
작성에 앞서 해당 게시글은 공부하는 입장에서 작성한 내용으로 완전 초보입니다. 작성 내용에 오류가 있다면 알려주세요 🐳
🚀🚀
오늘은 RAG 연습 세 번째로 청크를 임베딩하여 벡터 스토어에 저장하고, 이를 시각화해보려고 한다.
📂 가상환경 활성화 및 juypter lab 열기
지난 번에 만든 가상 환경을 가장 먼저 활성화해준다.
conda activate llms 의 명령어를 통해 활성화할 수 있다.
활성화가 된 상태에서 주피터 랩 명령어를 통해 jupyter lab을 켜준다.
주피터랩에서 rag_practice3 라는 노트북 파일을 생성한다.
👩💻 코드 작성
(더미 데이터는 있다고 가정하며, 대충 products, company, employees 디렉토리 내에 해당 속성에 맞는 원하는 파일을 생성해두면 된다)(지난 블로그들 참고)
1. 라이브러리 임포트 & 모델 정의
- 가장 먼저 기초 라이브러리를 임포트한다.
# imports
import os
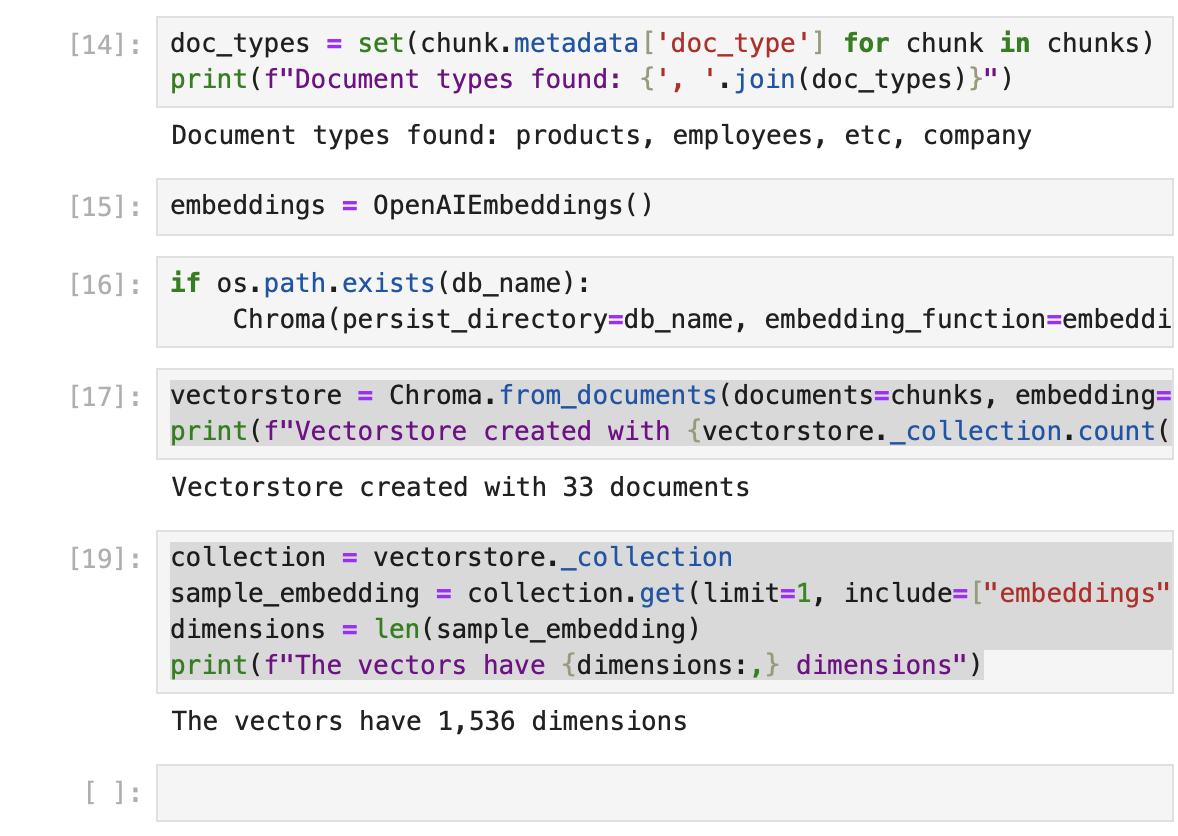
import glob # 특정 패턴에 맞는 파일 경로를 검색하는 데 사용
from dotenv import load_dotenv # .env 파일에 저장된 환경 변수(예: API 키)를 로드
import gradio as gr # 머신러닝 모델 및 기타 Python 함수의 웹 인터페이스를 간단히 생성그리고 랭체인 및 다른 라이브러리들도 임포트한다 (이게 변화된 부분이다)
from langchain.document_loaders import DirectoryLoader, TextLoader # 문서 로더
from langchain.text_splitter import CharacterTextSplitter # 텍스트 분할
from langchain.schema import Document # 문서 구조 정의
from langchain_openai import OpenAIEmbeddings, ChatOpenAI # OpenAI 임베딩 및 모델
from langchain_chroma import Chroma # 임베딩 저장/검색
import numpy as np # 수치 계산
from sklearn.manifold import TSNE # 차원 축소
import plotly.graph_objects as go # 데이터 시각화그리고 모델과 db 명을 설정한다. 모델은 지난번처럼 gpt-4o-mini 를 사용하였고, db_name 을 vector_db 로 하였다.
MODEL = "gpt-4o-mini"
db_name = "vector_db"2. OPEN AI API 키 불러오기
