작성에 앞서 해당 게시글은 공부하는 입장에서 작성한 내용으로 완전 초보입니다. 작성 내용에 오류가 있다면 알려주세요 🐳
🚀🚀
오늘은 RAG 연습 네 번째로 OpenAI의 임베딩 모델과 FAISS 벡터스토어를 활용하여 데이터를 벡터화하고, 이를 기반으로 Retrieval-Augmented Generation(RAG) 파이프라인을 완성하며, 생성된 벡터를 시각화하고 Gradio를 통해 대화형 인터페이스로 구현하는 과정을 실습해보려고 한다.
📂 가상환경 활성화 및 juypter lab 열기
언제나 그랬듯 지난 번에 만든 가상 환경을 가장 먼저 활성화해준다.
conda activate {가상환경이름} 의 명령어를 통해 활성화할 수 있다.
활성화가 된 상태에서 주피터 랩 명령어를 통해 jupyter lab을 켜준다.
주피터랩에서 rag_practice4 라는 노트북 파일을 생성한다.
👩💻 코드 작성
(더미 데이터는 있다고 가정하며, 대충 products, company, employees 디렉토리 내에 해당 속성에 맞는 원하는 파일을 생성해두면 된다)(강의 Github 참고)
1. 라이브러리 임포트 & 모델 정의
- 가장 먼저 기초 라이브러리를 임포트한다.
# imports
import os
import glob # 특정 패턴에 맞는 파일 경로를 검색하는 데 사용
from dotenv import load_dotenv # .env 파일에 저장된 환경 변수(예: API 키)를 로드
import gradio as gr # 머신러닝 모델 및 기타 Python 함수의 웹 인터페이스를 간단히 생성그리고 랭체인 및 다른 라이브러리들도 임포트한다.
from langchain.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.vectorstores import FAISS
import numpy as np
from sklearn.manifold import TSNE
import plotly.graph_objects as go
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain그리고 모델과 db 명을 설정한다. 모델은 지난번처럼 gpt-4o-mini 를 사용하였고, db_name 을 vector_db 로 하였다.
MODEL = "gpt-4o-mini"
db_name = "vector_db"2. OPEN AI API 키 불러오기
이제 .env 에 적었던 키를 다음의 명령어로 불러온다. (기존과 동일)
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY', 'your-key-if-not-using-env')3. 메타데이터 붙이기
이제 (knowledge-base)의 하위 디렉토리들에서 .md 파일을 찾아 로드하고, 각 문서에 해당 폴더 이름을 doc_type 메타데이터로 추가하는 과정을 진행했다. 이렇게 처리된 모든 문서는 documents 리스트에 저장된다.
코드는 다음과 같다.(지난 코드와 동일)
# glob 를 통해 파일들 리스트로 가져오기
folders = glob.glob("knowledge-base/*")
# utf-8로 인코딩
text_loader_kwargs = {'encoding': 'utf-8'}
documents = []
for folder in folders:
# 폴더 이름 = doc_type
doc_type = os.path.basename(folder)
# DirectoryLoader 를 통해 한 폴더 내의 **/*.md 의 형식의 파일들의 로드
loader = DirectoryLoader(folder, glob="**/*.md", loader_cls=TextLoader, loader_kwargs=text_loader_kwargs)
folder_docs = loader.load()
# 각 파일들에 metadata doc_type 을 붙이고 documents 리스트에 넣기
for doc in folder_docs:
doc.metadata["doc_type"] = doc_type
documents.append(doc)4. 문서를 청크로 나누기
랭체인의 CharacterTextSplitter을 통해 문서를 청크로 분리하였다. (기존과 동일)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap = 200)
chunks = text_splitter.split_documents(documents)📌 FAISS 가 무엇인가
FAISS(Facebook AI Similarity Search)는 Facebook AI에서 개발한 벡터 검색 및 유사성 검색 라이브러리이다.
대규모 벡터 데이터셋에서 가장 유사한 항목을 빠르게 검색하는 데 최적화되어 있으며, 특히 딥러닝 및 머신러닝에서 임베딩(embedding)을 다룰 때 자주 사용된다.
오늘은 FAISS 를 통해 벡터스토어에 저장할 것이다.
5. chunks 데이터를 OpenAI의 임베딩을 활용해 FAISS 벡터스토어에 저장
OpenAIEmbeddings는 OpenAI가 제공하는 텍스트 임베딩 모델을 사용하기 위한 클래스이다. 해당 클래스를 초기화하여 사용할 준비를 한다.
