Background
Visualization
- CNN을 시각화한다는 것은 각 Layer들의 Filter들의 역할을 눈으로 볼 수 있게 하는 것
- FIlter를 시각화함으로써 CNN이 효과적으로 작동하는지 관찰
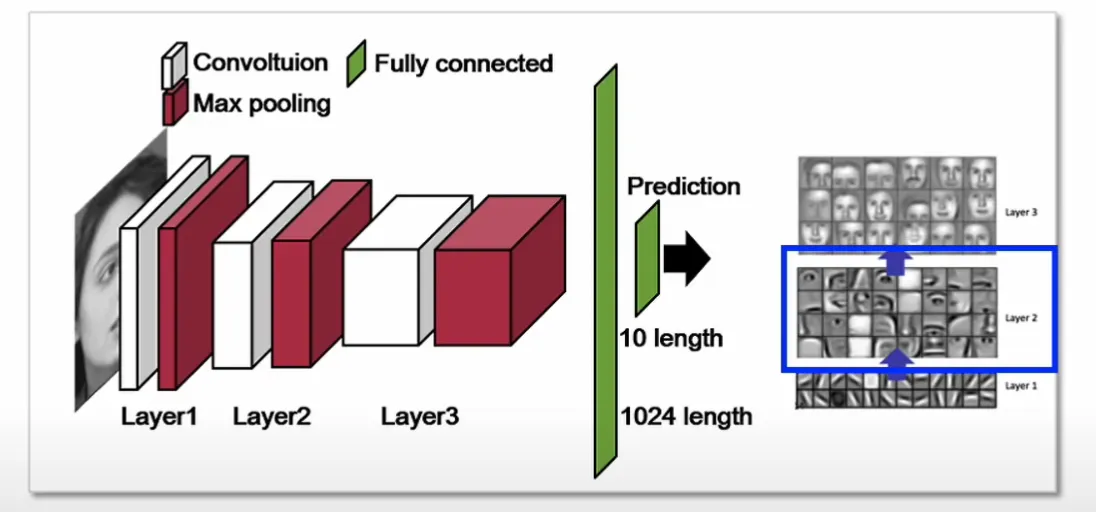
- Layer3에서 Feature Map의 특정값이 상당히 크다면 deconvolution을 이용해 feature map의 값이 계산되기까지 거쳐왔던 길을 역추적하여 input image의 어떤 부분을 자극시켰는지 확인할 수 있음
- ex. Layer2에서 특정 값을 역추적했더니 눈이 나왔다 → 사람의 얼굴에서 눈이 해당 필터를 자극하고, 해당 필터는 눈의 특징을 잡아내는 역할을 한다는 것
Deconvolutional Networks
- 컨볼루션의 효과를 반전시키는 수학적 연산

- convolution은 적분이 들어가는 연산이기에 input이 없는 상태에서는 역연산이 어려움
Deconvolution
- Convolution 연산할 때 사용한 Kernal과 Output을 알고 있어야 하며, 역연산을 통해 Input을 근사하는 것이 목적
- 주로 Feature Map을 3차원 이미지로 재구성하여 시각화하는 용도로 사용
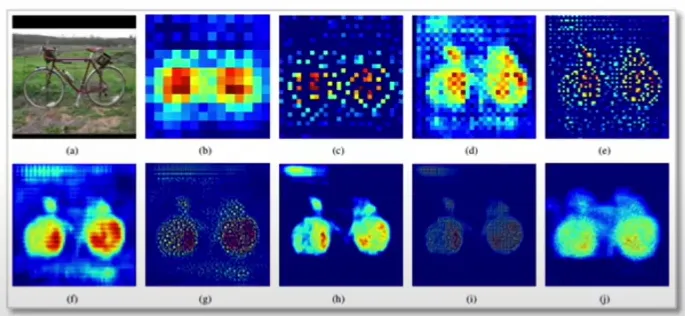
- Activation Function을 거쳤기 때문에 활성화된 부분만 시각화하므로 예측의 근거를 찾는데 활용
Transposed Convolution
- Convolution Layer와 사용하는 Kernel을 공유하는 것이 아닌 학습을 통해 Kernel을 찾아가는 것이 목적
- 주로 GAN, Segmentation Task에서 이미지의 공간적인 크기를 증가시키기 위한 목적으로 사용됨
Abstract
많은 CNN 모델은 ImageNet에서 인상적인 분류 성능을 보이지만 왜 잘 수행되는지, 어떻게 개선할 수 있는지에 대한 명확한 이해가 없다. 이에 본 논문에서는 중간 단의 Feature Layer와 분류에 대한 인사이트를 제공하는 새로운 시각화 기법 소개하였다.
CNN Architecture를 구성하는 각각의 중간 Layer부터 최종 Classifier까지 입력된 이미지로부터 특징이 어떻게 추출되고, 학습이 되어 가는지 시각화를 통해 분석하는 방법을 제시하였고, 시각화를 통한 개선 사항을 적용한 모델은 기존의 모델(AlexNet 2012)보다 뛰어난 성능을 달성하였다.