이제 .env 에 적었던 키를 다음의 명령어로 불러온다. (기존과 동일)
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY', 'your-key-if-not-using-env')3. 메타데이터 붙이기
이제 (knowledge-base)의 하위 디렉토리들에서 .md 파일을 찾아 로드하고, 각 문서에 해당 폴더 이름을 doc_type 메타데이터로 추가하는 과정을 진행했다. 이렇게 처리된 모든 문서는 documents 리스트에 저장된다.
코드는 다음과 같다.(지난 코드와 동일)
folders = glob.glob("knowledge-base/*")
text_loader_kwargs = {'encoding': 'utf-8'}
documents = []
for folder in folders:
doc_type = os.path.basename(folder)
loader = DirectoryLoader(folder, glob="**/*.ml", loader_cls=TextLoader, loader_kwargs=text_loader_kwargs)
folder_docs = loader.load()
for doc in folder_docs:
doc.metadata["doc_type"] = doc_type
documents.append(doc)4. 문서를 청크로 나누기
이제 랭체인 패키지를 사용하여 문서를 작은 크기로 나눠 LLM에서 더 효율적으로 처리할 수 있게 하려 한다.
CharacterTextSplitter는 LangChain 라이브러리에서 제공하는 기능으로 문서를 각 청크의 최대 문자 수를 1000자로, 청크 간 겹치는 문자 수를 200자로 설정하여 청크로 분리하였다. (기존과 동일)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)📌 Embedding 과 Auto-Encoding LLM 설명
이쯤에서 임베딩과 오토 인코딩 LLM 에 대해 알아보자.
다음으로 텍스트의 각 청크을 텍스트의 의미를 나타내는 벡터(임베딩)로 매핑할 것이기 때문이다.
OpenAI는 이를 수행하는 모델을 제공하며, LangChain 코드를 통해 OpenAI API를 호출하여 사용할 수 있다.
Auto-Encoding LLM은 완전한 입력이 주어졌을 때 출력을 생성한다. 이는 과거 문맥을 기반으로 미래의 토큰을 예측하여 생성하는 "Auto-Regressive LLM"과 다르다.
Google의 BERT가 Auto-Encoding LLM의 예이다. Auto-Encoding LLM은 임베딩 생성뿐만 아니라 분류(classification) 작업에서도 자주 사용된다.