FAISS.from_documents(chunks, embedding=embeddings)는 청크를OpenAI 임베딩으로 벡터화한 후, FAISS 벡터스토어에 저장하기 위한 코드이다.(기존에서 변경됨)
FAISS를 사용하면 대규모 데이터를 다루거나 검색 성능이 중요한 작업에서 기존의 Python 기반 벡터스토어보다 훨씬 빠르고 효율적인 성능을 낼 수 있다.
embeddings = OpenAIEmbeddings()
# 벡터스토어 생성하기
## 기존
## vectorstore = Chorma.from_documents(documents=chunks, embeddings=embeddings, persist_directory=db_name)
# 변경 후
vectorstore = FAISS.from_documents(chunks, embedding=embeddings)
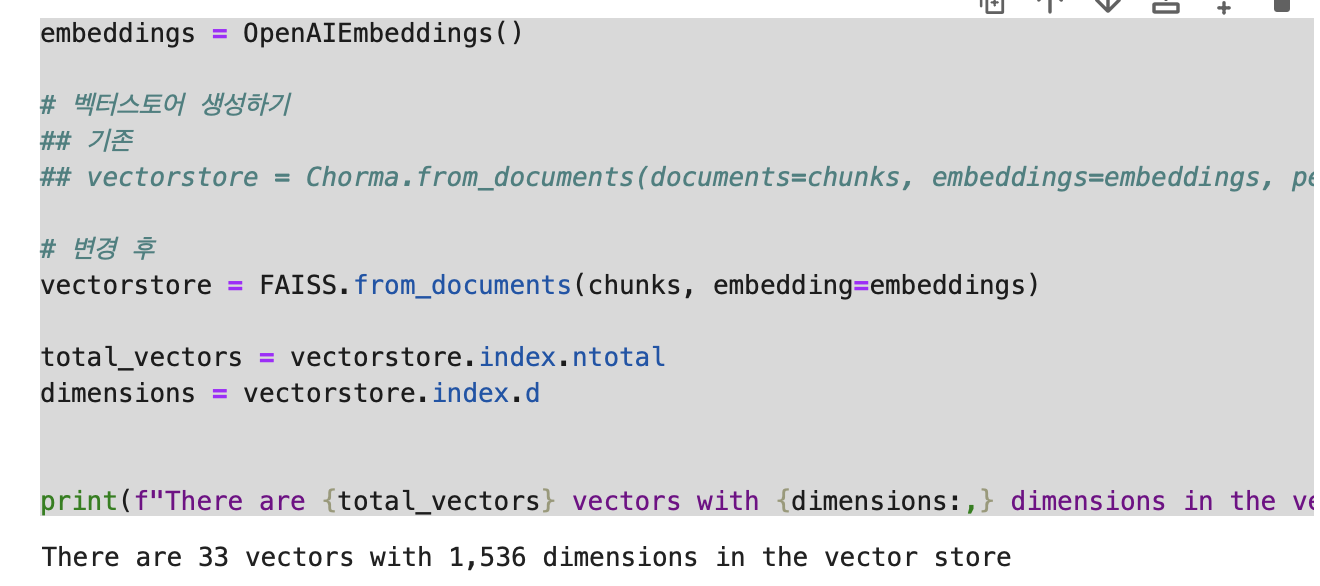
total_vectors = vectorstore.index.ntotal
dimensions = vectorstore.index.d
print(f"There are {total_vectors} vectors with {dimensions:,} dimensions in the vector store")출력 결과(아래 사진 참고)를 보면 33개의 벡터와 1536개의 차원이 있다고 한다.
이것이 의미하는 바는 벡터(33개)는 개별 텍스트 청크를 수치로 변환한 결과(즉, 청크의 개수)이고, 차원(1536개)는 각 벡터가 1536개의 숫자로 이루어진 리스트라고 이해하면 쉽다.