1. Introduction
모델의 모든 Layer에 대한 각각의 Feature Map들을 자극하는 입력을 드러내기 위한 시각화 기법을 연구했고, 시각화는 학습 동안에 발생되는 feature의 진화를 관측할 수 있게 해주며 모델의 잠재적인 문제를 진단할 수 있게 해준다.
이들이 제안하는 시각화 기법은 Zeiler가 제안한 Deconvolution Network를 사용하여 입력 픽셀 공간에 feature activation을 투영시키는 방법이다. 분류를 하는데 어느 부분이 중요한 역할을 하는지 알기 위해 이미지의 일부를 가리고 분류기의 출력이 이에 얼마나 민감하게 변화하는지 분석하는 연구 역시 수행한다.
1.1 Related Work
네트워크에 대한 직관을 얻기 위해 시각화를 많이 수행하나, 대부분이 픽셀 공간으로 투영이 가능한 첫 번쨰 레이어로 제한된 연구였다.
-
Erhan et al.(2009) : 각 유닛의 활성화를 극대화하기 위해 이미지 공간에서 경사 하강법을 사용하는 방법을 제안하였다.
→ 모델의 특정 유닛에 대해 반응(activation)을 최대화하려면, 이 유닛이 가장 강하게 반응하는 “이상적인 자극”(최적의 입력 이미지)을 찾아야 한다. 이를 위해 입력 이미지를 점차 수정하면서 해당 유닛의 활성화 값을 최대화하는 이미지로 만들어가는 gradient descent 과정을 거친다.
→ 이때 최적의 입력 이미지를 찾기 위해서는 초기 이미지 설정이 중요했고 유닛의 불변성에 대한 정보는 제공하지 않는다는 단점이 있었다.
-
Le et al.(2010) : 이를 보안하기 위해 주어진 유닛의 헤시안을 수치적으로 계산해 불변성을 일부 해석하고자 하였다.
→ 그러나 높은 레이어에서는 불변성이 매우 복잡해지기 때문에, 단순한 2차 근사로는 제대로 표현되지 않는 한계가 있다.
-
본 논문에서는 비모수적 접근법(non-parametric)을 통해 불변성을 시각화하는 방법을 제안한다.
학습 데이터셋에서 특정 피처맵을 활성화시키는 패턴을 직접 보여주며, 단순히 입력 이미지의 일부를 잘라낸 것이 아니라, 각 패치 내의 구조를 위에서 아래로 투사하여 해당 피처맵을 자극하는 요소를 명확하게 드러낸다.
→ 별도의 수학적 모델(ex. 수식이나 함수)을 이용해 불변성을 정의하지 않고, 학습 데이터에서 관찰한 활성화 패턴 자체를 통해 직관적으로 불변성을 파악
2. Approach
본 논문에서는 AlexNet(Fully Supervised ConvNet Models)을 기반으로 모델을 구현했다.
2.1 Visualization with a Deconvnet
convnet의 작동 원리를 이해하기 위해서는 중간 layer의 feature activity를 해석해야 하기 때문에 이러한 활동을 입력 픽셀 공간에 다시 매핑하여 Feature Map에서 어떤 입력 패턴이 활성화를 유발했는지 보여주는 방법을 제시한다.
Deconvolutional Network를 활용해 feature map내에서 주어진 activation이 어떠한 input pattern에서 비롯되었는지 확인하는 것이다.
Deconvnet은 Convnet과 동일하게 filtering과 pooling으로 구성되지만 이와 반대로 작용한다.
CNN의 max pooling 대신 unpooling이, activation 대신 rectification이, conv 대신 deconv가 수행된다.
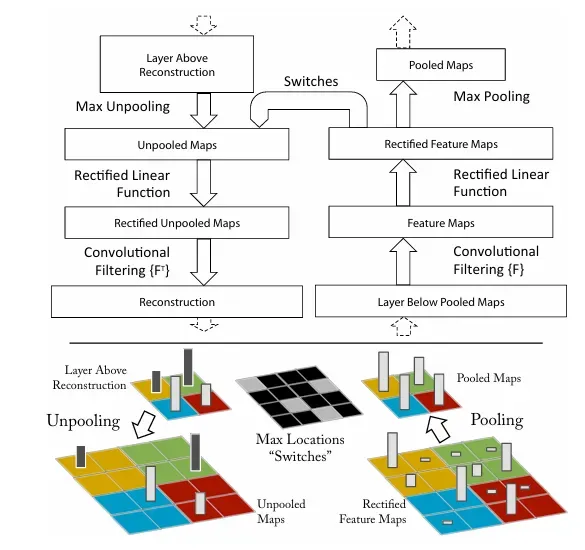
- Convnet을 검사하기 위해 각 레이어에 Deconvnet을 연결하여 이미지 픽셀로 돌아가는 연속적인 경로를 제공한다.