5. 문서 데이터를 벡터로 변환해 Chroma 벡터스토어에 저장
OpenAIEmbeddings는 OpenAI가 제공하는 텍스트 임베딩 모델을 사용하기 위한 클래스이다. 해당 클래스를 초기화하여 사용할 준비를 한다.
embeddings = OpenAIEmbeddings()그리고 db_name 으로 데이터베이스 파일 존재 여부를 확인한 후,해당 디렉토리나 파일에 저장된 Chroma 데이터베이스 컬렉션을 삭제하여 기존 데이터를 초기화한다. 이는 데이터베이스를 새로 생성하거나 다른 데이터를 저장할 준비를 하기 위한 과정이다.
if os.path.exists(db_name):
Chroma(persist_directory=db_name, embedding_function=embeddings).delete_collection()Chroma는 임베딩을 저장하고 검색하는 데 사용되는 데이터베이스이다.
그리고, 크로마 벡터스토어를 만든다.
Chroma.from_documents는 주어진 문서(documents)를 벡터로 변환하고 이를 데이터베이스에 저장한다. 벡터화할 텍스트 데이터를 포함하는 문서 청크(chunks), 문서의 임베딩을 생성하는 데 사용할 함수 또는 모델(embeddings), 벡터 데이터를 저장할 디렉토리 경로(db_name) 을 파라미터로 설정할 수 있다.
# Chroma 데이터베이스를 문서(chunks)와 임베딩(embeddings)을 사용해 생성
vectorstore = Chroma.from_documents(documents=chunks, embedding=embeddings, persist_directory=db_name)
# 생성된 벡터스토어의 문서 수를 출력
print(f"Vectorstore created with {vectorstore._collection.count()} documents")벡터스토어 내부 컬렉션 접근하여 한 번 임베딩 벡터의 차원을 계산해보자. 다음처럼 vectorstore._collection 으로 내부 컬렉션 객체를 가져올 수 있고, collection.get(limit=1, include=["embeddings"])["embeddings"][0] 으로 컬렉션에서 첫 번째 벡터 임베딩을 가져온다.
이런 샘플 임베딩의 len() 을 통해 차원의 수를 계산할 수 있다.
# 벡터스토어에서 내부 컬렉션 객체 가져오기
collection = vectorstore._collection
# 컬렉션에서 첫 번째 벡터 임베딩 가져오기
sample_embedding = collection.get(limit=1, include=["embeddings"])["embeddings"][0]
# 임베딩의 차원 수 계산
dimensions = len(sample_embedding)
# 임베딩 벡터의 차원 수 출력
print(f"The vectors have {dimensions:,} dimensions")
결과는 이렇게 1,536 차원으로 나왔다.
6. 벡터스토어 시각화하기
이제 만든 벡터스토어를 시각화해보려고 한다.
collection.get(include=['embeddings', 'documents', 'metadatas']): 컬렉션에서 요청된 데이터(임베딩, 문서, 메타데이터)를 가져오고, 임베딩 데이터를 NumPy 배열로 변환한다. 그리고 원본 documents 데이터를 추출하고, doc_type 도 추출해서 doc_type 에 따라 색상을 지정한다.
# 컬렉션에서 임베딩, 원본 문서, 메타데이터 가져오기
result = collection.get(include=['embeddings', 'documents', 'metadatas'])
# 임베딩 데이터를 NumPy 배열로 변환
vectors = np.array(result['embeddings'])
# 원본 문서 데이터 추출
documents = result['documents']
# 메타데이터에서 문서 유형(doc_type) 추출
doc_types = [metadata['doc_type'] for metadata in result['metadatas']]
# 문서 유형에 따라 색상을 지정
# 'products' -> 'blue', 'employees' -> 'green', 'company' -> 'red', 'etc' -> 'orange'
colors = [['blue', 'green', 'red', 'orange'][['products', 'employees', 'company', 'etc'].index(t)] for t in doc_types]그리고, 해당하는 색상에 맞게 데이터들을 그래프로 표현할 것이다.