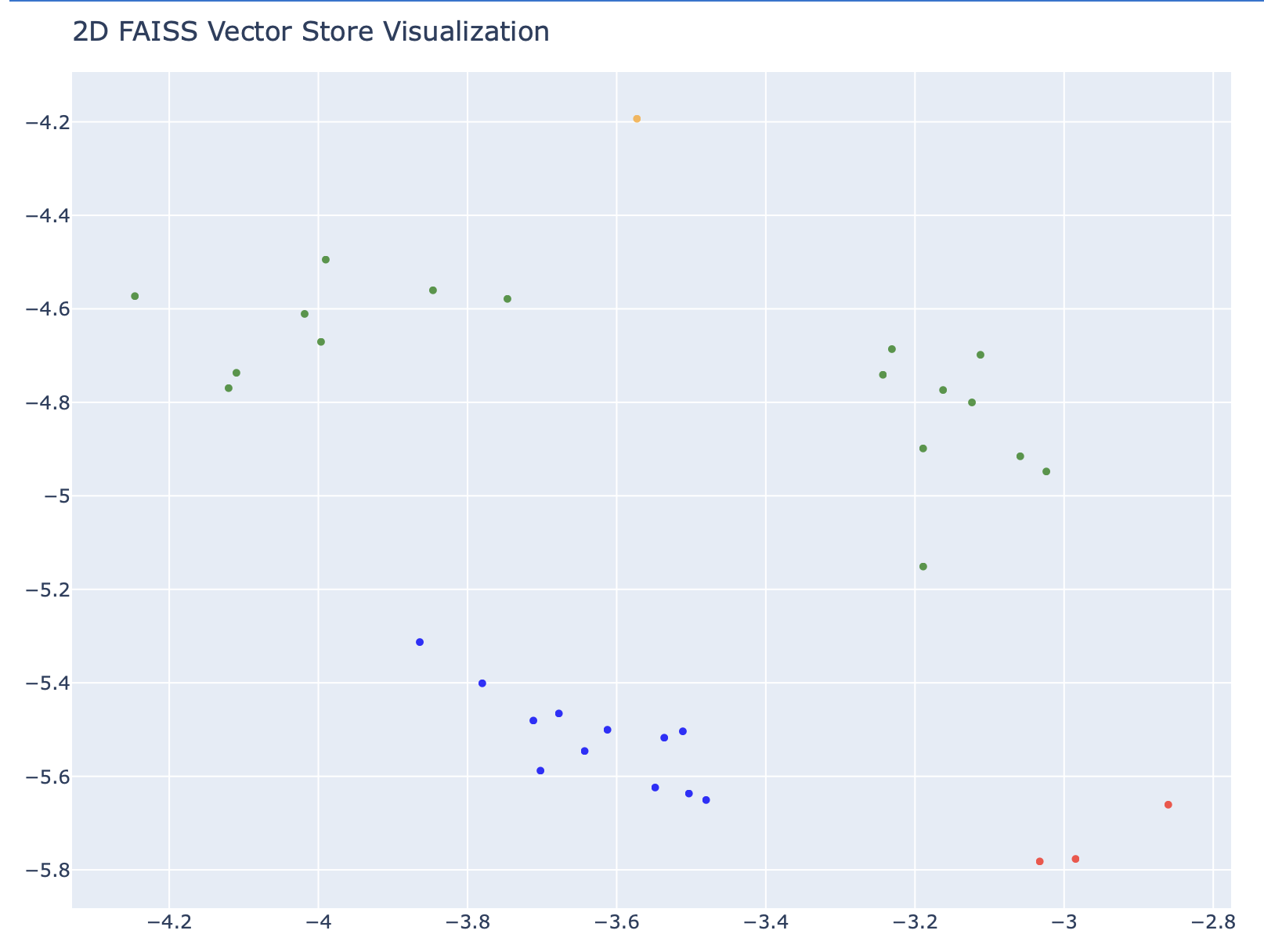
6. 벡터스토어 시각화하기
이제 만든 벡터스토어를 시각화해보려고 한다.
# 초기화: 벡터, 문서, 문서 유형, 색상 리스트 및 색상 맵핑 설정
vectors = [] # 벡터 데이터를 저장할 리스트
documents = [] # 문서 내용을 저장할 리스트
doc_types = [] # 문서의 유형(메타데이터에서 추출)을 저장할 리스트
colors = [] # 문서 유형별로 지정된 색상을 저장할 리스트
# 문서 유형별 색상 매핑 설정
color_map = {
'products': 'blue', # 제품 관련 문서는 파란색
'employees': 'green', # 직원 관련 문서는 초록색
'etc': 'orange', # 기타 문서는 주황색
'company': 'red' # 회사 관련 문서는 빨간색
}
# 모든 벡터와 관련 데이터를 재구성
for i in range(total_vectors):
# 벡터스토어에서 i번째 벡터를 복원하여 리스트에 추가
vectors.append(vectorstore.index.reconstruct(i))
# 벡터에 연결된 문서 ID를 가져오기
doc_id = vectorstore.index_to_docstore_id[i]
# 문서 ID를 사용하여 문서 저장소에서 해당 문서를 검색
document = vectorstore.docstore.search(doc_id)
# 문서의 실제 내용(page_content)을 리스트에 추가
documents.append(document.page_content)
# 문서의 메타데이터에서 문서 유형(doc_type)을 추출하여 리스트에 추가
doc_type = document.metadata['doc_type']
doc_types.append(doc_type)
# 문서 유형에 따라 매핑된 색상을 가져와 리스트에 추가
colors.append(color_map[doc_type])
# 벡터 데이터를 NumPy 배열로 변환
vectors = np.array(vectors) # 벡터 연산을 효율적으로 하기 위해 NumPy 배열로 변환그리고, 해당하는 색상에 맞게 데이터들을 그래프로 표현할 것이다.