- 입력 이미지가 CNN에 전달되면, 각 레이어의 특징이 계산된다. 특정 레이어에서의 활성화 상태를 해석하고자 할 때, 해당 레이어의 활성화 외에 다른 모든 활성화를 0으로 설정하여 deconvnet에 입력으로 전달한다.
- Deconvnet은 Unpooling, Rectification, Filtering을 거쳐 특정 활성화 상태를 역으로 재구성해 입력 이미지의 픽셀 공간으로 되돌린다.
📌 재구성이란?
CNN이 입력 이미지의 특정 부분을 어떻게 구분하고 있는지 시각화하는 것.
Unpooling
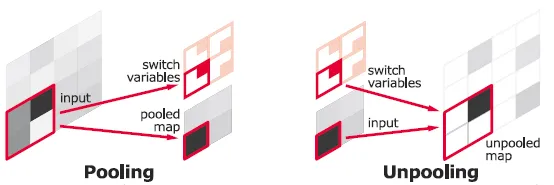
Convnet에서 Max pooling 연산은 주변에서 가장 강한 자극만을 다음 단계로 전달한다. 때문에 다음 단계에서 어느 신호가 가장 강한 자극을 가지고 있었는지 파악하기 힘들다.
본 논문에서는 Switch라는 개념을 도입하였다. Switch는 Max pooling 전에 가장 강한 자극의 위치 정보를 저장해놓는 것으로, Unpooling을 시행할 때 Switch 정보를 활용해 가장 강한 자극의 위치로 찾아갈 수 있게 된다. (단, 가장 큰 값의 위치 정보만 기록하기 때문에 그 외의 값들은 복원하지 않는다.)
Deconvet에서 Unpooling 연산은 이러한 switch를 사용해 위 레이어의 재구성을 적절한 위치에 배치해 자극의 구조를 보존한다.
Rectification
Convnet은 Feature Map이 항상 양수가 되도록 하는 ReLU 비선형 함수를 사용한다.
각 layer의 적절한 feature reconstructions 또한 항상 양수여야 하기 떄문에 ReLU를 사용한다.
음수 부분은 0이 되는 것인데, 본 논문에서는 우리가 원하는 자극(stimulus)을 찾는데 영향을 끼치지 않기 때문에 문제가 되지 않는다고 한다.
Filtering
CNN은 학습된 필터를 사용해 이전 레이어의 Feature Map을 합성곱한다.
Deconvnet에서는 이 필터를 뒤집어(transposed) 적용하여 반대로 진행한다.
📌
transposed convolution
input data를 abstract spatial representation으로 compress하기 위해 convolution 연산을 사용한 후, 이를 다시 decompress하는 경우에 사용됨.
- convolutional auto-encoder의 복원 과정, semantic segmentation 분야
3. Training Details
- ImageNet 데이터셋의 분류 수행을 위해 AlexNet 모델을 사용하며 ImageNet 2012 데이터셋을 기반으로 학습
- 256X256 으로 먼저 cropping 수행 후, 224X224로 sub cropping을 수행하였다.
- 학습하는 도중 첫 번째 레이어의 시각화를 해보면 일부가 dominate하는 것을 확인할 수 있는데,이를 해결하기 위해 conv layer의 각 filter를 renormalize하였다.
4. Convnet Visualization
Deconvet을 사용해 ImageNet의 Validation set 에 대해 Feature activation을 시각화하였다.
Feature Visualization

해당 그림은 각 Layer별 얻은 Feature Map에서 가장 강한 특징 9개와 그에 해당하는 원본 이미지다.
Layer1에서는 색, edge, corner와 같은 낮은 레벨의 특징들을 추출하는 것을 볼 수 있ek.
이후 Layer3에서는 어느 정도의 사물을 포착하고 Layer4, 5로 갈 수록 더 세밀한 특징들을 잡아내는 것을 볼 수 있다.
(Layer4 : 사물이나 개체의 일부분을 보여줌. 개의 얼굴이나 새의 다리)
Feature Evolution during Training

Layer가 깊어질수록 Feature를 시각화한 결과, 학습 Epoch이 어느 정도 진행돼야 함을 알 수 있다.