# t-SNE 모델 초기화: 2D로 차원 축소
tsne = TSNE(n_components=2, random_state=42)
# 벡터 데이터에 대해 t-SNE 변환 수행
reduced_vectors = tsne.fit_transform(vectors)
# 2D 산점도 생성
fig = go.Figure(data=[go.Scatter(
x=reduced_vectors[:, 0], # 축소된 x 좌표
y=reduced_vectors[:, 1], # 축소된 y 좌표
mode='markers', # 마커로 표시
marker=dict(
size=5, # 마커 크기
color=colors, # 문서 유형에 따른 색상
opacity=0.8 # 마커 투명도
),
# 호버 시 표시될 텍스트 (문서 유형과 내용 일부 표시)
text=[f"Type: {t}<br>Text: {d[:100]}..." for t, d in zip(doc_types, documents)],
hoverinfo='text' # 호버 정보로 텍스트 표시
)])
# 그래프 레이아웃 설정
fig.update_layout(
title='2D Chroma Vector Store Visualization', # 그래프 제목
scene=dict(
xaxis_title='x', # x축 제목
yaxis_title='y' # y축 제목
),
width=800, # 그래프 너비
height=600, # 그래프 높이
margin=dict(r=20, b=10, l=10, t=40) # 여백 설정
)
# 그래프 표시
fig.show()
그래프가 이렇게 표시되었다. 파란 점들이 products 디렉토리 내의 청크들, 초록점이 employees 내의 청크들, 빨간색이 company 내의 청크들, etc 는 내가 임의로 작성한 기타 문서이다.
나름 유형별로 군집화 되어있는 것을 확인할 수 있다.
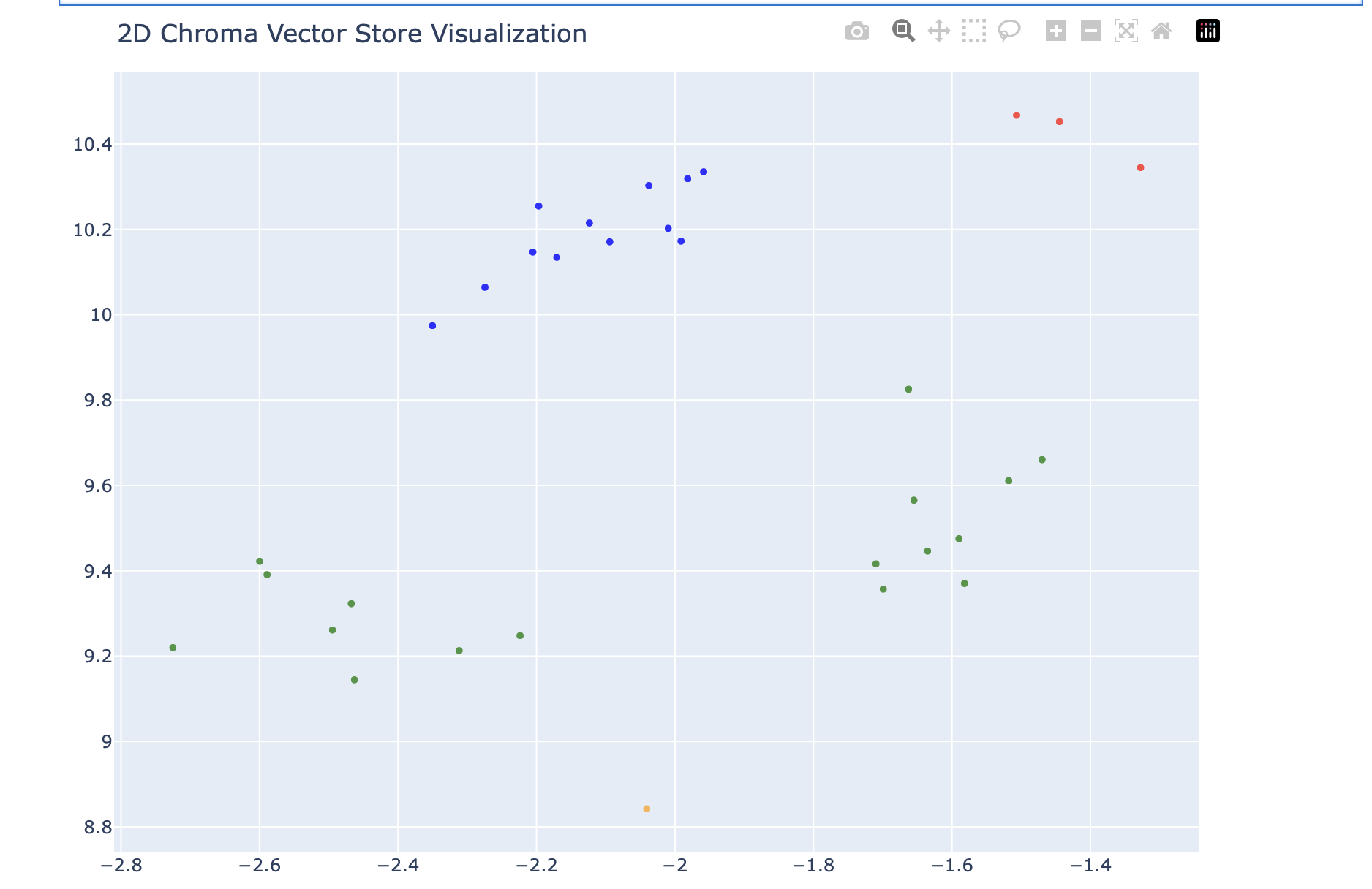
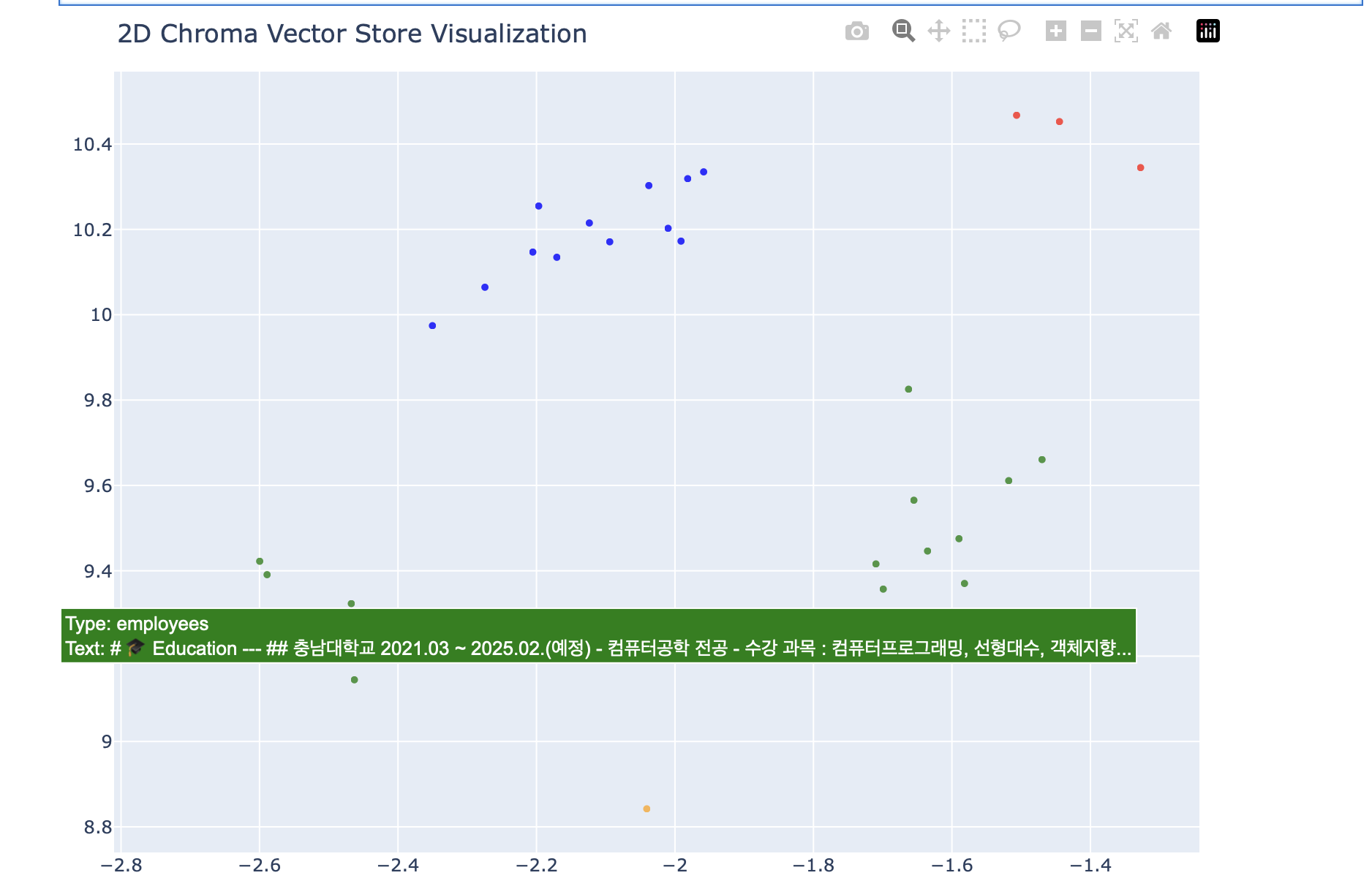
왼쪽에 초록색이 왜 오른쪽이랑 떨어져서 모여있나 확인했더니 왼쪽 녹색 점들은 전부 내 포트폴리오 내용이었다. 내용이 길어서 여러 청크로 나뉜것 같다.