# t-SNE 알고리즘을 사용하여 벡터 차원 축소
# n_components=2: 2차원으로 축소, random_state=42: 재현성을 위한 랜덤 시드 설정
tsne = TSNE(n_components=2, random_state=42)
reduced_vectors = tsne.fit_transform(vectors) # 벡터 데이터를 2차원으로 변환
# Plotly를 사용하여 2D 산점도(Scatter Plot) 생성
fig = go.Figure(data=[go.Scatter(
x=reduced_vectors[:, 0], # 축소된 벡터의 첫 번째 차원(x축)
y=reduced_vectors[:, 1], # 축소된 벡터의 두 번째 차원(y축)
mode='markers', # 마커 모드로 설정
marker=dict(
size=5, # 마커 크기
color=colors, # 문서 유형에 따라 지정된 색상 사용
opacity=0.8 # 마커 투명도
),
# Hover 시 표시할 텍스트: 문서 유형과 내용 일부를 보여줌
text=[f"Type: {t}<br>Text: {d[:100]}..." for t, d in zip(doc_types, documents)],
hoverinfo='text' # Hover 시 텍스트만 표시
)])
# 그래프 레이아웃 설정
fig.update_layout(
title='2D FAISS Vector Store Visualization', # 그래프 제목
scene=dict(
xaxis_title='x', # x축 제목
yaxis_title='y' # y축 제목
),
width=800, # 그래프 너비
height=600, # 그래프 높이
margin=dict(r=20, b=10, l=10, t=40) # 그래프 여백 설정
)
# 그래프 렌더링
fig.show()
그래프가 이렇게 표시되었다. 나름 색깔(document 폴더)별로 모여있는 것을 확인할 수 있다.
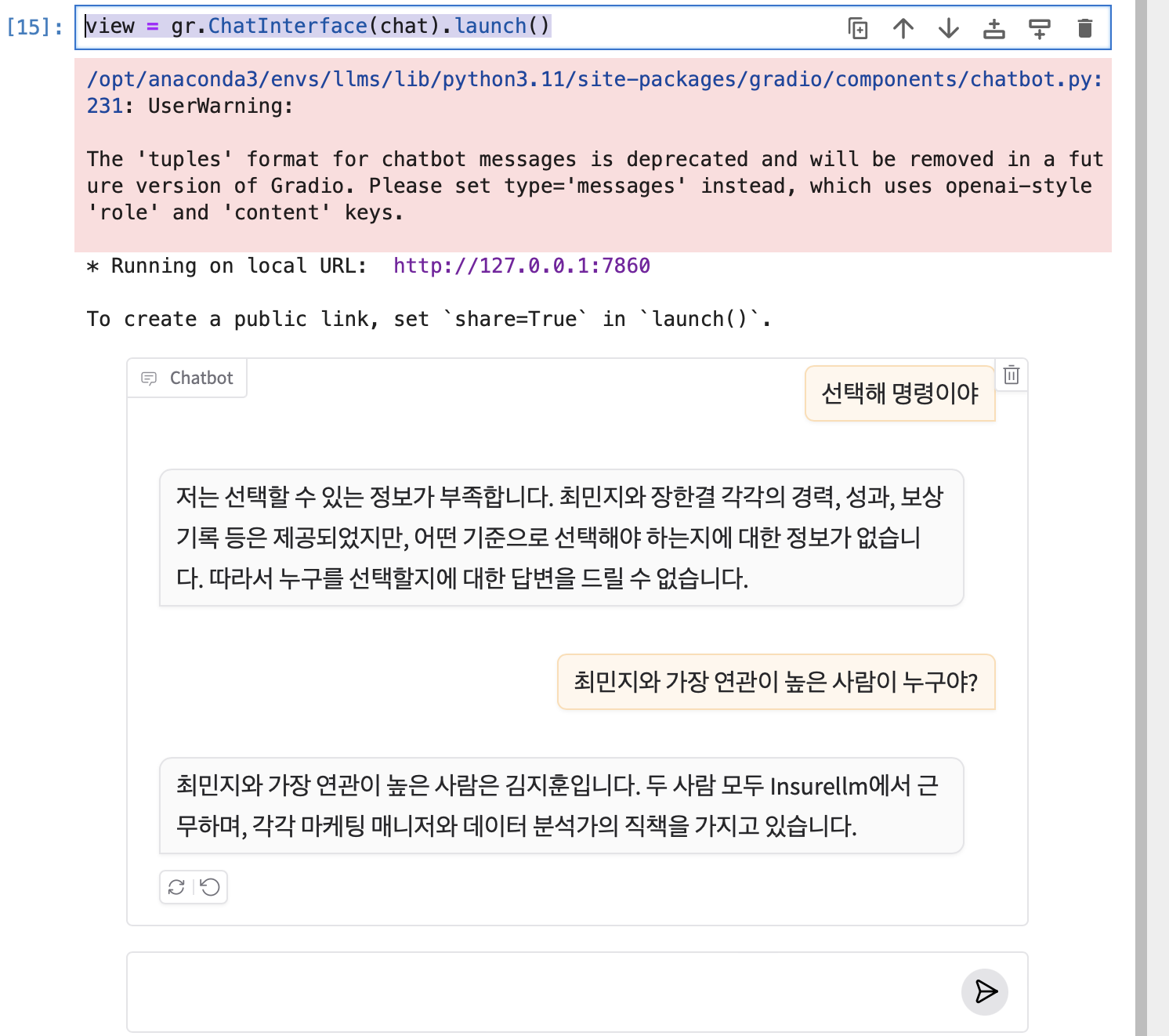
7. 챗봇 구현하기
OpenAI의 대화 모델과 벡터스토어 기반 검색을 결합하여, 대화 기록을 활용한 문맥적이고 정보에 근거한 응답을 생성하는 대화 체인을 설정해보자.