[1, 2, 5, 10, 20, 30, 40, 64] epoch에서 각 layer의 변화를 나타낸 것으로, 하위 layer에서는 비교적 적은 epoch만에 수렴하지만, 상위 layer의 경우 40~50 이상의 많은 epoch를 학습해야 수렴함
Feature Invariance
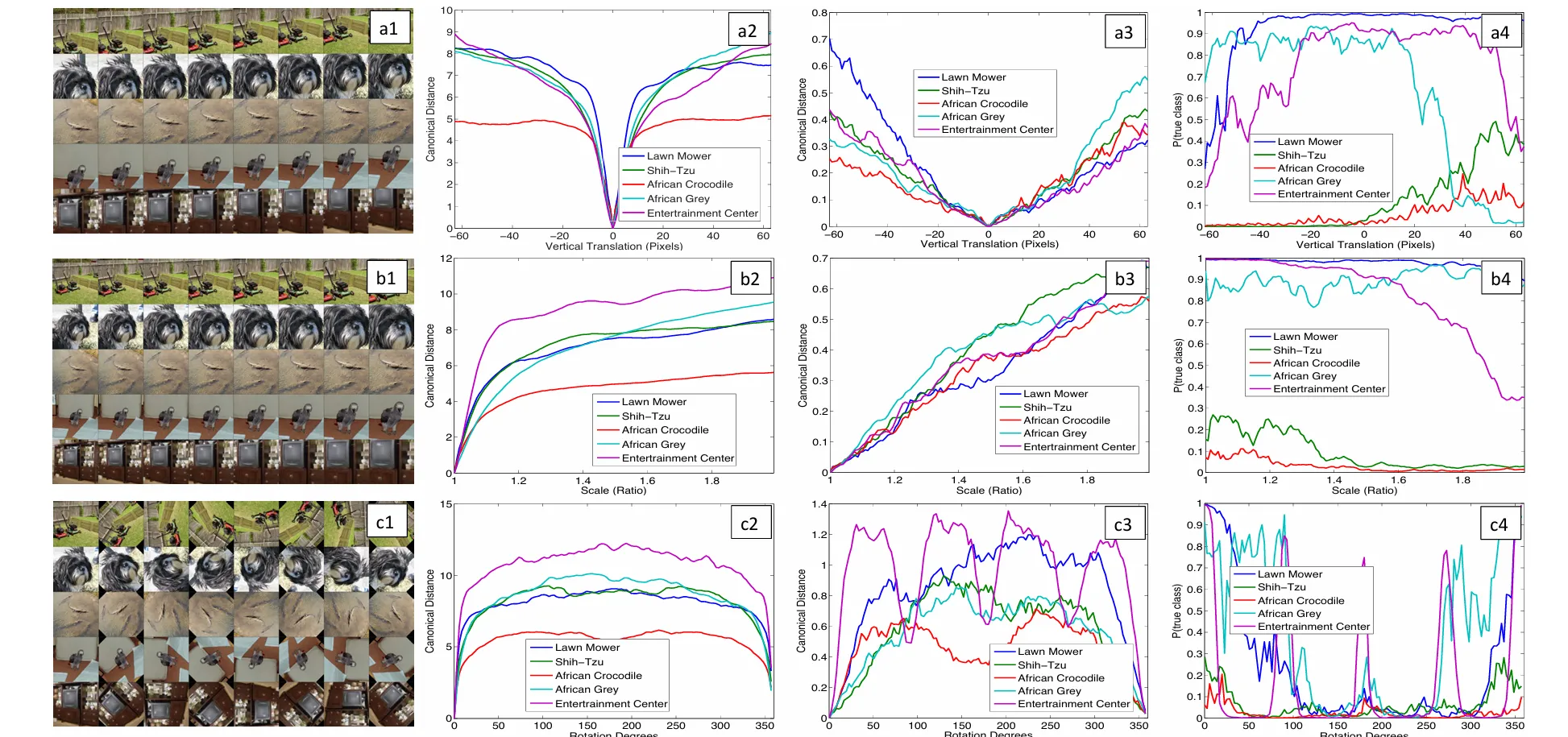
(a)는 vertical translation 했을 때, (b)는 Scaling 했을 때, (c)는 Rotation 했을 때 Invariance한 특성을 확인하는 것이다.
📌Feature Invariance
input image가 변해도 모델의 output은 변하지 않는 정도
5개의 샘플 이미지에 대해 위치 이동(translation), 크기 변환(Scaling), 회전 변환(rotation)을 수행하였고 모델의 가장 상단 및 하단인 layer1과 layer7 각각의 feature vector와 변환을 하지 않은 이미지에 대한 feature간의 유클리드 거리를 확인하였다.
- a2~c2 : layer1에 대해 변환하지 않은 이미지의 feature과의 유클리안 거리
- a3~c3 : layer7에 대해 변환하지 않은 이미지의 feature과의 유클리안 거리
- a4~c4 : 이미지가 변환되었을 때 각 이미지를 옳게 분류할 확률. 값이 높을 수록 모델이 해당 클래스를 더 확신함
layer1에서는 색상, 엣지 등 단순한 영역을 나타내기 때문에 작은 변화에도 큰 차이가 발생(a2)하지만 layer7에서는 추상적이 특성을 학습하기 때문에 변환에 덜 민감하게 반응(a3)하는 것을 볼 수 있다.
4.1 Architecture Selection

Feature Map 시각화를 통해 모델의 어떤 부분에 문제가 있으며, 어떻게 개선해야 할지 알아볼 수 있다.
첫 번째 layer filter는 중간 frequency information이 거의 없이 매우 높거나 낮은 frequency information이 혼합된 형태(b,d)이다.