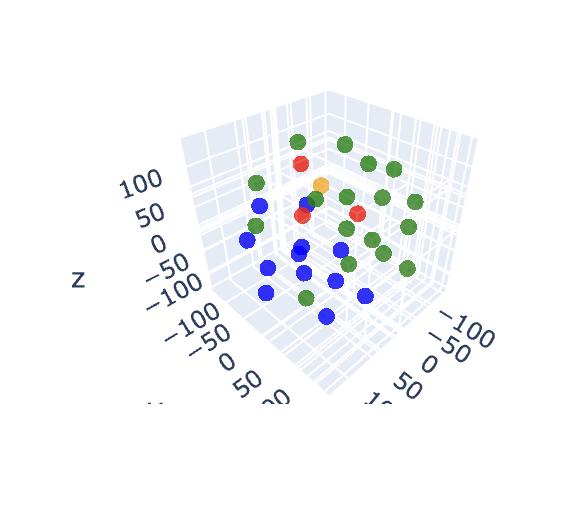
3d 로 시각화하는 코드는 이렇다.
tsne = TSNE(n_components=3, random_state=42)
reduced_vectors = tsne.fit_transform(vectors)
fig = go.Figure(data=[go.Scatter3d(
x=reduced_vectors[:, 0],
y=reduced_vectors[:,1],
z=reduced_vectors[:,2],
mode='markers',
marker=dict(size=5, color=colors, opacity=0.8),
text=[f"Type: {t}<br> Text: {d[:100]}..." for t, d in zip(doc_types, documents)],
hoverinfo='text'
)])이런식으로 표현되었다.
다음 목표
- 다음 시간엔 채팅 인터페이스를 통해 실제 챗봇을 구현하려고 한다.
