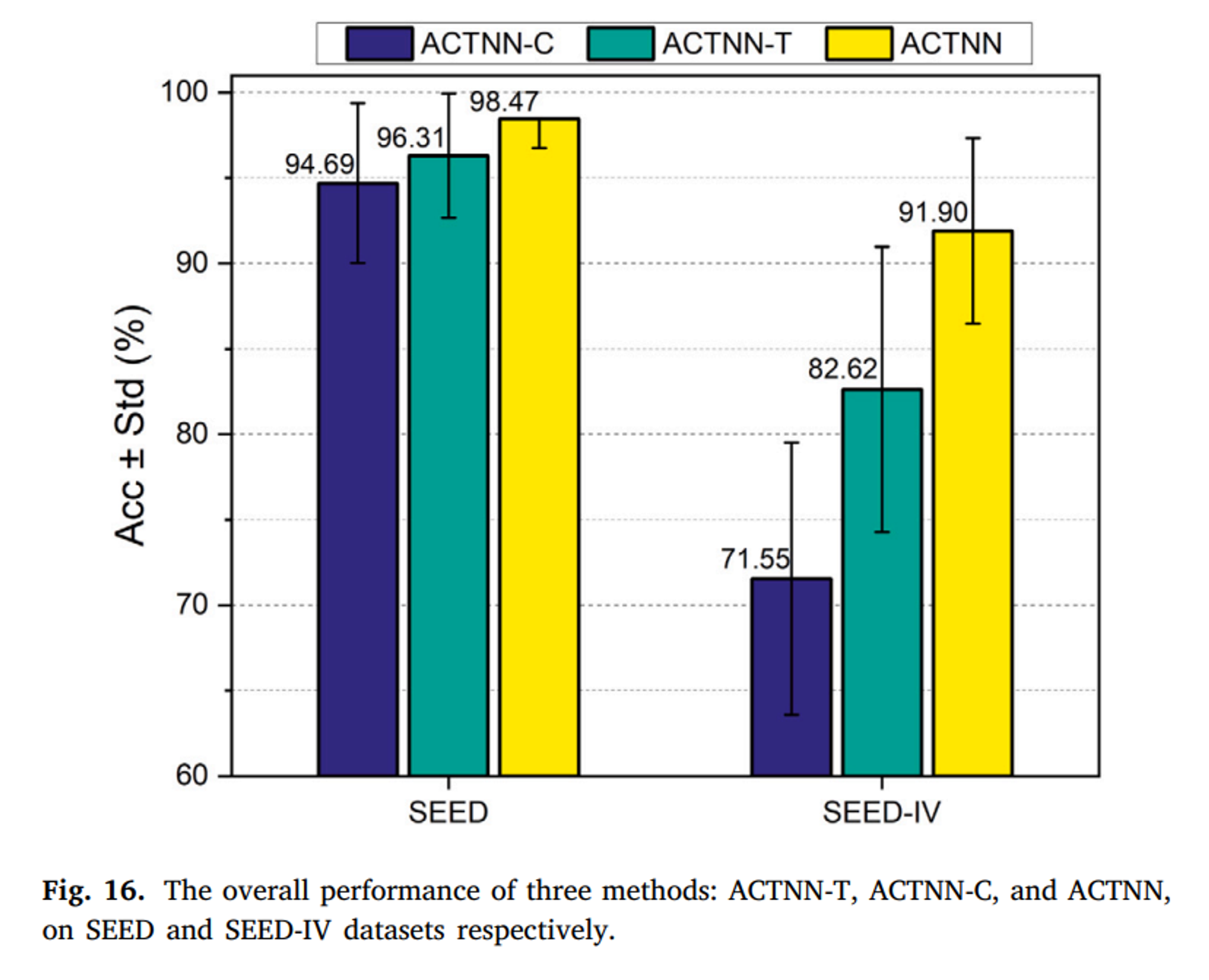
이를 검증하기 위해 Ablation 실험을 수행했다. ACTNN의 핵심 부분인 공간 스펙트럼 Convolution 부분과 시간 인코딩 부분을 제거하여 ACTNN-T와 ACTNN-C를 얻었고 해당 결과는 Fig16과 같다.