이는 stride 크기가 4로 너무 커 layer2의 시각화에서 Aliasing이 발생 (흐릿하게 특징을 잘 못 잡아내는 것)하는 것으로 아래와 같이 구조를 바꾼 결과(c,e) 기존 모델에 비해 Aliasing 없이 깨끗한 것을 볼 수 있었다.
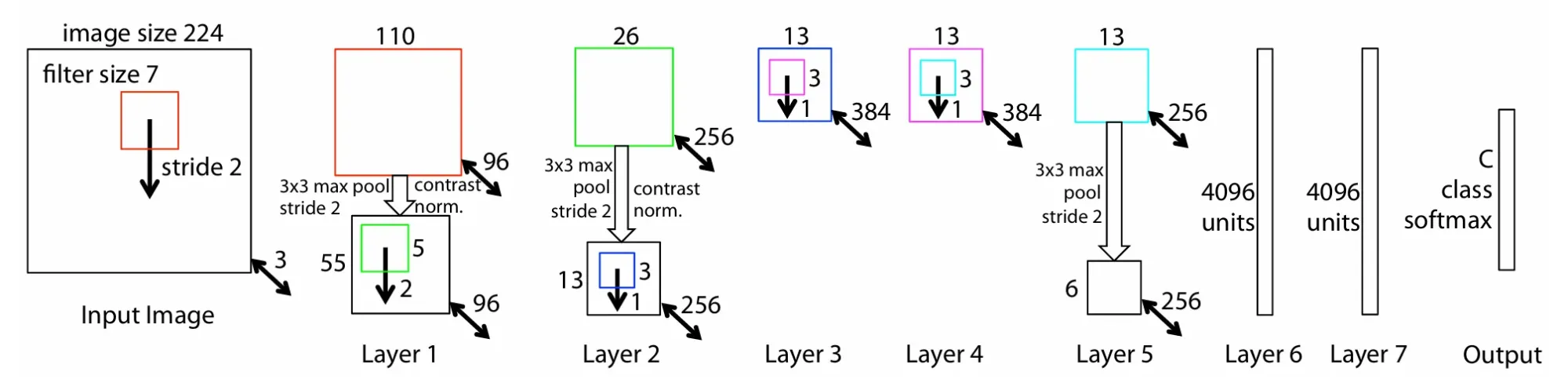
AlexNet의 첫 번째 layer의 구조를 변경한 것으로 먼저 1) Layer 3, 4, 5에서 사용된 Sparse Connection을 Dense Connection으로 대체하고 2) layer1의 filter size를 (11X11)에서 (7X7)로 변경하였으며 3) conv 연산의 stride 크기를 4에서 2로 감소시켰다.
새로운 아키텍쳐를 통해 layer1, layer2 feature에 더 많은 정보를 포함시켰으며(figure6의 c,e), 결과적으로 분류 성능을 향상시킬 수 있었다.
4.2 Occlusion Sensitivity
이미지 분류 모델이 이미지 내 객체의 위치를 실제로 파악하는지, 혹은 주변의 context를 통해 분류하는 것인지 확인하기 위해, 입력 이미지의 다양한 부분을 회색 사각형으로 가려가며 분류기의 출력을 모니터링하는 실험을 수행했다.
→ 맥락만을 활용해 분류를 수행하는지, 혹은 정확한 물체의 위치를 찾아내어 분류를 수행하는지!
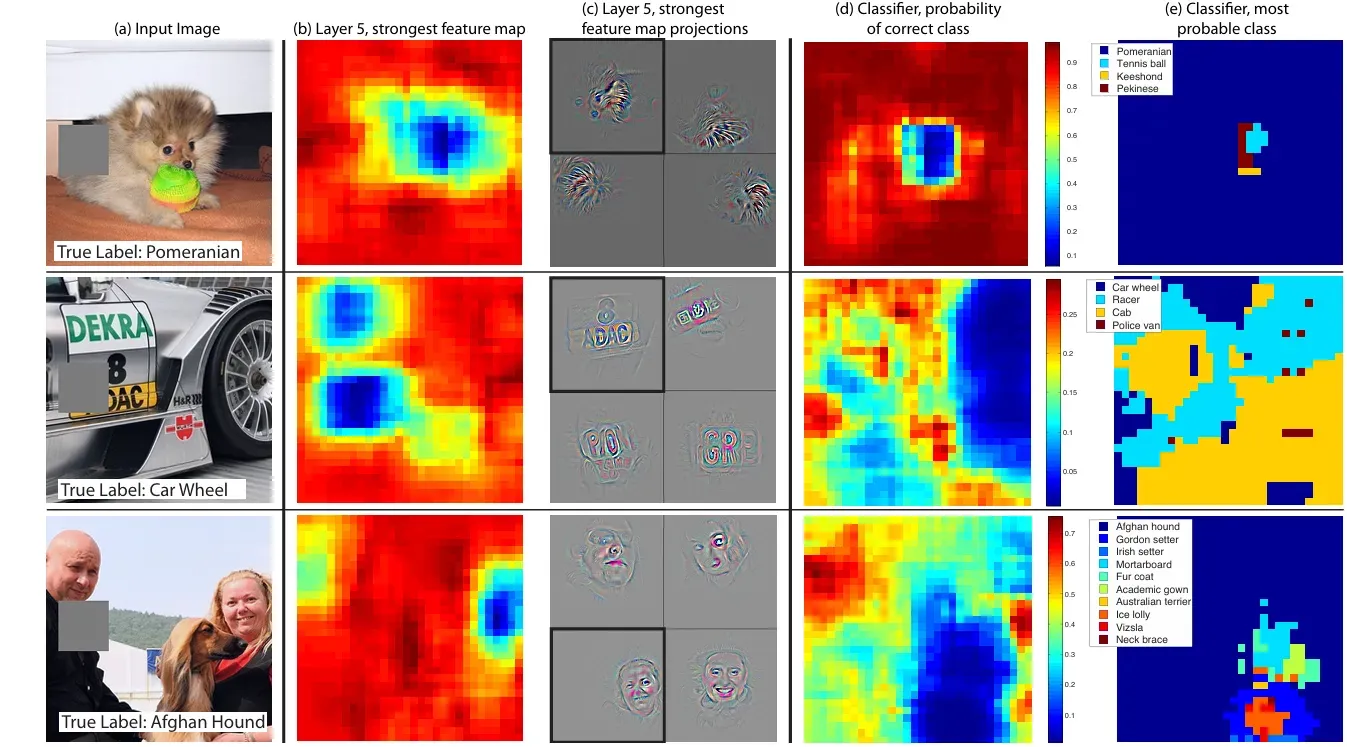
Figure 7