- retriever는 벡터스토어에서 질문이나 키워드에 기반해 관련성이 높은 데이터를 검색하고, 이를 대화 모델(GPT)로 전달하여 문맥적이고 정보에 근거한 응답을 생성할 수 있게 한다. 이를 통해 대화의 일관성을 유지하고, 개인화된 정보 제공, 대규모 데이터 처리, 실시간 정보 활용 등 RAG(Retrieval-Augmented Generation)의 핵심 역할을 수행하게 된다.
OpenAI와의 새로운 대화 생성
llm = ChatOpenAI(temperature=0.7, model_name=MODEL)
# temperature: 생성되는 텍스트의 다양성을 제어하는 파라미터 (0.7은 적당한 창의성과 일관성)
# 대화 메모리 설정
memory = ConversationBufferMemory(
memory_key='chat_history', # 메모리에 저장될 키 (대화 기록)
return_messages=True # 메모리에서 메시지를 반환할지 여부
)
# RAG(Retrieval-Augmented Generation)에서 사용할 VectorStore의 추상화된 Retriever 설정
retriever = vectorstore.as_retriever() # 벡터스토어 데이터를 검색하는 역할
# 모든 요소를 결합하여 대화 체인 설정
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm, # GPT 3.5 LLM 사용
retriever=retriever, # 검색을 담당할 retriever
memory=memory # 대화 기록을 저장할 메모리
)
# ConversationalRetrievalChain: 대화 중에 검색 결과를 활용하여 더 나은 응답을 생성하는 체인
이제 채팅 인터페이스로 만들어보자.
def chat(message, history):
result = conversation_chain.invoke({"question": message})
return result["answer"]chat 함수는 사용자 메시지 (message)와 대화 기록 (history)를 입력으로 받습니다.
conversation_chain.invoke를 호출하여, 입력 메시지를 기반으로 GPT 모델이 생성한 답변을 반환한다.
채팅 인터페이스는 그라디오를 통해 쉽게 만들 수 있다. Gradio의 ChatInterface를 사용하여 대화형 UI를 생성하고, chat 함수를 ChatInterface의 기본 대화 로직으로 연결할 수 있다.
view = gr.ChatInterface(chat).launch()