(ACTNN-T는 시간 인코딩 부분과 완전 연결 계층, ACTNN-C는 공간-스펙트럼 주의 분기, 공간-스펙트럼 컨볼루션 모듈 및 완전 연결 계층으로 구성된 공강-스펙트럼 컨볼루션 부분을 포함함)
또한 공간 및 스펙트럼 어탠션 마스트 분석을 통해 가중치 분포는 뇌의 전전두엽 및 측두엽과 뇌파 신호의 감마 대역의 활동이 사람의 감정과 관련이 있음을 보여준다.
보완할 점
각 피험자의 세션의 뇌파 데이터에 대해 광범위한 실험을 진행했다. 동일한 자극 물질과 시간에 대해 같은 피험자의 정서 활성화 상태가 다르므로 수집되는 뇌파 신호의 분포가 다르다. 때문에 향후 모델의 일반화 능력 향상을 위해 피험자 독립적인 교차 세션 실험을 수행해야 한다.
5. Conclusion
ACTNN의 주요 특징은 CNN 기반 모듈과 Transformer 기반 모듈을 새로운 방식으로 연결한다는 것이다. 이로써 공간적, 스펙트럼적, 시간적 정보를 효과적으로 통합한다.
SEED 데이터셋에서 98.47%, SEED4 데이터셋에서 91.90%의 평균인식도를 달성했으며 이는 최고 성능이다.
Ablation 실험 결과 시간적 인코딩 부분(ACTNN-T)가 공간-스펙트럼 합성곱 부분(ACTNN-C)보다 더 나은 성능을 보였다.
그러나 향후에는 일반화 성능 개선이 필요하며 논문에서는 피험자 독립적 실험과 교차 세션 실험을 통해 모델의 일반화 능력을 향상할 것이라 한다.
모델 정리
🍦 모델 정리
1.EEG 신호 획득(EEG signals acquisiton)
- 실험자는 감정을 유발하는 자극을 화면으로 받고, 이때 EEG 신호가 전극을 통해 기록됨
- 여러 개의 전극이 머리 위에 배치되어 있으며 EEG 시계열 데이터로 나타남
전처리 및 분할(Preprocessing and Segmentation)
- 여러 개의 세그먼트로 분할해 분석에 적합한 형태로 데이터 준비
특징 추출(Feature Extraction)
- 각 전극에서 측정된 신호는 다양한 주파수 대역(리듬)으로 분할되며 이 리듬별로 각 전극의 데이터를 모아 특징맵(feature map)으로 표현
- 신호의 주파수 대역과 공간적 위치(전극별)를 고려한 주요 특징을 추출해 감정 상태를 분석할 수 있는 기초 데이터 제공
공간 투영(Spatial projection)
- 각 시간 세그먼트 별로 공간적 투영이 이루어짐. 3차원 텐서로 변환
공간 및 스펙트럼 주의 메커니즘(Spatial and Spectral Attention Branch)
- 스펙트럼 주의
- 공간 주의
→ 중요한 주파수 대역과 전극 위치에 더 큰 가중치를 부여
공간-스펙트럼 컨볼루션(Spatial-Spectral Convolution Part)
- 각각의 시간 세그먼트에 대해 공간적 및 스펙트럼 정보를 통합해 특징 맵 생성
시간 인코딩(Temporal Encoding Part)
- 각 시간 세그먼트별로 추출된 특징 맵은 시간 인코딩 레이어로 입력됨
분류기(Classifier)
- 완전 연결층(Fully-connected layer)와 소프트맥스(softmax) 레이어로 전달되어 감정 상태를 긍정, 중립, 부정 중 하나로 예측함(1, 0, -1)