input image 내 객체가 회색 사각형에 의해 가려지면 layer5(fully-connected layer 이전에 있는 마지막 layer)의 feature map의 activity와 올바른 클래스를 예측할 확률이 모두 현저히 떨어졌다. 이는 모델이 객체를 잘 localize하는 것을 의미한다.
첫 번째 포메라니안 이미지의 예시에서는 개의 얼굴을 가릴 경우, feature map의 activity도 가장 덜 활발하며(파란색), 올바른 클래스를 예측할 확률도 떨어졌다. 이는 모델이 얼굴 부분을 주요 특징으로 인식하고 있다는 의미다.
실험 결과, 객체가 가려지면 정답 클래스에 대한 확률이 크게 떨어지는 것을 확인할 수 있었다.
이를 통해 모델이 단순히 주변 맥락이 아닌, 실제로 장면 내 객체의 위치를 인식하고 있음을 알 수 있다.
4.3 Correspondence Analysis

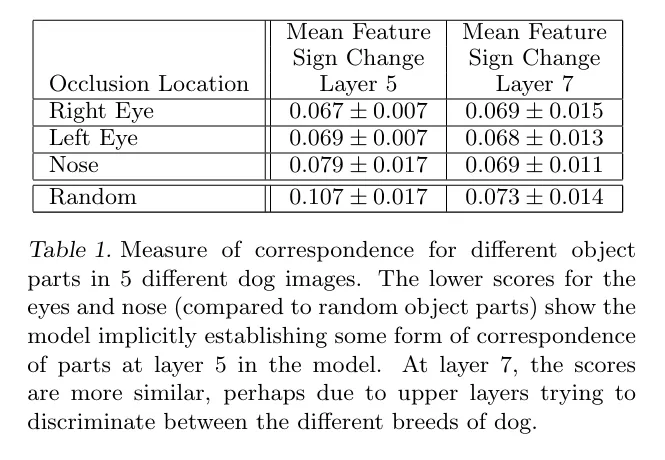
- Co1 : 원본 이미지
- Col 2, 3, 4 : 각각 오른쪽 눈, 왼쪽 눈, 코를 가림
5개의 서로 다른 개 이미지에서 서로 다른 물체 부분의 일치도를 측정하는 것으로 Mean Feature Sign Change는 해당 부위가 가려졌을 때 레이어 5와 7에서 feature의 값이 얼마나 변하는지를 의미한다.
Layer 7에서는 모든 부위에서 변화량이 비교적 유사해지는데, 레이어가 높아질수록 모델이 강아지의 품종을 구분하려고 하면서 개별 부위의 중요도가 낮아지고, 전체적인 패턴을 바탕으로 구분하려고 한다는 것을 보여준다.
5. Experiments
5.1 ImageNet 2012
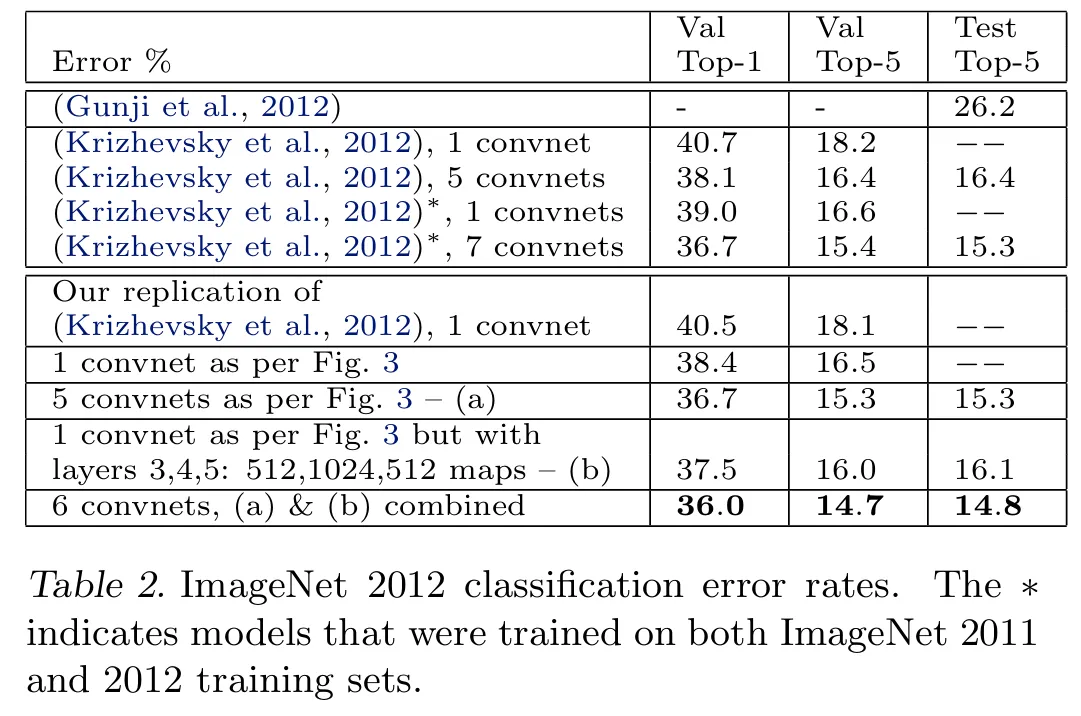
- Val Top-1 : 검증 세트에서 모델이 최상위 예측에서 정답을 맞추지 못한 비율
- Val Top-5 : 검증 세트에서 모델이 상위 5개의 예측 중 정답이 포함되지 않은 비율
- Test Top-5 : 테스트 세트에서 Top-5 오류율
해당 표는 ImageNet 2012 데이터셋에 대한 분류 오류율을 비교한 것이다.
ImageNet 2012 데이터셋은 1,000개의 카테고리에 대해 130만 개의 훈련 이미지, 5만 개의 검증 이미지, 10만 개의 테스트 이미지로 구성되어 있다.
AlexNet을 정확히 동일한 구조로 복제한 결과 원본 논문과 0.1% 이내로 비슷하게 나왔으며, 이후 4.1에서 변경한 것처럼 layer1에 7X7 필터를 사용하고 layer1과 2에 stride 2를 적용한 conv를 도입하였다.(Fig3)
여러 개의 모델을 앙상블한 결과 최종 데스트 세트 top-5 오류율은 14.8%로 최고 성능을 달성했다.
5.2 Feature Generalization
CNN 모델을 사용해 ImageNet을 학습한 후 다른 데이터셋(Caltech-101, Caltech-256, PASCAL VOC 2012)에 어떻게 일반화되는지 평가한다. 이를 위해 ImageNet 학습 모델의 레이어 1-7을 고정하고, 새로운 데이터셋에 대해 소프트맥스 분류기를 추가로 학습했다.
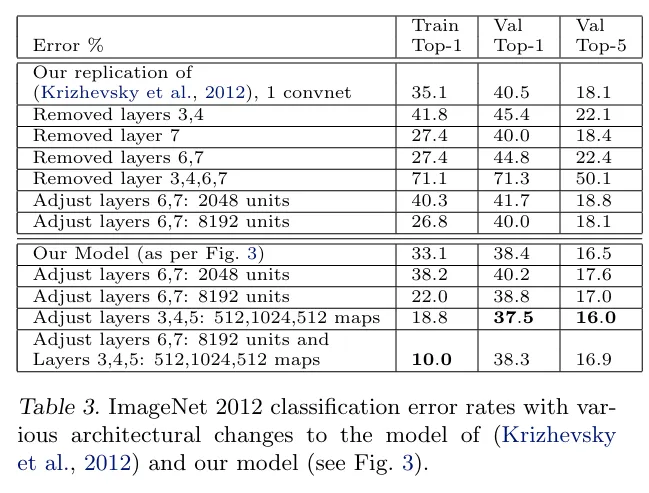
기존 모델 복제 후 Layer 별 제거 실험을 진행하였다.
- Caltech-101 데이터셋 : ImageNet으로 pre-trained 된 CNN 모델을 사용할 경우 비학습 모델보다 월등히 높은 성능을 보였다.
- Caltech-256 데이터셋 : 마찬가지로 높은 성능을 보였다.
- PASCAL VOC 2012 데이터셋 : 높은 성능을 보이지만 데이터셋 특성상 여러 객체가 포함된 이미지들이 많아, CNN 모델이 다소 어려움을 겪는 것으로 보인다.
해당 Feature를 일반화하여 다른 데이터에서도 사용할 수 있음을 확인하였다.
5.3 Feature Analysis(특징 분석)
CNN의 각 계층이 얼마나 구분력 있는 정보를 포함하고 있는지 분석.
Caltech-101과 Caltech-256에서 다양한 계층을 사용해 실험했으며, SVM과 소프트맥스 분류기를 활용해 각 계층이 가지는 특징의 분류 성능을 비교하였다.
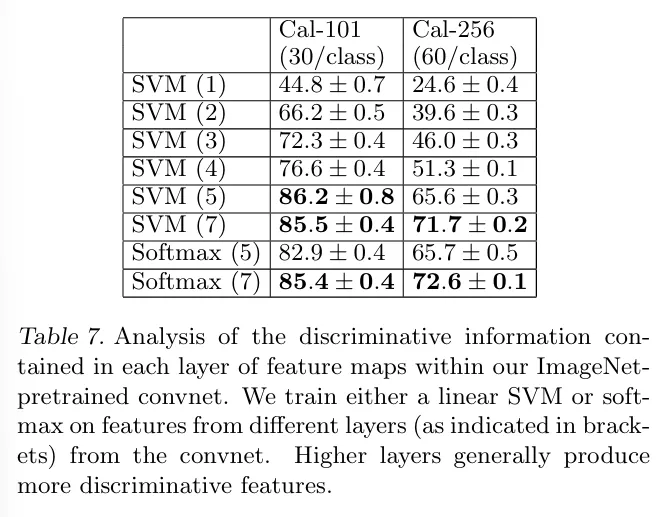
SVM(n)은 n번째 레이어의 특성을 사용한 분류기의 성능을 나타낸다. Cal-101과 Cal-256 둘 다 SVM(1)에서 SVM(7)로 갈수록, 즉 낮은 레이어보다 상위 레이어가 더 구분력 있는 특징을 학습하고 있음을 보여준다.
Network의 깊이가 깊어질 수록 더 강력한 Feature를 학습한다!
6. Discussion
CNN 모델을 이미지 분류 작업에서 다양한 방식으로 탐구한 결과는 다음과 같다
모델 시각화
- CNN 모델 내에서 이루어지는 activity에 대한 새로운 시각화 방법을 제안하여 CNN을 통해 추출한 features가 해석가능함을 보였다.
- 오히려 특징들은 계층을 올라갈수록 직관적인 속성을 가지며 구성성(compositionality), 불변성 증가(increasing invariance), 클래스 구분력(class discrimination) 같은 속성을 보여준다
가림 실험
모델이 이미지 분류를 위해 광범위한 장면의 맥락(scene context)만을 사용하는 것이 아니라, 이미지의 국소적(local) 구조에도 민감하다는 것을 입증했다.
Ablation test
이를 통해 네트워크의 최소 깊이가 모델 성능에 중요하다는 사실을 발견했다. 개벌적인 이어나 섹션보다 네트워크 전체의 깊이가 모델 성능에 더 큰 영향을 미친다.
일반화 성능
Caltech-101과 Caltech-256에서는 ImageNet 데이터셋과 유사성이 있어, 이전 최고 성능을 능가했다.
PASCAL 데이터셋에서는 성능이 약간 떨어졌지만, 사전 작업 없이도 최고 성능과 3.2% 이내의 차이를 기록했다.
이를 통해 ImageNet을 통해 훈련된 모델이 다른 데이터셋을 잘 일반화할 수 있음을 보여준다.
📌Conclusion
1. 이미지 분류를 위해 Large Convolutional Neural Network 여러 가지 모델을 탐색함
2. 모델 내의 활동을 시각화하는 새로운 방법을 제시함
- CNN 을 구성하는 각각의 중간 Layer부터 최종 Classifier까지 입력된 이미지로부터 특징이 어떻게 추출되고, 학습이 되어 가는지 시각화를 통해 분석하는 방법 제시
- 이러한 시각화를 사용하여 모델의 문제를 Debugging하여 더 나은 결과를 얻을 수 있는 방법을 보여줌
- Occlusion 실험을 통해 이미지는 local structure에 민감하며 Broad Scene context만 사용하는 것이 아니라는 것을 입증함
- ImageNet으로 학습된 모델이 다른 데이터에서 어떻게 잘 일반화될 수 있는지 보여줌
참고자료
https://velog.io/@lm_minjin/논문-리뷰-Visualizing-and-Understanding-Convolutional-Networks
https://sonstory.tistory.com/121
https://www.youtube.com/watch?v=1j9EUGJn9Qg
